jag har nyligen fått en begäran om att skriva en uppdatering om att arbeta med AWR-rapporter, så som lovat, här är det!
det automatiska Arbetsbelastningsförvaret
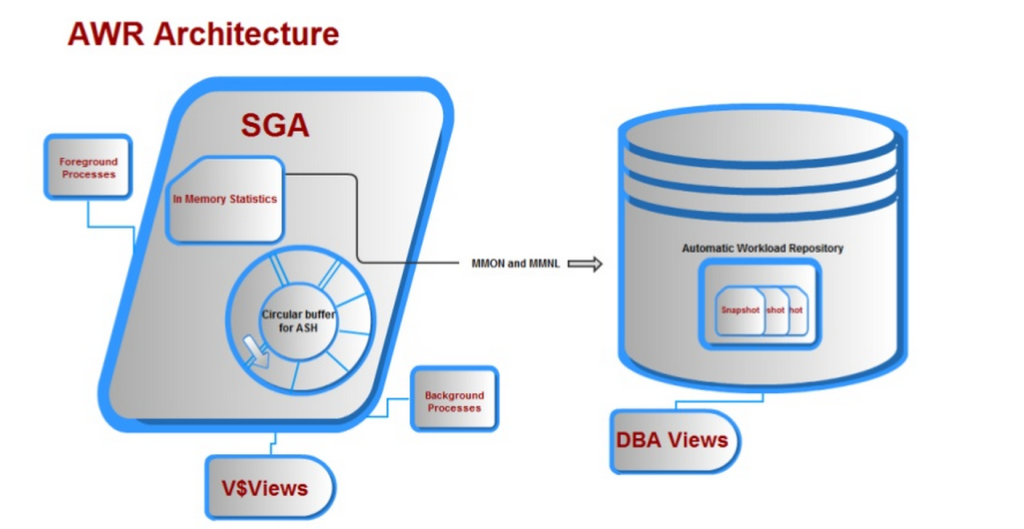
det automatiska Arbetsbelastningsförvaret, (AWR) var en av de bästa förbättringarna till Oracle tillbaka i release 10g. det fanns ett ganska mål framför utvecklingsgruppen när de ombads att utveckla en produkt som:
1. Förutsatt betydande prestanda rekommendation och vänta händelsedata förbättringar över sin föregångare statspack.
2. Var alltid på, vilket innebär att data kontinuerligt skulle samla in utan manuell ingripande från databasadministratören.
3. Skulle inte påverka den nuvarande behandlingen, med egna bakgrundsprocesser och minnesbuffert, betecknad tabellutrymme, (SYSAUX).
4. Minnesbufferten skulle skriva i motsatt riktning kontra riktning som användaren läser, vilket eliminerar samtidighetsproblem.
tillsammans med många andra krav erbjöds allt ovan med det automatiska Arbetsbelastningsförvaret och vi slutar med arkitektur som ser ut så här:
använda AWR-Data
AWR-data identifieras av DBID, (Database Identifier) och en SNAP_ID, (snapshot identifier, som har en begin_interval_time och end_interval_time för att isolera datum och tid för datainsamlingen.) och information om vad som för närvarande finns kvar i databasen kan frågas från DBA_HIST_SNAPSHOT. AWR-data innehåller också ASH, (Active Session History) – prover tillsammans med ögonblicksbildsdata, som standard, cirka 1 av 10 prover.
målet att använda AWR-data effektivt har verkligen att göra med följande:
1. Har du identifierat ett verkligt prestandaproblem som en del av en prestationsgranskning?
2. Har det förekommit ett användarklagomål eller en begäran om att undersöka en prestandaförsämring?
3. Finns det en affärsutmaning eller Fråga som behöver besvaras som AWR kan erbjuda svar på? (vi går när du ska använda AWR vs. andra funktioner…)
Performance Review
en performance review är där du antingen har identifierat ett problem eller har tilldelats för att undersöka miljön för prestandaproblem att lösa. Jag har ett par Enterprise Manager-miljöer tillgängliga för mig, men jag valde att gå ut till en i synnerhet och korsa fingrarna i hopp om att jag skulle ha lite tung bearbetning för att passa kraven i det här inlägget.
det snabbaste sättet att se arbetsbelastning i din databasmiljö från EM12c, klicka på mål –> databaser. Välj att visa efter lastkarta och du kommer sedan att visa databaser efter arbetsbelastning. När jag gick till en specifik Enterprise Manager-miljö fick jag reda på att det var min lyckodag!
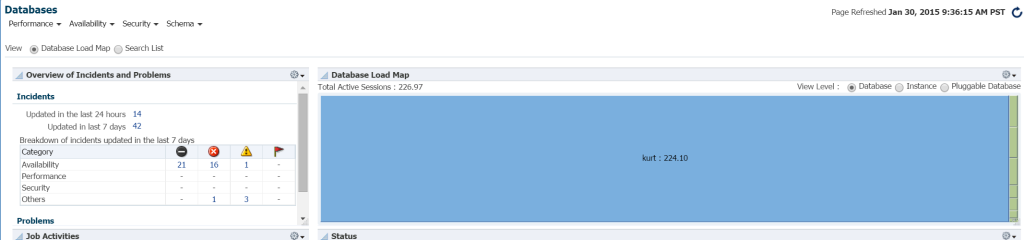 jag vet verkligen inte vem Kurt är som har en databas övervakad på denna EM12c molnkontrollmiljö, men pojke, är han min favorit person idag!
jag vet verkligen inte vem Kurt är som har en databas övervakad på denna EM12c molnkontrollmiljö, men pojke, är han min favorit person idag!
svävar min markör över databasnamnet, (kurt) du kan se arbetsbelastningen han har kört på sin testdatabas för närvarande: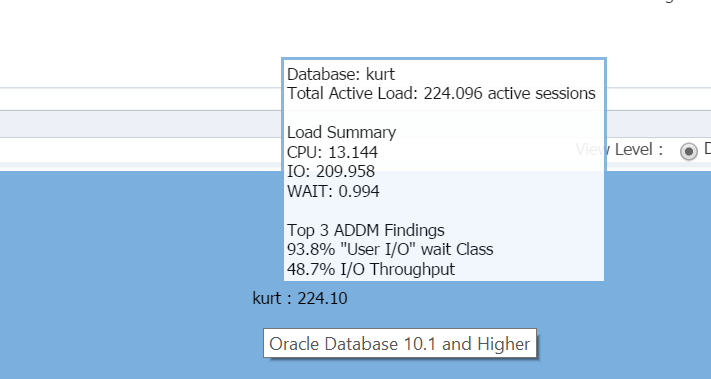
pojke, är Kurt min favorit person idag!
EM12c databasens hemsida
logga in i databasen, jag kan se den betydande Io och resursanvändningen för databasen och värden från databasens hemsida:
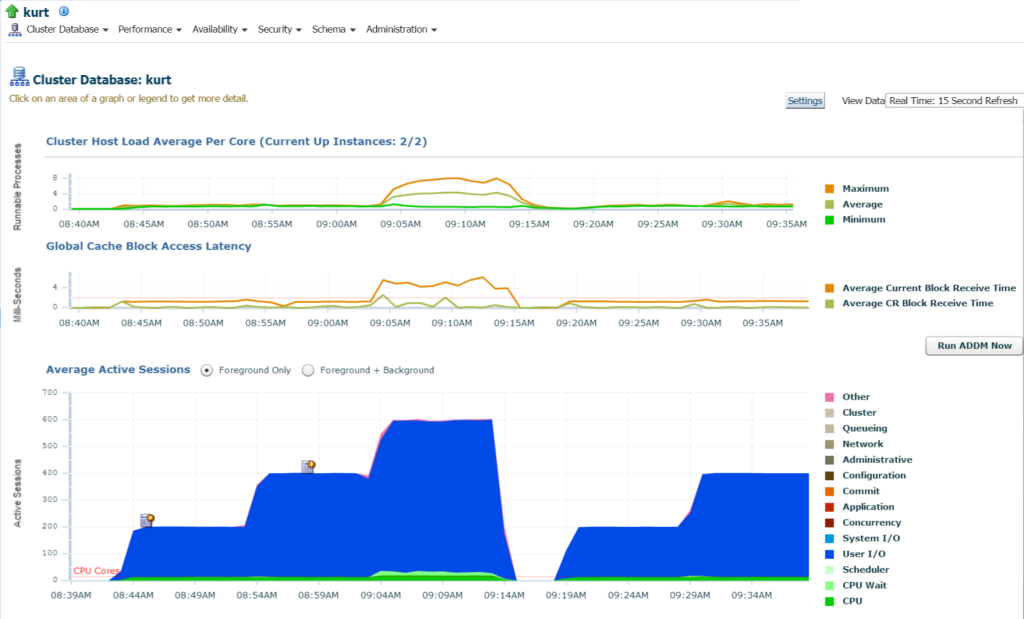
om vi flyttar till toppaktivitet, (Prestationsmeny, toppaktivitet) börjar jag se mer information om bearbetningen och olika väntehändelser:
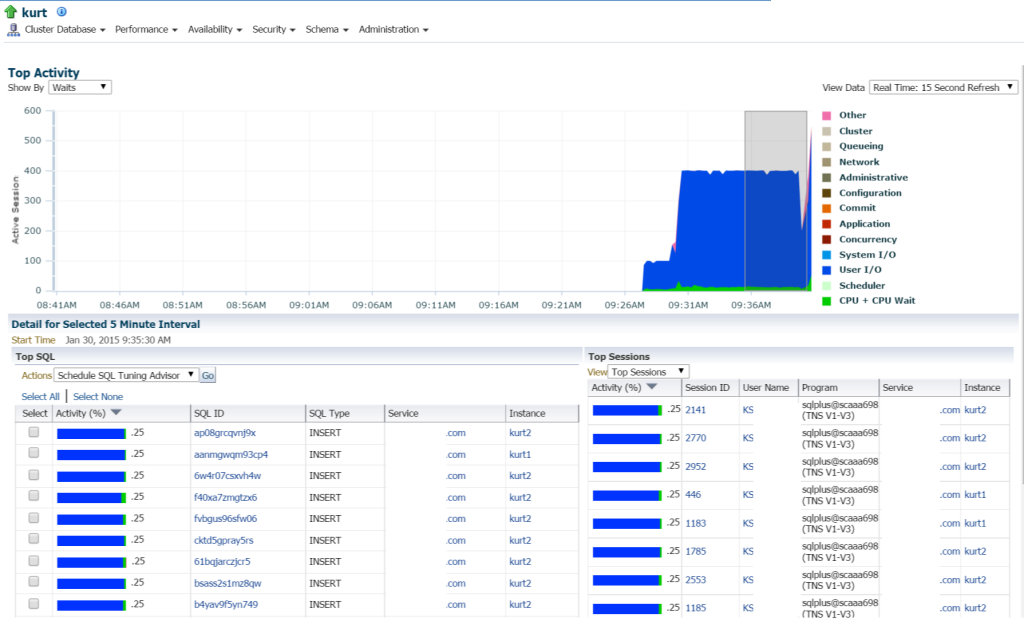
Kurt gör alla typer av insatser, (ses av de olika SQL_IDs, av SQL typ ”infoga”. Jag kan borra ner i de enskilda uttalandena och undersöka detta, men det finns verkligen massor av uttalanden och SQL_ID är här, skulle det inte bara vara lättare att se arbetsbelastningen med en AWR-rapport?
kör AWR-rapporten
jag väljer att klicka på prestanda, AWR, AWR-rapport. Nu har jag ett val. Jag kunde begära en ny ögonblicksbild som ska utföras omedelbart eller jag kunde vänta till toppen av timmen, eftersom intervallet är inställt varje timme i den här databasen. Jag valde den senare för den här demonstrationen, men om du ville skapa en ögonblicksbild omedelbart kan du göra det enkelt från EM12c eller begära en ögonblicksbild genom att utföra följande från SQLPlus med en användare med exekvera privilegier på DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
för det här exemplet väntade jag helt enkelt, eftersom det inte fanns någon brådska eller oro här och begärde rapporten för föregående timme och senaste ögonblicksbild:
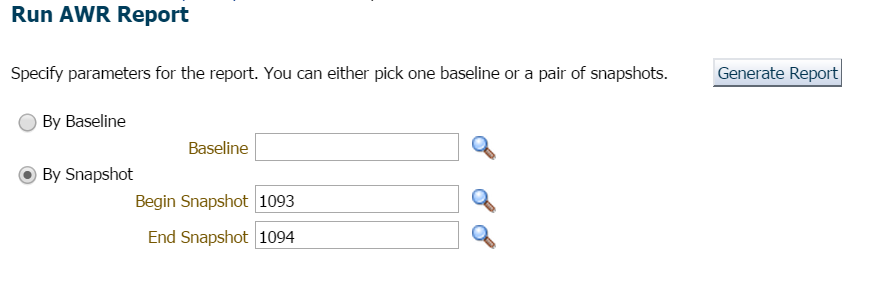
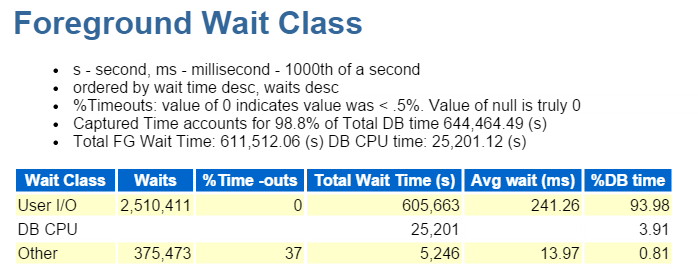
jag börjar alltid på de tio bästa Förgrundshändelserna och tittar ofta på dem med höga vänteprocent:
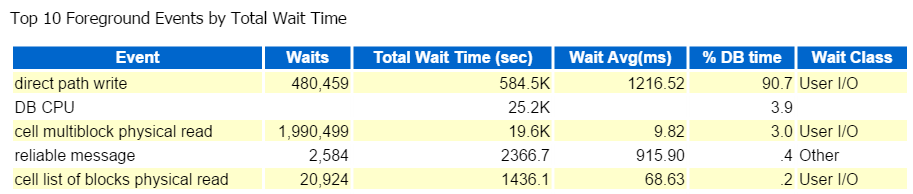
direkt väg skriv, det är det. Inget annat att se här…
direct path write innebär följande: inlägg/uppdateringar, objekt som skrivs till, tabeller skrivs till och de datafiler som utgör tabellutrymmet(erna).
det är också IO, som vi snabbt verifierar ner i förgrunden vänta klassen:
om man tittar på toppen SQL efter förfluten tid bekräftar att vi har att göra med en arbetsbelastning som består av alla insatser:
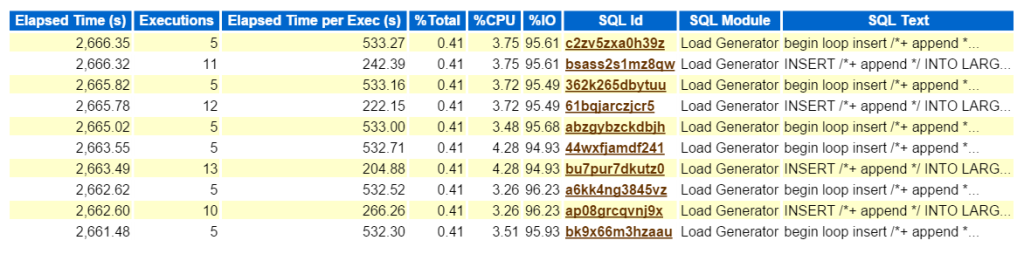
genom att klicka på SQL ID, tar mig till den fullständiga listan över SQL Text och visar mig precis vad Bad Boy Kurt gör för att producera sin testning arbetsbelastning:

Wow, att Kurt är ganska rebell, va? 1878>
sätt i en slinga i ett bord från samma bord, rulla tillbaka och avsluta sedan slingan, tack för att du spelade. Han sparkar några däck och gör det med ångest! Oroa dig inte människor, som jag sa, Kurt gör sitt jobb, med hjälp av en modul som heter ”Load Generator”. Jag skulle vara en dåre att inte känna igen detta som något annat än vad det är – Generera arbetsbelastning för att testa något. Jag får bara den extra fördelen av att ha en arbetsbelastning för att göra ett blogginlägg om att använda AWR-data… exporterade awr-data … om det här var ett verkligt problem och jag försökte ta reda på vad den här typen av prestanda påverkar denna typ av insats skapade på miljön, vart ska man gå nästa i AWR-rapporten? Den översta SQL efter förfluten tid är viktig eftersom det borde vara där du fokuserar dina ansträngningar. Andra avsnitt uppdelade av SQL är trevligt att ha, men kom alltid ihåg, ”om du inte stämmer för tid, slösar du tid.”Ingenting kan komma av en optimeringsövning om inga tidsbesparingar ses efter att du har slutfört arbetet. Så genom att först ta den översta SQL efter förfluten tid och sedan titta på uttalandet kan vi nu se vilka objekt som ingår i uttalandet (large_block149, 191, 194, 145).
vi vet också att problemet är IO, Så vi borde hoppa ner från SQL-detaljerad information och gå till objektnivåinformationen. Dessa avsnitt identifieras av segment av xxx.
- segment efter logiska läsningar
- segment efter fysiska läsningar
- segment efter Läsförfrågningar
- segment efter Tabellskanningar
så vidare och så vidare….
dessa visar alla ett mycket liknande mönster och procentandel för de objekt vi ser i vår topp SQL. Kom ihåg att Kurt läste var och en av dessa tabeller, sedan sätta in samma rader tillbaka i bordet igen och sedan rulla tillbaka. Eftersom det här är ett arbetsbelastningsscenario, till skillnad från de flesta prestandaproblem jag ser, finns det inget enastående objekt som visar med över 10% påverkan i något område.

eftersom det här är en Exadata finns det massor av information som hjälper dig att förstå avlastning, (smarta skanningar) flash-cache etc. det kommer att hjälpa till att vidarebefordra den information du behöver för att se till att du uppnår den prestanda du önskar med ett konstruerat system, men jag skulle vilja spara det för ett annat inlägg och bara röra på några av IO-rapporterna, eftersom vi utförde tabellskanningar, så vi vill se till att de lossades till cellnoderna, (smarta skanningar) vs. utförs på en databasnod.
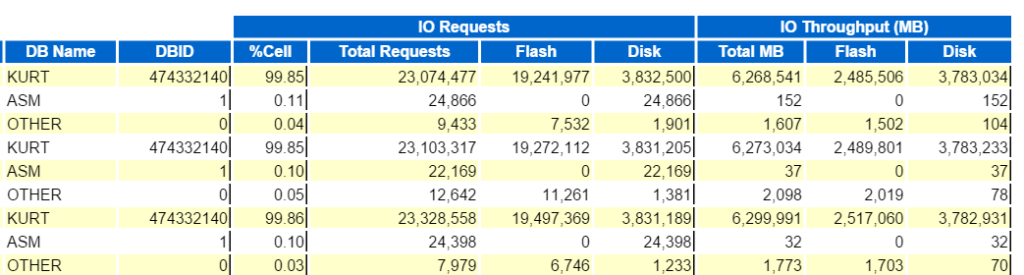
vi kan börja med att titta på Top Database Io genomströmning:

och visa sedan de översta Databasförfrågningarna Per Cellgenomströmning, (sans Cellnodnamnen) för att se hur de jämför: