He recibido una solicitud reciente para escribir una actualización sobre el trabajo con informes AWR, así que como prometí, ¡aquí está!
El Repositorio Automático de carga de trabajo
El Repositorio Automático de carga de trabajo (AWR) fue una de las mejores mejoras de Oracle en la versión 10g. Se puso un objetivo al frente del grupo de desarrollo cuando se les pidió que desarrollaran un producto que:
1. Proporcionó recomendaciones de rendimiento significativas y mejoras de datos de eventos de espera sobre su predecesor statspack.
2. Siempre estaba encendido, lo que significa que los datos se recopilarían continuamente sin la intervención manual del administrador de la base de datos.
3. No afectaría al procesamiento actual, ya que tiene sus propios procesos en segundo plano y búfer de memoria, espacio de tablas designado, (SYSAUX).
4. El búfer de memoria escribiría en la dirección opuesta a la dirección en la que el usuario lee, eliminando los problemas de concurrencia.
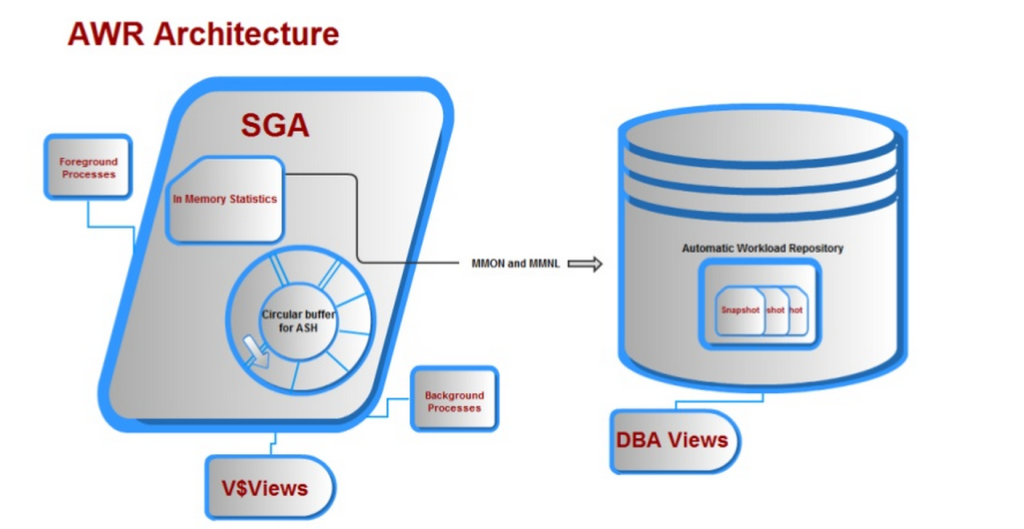
Junto con muchos otros requisitos, todo lo anterior se ofreció con el Repositorio de carga de trabajo Automática y terminamos con una arquitectura que se ve algo como esto:
Usando Datos AWR
Los datos AWR se identifican mediante el DBID (Identificador de base de datos) y un SNAP_ID (identificador de instantánea), que tiene un begin_interval_time y end_interval_time para aislar la fecha y hora de la recopilación de datos.) y la información sobre lo que se conserva actualmente en la base de datos se puede consultar desde DBA_HIST_SNAPSHOT. Los datos AWR también contienen muestras ASH (Historial de sesiones activo) junto con los datos de instantáneas, de forma predeterminada, aproximadamente 1 de cada 10 muestras.
El objetivo de usar los datos AWR de manera efectiva realmente tiene que ver con lo siguiente:
1. ¿Ha identificado un problema de rendimiento real como parte de una revisión de rendimiento?
2. ¿Ha habido una queja del usuario o una solicitud para investigar una degradación del rendimiento?
3. ¿Hay algún desafío o pregunta de negocios que necesite respuesta y a la que AWR pueda ofrecer una respuesta? (veremos cuándo usar AWR en comparación con otras funciones
Revisión de rendimiento
Una revisión de rendimiento es donde ha identificado un problema o se le ha asignado investigar el entorno para resolver problemas de rendimiento. Tengo un par de entornos de Gestión empresarial disponibles para mí, pero elegí ir a uno en particular y cruzar los dedos con la esperanza de tener un procesamiento pesado que se ajuste a los requisitos de este puesto.
La forma más rápida de ver la carga de trabajo en su entorno de base de datos desde EM12c, haga clic en Destinos – > Bases de datos. Elija ver por mapa de carga y, a continuación, verá las bases de datos por carga de trabajo. Al ir a un entorno de Gerente de empresa específico, descubrí que era mi día de suerte.
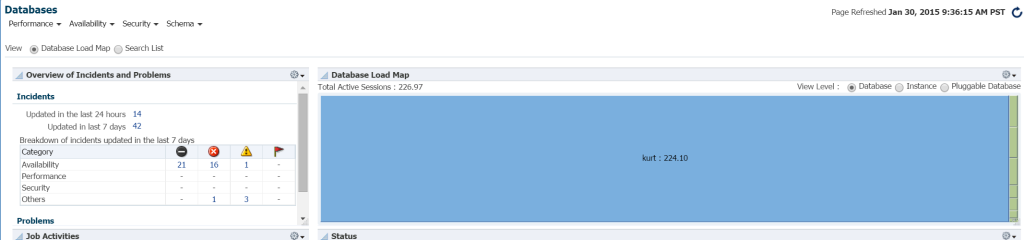 Realmente no sé quién es Kurt que tiene una base de datos monitoreada en este entorno de control en la nube EM12c, pero ¡vaya, es mi persona favorita hoy! 🙂
Realmente no sé quién es Kurt que tiene una base de datos monitoreada en este entorno de control en la nube EM12c, pero ¡vaya, es mi persona favorita hoy! 🙂
Al pasar el cursor sobre el nombre de la base de datos, (kurt) puede ver la carga de trabajo que tiene ejecutándose en su base de datos de prueba actualmente: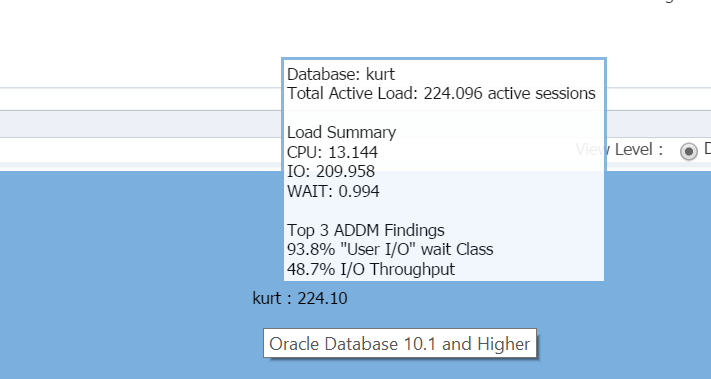
Chico, es Kurt mi persona favorita hoy!
Página de inicio de la base de datos EM12c
Al iniciar sesión en la base de datos, puedo ver el uso significativo de E / S y recursos para la base de datos y el host desde la página de inicio de la base de datos:
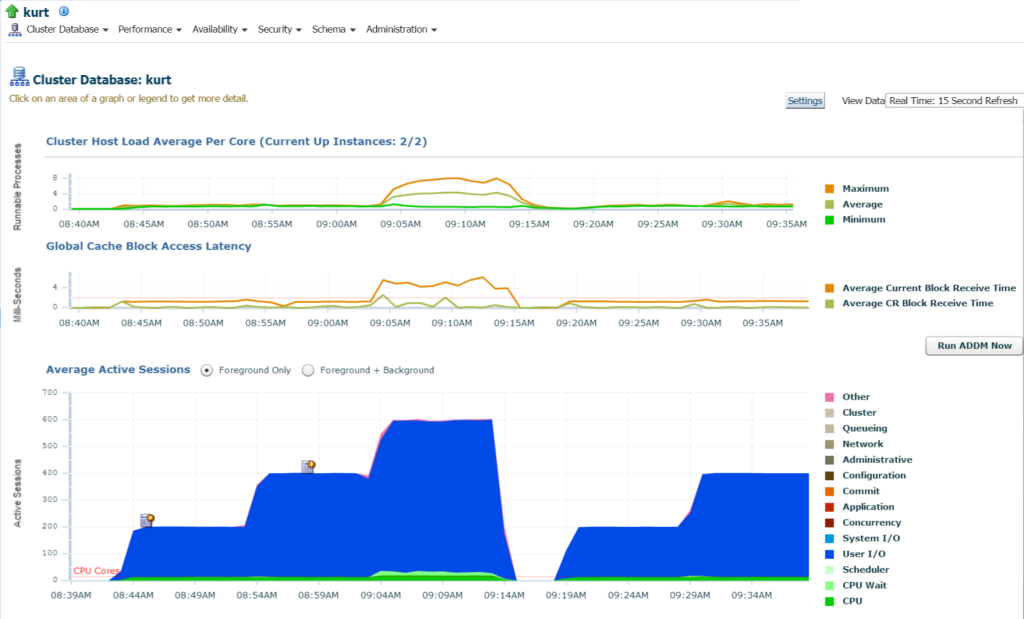
Si nos movemos a la Actividad Principal (Menú de rendimiento, Actividad Principal), empiezo a ver más detalles sobre el procesamiento y los diferentes eventos de espera:
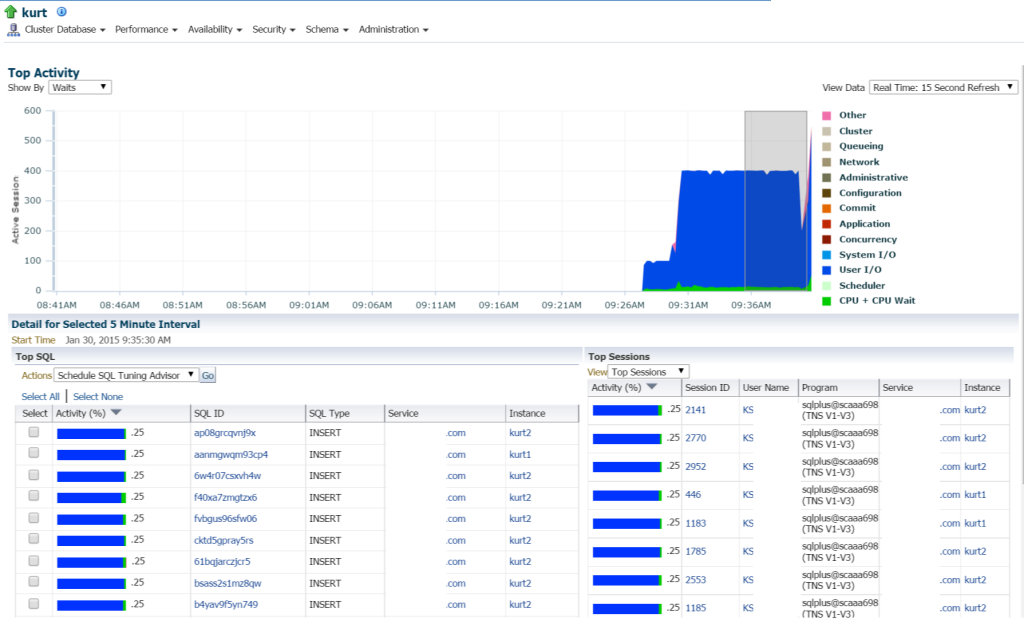
Kurt está haciendo todo TIPO de inserciones, (visto por los diferentes SQL_ID, por el tipo SQL «INSERT». Puedo profundizar en las declaraciones individuales e investigar esto, pero en realidad, hay un MONTÓN de declaraciones y SQL_ID está aquí, ¿no sería más fácil ver la carga de trabajo con un informe AWR?
Ejecutar el informe AWR
Elijo hacer clic en Rendimiento, AWR, Informe AWR. Ahora tengo una opción. Podría solicitar una nueva instantánea para que se realice de inmediato o podría esperar hasta la parte superior de la hora, ya que el intervalo se establece cada hora en esta base de datos. Elegí lo último para esta demostración, pero si desea crear una instantánea de inmediato, puede hacerlo fácilmente desde EM12c o solicitar una instantánea ejecutando lo siguiente desde SQLPlus con un usuario con privilegios de ejecución en DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
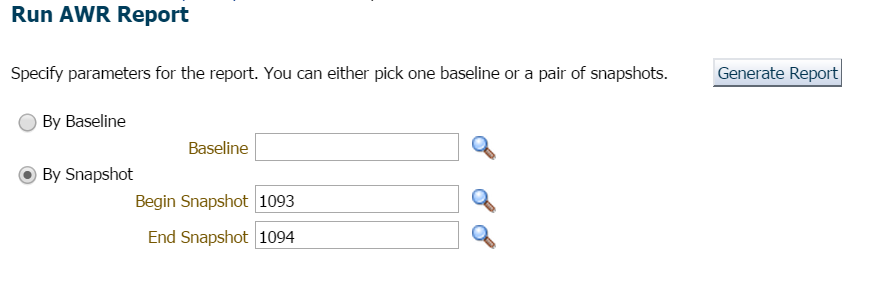
Para este ejemplo, simplemente esperé, ya que no había prisa ni preocupación aquí y solicité el informe de la hora anterior y la última instantánea:
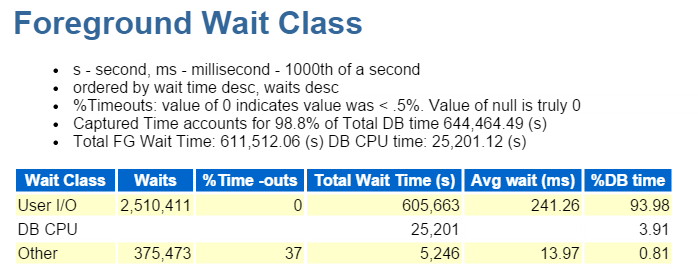
Siempre comienzo en los Diez Primeros eventos en Primer plano y comúnmente miro aquellos con altos porcentajes de espera:
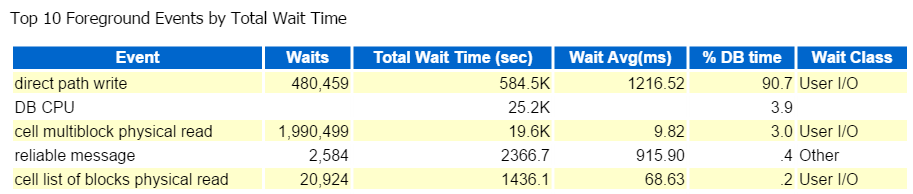
Escritura de ruta directa, eso es todo. No hay nada más que ver aquí 🙂 🙂
La escritura de ruta directa implica lo siguiente: inserciones/actualizaciones, objetos en los que se escriben, espacios de tablas en los que se escriben y los archivos de datos que componen el(los) espacio (s) de tablas.
También es IO, que verificamos rápidamente en la Clase de espera en Primer plano:
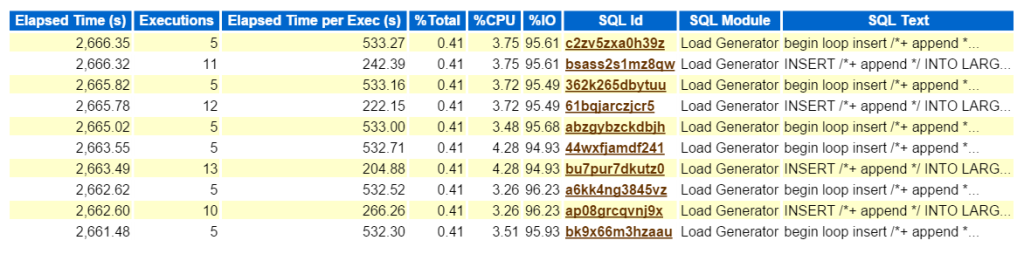
Mirar el SQL Superior por Tiempo Transcurrido confirma que estamos tratando con una carga de trabajo que consta de todas las inserciones:
Al hacer clic en el ID de SQL, me lleva a la Lista completa de Texto SQL y me muestra lo que el Chico Malo Kurt está haciendo para producir su carga de trabajo de pruebas:

Vaya, ese Kurt es bastante rebelde, ¿eh? 🙂
Inserte en un bucle en una mesa de la misma mesa, retroceda y luego termine el bucle, gracias por jugar. ¡Patea neumáticos y lo hace con angustia! No se preocupen, como dije, Kurt está haciendo su trabajo, usando un módulo llamado «Generador de carga». Sería un tonto no reconocer esto como otra cosa que no sea lo que es: generar carga de trabajo para probar algo. Solo obtengo el beneficio adicional de tener una carga de trabajo para hacer una publicación de blog sobre el uso de datos de AWR 🙂 🙂
Ahora, si esto era un problema real y estaba tratando de averiguar qué impacto de este tipo de rendimiento este tipo de inserción estaba creando en el entorno, ¿a dónde ir a continuación en el informe de AWR? El SQL superior por tiempo transcurrido es importante, ya que debe ser donde enfoque sus esfuerzos. Es bueno tener otras secciones desglosadas por SQL, pero recuerda siempre: «Si no estás afinando el tiempo, estás perdiendo el tiempo.»Nada puede salir de un ejercicio de optimización si no se ve un ahorro de tiempo después de haber completado el trabajo. Así que tomando primero el SQL Superior por Tiempo Transcurrido, luego mirando la sentencia, ahora podemos ver qué objetos forman parte de la sentencia, (large_block149, 191, 194, 145).
También sabemos que el problema es IO, por lo que debemos saltar desde la información detallada de SQL e ir a la información a nivel de objeto. Estas secciones se identifican por Segmentos por xxx.
- Segmentos por Lecturas lógicas
- Segmentos por Lecturas físicas
- Segmentos por Solicitudes de lectura
- Segmentos por Exploraciones de tabla
así sucesivamente y así sucesivamente….
Todos estos muestran un patrón y porcentaje muy similares para los objetos que vemos en nuestro SQL superior. Recuerda, Kurt estaba leyendo cada una de estas mesas, luego insertando las mismas filas en la mesa de nuevo, y luego retrocediendo. Como este es un escenario de carga de trabajo, a diferencia de la mayoría de los problemas de rendimiento que veo, no hay ningún objeto sobresaliente que se muestre con un impacto superior al 10% en cualquier área.

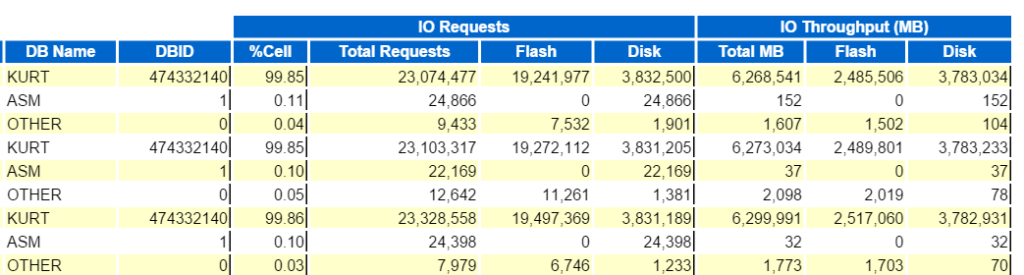
Como se trata de una Exadata, hay un montón de información para ayudarlo a comprender la descarga, la caché flash (escaneos inteligentes), etc. eso ayudará a transmitir la información que necesita para asegurarse de que está logrando el rendimiento que desea con un sistema diseñado, pero me gustaría guardarlo para otro post y solo tocar algunos de los informes de E / S, ya que estábamos realizando escaneos de tablas, por lo que queremos asegurarnos de que se estaban descargando a los nodos celulares (escaneos inteligentes) en lugar de realizarse en un nodo de base de datos.
Podemos comenzar mirando el rendimiento de E / s de la base de datos superior:

Y luego vea las Solicitudes de Base de Datos Principales Por Rendimiento de Celda (sin los nombres de nodo de Celda) para ver cómo se comparan: