ik heb een recent verzoek gehad om een update te schrijven over werken met AWR rapporten, dus zoals beloofd, hier is het!
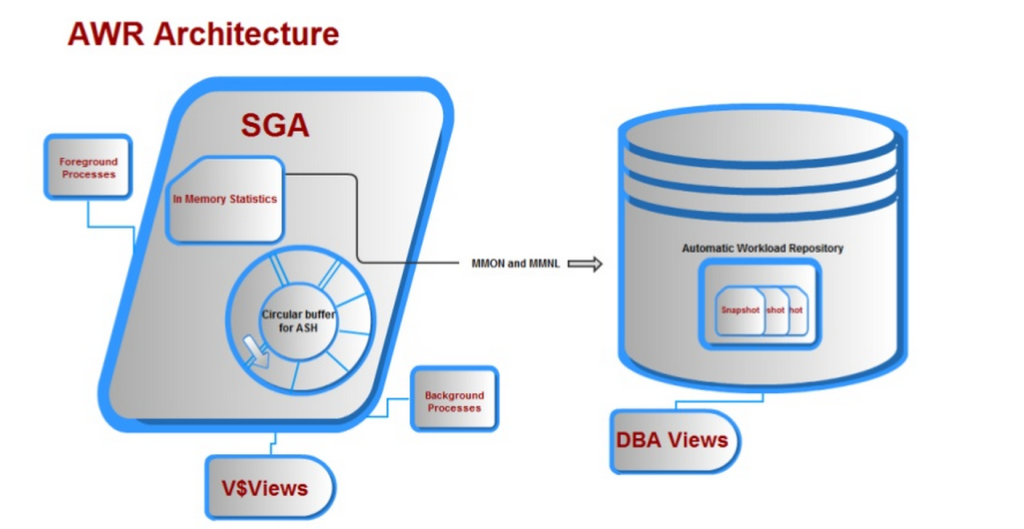
the Automatic Workload Repository
the Automatic Workload Repository, (AWR) was een van de beste verbeteringen aan Oracle in release 10g. er werd een behoorlijk doel voor de ontwikkelingsgroep gesteld toen hen werd gevraagd een product te ontwikkelen dat:
1. Op voorwaarde dat significante prestatieaanbevelingen en wacht event data verbeteringen ten opzichte van zijn voorganger statspack.
2. Was altijd aan, wat betekent dat de gegevens continu zouden verzamelen zonder handmatige tussenkomst van de beheerder van de database.
3. Zou geen invloed hebben op de huidige verwerking, met zijn eigen achtergrond processen en geheugen buffer, aangewezen tablespace, (SYSAUX).
4. De geheugenbuffer zou schrijven in de tegenovergestelde richting vs. richting de gebruiker leest, waardoor concurrency problemen.
samen met vele andere vereisten werd al het bovenstaande aangeboden met de Automatic Workload Repository en we eindigen met architectuur die er ongeveer zo uitziet:
met behulp van AWR-gegevens
worden de AWR-gegevens geïdentificeerd door de DBID (Database-Identifier) en een SNAP_ID (snapshot-identifier), die een begin_interval_time en end_interval_time heeft om de datum en tijd van de gegevensverzameling te isoleren.) en informatie over wat momenteel wordt bewaard in de database kan worden opgevraagd via de DBA_HIST_SNAPSHOT. AWR gegevens bevatten ook ASH, (actieve Sessiegeschiedenis) monsters samen met de snapshot gegevens, standaard, ongeveer 1 op elke 10 monsters.
het doel om AWR-gegevens effectief te gebruiken heeft echt te maken met het volgende::
1. Heb je een echt prestatieprobleem geïdentificeerd als onderdeel van een prestatiebeoordeling?
2. Is er een klacht van de gebruiker of een verzoek om een prestatievermindering te onderzoeken?
3. Is er een zakelijke uitdaging of vraag die beantwoord moet worden waarop AWR een antwoord kan bieden? (we zullen gaan wanneer AWR vs.andere functies te gebruiken…)
Performance Review
een performance review is waar je ofwel een probleem hebt geïdentificeerd of bent toegewezen om de omgeving te onderzoeken voor performance problemen op te lossen. Ik heb een paar Enterprise Manager omgevingen beschikbaar voor mij, maar ik koos ervoor om uit te gaan naar een in het bijzonder en kruis mijn vingers in de hoop dat ik zou hebben een aantal zware verwerking aan de eisen van deze post passen.
de snelste manier om werkbelasting in uw database omgeving te zien vanuit EM12c, klik op Targets – > Databases. Kies om te bekijken op load map en u zult dan databases bekijken op workload. Bij het gaan naar een specifieke Enterprise Manager omgeving, ik ontdekte dat het was mijn geluksdag!
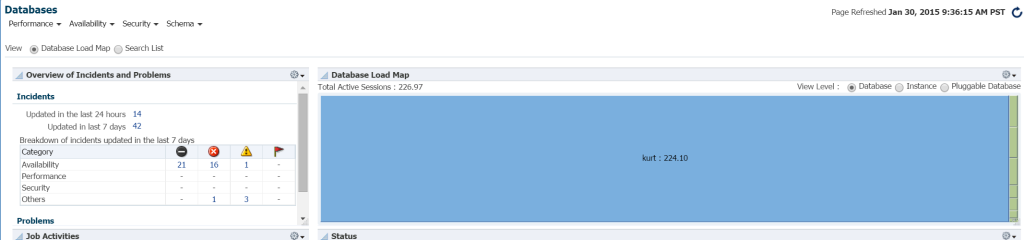 ik weet echt niet wie Kurt is die een database heeft gemonitord op deze EM12c cloud control omgeving, maar tjonge, is hij mijn favoriete persoon vandaag! 🙂
ik weet echt niet wie Kurt is die een database heeft gemonitord op deze EM12c cloud control omgeving, maar tjonge, is hij mijn favoriete persoon vandaag! 🙂
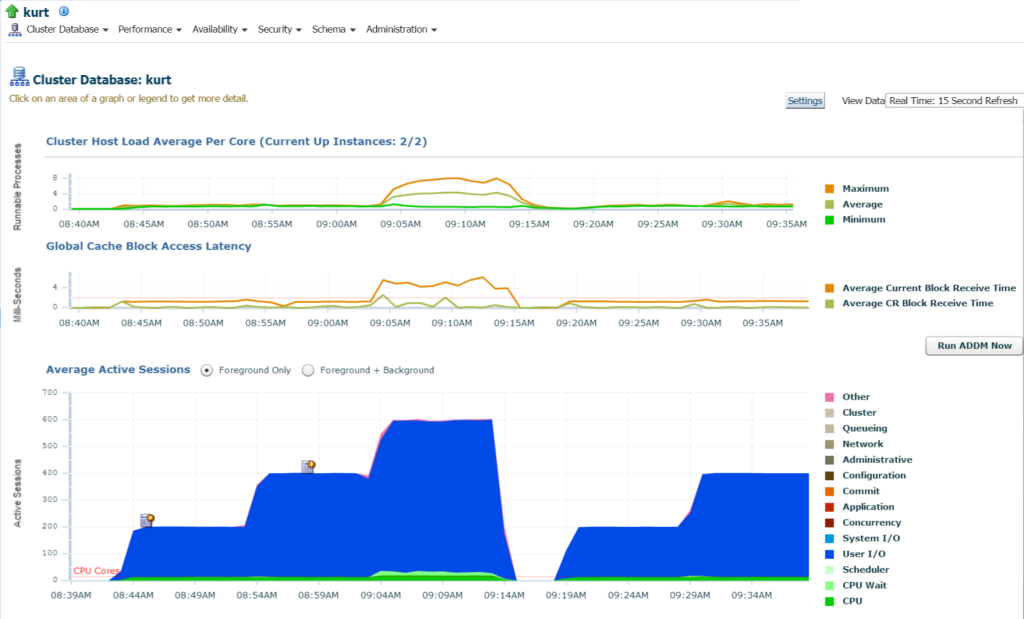
met mijn cursor boven de naam van de database, (kurt) kunt u de werkbelasting die hij heeft lopen op zijn testdatabase op dit moment bekijken: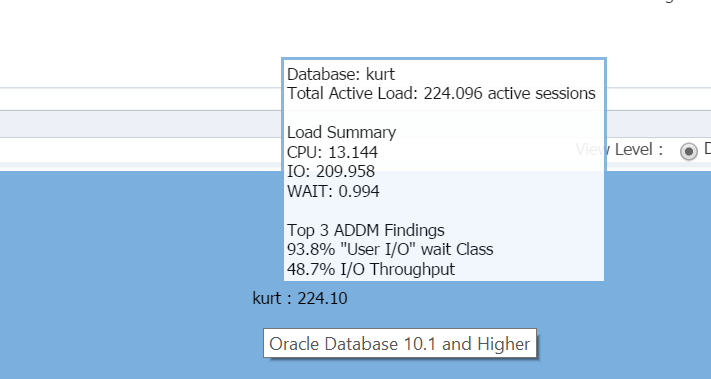
jongen, Kurt is mijn favoriete persoon vandaag!
EM12c Database Home Page
inloggen op de database, kan ik de significante IO en resource gebruik voor de database en host van de database home page:
als we naar Top activiteit gaan (Performance menu, Top activiteit) begin ik meer details te bekijken over de verwerking en verschillende wachtgebeurtenissen:
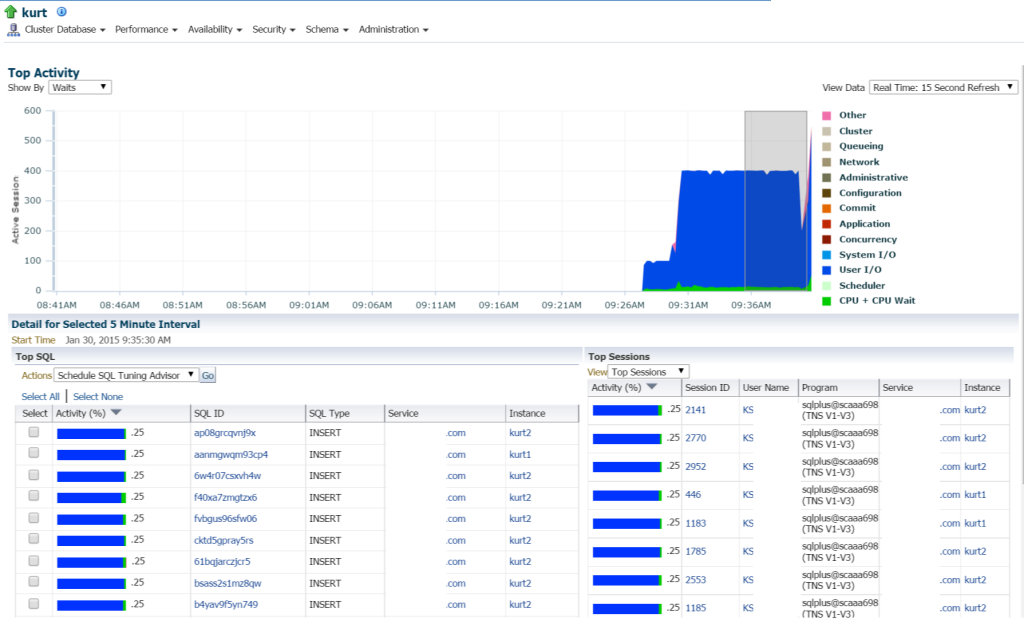
Kurt doet allerlei inserts, (gezien door de verschillende SQL_IDs, door SQL Type “INSERT”. Ik kan dieper ingaan op de individuele verklaringen en dit onderzoeken, maar echt, er zijn een TON van verklaringen en SQL_ID ‘ s hier, zou het niet gewoon makkelijker zijn om de werkdruk te bekijken met een AWR rapport?
bij het uitvoeren van het AWR-rapport
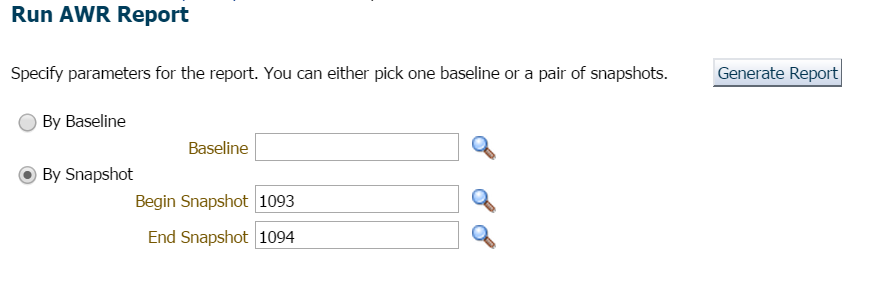
kies ik om te klikken op Performance, AWR, AWR-rapport. Nu heb ik een keuze. Ik zou kunnen vragen om een nieuwe snapshot onmiddellijk uitgevoerd te worden of ik zou kunnen wachten tot de top van het uur, omdat het interval per uur is ingesteld in deze database. Ik koos voor de laatste voor deze demonstratie, maar als je direct een snapshot wilt maken, kun je dit eenvoudig doen vanuit EM12c of een snapshot aanvragen door het volgende uit te voeren vanuit SQLPlus met een gebruiker met uitvoerrechten op de DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
voor dit voorbeeld heb ik gewoon gewacht, Want er was geen haast of bezorgdheid hier en verzocht om het verslag van het vorige uur en de laatste snapshot:
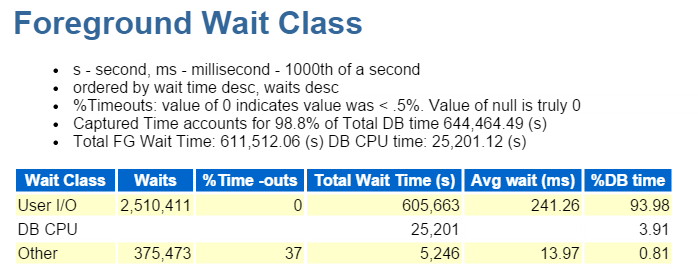
ik begin altijd bij de top tien Voorgrondgebeurtenissen en kijk vaak naar die met hoge wachtpercentages:
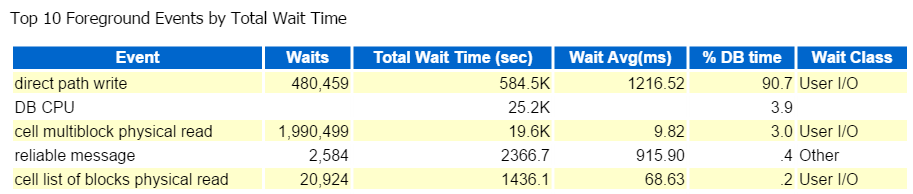
Direct pad schrijven, dat is het. Niets anders om hier te zien… 🙂
Direct path write omvat het volgende: inserts/updates, objecten worden geschreven, tablespaces worden geschreven en die databestanden die deel uitmaken van de tablespace(s).
het is ook IO, die we snel controleren op de voorgrond wacht Klasse:
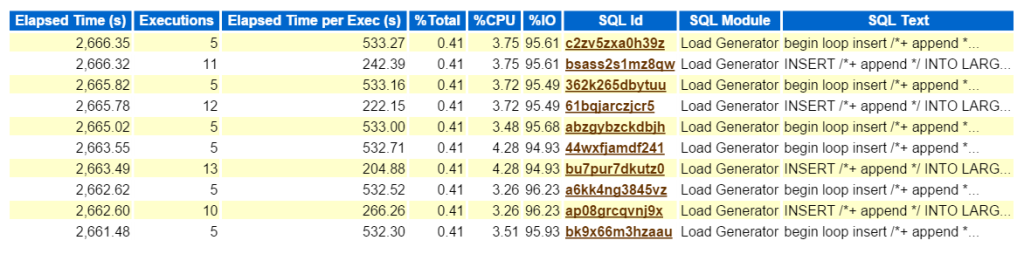
kijkend naar de bovenste SQL door verstreken tijd bevestigt dat we te maken hebben met een workload die bestaat uit alle inserts:
klikken op de SQL ID, neemt me mee naar de volledige lijst van SQL tekst en laat me zien wat Bad Boy Kurt doet om zijn test werklast te produceren:

die Kurt is nogal een rebel, hè? 🙂
plaats in een lus in een tabel van dezelfde tafel, draai terug en beëindig de lus, bedankt voor het spelen. Hij schopt wat banden en doet het met angst! Maak je geen zorgen mensen, zoals ik al zei, Kurt doet zijn werk, met behulp van een module genaamd “Load Generator”. Ik zou gek zijn om dit niet te herkennen als iets anders dan wat het is – het genereren van werkbelasting om iets te testen. Ik krijg gewoon het extra voordeel van het hebben van een werklast om een blogpost te doen over het gebruik van AWR-gegevens… 🙂
nu, als dit een echt probleem was en ik probeerde uit te vinden wat dit soort prestaties impact dit type insert creëerde op het milieu, waar te gaan volgende in het AWR-rapport? De top SQL door verstreken tijd is belangrijk als het zou moeten zijn waar u uw inspanningen richten. Andere secties opgesplitst door SQL is leuk om te hebben, maar onthoud altijd: “als je niet op tijd stemt, verspil je tijd.”Er kan niets van een optimalisatieoefening komen als er geen tijdwinst wordt gezien nadat u het werk hebt voltooid. Dus door eerst de bovenste SQL te nemen door de verstreken tijd, dan te kijken naar het statement, kunnen we nu zien welke objecten deel uitmaken van het statement, (large_block149, 191, 194, 145).
we weten ook dat het probleem IO is, dus moeten we van de SQL gedetailleerde informatie springen en naar de informatie op objectniveau gaan. Deze secties worden geïdentificeerd door segmenten door xxx.
- segmenten volgens logische Reads
- segmenten volgens fysieke Reads
- segmenten volgens Leesverzoeken
- segmenten volgens tabel Scans
enzovoort….
deze tonen allemaal een zeer vergelijkbaar patroon en percentage voor de objecten die we zien in onze bovenste SQL. Weet je nog, Kurt was elk van deze tafels aan het lezen, en voegde dezelfde rijen weer in de tafel, en rolde dan terug. Aangezien dit een workload scenario is, in tegenstelling tot de meeste prestatieproblemen die ik zie, is er geen uitstekend object met een impact van meer dan 10% op enig gebied.

aangezien dit een Exadata is, is er een ton van informatie om u te helpen het lossen te begrijpen, (smart scans) flash cache, enz. dat zal helpen bij het doorgeven van de informatie die u nodig hebt om ervoor te zorgen dat u het bereiken van de prestaties die u wenst met een ontworpen systeem, maar Ik wil dat opslaan voor een andere post en gewoon aanraken op een paar van de io-rapporten, als we het uitvoeren van tabel scans, dus we willen ervoor zorgen dat die werden offload naar de celknooppunten, (smart scans) vs.wordt uitgevoerd op een database-knooppunt.
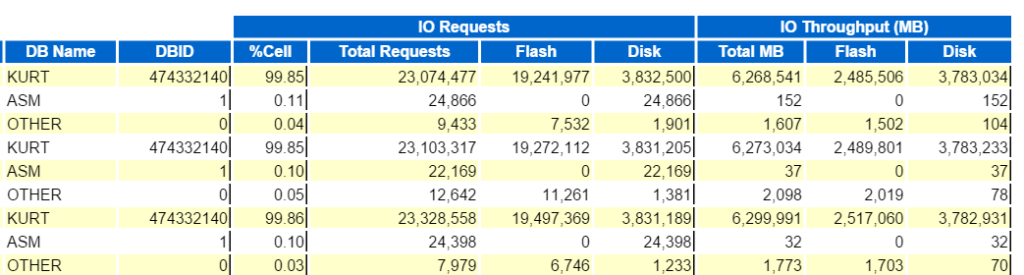
we kunnen beginnen door te kijken naar de hoogste Database Io doorvoer:

en bekijk vervolgens de bovenste Databaseverzoeken Per Celdoorvoer (zonder de namen van de Celknooppunten) om te zien hoe ze zich vergelijken: