am avut o cerere recentă de a scrie o actualizare cu privire la lucrul cu AWR rapoarte, așa cum a promis, aici este!
Automatic Workload Repository
Automatic Workload Repository (AWR) a fost una dintre cele mai bune îmbunătățiri aduse Oracle în versiunea 10g. a existat un obiectiv destul de pus în fața grupului de dezvoltare atunci când li s-a cerut să dezvolte un produs care:
1. Cu condiția recomandări semnificative de performanță și așteptați îmbunătățiri de date eveniment peste statspack predecesorul său.
2. A fost întotdeauna pornit, ceea ce înseamnă că datele vor colecta continuu fără intervenția manuală a administratorului bazei de date.
3. Nu ar avea impact asupra procesării curente, având propriile procese de fundal și tampon de memorie, spațiu de masă desemnat (SYSAUX).
4. Memoria tampon ar scrie în direcția opusă față de direcția pe care utilizatorul o Citește, eliminând problemele de concurență.
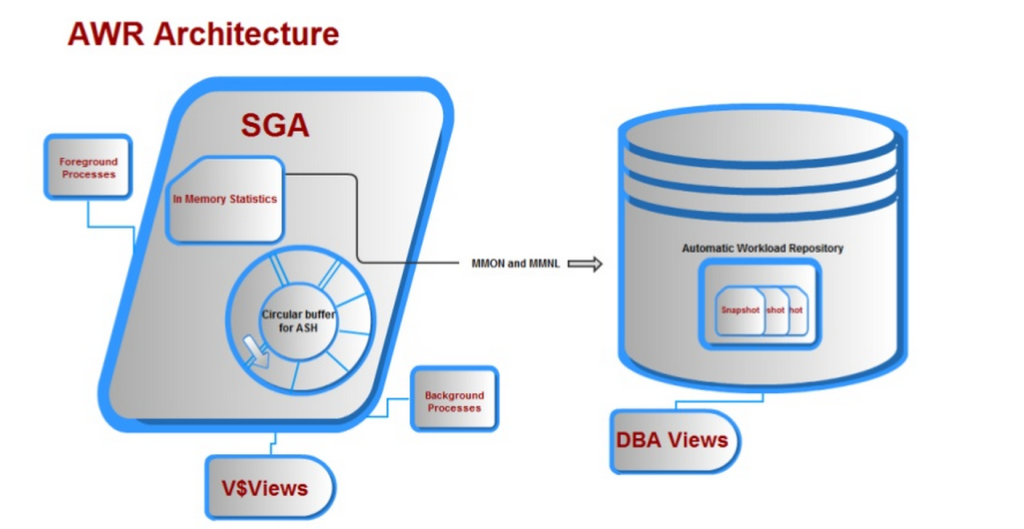
împreună cu multe alte cerințe, toate cele de mai sus au fost oferite cu depozitul automat de încărcare și ajungem la o arhitectură care arată cam așa:
folosind date AWR
datele AWR sunt identificate prin Dbid, (identificatorul bazei de date) și un SNAP_ID, (identificator instantaneu, care are un begin_interval_time și end_interval_time pentru a izola data și ora colectării datelor.) și informații despre ceea ce este păstrat în prezent în baza de date pot fi interogate din DBA_HIST_SNAPSHOT. AWR date conține, de asemenea, cenușă, (Istorie sesiune activă) probe, împreună cu datele instantaneu, în mod implicit, aproximativ 1 din fiecare 10 probe.
scopul utilizării eficiente a datelor AWR are de-a face cu următoarele:
1. Ați identificat o problemă reală de performanță ca parte a unei revizuiri a performanței?
2. A existat o reclamație a utilizatorului sau o solicitare de investigare a unei degradări a performanței?
3. Există o provocare de afaceri sau întrebare care trebuie să se răspundă că AWR poate oferi un răspuns la? (vom merge când să utilizați AWR vs.Alte caracteristici…)
revizuirea performanței
o revizuire a performanței este locul în care fie ați identificat o problemă, fie ați fost atribuit să investigați mediul pentru rezolvarea problemelor de performanță. Am câteva medii de Manager de întreprindere disponibile pentru mine, dar am ales să merg la unul în special și să-mi încrucișez degetele sperând că voi avea o prelucrare grea pentru a se potrivi cerințelor acestui post.
cel mai rapid mod de a vedea volumul de lucru în mediul bazei de date din EM12c, faceți clic pe ținte –> baze de date. Alegeți pentru a vizualiza de încărcare hartă și veți vedea apoi baze de date de volumul de muncă. După ce am mers la un anumit mediu de manager de întreprindere, am aflat că a fost ziua mea norocoasă!
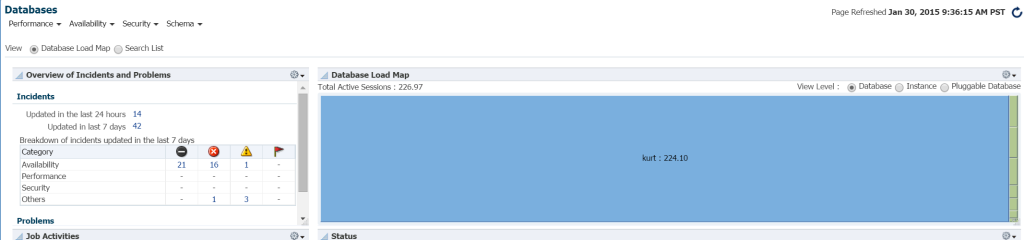 chiar nu știu cine este Kurt care are o bază de date monitorizată pe acest mediu de control Cloud EM12c, dar băiete, este persoana mea preferată astăzi!
chiar nu știu cine este Kurt care are o bază de date monitorizată pe acest mediu de control Cloud EM12c, dar băiete, este persoana mea preferată astăzi!
plasându-mi cursorul peste numele bazei de date, (kurt) puteți vizualiza volumul de lucru pe care îl rulează în baza sa de date de testare în prezent: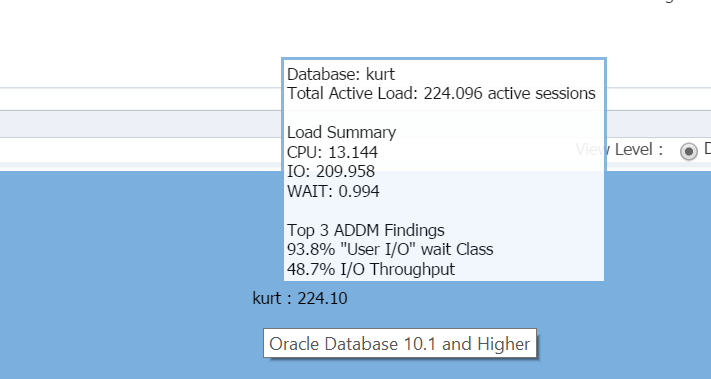
Boy, este Kurt persoana mea preferată astăzi!
pagina principală a bazei de date EM12c
conectarea la baza de date, pot vedea utilizarea semnificativă a IO și a resurselor pentru baza de date și gazdă din pagina principală a bazei de date:
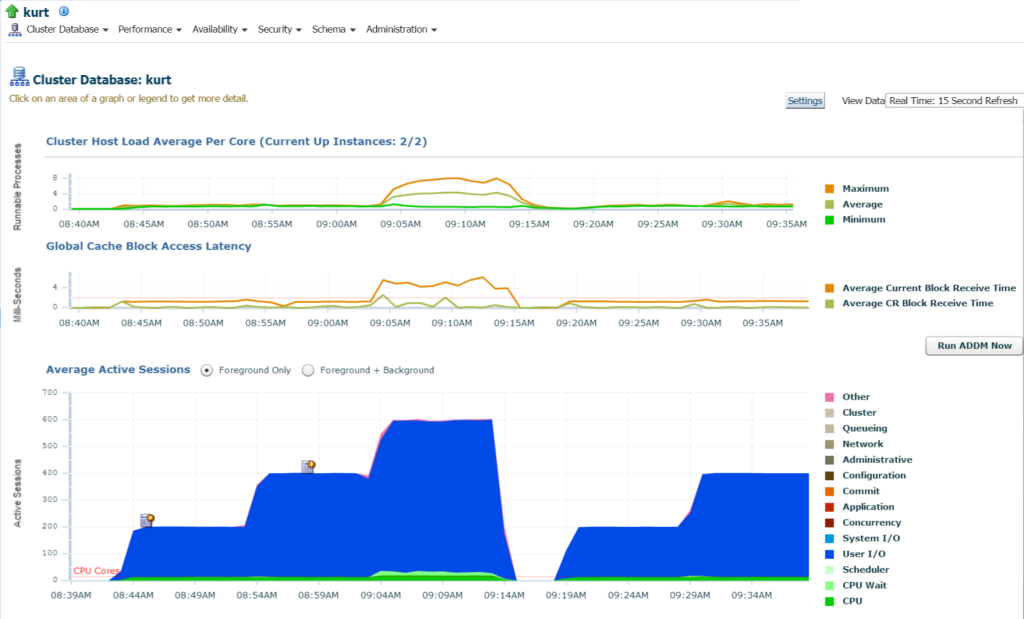
dacă trecem la activitatea de Top, (meniu de performanță, activitate de Top) încep să vizualizez mai multe detalii despre procesare și diferite evenimente de așteptare:
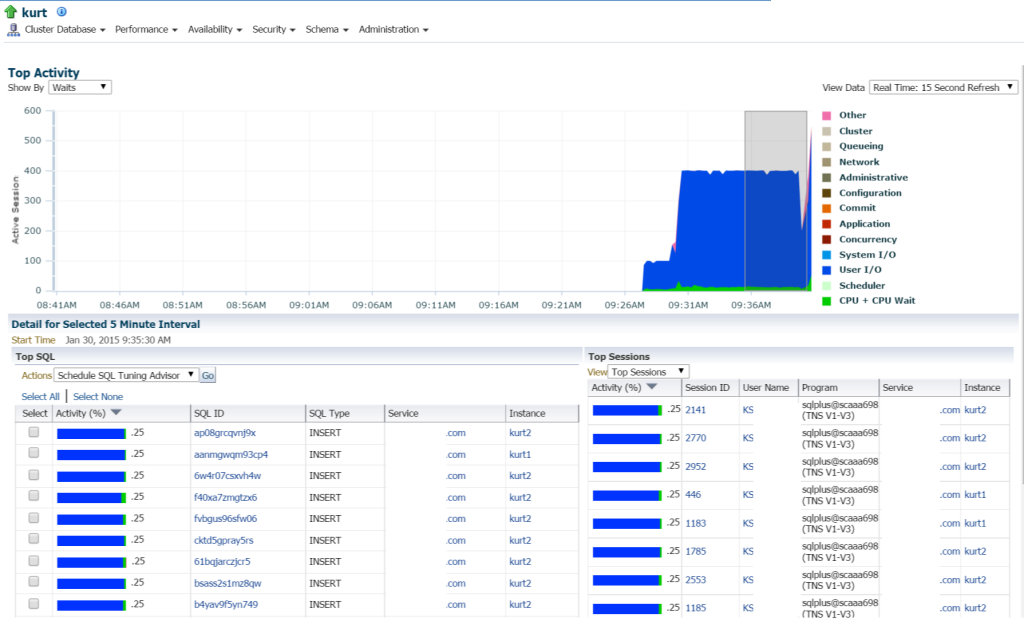
Kurt este de a face tot felul de inserții, (văzut de diferite SQL_IDs, de tip SQL „INSERT”. Pot detalia în declarațiile individuale și investiga acest lucru, dar într-adevăr, există o tona de declarații și SQL_ID aici, nu ar fi doar mai ușor pentru a vizualiza volumul de muncă cu un raport AWR?
rularea raportului AWR
aleg să fac clic pe performanță, AWR, AWR raport. Acum am de ales. Am putea solicita un nou instantaneu pentru a fi efectuate imediat sau am putea aștepta până în partea de sus a orei, ca intervalul este setat pe oră în această bază de date. L-am ales pe acesta din urmă pentru această demonstrație, dar dacă doriți să creați imediat un instantaneu, puteți face acest lucru cu ușurință de la EM12c sau puteți solicita un instantaneu executând următoarele din SQLPlus cu un utilizator cu privilegii de executare pe DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
pentru acest exemplu, am așteptat pur și simplu, deoarece nu a existat nicio grabă sau îngrijorare aici și am solicitat raportul pentru ora anterioară și ultimul instantaneu:
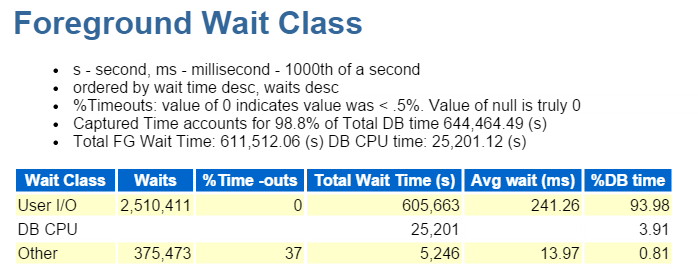
întotdeauna încep de la primele zece evenimente din prim plan și mă uit în mod obișnuit la cele cu procente mari de așteptare:
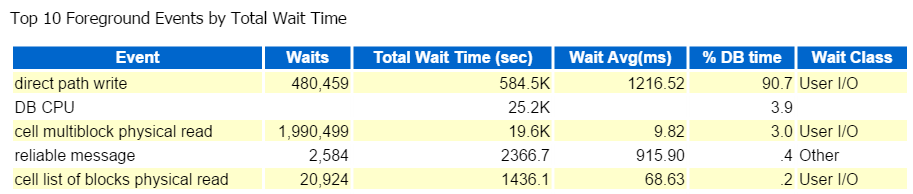
calea directă scrie, asta este. Nimic altceva de văzut aici…
direct path write implică următoarele: inserturi/actualizări, obiecte fiind scrise, spații de tabele fiind scrise și acele fișiere de date care alcătuiesc spațiul de tabele.
este, de asemenea, IO, pe care o verificăm rapid în clasa de așteptare din prim plan:
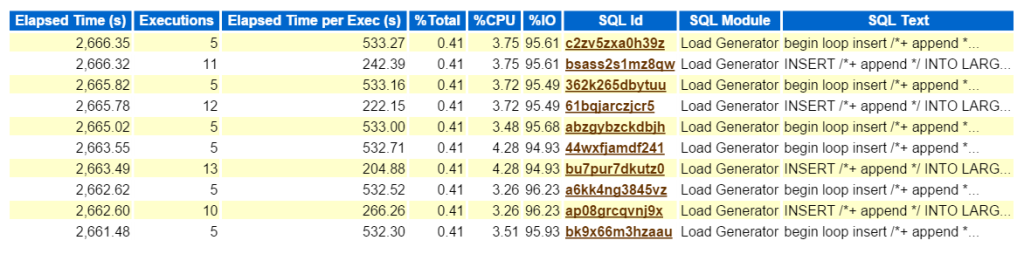
Privind la SQL-ul de sus după timpul scurs confirmă faptul că avem de-a face cu un volum de muncă format din toate inserțiile:
dacă faceți clic pe ID-ul SQL, mă duce la lista completă a textului SQL și îmi arată exact ce face Bad Boy Kurt pentru a-și produce volumul de muncă de testare:

Wow, că Kurt este destul de rebel, nu-i așa?
introduceți într-o buclă într-o singură masă din aceeași masă, rollback și apoi se încheie bucla, Vă mulțumim pentru a juca. Lovește niște cauciucuri și o face cu angoasă! Nu vă faceți griji, cum am spus, Kurt își face treaba, folosind un modul numit”Generator de sarcină”. Aș fi un prost să nu recunosc acest lucru ca altceva decât ceea ce este – generând volumul de muncă pentru a testa ceva. Am doar avantajul suplimentar de a avea un volum de muncă pentru a face o postare pe blog cu privire la utilizarea datelor AWR…
acum, dacă aceasta a fost o problemă reală și am încercat să aflu ce impact acest tip de performanță acest tip de inserție a fost crearea asupra mediului, în cazul în care pentru a merge mai departe în raportul AWR? SQL-ul de top după timpul scurs este important, deoarece ar trebui să fie locul în care vă concentrați eforturile. Alte secțiuni defalcate în funcție de SQL este frumos de a avea, dar amintiți-vă întotdeauna, „dacă nu sunt de tuning pentru timp, pierzi timpul.”Nimic nu poate veni dintr-un exercițiu de optimizare dacă nu se observă economii de timp după ce ați finalizat lucrarea. Deci, luând mai întâi SQL-ul de sus după timpul scurs, apoi uitându-ne la declarație, acum putem vedea ce obiecte fac parte din declarație, (large_block149, 191, 194, 145).
știm, de asemenea, că problema este IO, așa că ar trebui să sari în jos de la SQL informații detaliate și du-te la informațiile de nivel obiect. Aceste secțiuni sunt identificate pe segmente de xxx.
- segmente de citiri logice
- segmente de citiri fizice
- segmente de cereri de citire
- segmente de scanări de tabel
așa mai departe și așa mai departe….
toate acestea arată un model și un procent foarte similar pentru obiectele pe care le vedem în SQL-ul nostru de top. Amintiți-vă, Kurt citea fiecare dintre aceste tabele, apoi introducea aceleași rânduri înapoi în tabel, apoi se rostogolea înapoi. Deoarece acesta este un scenariu de volum de muncă, spre deosebire de majoritatea problemelor de performanță pe care le văd, nu există niciun obiect remarcabil care să arate cu un impact de peste 10% în nicio zonă.

deoarece aceasta este o Exadata, există o mulțime de informații care vă ajută să înțelegeți descărcarea, cache-ul flash (scanări inteligente) etc. acest lucru va ajuta la transmiterea informațiilor de care aveți nevoie pentru a vă asigura că atingeți performanța dorită cu un sistem proiectat, dar aș dori să salvez asta pentru o altă postare și să ating doar câteva dintre rapoartele IO, pe măsură ce efectuam scanări de masă, așa că vrem să ne asigurăm că acestea au fost descărcate în nodurile celulare, (scanări inteligente) vs.fiind efectuate pe un nod de bază de date.
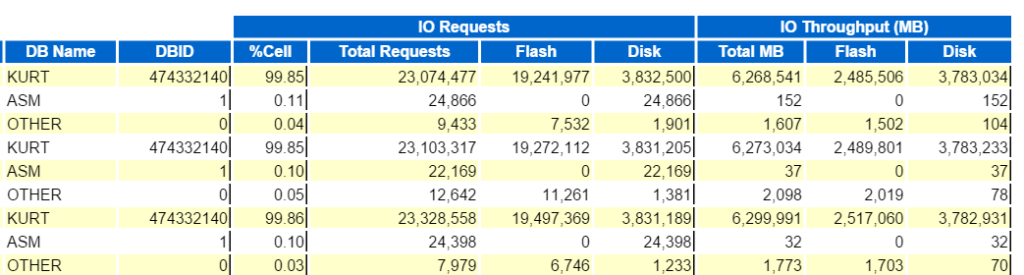
putem începe prin a ne uita la baza de date de top IO tranzitată:

și apoi vizualizați cererile de bază de date de Top pe Transfer de celule, (fără numele nodului de celule) pentru a vedea cum se compară: