J’ai récemment demandé d’écrire une mise à jour sur le travail avec les rapports AWR, alors comme promis, le voici!
Le Référentiel automatique de charges de travail
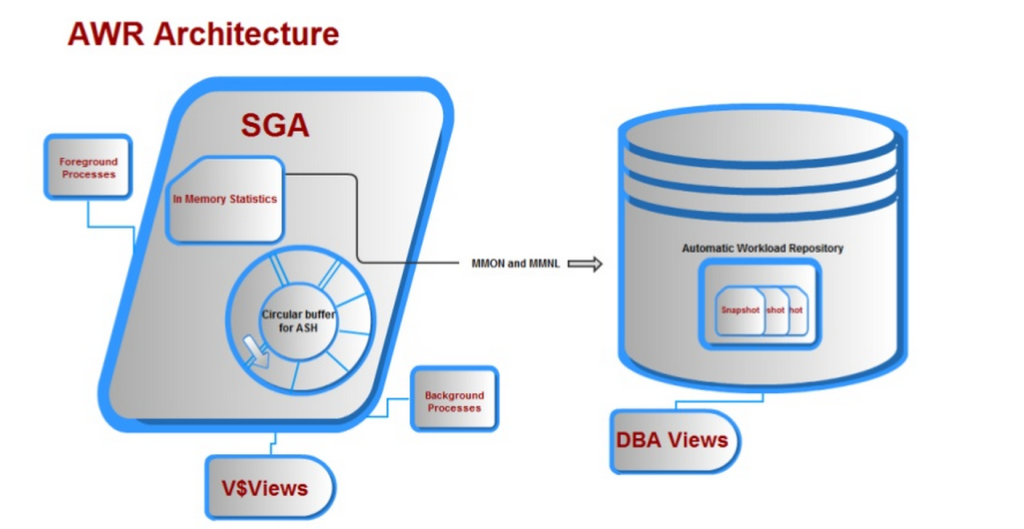
Le Référentiel automatique de charges de travail (AWR) était l’une des meilleures améliorations apportées à Oracle dans la version 10g. Le groupe de développement avait tout un objectif lorsqu’il leur a été demandé de développer un produit qui :
1. A fourni des recommandations de performances significatives et des améliorations des données d’événements d’attente par rapport à son prédécesseur statspack.
2. Était toujours activé, ce qui signifie que les données seraient continuellement collectées sans intervention manuelle de l’administrateur de la base de données.
3. N’aurait pas d’impact sur le traitement en cours, ayant ses propres processus d’arrière-plan et tampon mémoire, espace de table désigné (SYSAUX).
4. Le tampon mémoire écrirait dans la direction opposée par rapport à la direction que lit l’utilisateur, éliminant ainsi les problèmes de concurrence.
Avec de nombreuses autres exigences, tout ce qui précède a été proposé avec le référentiel de charge de travail automatique et nous nous retrouvons avec une architecture qui ressemble à ceci:
En utilisant des données AWR
, les données AWR sont identifiées par le DBID, (Identifiant de base de données) et un SNAP_ID, (identifiant d’instantané, qui a un begin_interval_time et end_interval_time pour isoler la date et l’heure de la collecte de données.) et des informations sur ce qui est actuellement conservé dans la base de données peuvent être interrogées à partir du DBA_HIST_SNAPSHOT. Les données AWR contiennent également des échantillons ASH (Historique de session actif) ainsi que les données d’instantané, par défaut, environ 1 échantillon sur 10.
L’objectif d’utiliser efficacement les données AWR a vraiment à voir avec ce qui suit:
1. Avez-vous identifié un véritable problème de rendement dans le cadre d’un examen du rendement?
2. Y a-t-il eu une plainte de l’utilisateur ou une demande d’enquête sur une dégradation des performances ?
3. Y a-t-il un défi commercial ou une question à laquelle AWR peut apporter une réponse? (nous irons quand utiliser AWR par rapport à d’autres fonctionnalités…)
Examen des performances
Un examen des performances est l’endroit où vous avez identifié un problème ou où vous avez été chargé d’étudier l’environnement pour résoudre les problèmes de performances. J’ai quelques environnements de gestionnaire d’entreprise à ma disposition, mais j’ai choisi d’en choisir un en particulier et de croiser les doigts en espérant que j’aurais un traitement lourd pour répondre aux exigences de ce poste.
Le moyen le plus rapide de voir la charge de travail dans votre environnement de base de données à partir d’EM12c, cliquez sur Cibles – > Bases de données. Choisissez d’afficher par carte de charge et vous afficherez ensuite les bases de données par charge de travail. En me rendant dans un environnement de gestionnaire d’entreprise spécifique, j’ai découvert que c’était mon jour de chance!
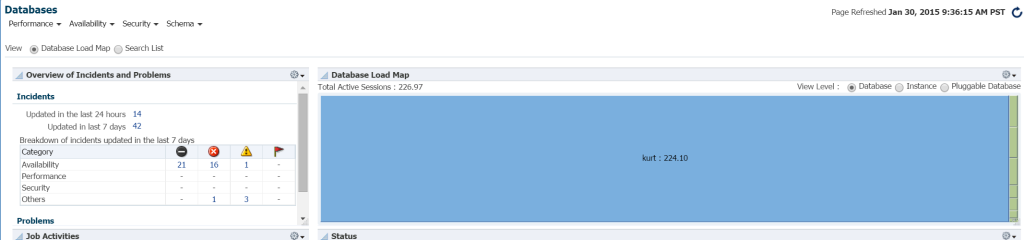 Je ne sais vraiment pas qui est Kurt qui a une base de données surveillée sur cet environnement de contrôle du cloud EM12c, mais mon garçon, est-il ma personne préférée aujourd’hui! 🙂
Je ne sais vraiment pas qui est Kurt qui a une base de données surveillée sur cet environnement de contrôle du cloud EM12c, mais mon garçon, est-il ma personne préférée aujourd’hui! 🙂
En passant mon curseur sur le nom de la base de données, (kurt) vous pouvez voir la charge de travail qu’il exécute actuellement sur sa base de données de test: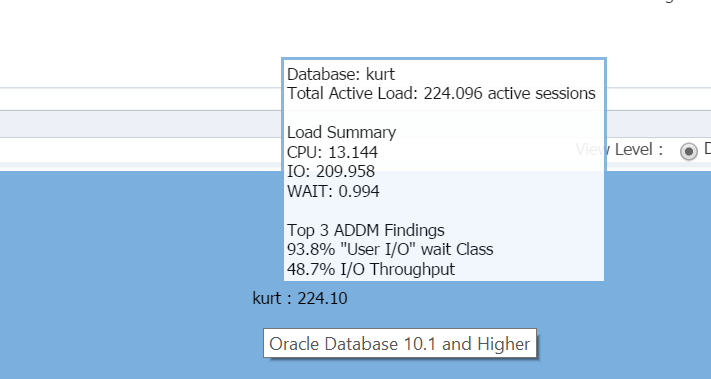
Mon garçon, Kurt est ma personne préférée aujourd’hui!
Page d’accueil de la base de données EM12c
En me connectant à la base de données, je peux voir l’utilisation significative des E/ S et des ressources pour la base de données et l’hôte à partir de la page d’accueil de la base de données:
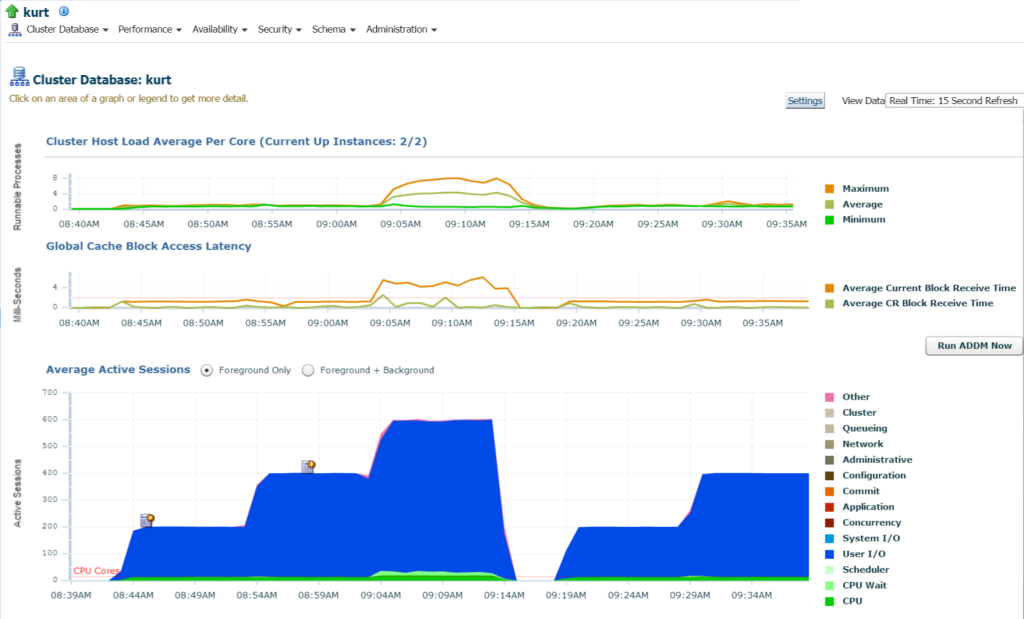
Si nous passons à l’activité supérieure (menu Performance, Activité supérieure), je commence à afficher plus de détails sur le traitement et les différents événements d’attente:
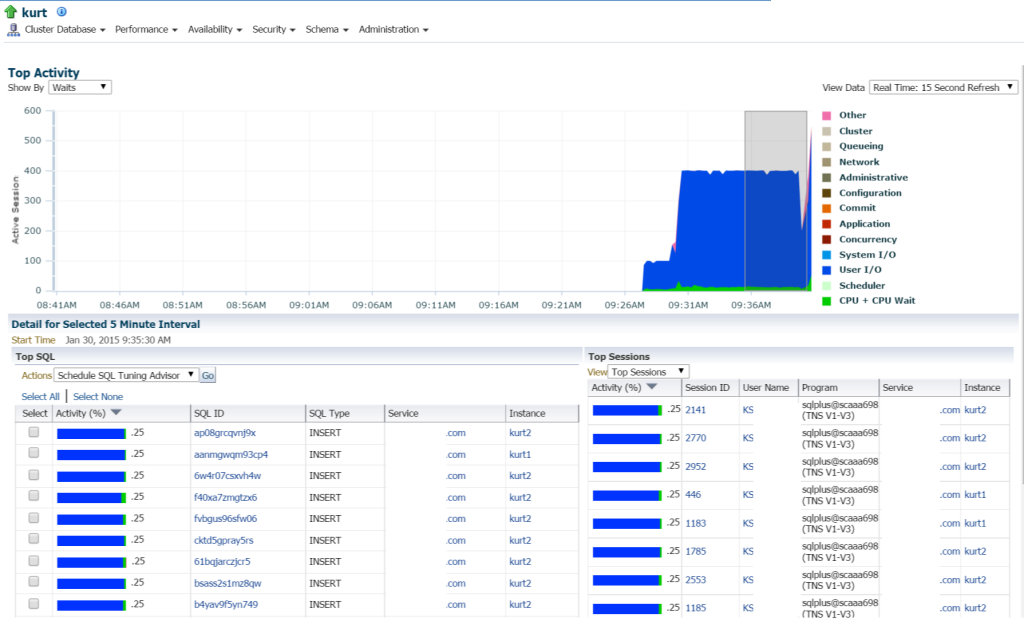
Kurt fait toutes SORTES d’insertions, (vues par les différents SQL_IDs, par type SQL « INSERT ». Je peux explorer les déclarations individuelles et enquêter sur cela, mais vraiment, il y a une TONNE d’instructions et SQL_ID est ici, ne serait-il pas plus facile de voir la charge de travail avec un rapport AWR?
Exécution du rapport AWR
Je choisis de cliquer sur Performance, AWR, Rapport AWR. Maintenant, j’ai le choix. Je pourrais demander qu’un nouvel instantané soit exécuté immédiatement ou attendre le début de l’heure, car l’intervalle est défini toutes les heures dans cette base de données. J’ai choisi ce dernier pour cette démonstration, mais si vous vouliez créer un instantané immédiatement, vous pouvez le faire facilement à partir d’EM12c ou demander un instantané en exécutant ce qui suit à partir de SQLPlus avec un utilisateur disposant des privilèges d’exécution sur le DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
Pour cet exemple, j’ai simplement attendu, car il n’y avait pas de hâte ou d’inquiétude ici et j’ai demandé le rapport pour l’heure précédente et le dernier instantané:
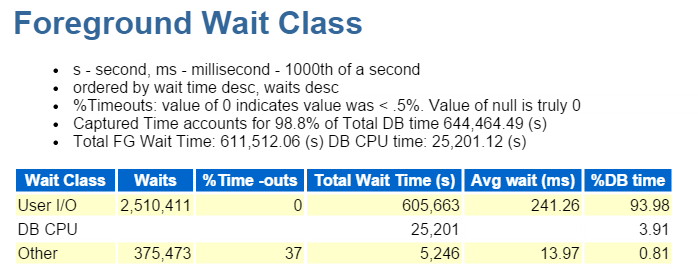
Je commence toujours par les dix premiers événements de premier plan et je regarde généralement ceux avec des pourcentages d’attente élevés:
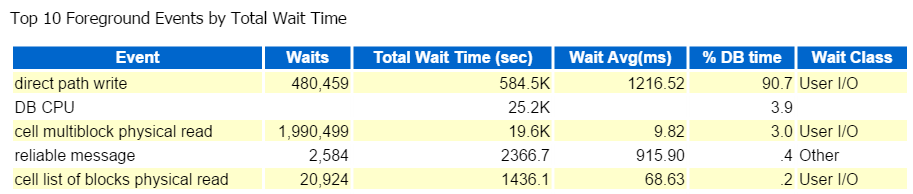
Écrire le chemin direct, c’est tout. Rien d’autre à voir ici 🙂 🙂
L’écriture directe du chemin implique les éléments suivants: insertions / mises à jour, objets en cours d’écriture, espaces de table en cours d’écriture et les fichiers de données qui composent le (s) espace (s) de table.
C’est aussi IO, que nous vérifions rapidement dans la classe d’attente au premier plan:
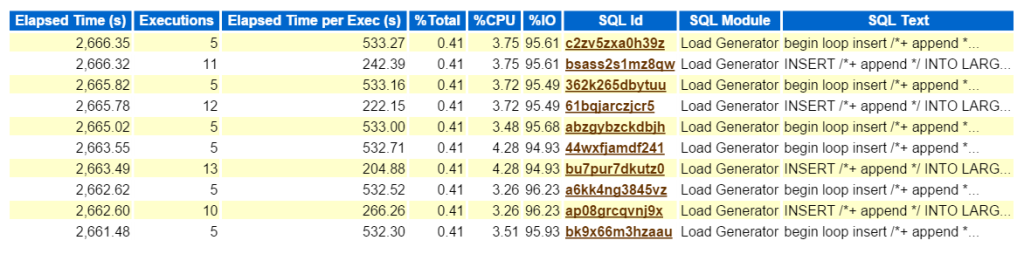
Regarder le SQL supérieur par temps écoulé confirme que nous avons affaire à une charge de travail composée de tous les insertions:
En cliquant sur l’ID SQL, j’accède à la liste complète du texte SQL et me montre exactement ce que fait le Bad Boy Kurt pour produire sa charge de travail de test:

Ce Kurt est un rebelle, hein ? 🙂
Insérer une boucle dans une table à partir de la même table, restaurer puis terminer la boucle, merci d’avoir joué. Il tire des pneus et le fait avec angoisse! Ne vous inquiétez pas les gens, comme je l’ai dit, Kurt fait son travail, en utilisant un module appelé « Générateur de charge ». Je serais un imbécile de ne pas reconnaître cela comme autre chose que ce que c’est – générer une charge de travail pour tester quelque chose. J’ai juste l’avantage supplémentaire d’avoir une charge de travail pour faire un article de blog sur l’utilisation des données AWR 🙂 🙂
Maintenant, si c’était un vrai problème et que j’essayais de savoir quel impact de ce type de performance ce type d’insert créait sur l’environnement, où aller ensuite dans le rapport AWR? Le SQL supérieur par temps écoulé est important car il devrait être là où vous concentrez vos efforts. D’autres sections ventilées par SQL sont agréables à avoir, mais rappelez-vous toujours: « Si vous ne réglez pas le temps, vous perdez du temps. »Rien ne peut découler d’un exercice d’optimisation si aucun gain de temps n’est constaté une fois le travail terminé. Donc, en prenant d’abord le SQL supérieur par temps écoulé, puis en regardant l’instruction, nous pouvons maintenant voir quels objets font partie de l’instruction, (large_block149, 191, 194, 145).
Nous savons également que le problème est IO, nous devrions donc sauter des informations détaillées SQL et passer aux informations au niveau de l’objet. Ces sections sont identifiées par Segments par xxx.
- Segments par Lectures logiques
- Segments par Lectures Physiques
- Segments par Requêtes de Lecture
- Segments par Analyses de Table
et ainsi de suite….
Ceux-ci montrent tous un motif et un pourcentage très similaires pour les objets que nous voyons dans notre SQL supérieur. Rappelez-vous, Kurt lisait chacune de ces tables, puis insérait à nouveau ces mêmes lignes dans la table, puis reculait. Comme il s’agit d’un scénario de charge de travail, contrairement à la plupart des problèmes de performances que je vois, il n’y a aucun objet en suspens avec un impact supérieur à 10% dans aucun domaine.

Comme il s’agit d’un Exadata, il existe une tonne d’informations pour vous aider à comprendre le déchargement, le cache flash (analyses intelligentes), etc. cela vous aidera à relayer les informations dont vous avez besoin pour vous assurer que vous atteignez les performances souhaitées avec un système technique, mais j’aimerais les conserver pour un autre article et simplement toucher à quelques-uns des rapports d’E / S, alors que nous effectuions des analyses de table, nous voulons donc nous assurer que ceux-ci étaient déchargés vers les nœuds cellulaires, (analyses intelligentes) par rapport à un nœud de base de données.
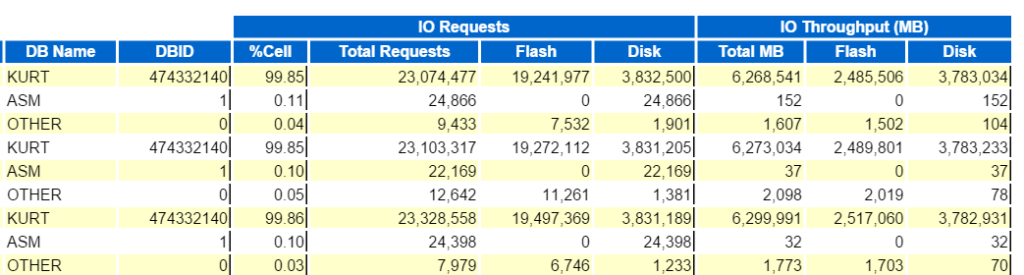
Nous pouvons commencer par regarder le meilleur débit d’E/S de la base de données:

Et puis affichez les principales demandes de base de données par débit de cellule (sans les noms de nœuds de cellule) pour voir comment elles se comparent: