Ich hatte kürzlich eine Anfrage, ein Update zur Arbeit mit AWR-Berichten zu schreiben, also wie versprochen, hier ist es!
Das automatische Workload-Repository
Das automatische Workload-Repository (AWR) war eine der besten Verbesserungen für Oracle in Release 10g. Die Entwicklungsgruppe hatte ein ziemliches Ziel, als sie gebeten wurde, ein Produkt zu entwickeln, das:
1. Erhebliche Leistungsempfehlungen und Verbesserungen der Warteereignisdaten gegenüber dem Vorgänger Statspack.
2. War immer eingeschaltet, was bedeutet, dass die Daten ohne manuelles Eingreifen des Datenbankadministrators kontinuierlich erfasst werden.
3. Würde die aktuelle Verarbeitung nicht beeinträchtigen, da sie über eigene Hintergrundprozesse und einen Speicherpuffer verfügt, der als Tablespace (SYSAUX) bezeichnet wird.
4. Der Speicherpuffer würde in die entgegengesetzte Richtung schreiben, in die der Benutzer liest, wodurch Probleme mit der Parallelität beseitigt werden.
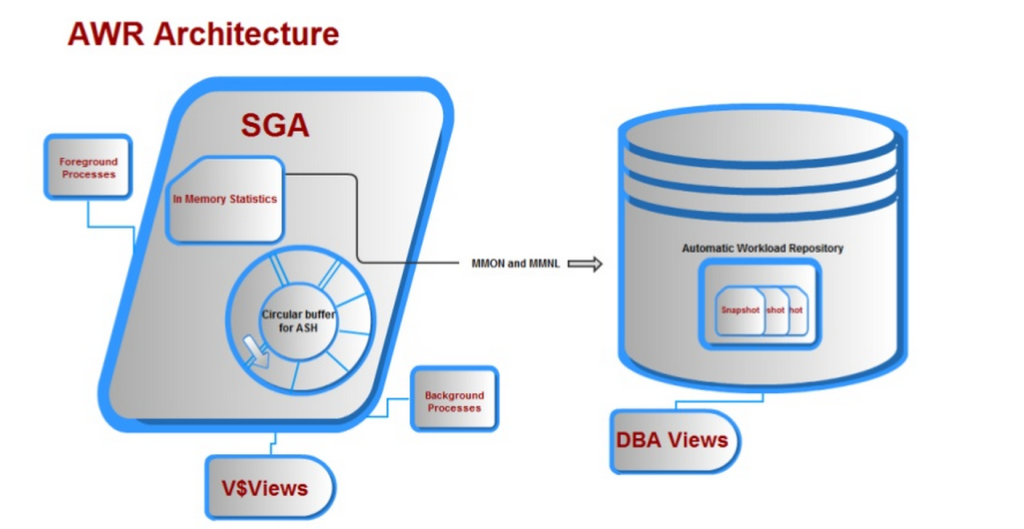
Zusammen mit vielen anderen Anforderungen wurde all dies mit dem automatischen Workload-Repository angeboten, und wir erhalten eine Architektur, die ungefähr so aussieht:
Verwenden von AWR-Daten
Die AWR-Daten werden durch die DBID (Datenbankkennung) und eine SNAP_ID (Snapshot-Kennung) identifiziert, die eine begin_interval_time und end_interval_time , um das Datum und die Uhrzeit der Datenerfassung zu isolieren.) und Informationen darüber, was derzeit in der Datenbank gespeichert ist, können aus dem DBA_HIST_SNAPSHOT abgefragt werden. AWR-Daten enthalten auch ASH (Active Session History) -Samples zusammen mit den Snapshot-Daten, standardmäßig etwa 1 von 10 Samples.
Das Ziel, AWR-Daten effektiv zu nutzen, hat wirklich mit Folgendem zu tun:
1. Haben Sie im Rahmen einer Leistungsüberprüfung ein echtes Leistungsproblem festgestellt?
2. Gab es eine Benutzerbeschwerde oder eine Anfrage zur Untersuchung einer Leistungsminderung?
3. Gibt es eine geschäftliche Herausforderung oder Frage, die beantwortet werden muss, auf die AWR eine Antwort geben kann? (wir gehen, wenn AWR im Vergleich zu anderen Funktionen zu verwenden …)
Leistungsüberprüfung
Eine Leistungsüberprüfung ist, wo Sie entweder ein Problem identifiziert haben oder zugewiesen wurden, um die Umgebung für Leistungsprobleme zu untersuchen zu lösen. Ich habe ein paar Enterprise Manager-Umgebungen zur Verfügung, aber ich entschied mich, zu einem bestimmten zu gehen und meine Finger zu drücken, in der Hoffnung, dass ich einige schwere Verarbeitung haben würde, um die Anforderungen dieses Beitrags zu erfüllen.
Der schnellste Weg, um die Auslastung in Ihrer Datenbankumgebung von EM12c aus zu sehen, klicken Sie auf Ziele –> Datenbanken. Wählen Sie view by load map aus, um die Datenbanken nach Workload anzuzeigen. Als ich zu einer bestimmten Enterprise Manager-Umgebung ging, fand ich heraus, dass es mein Glückstag war!
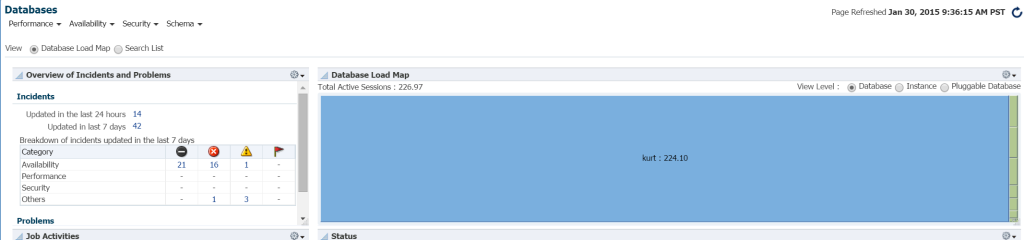 Ich weiß wirklich nicht, wer Kurt ist, der eine Datenbank in dieser EM12c Cloud Control-Umgebung überwacht hat, aber Junge, ist er heute meine Lieblingsperson! 🙂
Ich weiß wirklich nicht, wer Kurt ist, der eine Datenbank in dieser EM12c Cloud Control-Umgebung überwacht hat, aber Junge, ist er heute meine Lieblingsperson! 🙂
Wenn Sie den Mauszeiger über den Datenbanknamen bewegen, (kurt) können Sie die Arbeitslast anzeigen, die er derzeit in seiner Testdatenbank ausgeführt hat: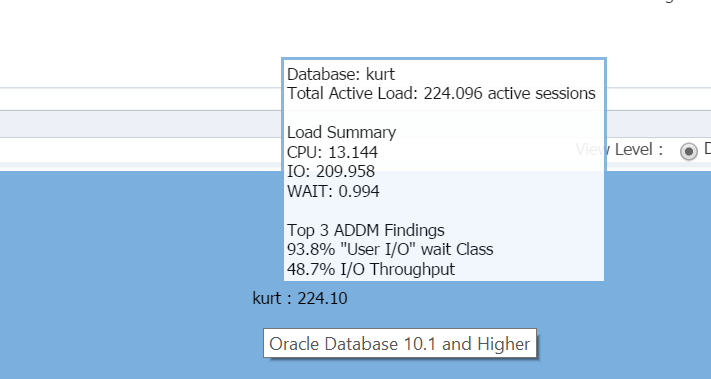
Junge, ist Kurt heute meine Lieblingsperson!
EM12c-Datenbank-Homepage
Wenn ich mich in die Datenbank anmelde, kann ich die signifikante E / A- und Ressourcennutzung für die Datenbank und den Host auf der Datenbank-Homepage sehen:
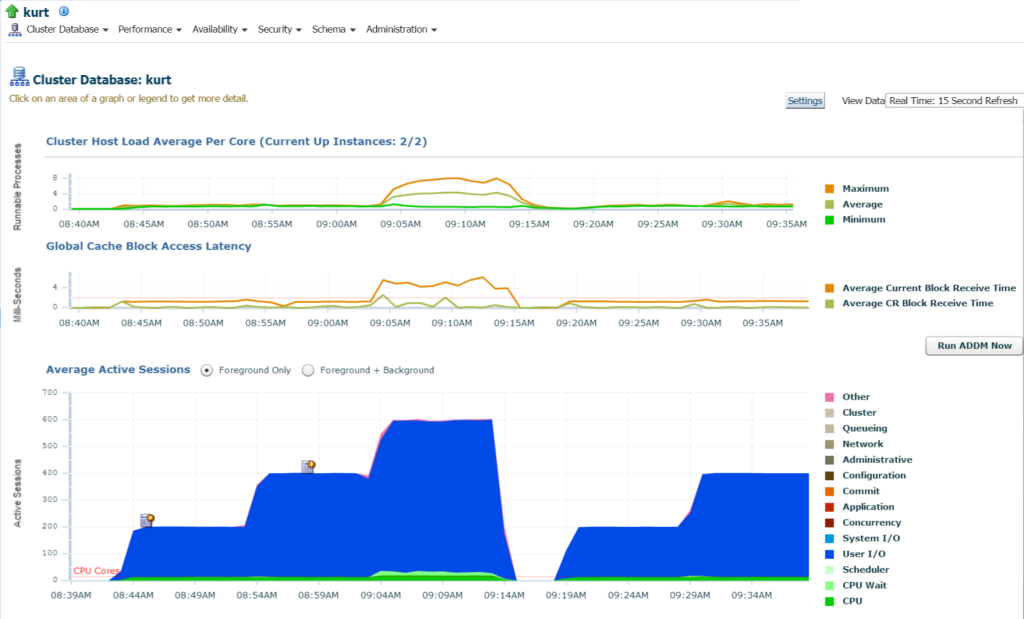
Wenn wir zur obersten Aktivität wechseln (Leistungsmenü, Oberste Aktivität), fange ich an, weitere Details zur Verarbeitung und zu verschiedenen Warteereignissen anzuzeigen:
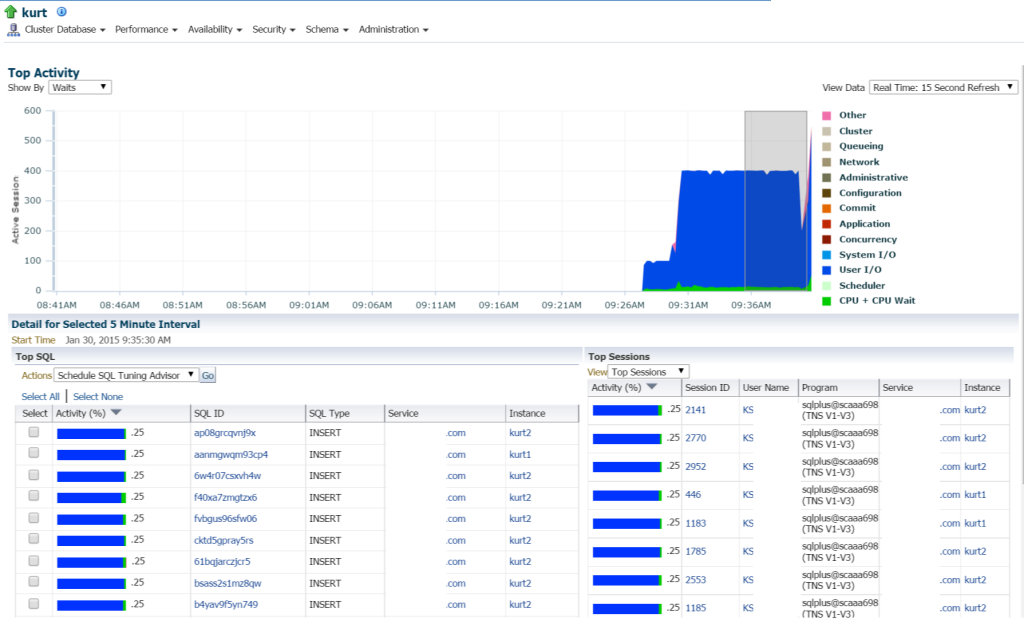
Kurt macht alle ARTEN von Einfügungen (gesehen von den verschiedenen SQL_IDs, nach SQL-Typ „INSERT“. Ich kann einen Drilldown in die einzelnen Anweisungen durchführen und dies untersuchen, aber wirklich, es gibt eine Menge Anweisungen und SQL_IDS hier, wäre es nicht einfacher, die Arbeitslast mit einem AWR-Bericht anzuzeigen?
Ausführen des AWR-Berichts
Ich klicke auf Leistung, AWR, AWR-Bericht. Jetzt habe ich die Wahl. Ich könnte sofort einen neuen Snapshot anfordern oder bis zum Ende der Stunde warten, da das Intervall in dieser Datenbank stündlich festgelegt ist. Wenn Sie jedoch sofort einen Snapshot erstellen möchten, können Sie dies problemlos von EM12c aus tun oder einen Snapshot anfordern, indem Sie Folgendes von SQLPlus mit einem Benutzer mit Ausführungsrechten für das DBMS_WORKLOAD_REPOSITORY ausführen:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
Für dieses Beispiel habe ich einfach gewartet, da es hier keine Eile oder Besorgnis gab, und den Bericht für die vorherige Stunde und den neuesten Schnappschuss angefordert:
Ich beginne immer bei den Top-Ten-Vordergrund-Events und schaue mir häufig solche mit hohen Wartezeiten an:
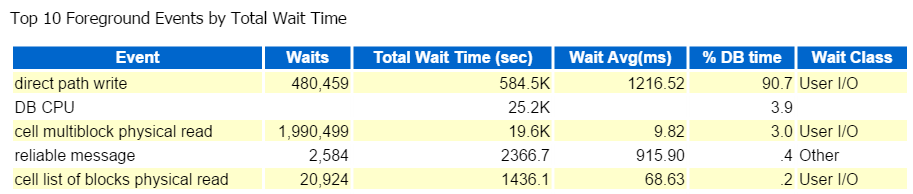
Direkter Weg schreiben, das war’s. Hier gibt es nichts anderes zu sehen … 🙂
Direct path Write beinhaltet Folgendes: Einfügungen / Aktualisierungen, Objekte, in die geschrieben wird, Tablespaces, in die geschrieben wird, und die Datendateien, aus denen die Tablespaces bestehen.
Es ist auch IO , was wir schnell in der Vordergrund-Wait-Klasse überprüfen:
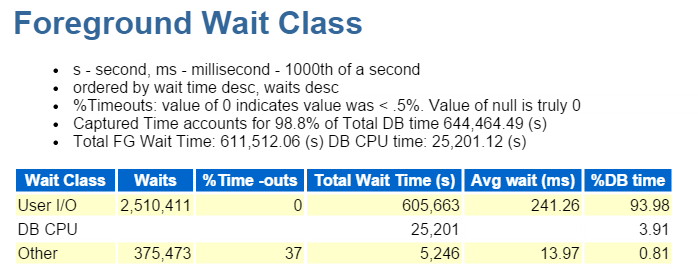
Ein Blick auf die oberste SQL nach verstrichener Zeit bestätigt, dass es sich um eine Arbeitslast handelt, die aus allen Einfügungen besteht:
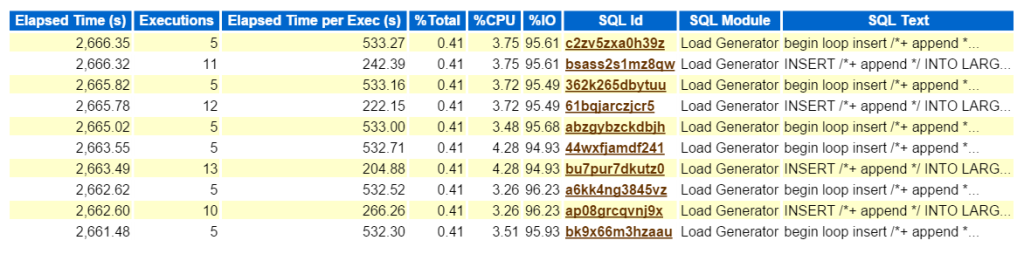
Ein Klick auf die SQL-ID führt mich zur vollständigen Liste des SQL-Textes und zeigt mir, was Bad Boy Kurt tut, um seine Test-Workload zu produzieren:

Wow, dieser Kurt ist ein ziemlicher Rebell, was? 🙂
In einer Schleife in eine Tabelle aus derselben Tabelle einfügen, Rollback und dann die Schleife beenden, danke fürs Spielen. Er tritt ein paar Reifen und tut es mit Angst! Keine Sorge Leute, wie gesagt, Kurt macht seinen Job mit einem Modul namens „Load Generator“. Ich wäre ein Narr, dies nicht als etwas anderes als das zu erkennen, was es ist – Arbeitsbelastung zu erzeugen, um etwas zu testen. Ich habe nur den zusätzlichen Vorteil, dass ich einen Blogbeitrag zur Verwendung von AWR-Daten erstellen kann … 🙂
Wenn dies ein echtes Problem war und ich herausfinden wollte, welche Auswirkungen diese Art von Leistung auf die Umgebung hatte, wohin sollte ich als nächstes im AWR-Bericht gehen? Die Top-SQL nach verstrichener Zeit ist wichtig, da Sie dort sein sollte, wo Sie Ihre Bemühungen konzentrieren. Andere Abschnitte, die nach SQL aufgeschlüsselt sind, sind nett zu haben, aber denken Sie immer daran: „Wenn Sie nicht auf Zeit einstellen, verschwenden Sie Zeit.“ Aus einer Optimierungsübung kann nichts werden, wenn nach Abschluss der Arbeit keine Zeitersparnis erkennbar ist. Indem wir also zuerst die oberste SQL nach verstrichener Zeit nehmen und dann die Anweisung betrachten, können wir jetzt sehen, welche Objekte Teil der Anweisung sind (large_block149, 191, 194, 145).
Wir wissen auch, dass das Problem IO ist, also sollten wir von den SQL-Detailinformationen nach unten springen und zu den Informationen auf Objektebene gehen. Diese Abschnitte werden durch Segmente mit xxx gekennzeichnet.
- Segmente nach logischen Lesevorgängen
- Segmente nach physischen Lesevorgängen
- Segmente nach Leseanforderungen
- Segmente nach Tabellenscans
so weiter und so fort ….
Diese zeigen alle ein sehr ähnliches Muster und einen ähnlichen Prozentsatz für die Objekte, die wir in unserer Topographie sehen. Denken Sie daran, Kurt hat jede dieser Tabellen gelesen, dann dieselben Zeilen wieder in die Tabelle eingefügt und dann ein Rollback durchgeführt. Da dies ein Workload-Szenario ist, wird im Gegensatz zu den meisten Leistungsproblemen, die ich sehe, in keinem Bereich ein herausragendes Objekt mit einer Auswirkung von über 10% angezeigt.

Da dies ein Exadata ist, gibt es eine Menge Informationen, die Ihnen helfen, Offloading, (Smart Scans) Flash-Cache usw. zu verstehen. das hilft bei der Weiterleitung der Informationen, die Sie benötigen, um sicherzustellen, dass Sie die gewünschte Leistung mit einem Engineered System erreichen, aber ich möchte das für einen anderen Beitrag speichern und nur einige der IO-Berichte berühren, da wir Tabellenscans durchgeführt haben, also wollen wir sicherstellen, dass diese auf die Zellknoten (Smart Scans) ausgelagert werden, anstatt auf einem Datenbankknoten ausgeführt zu werden.
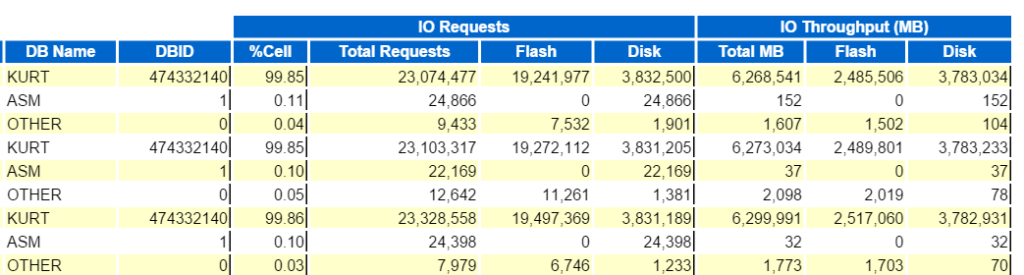
Wir können beginnen, indem wir uns den Top-Datenbank-IO-Durchsatz ansehen:

Zeigen Sie dann die wichtigsten Datenbankanforderungen pro Zellendurchsatz (ohne die Zellknotennamen) an, um zu sehen, wie sie verglichen werden: