jeg har nylig hatt en forespørsel om å skrive en oppdatering om å jobbe med AWR-rapporter, så som lovet, her er det!
The Automatic Workload Repository
The Automatic Workload Repository, (AWR) var en Av De beste forbedringene Til Oracle tilbake i utgivelse 10g. Det var ganske et mål satt foran utviklingsgruppen da de ble bedt om å utvikle et produkt som:
1. Gitt betydelig ytelse anbefaling og vente hendelsen data forbedringer over forgjengeren statspack.
2. Var alltid på, noe som betyr at dataene ville kontinuerlig samle uten manuell inngripen fra databaseadministratoren.
3. Ville ikke påvirke dagens behandling, har sine egne bakgrunnsprosesser og minnebuffer, utpekt tabellplass, (SYSAUX).
4. Minnebufferen ville skrive i motsatt retning vs. retning brukeren leser, eliminere samtidighetsproblemer.
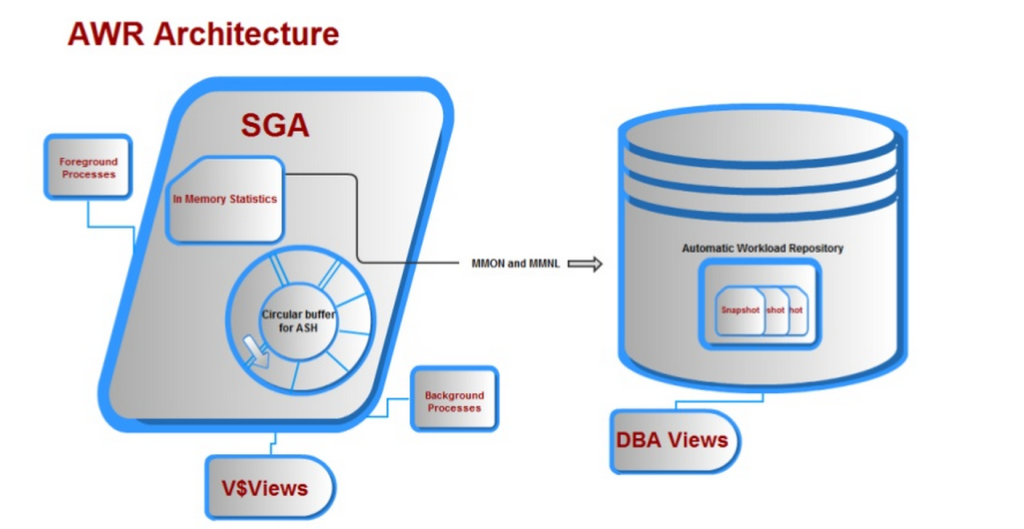
sammen med mange andre krav ble alt ovenfor tilbudt Med Det Automatiske Arbeidsbelastningsregisteret, og vi ender opp med arkitektur som ser noe ut som dette:
VED HJELP AV AWR-Data
IDENTIFISERES AWR-dataene av Dbid (Databaseidentifikator) og EN SNAP_ID (snapshot identifier, som har en begin_interval_time og end_interval_time for å isolere dato og klokkeslett for datainnsamlingen.) og informasjon om hva som for tiden beholdes i databasen, kan spørres fra DBA_HIST_SNAPSHOT. AWR data inneholder OGSÅ ASH, (Aktiv Session History) prøver sammen med snapshot data, som standard, ca 1 av hver 10 prøver.
målet om å bruke AWR-data effektivt har virkelig å gjøre med følgende:
1. Har du identifisert et ekte ytelsesproblem som en del av en ytelsesvurdering?
2. Har det vært en brukerklage eller en forespørsel om å undersøke en ytelsesforringelse?
3. Er det en forretningsutfordring eller spørsmål SOM MÅ besvares SOM AWR kan tilby svar på? (vi går når DU skal bruke AWR vs andre funksjoner…)
Ytelsesgjennomgang
en ytelsesgjennomgang er der du enten har identifisert et problem eller har blitt tildelt for å undersøke miljøet for ytelsesproblemer å løse. Jeg har et Par Enterprise Manager miljøer tilgjengelig for meg, men jeg valgte å gå ut til en spesielt og krysse fingrene i håp om at jeg ville ha litt tung behandling for å passe kravene i dette innlegget.
den raskeste måten å se arbeidsmengden i databasemiljøet Fra EM12c, klikk På Mål –> Databaser. Velg å vise etter last kart, og du vil da vise databaser etter arbeidsbelastning. Ved å gå til en Bestemt Enterprise Manager miljø, jeg fant ut at det var min lykkedag!
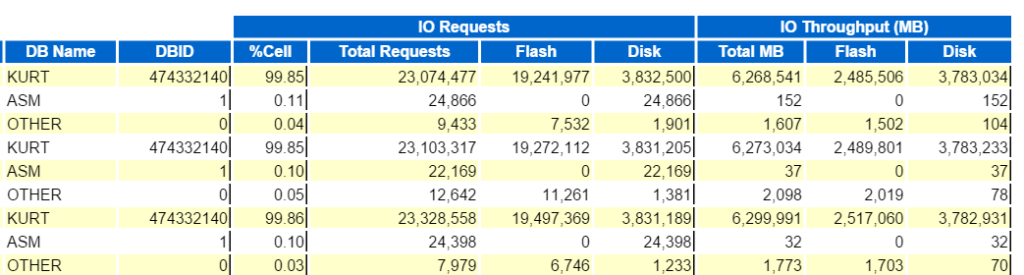
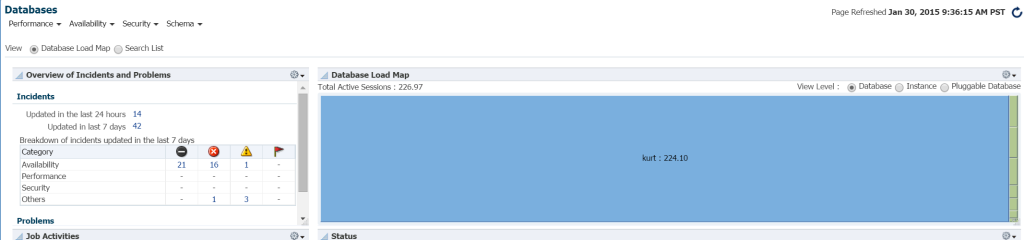 Jeg vet egentlig ikke hvem Kurt Er som har en database overvåket på Dette EM12c cloud control-miljøet, men gutt, er han min favoritt person i dag! 🙂
Jeg vet egentlig ikke hvem Kurt Er som har en database overvåket på Dette EM12c cloud control-miljøet, men gutt, er han min favoritt person i dag! 🙂
Svever markøren over databasenavnet, (kurt) du kan se arbeidsbelastningen han har kjørt på sin testdatabase for øyeblikket: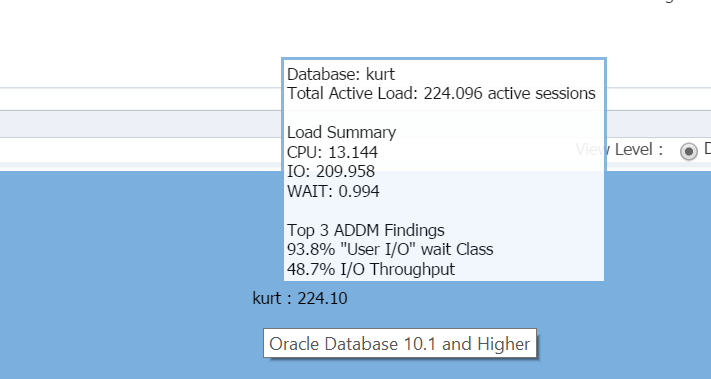
Gutt, Er Kurt min favoritt person i dag!
EM12c Database Hjemmeside
Logge inn i databasen, kan jeg se betydelig IO og ressursbruk for databasen og verten fra databasen hjemmesiden:
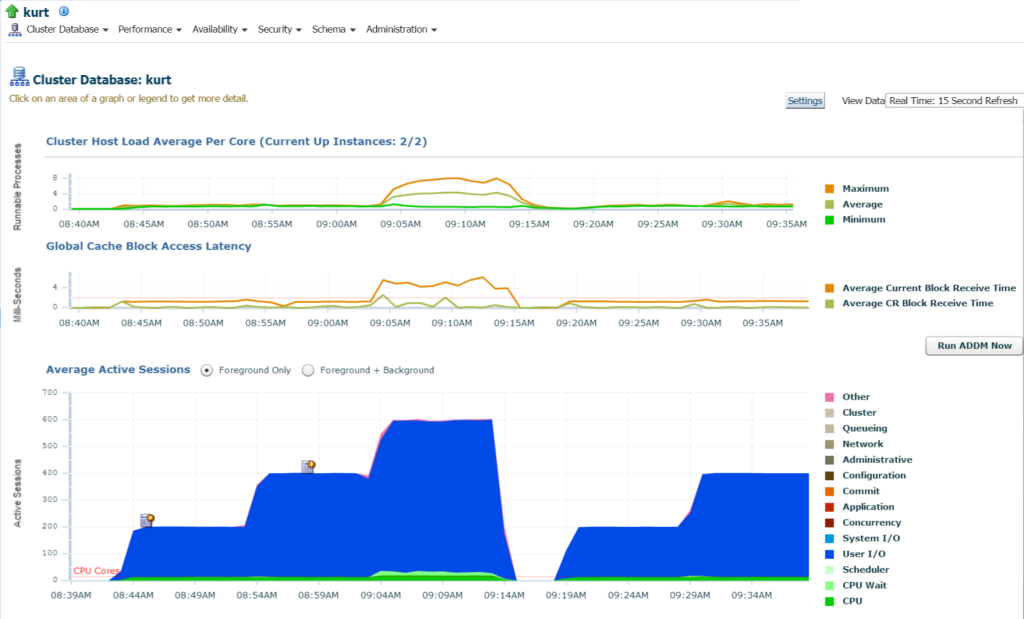
hvis Vi flytter Til Topp Aktivitet, (Ytelse meny, Topp Aktivitet) jeg begynner å vise flere detaljer om behandling og ulike ventehendelser:
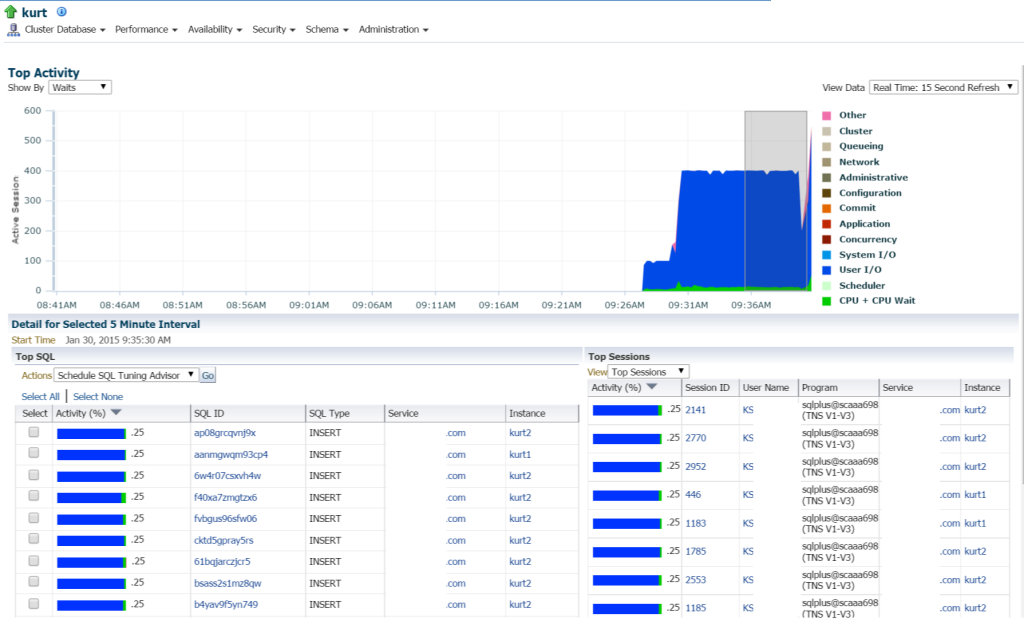
Kurt gjør alle slags innlegg, (sett av de forskjellige SQL_IDs, AV SQL Type «SETT inn». Jeg kan bore ned i de enkelte uttalelsene og undersøke dette, men egentlig er DET MASSEVIS av uttalelser og SQL_ID er her, ville det ikke bare være lettere å se arbeidsbelastningen med EN AWR-rapport?
Kjører AWR-Rapporten
jeg velger å klikke På Ytelse, AWR, AWR-Rapport. Nå har jeg et valg. Jeg kunne be om et nytt øyeblikksbilde som skal utføres umiddelbart, eller jeg kunne vente til toppen av timen, da intervallet er satt hver time i denne databasen. Jeg valgte sistnevnte for denne demonstrasjonen, men hvis du ønsket å lage et øyeblikksbilde umiddelbart, kan Du enkelt Gjøre Dette Fra EM12c eller be om et øyeblikksbilde ved å utføre følgende Fra SQLPlus med en bruker med utførelsesrettigheter PÅ DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
for dette eksemplet ventet jeg bare, da det ikke var travelt eller bekymring her og ba om rapporten for forrige time og siste øyeblikksbilde:
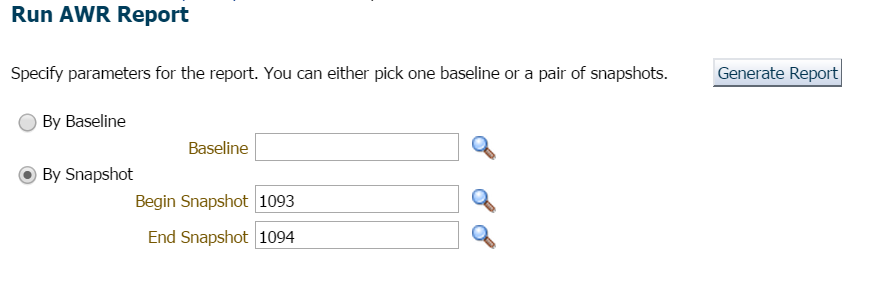
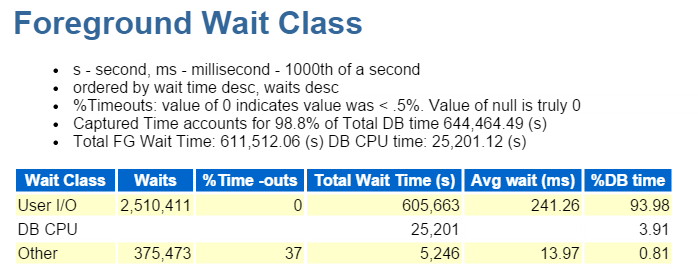
jeg starter alltid på Topp Ti Forgrunnshendelser og ser ofte på de med høye venteprosenter:
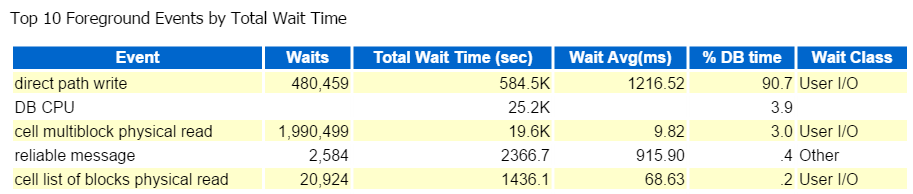
Direkte Sti Skrive, det er det. Ingenting annet å se her… hryvnias
Direct path write innebærer følgende: innlegg/oppdateringer, objekter som skrives til, tabeller som skrives til og de datafilene som utgjør tabellene.
Det er OGSÅ IO, som vi raskt verifiserer ned I Forgrunnen Venteklassen:
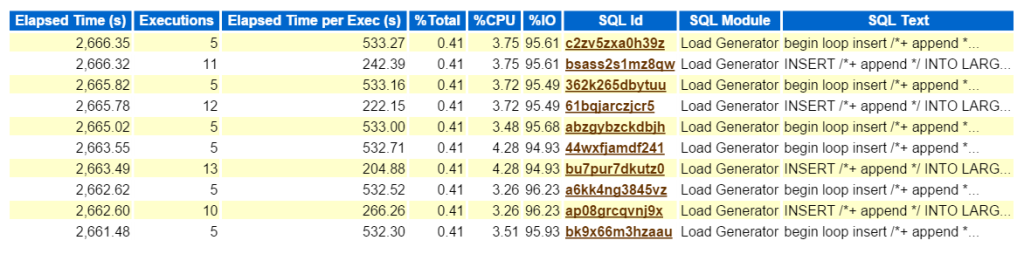
Ser På Topp SQL etter Forløpt tid bekrefter at vi har å gjøre med en arbeidsbelastning bestående av alle innlegg:
Ved Å Klikke PÅ SQL ID, tar meg Til Den Komplette Listen OVER SQL-Tekst og viser meg akkurat Hva Bad Boy Kurt gjør for å produsere sin testarbeidsbelastning:

Wow, At Kurt er ganske rebell, eh? 🙂
Sett inn en sløyfe i ett bord fra samme bord, rull tilbake og avslutt sløyfen, takk for at du spilte. Han sparker noen dekk og gjør det med angst! Ikke bekymre folk, Som jeg sa, Kurt gjør jobben sin, ved hjelp av en modul kalt «Load Generator». Jeg ville være en idiot for ikke å gjenkjenne dette som noe annet enn hva det er – generere arbeidsbelastning for å teste noe. Jeg får bare den ekstra fordelen av å ha en arbeidsbelastning for å gjøre et blogginnlegg om bruk AV AWR-data… 🙂
nå, Hvis dette var et reelt problem, og jeg prøvde å finne ut hva denne typen ytelsespåvirkning denne typen innsats skapte på miljøet, hvor skal jeg gå neste i AWR-rapporten? Den øverste SQL etter medgått tid er viktig som det burde være der du fokuserer din innsats. Andre seksjoner brutt ned AV SQL er hyggelig å ha, men husk alltid, «Hvis du ikke stemmer for tid, kaster du bort tid.»Ingenting kan komme av en optimaliseringsøvelse hvis ingen tidsbesparelser blir sett etter at du har fullført arbeidet. Så ved å ta Først Den Øverste SQL etter Forløpt Tid, så ser vi på setningen, kan vi nå se hvilke objekter som er en del av setningen, (large_block149, 191, 194, 145).
vi vet også at PROBLEMET ER IO, så vi bør hoppe ned fra SQL detaljert informasjon og gå til objektnivåinformasjonen. Disse seksjonene er identifisert Av Segmenter av xxx.
- Segmenter Etter Logisk Lesing
- Segmenter Etter Fysisk Lesing
- Segmenter Etter Leseforespørsler
- Segmenter Etter Tabellskanning
så videre og så videre….
alle disse viser et veldig lignende mønster og prosentandel for objektene vi ser i vår TOPP SQL. Huske, Kurt leste hver av disse tabellene, deretter sette de samme radene tilbake i tabellen igjen, deretter rulle tilbake. Siden dette er et arbeidsbelastningsscenario, i motsetning til de fleste ytelsesproblemer jeg ser, er det ikke noe utestående objekt som vises med over 10% innvirkning på noe område.

siden dette Er En Exadata, er det massevis av informasjon for å hjelpe deg med å forstå lossing, (smart skanner) flash cache, etc. det vil hjelpe til med å videresende informasjonen du trenger for å sikre at du oppnår ytelsen du ønsker med et konstruert system, men jeg vil gjerne lagre det for et annet innlegg og bare berøre noen AV IO-rapportene, da vi utførte tabellskanninger, så vi vil sørge for at de ble lastet av til cellenodene, (smarte skanninger) vs blir utført på en databaseknute.
Vi kan starte med Å se På Topp Database IO Gjennomstrømning:

og se Deretter De Øverste Databaseforespørslene Per Cellegjennomstrømning, (sans Cellenodenavnene) for å se hvordan de sammenligner: