I ’ ve had a recent request to write an update on working with AWR reports, so as promised, here it is!
the Automatic Workabase Repository
the Automatic Workabase Repository, (AWR) oli yksi parhaista parannuksista Oraclen takaisin julkaisuun 10g. kehitysryhmän eteen asetettiin aikamoinen tavoite, kun heitä pyydettiin kehittämään tuote, joka:
1. Tarjosi merkittäviä suorituskykysuosituksia ja odota tapahtumatietojen parannuksia edeltäjäänsä statspackiin verrattuna.
2. Oli aina päällä, mikä tarkoittaa, että tiedot keräisivät jatkuvasti ilman manuaalista väliintuloa tietokannan ylläpitäjältä.
3. Ei vaikuttaisi nykyiseen käsittelyyn, jolla on omat taustaprosessit ja Muistipuskuri, nimetty tablespace (SYSAUX).
4. Muistipuskuri kirjoittaisi vastakkaiseen suuntaan vs. suuntaan käyttäjä lukee, poistaa samanaikaisuus kysymyksiä.
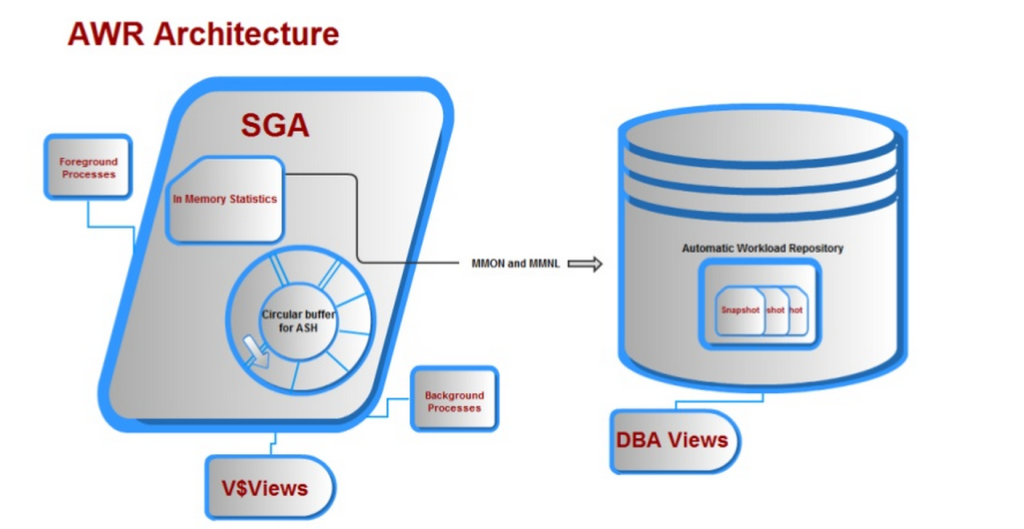
monien muiden vaatimusten ohella kaikki edellä mainitut tarjottiin automaattisella Työmääräarkistolla ja päädyimme arkkitehtuuriin, joka näyttää jotakuinkin tältä:
käyttämällä AWR-tietoja
AWR-tiedot tunnistetaan dbid-tunnisteella (Tietokantatunniste) ja Snapshot-tunnisteella (snapshot identifier), jossa on begin_interval_time ja end_interval_time, joka erittelee tiedonkeruun päivämäärän ja kellonajan.) ja tietoja siitä, mitä tällä hetkellä säilytetään tietokannassa, voidaan tiedustella dba_hist_snapshot-palvelusta. AWR data sisältää myös ASH, (Active Session History) näytteitä sekä tilannekuvan tiedot, oletuksena, noin yksi jokaisesta 10 näytettä.
tavoite AWR-datan tehokkaaseen käyttöön liittyy oikeastaan seuraaviin:
1. Oletko tunnistanut todellisen suorituskykyyn liittyvän ongelman osana suorituskyvyn tarkastelua?
2. Onko käyttäjä valittanut tai pyytänyt tutkimaan suorituskyvyn heikkenemistä?
3. Onko liiketoiminnan haaste tai kysymys, joka on vastattava, että AWR voi tarjota vastauksen? (menemme milloin käyttää AWR vs. muut ominaisuudet…)
Suorituskykyarvio
suorituskykyarvio on, jossa olet joko tunnistanut ongelman tai sinut on määrätty tutkimaan ympäristöä suorituskykyongelmien ratkaisemiseksi. Minulla on pari Enterprise Manager ympäristöissä käytettävissäni,mutta päätin mennä ulos yksi erityisesti ja risti sormeni toivoen minulla olisi raskas käsittely sopivaksi tämän postitse.
nopein tapa nähdä työmäärä tietokantaympäristössä em12c: stä, klikkaa Targets –> Databases. Valitse tarkastella kuormituskartan ja voit sitten tarkastella tietokantoja työmäärän. Kun menin tiettyyn Yritysjohtajaympäristöön, huomasin, että se oli onnenpäiväni!
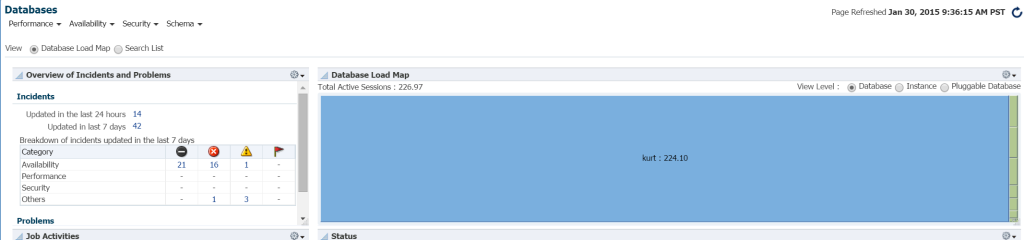 I really don ’ t know who Kurt is that has a database monitored on this EM12c cloud control environment, but boy, is he is my favorite person today! 🙂
I really don ’ t know who Kurt is that has a database monitored on this EM12c cloud control environment, but boy, is he is my favorite person today! 🙂
kursorin leijuminen tietokannan nimen yllä, (kurt) voit tarkastella hänen testitietokannassaan tällä hetkellä käynnissä olevaa työmäärää: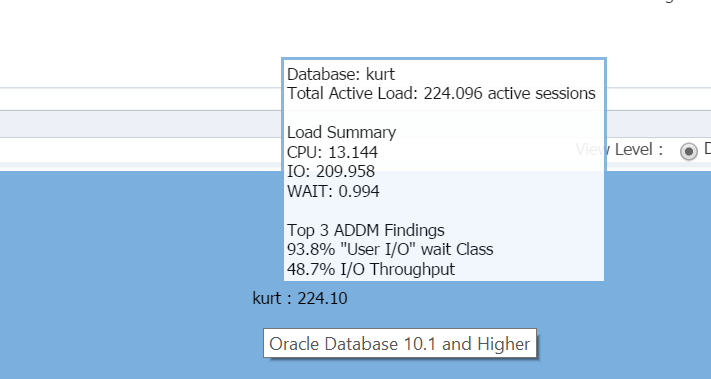
onpa Kurt lempi – ihmiseni tänään!
EM12c-tietokannan Kotisivu
kirjautumalla tietokantaan näen tietokannan ja isännän merkittävän IO: n ja resurssien käytön tietokannan kotisivulta:
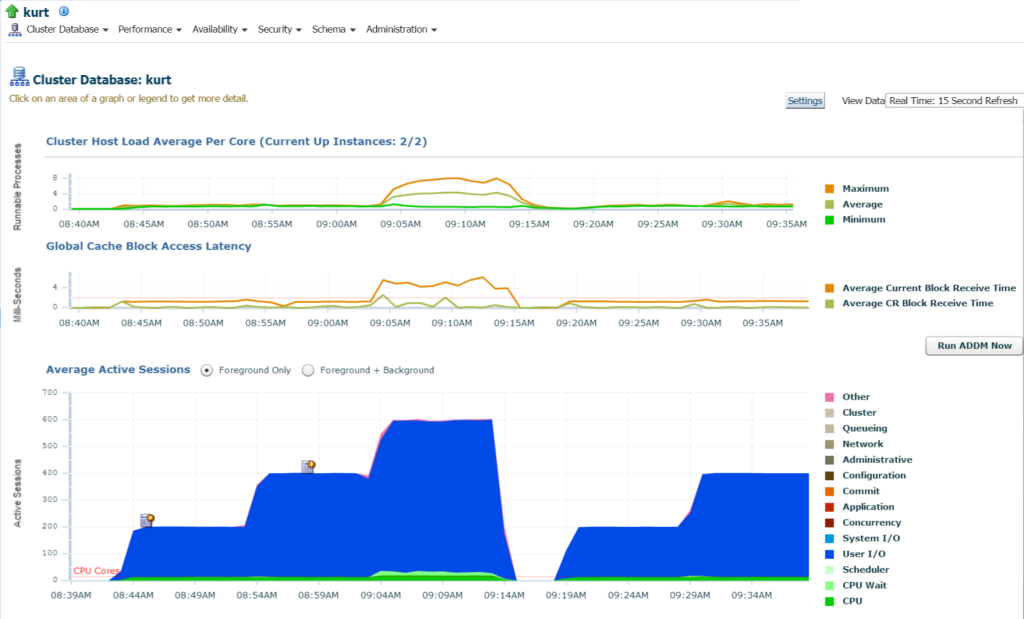
jos siirrymme Top Activity, (suorituskyky valikko, Top Activity) alan tarkastella lisätietoja käsittely ja eri odottaa tapahtumia:
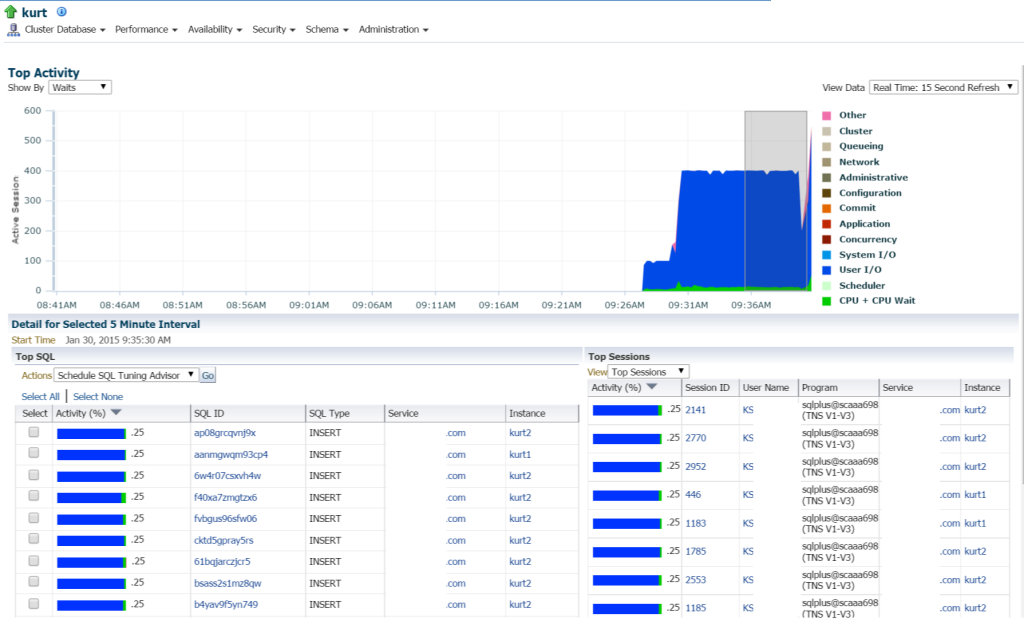
Kurt tekee kaikenlaisia inserttejä, (eri SQL_IDs, SQL-tyypin ”INSERT”mukaan. Voin porata alas yksittäisiä lausuntoja ja tutkia tätä, mutta todella, on TON lausuntoja ja SQL_ID on täällä, eikö se vain olisi helpompi tarkastella työmäärä AWR raportti?
Running the AWR Report
I choose to click on Performance, AWR, AWR Report. Nyt minulla on vaihtoehto. Voisin pyytää uuden tilannekuvan suoritettavaksi välittömästi tai voisin odottaa tunnin alkuun asti, sillä väli on asetettu tunneittain tässä tietokannassa. Valitsin jälkimmäisen tämän esittelyn, mutta jos haluat luoda tilannekuvan välittömästi, voit tehdä tämän helposti EM12c tai pyytää tilannekuvan suorittamalla seuraavat sqlplus käyttäjän kanssa suorittaa oikeudet dbms_workload_repository:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
tätä esimerkkiä varten minä vain odotin, koska täällä ei ollut kiirettä tai huolta ja pyysin raporttia edellisestä Tunnista ja viimeisimmästä tilannekuvasta.:
aloitan aina kärkikymmeniköstä etualan tapahtumista ja katson yleisesti niitä, joilla on korkeat odotusprosentit:
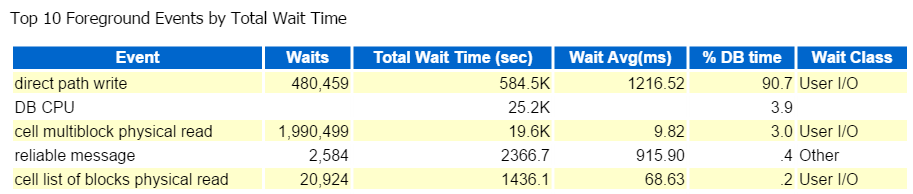
suora polku, siinä kaikki. Tässä ei ole mitään muuta nähtävää… 🙂
suora polku-kirjoitus sisältää seuraavat tiedot: Lisää/päivitä, objektit kirjoitetaan, taulukkotilat kirjoitetaan ja ne datafileet, jotka muodostavat taulukkotilat.
se on myös IO, jonka varmistamme nopeasti alas etualalla Odotusluokassa:
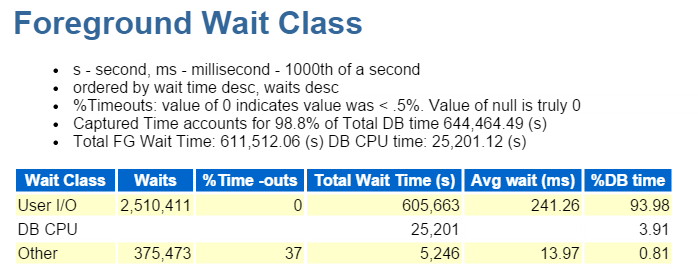
katsomalla alkuun SQL kulunut aika vahvistaa, että olemme tekemisissä työmäärä koostuu kaikista insertit:
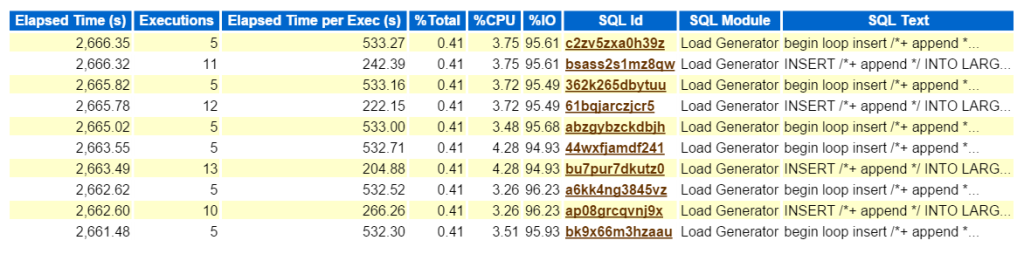
klikkaamalla SQL ID, vie minut täydellinen luettelo SQL tekstiä ja näyttää minulle, mitä Bad Boy Kurt tekee tuottaa hänen testaus työmäärä:

Kurt on aikamoinen kapinallinen. 🙂
aseta silmukka samaan pöytään samasta pöydästä, Kelaa taaksepäin ja päätä sitten silmukka, kiitos soitosta. Hän potkii renkaita ja tekee sitä angstilla! Älkää huoliko, kuten sanoin, Kurt tekee työtään käyttäen moduulia nimeltä ”Load Generator”. Olisin hölmö, jos en tunnistaisi tätä muuksi kuin mitä se on-työmäärää jonkin testaamiseen. Saan vain lisäetuna ottaa työmäärä tehdä blogikirjoitus käyttämällä AWR tietoja … 🙂
nyt, jos tämä oli todellinen ongelma ja yritin selvittää, mitä tämän tyyppinen suorituskyky vaikutus tämäntyyppisen insertin oli luomassa ympäristöön, minne mennä seuraavaksi AWR raportti? Top SQL kulunut aika on tärkeää, koska sen pitäisi olla, jos keskityt ponnisteluja. Muut osiot jaoteltu SQL on mukava olla, mutta aina muistaa, ”Jos et tuning aikaa, olet tuhlaa aikaa.”Optimointiharjoituksesta ei voi tulla mitään, jos työn valmistumisen jälkeen ei nähdä ajansäästöä. Joten ottamalla ensin alkuun SQL kulunut aika, sitten tarkastelemalla lausuma, voimme nyt nähdä, mitä esineitä ovat osa lausuman, (large_block149, 191, 194, 145).
tiedämme myös, että ongelma on IO, joten meidän pitäisi hypätä alas SQL yksityiskohtaista tietoa ja mennä objektitason tietoa. Nämä osiot yksilöidään osioittain xxx: n mukaan.
- loogisten lukujen mukaiset segmentit
- fyysisten lukujen mukaiset segmentit
- Lukupyyntöjen mukaiset segmentit
- Taulukkokannausten mukaiset segmentit
niin edelleen ja niin edelleen….
näissä kaikissa näkyy hyvin samanlainen kuvio ja prosenttiosuus niistä kohteista, joita näemme ylimmässä SQL: ssämme. Muista, että Kurt luki jokaisen näistä pöydistä, – laittoi samat rivit takaisin pöytään ja kierähti sitten takaisin. Koska tämä on työmäärä skenaario, toisin kuin useimmat suorituskykyä kysymyksiä näen, ei ole erinomainen kohde näyttää yli 10% vaikutus millään alueella.

koska tämä on Exadata, on ton tietoja, joiden avulla voit ymmärtää purku, (smart skannaa)flash cache, jne. se auttaa välittämään tiedot, joita tarvitset varmistaaksesi, että saavutat haluamasi suorituskyvyn suunnitellulla järjestelmällä, mutta haluaisin tallentaa sen toiseen viestiin ja vain koskettaa muutamaa IO-raporttia, koska suoritimme taulukon skannauksia, joten haluamme varmistaa, että ne purettiin solusolmuihin, (smart Scan) vs. suoritetaan tietokantasolmussa.
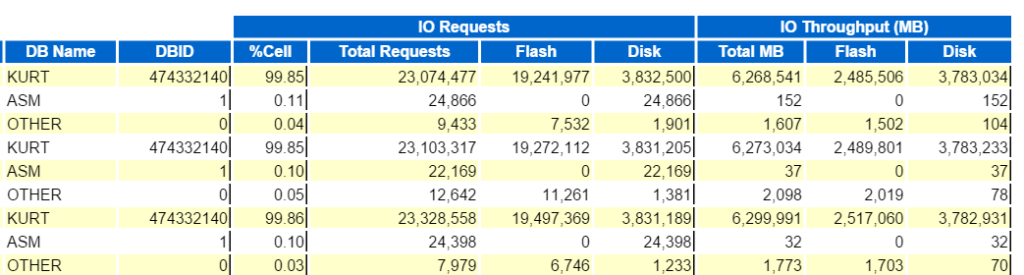
voimme aloittaa katsomalla tietokannan ylintä IO-läpimenoa:

ja sitten tarkastella alkuun tietokannan pyyntöjä per solu läpimeno, (sans Solusolmun nimet) nähdä, miten he vertaavat: