měl jsem poslední žádost o napsání aktualizace na práci s AWR zpráv, tak jak jsem slíbil, tady to je!
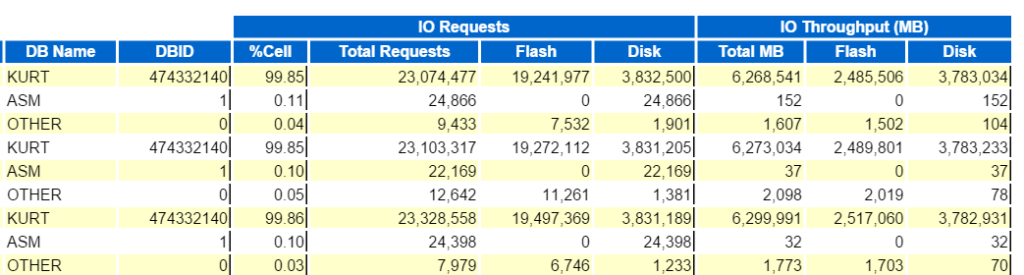
Automatic Workload Repository
Automatic Workload Repository (AWR) byl jedním z nejlepších vylepšení Oracle Zpět ve verzi 10g. tam byl docela cíl dát před vývojovou skupinou, když byli požádáni, aby vyvinuli produkt, který:
1. Poskytuje významné doporučení výkonu a vylepšení dat o událostech čekání oproti předchůdci statspack.
2. Byl vždy zapnutý, což znamená, že data budou neustále shromažďovat bez ručního zásahu správce databáze.
3. Nebude mít vliv na aktuální zpracování, které má své vlastní procesy na pozadí a vyrovnávací paměť, označený tablespace (SYSAUX).
4. Paměťová vyrovnávací paměť by zapisovala v opačném směru vs. směr, který uživatel čte, což eliminuje problémy se souběžností.
spolu s mnoha dalšími požadavky byly všechny výše uvedené nabízeny s automatickým úložištěm pracovní zátěže a my jsme skončili s architekturou, která vypadá nějak takto:
pomocí AWR dat
jsou data AWR identifikována pomocí DBID (identifikátor databáze) a SNAP_ID (identifikátor snímku, který má begin_interval_time a end_interval_time pro izolaci data a času sběru dat.) a informace o tom, co je aktuálně uchováváno v databázi, lze dotazovat z DBA_HIST_SNAPSHOT. Data AWR také obsahují vzorky ASH (Active session History) spolu s daty snapshot, ve výchozím nastavení asi 1 z každých 10 vzorků.
cíl efektivně využívat data AWR má opravdu co do činění s následujícími:
1. Identifikovali jste skutečný problém s výkonem jako součást kontroly výkonu?
2. Došlo k stížnosti uživatele nebo žádosti o vyšetření snížení výkonu?
3. Existuje obchodní výzva nebo otázka, na kterou je třeba odpovědět, na kterou AWR může nabídnout odpověď? (půjdeme, kdy použít AWR vs. ostatní funkce…)
recenze výkonu
kontrola výkonu je místo, kde jste buď identifikovali problém, nebo jste byli přiděleni k prozkoumání prostředí pro řešení problémů s výkonem. Mám k dispozici několik prostředí Enterprise Manager, ale rozhodl jsem se jít zejména na jednu a přejet prsty a doufat, že budu mít nějaké těžké zpracování, aby vyhovovalo požadavkům tohoto příspěvku.
nejrychlejší způsob, jak vidět pracovní zátěž v databázovém prostředí z EM12c, klikněte na cíle – > databáze. Vyberte, zda chcete zobrazit podle mapy zatížení a poté budete prohlížet databáze podle pracovní zátěže. Když jsem šel do konkrétního prostředí Enterprise Manager, zjistil jsem, že to byl můj šťastný den!
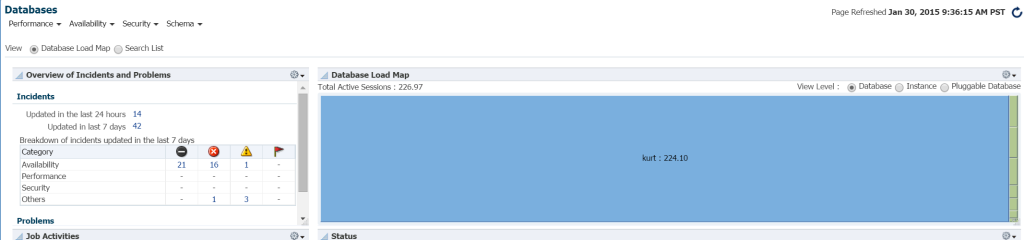 opravdu nevím, kdo je Kurt, který má databázi monitorovanou v tomto prostředí em12c cloud control, ale chlapec, je to můj oblíbený člověk dnes! 🙂
opravdu nevím, kdo je Kurt, který má databázi monitorovanou v tomto prostředí em12c cloud control, ale chlapec, je to můj oblíbený člověk dnes! 🙂
najetím kurzoru nad název databáze (kurt) můžete zobrazit pracovní zátěž, kterou v současné době běží ve své testovací databázi: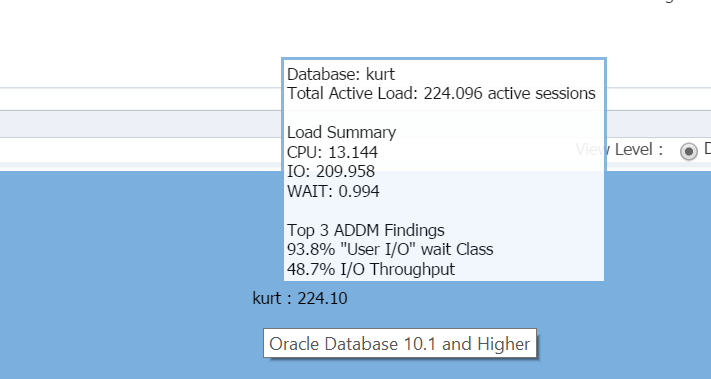
chlapec, je Kurt můj oblíbený člověk dnes!
domovská stránka databáze EM12c
při přihlášení do databáze vidím významné využití IO a zdrojů pro databázi a hostitele z domovské stránky databáze:
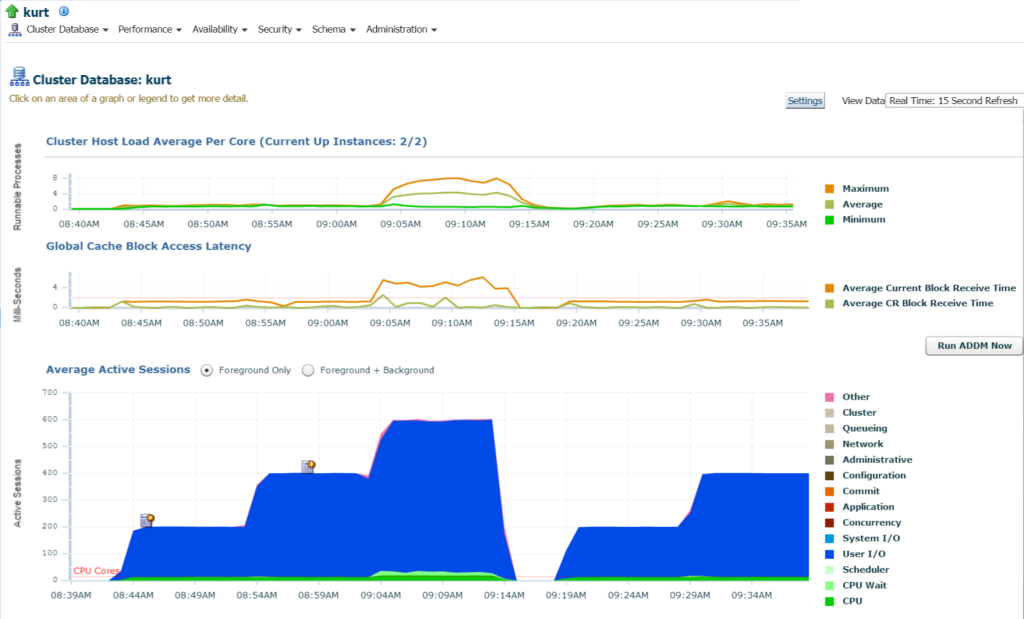
pokud se přesuneme na nejvyšší aktivitu (nabídka výkonu, nejvyšší aktivita), začnu si prohlížet další podrobnosti o zpracování a různých událostech čekání:
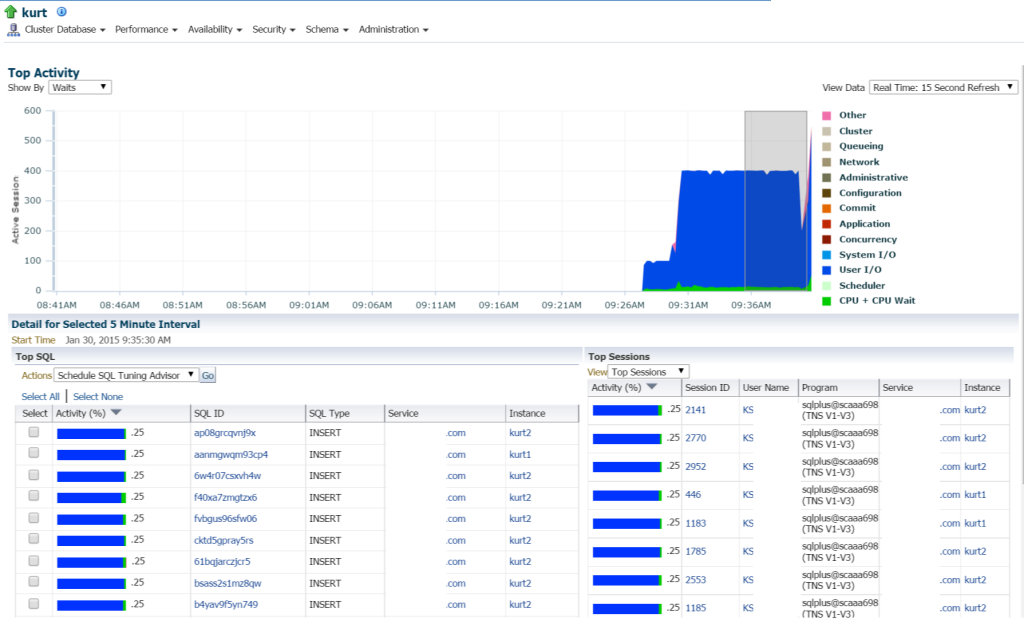
Kurt dělá všechny druhy vložek, (vidět různými SQL_IDs, SQL typu „INSERT“. Mohu přejít do jednotlivých prohlášení a prozkoumat to, ale ve skutečnosti existuje spousta příkazů a SQL_ID je tady, nebylo by jednodušší zobrazit pracovní zátěž pomocí zprávy AWR?
spuštění zprávy AWR
zvolím kliknutí na výkon, AWR, AWR zprávu. Teď mám na výběr. Mohl bych požádat o okamžité provedení nového snímku, nebo bych mohl počkat do horní části hodiny, protože interval je v této databázi nastaven každou hodinu. Pro tuto demonstraci jsem si vybral ten druhý, ale pokud jste chtěli okamžitě vytvořit snímek, můžete to udělat snadno z EM12c nebo požádat o snímek provedením následujícího z SQLPlus s uživatelem s oprávněními execute na DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
pro tento příklad, prostě jsem čekal, protože zde nebyl žádný spěch ani obavy a požádal jsem o zprávu za předchozí hodinu a nejnovější snímek:
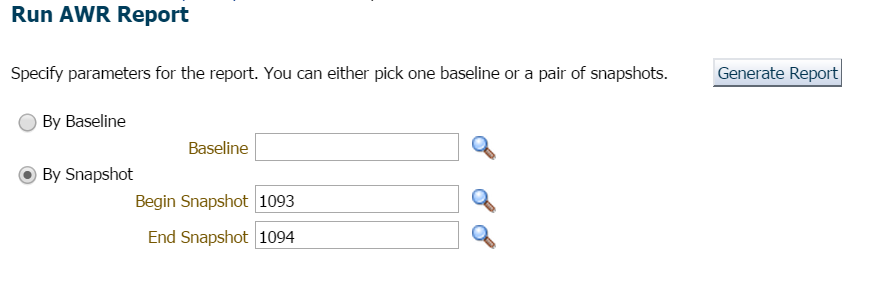
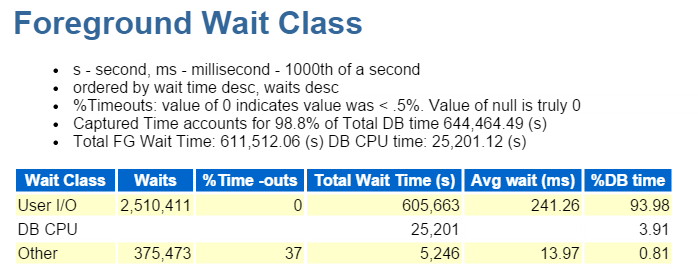
vždy začínám v první desítce událostí v popředí a běžně se dívám na ty s vysokým procentem čekání:
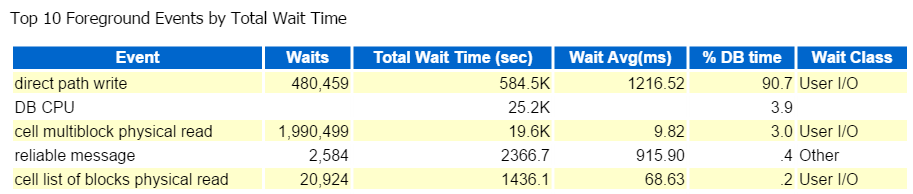
přímá cesta psát, to je ono. Nic jiného zde vidět … 🙂
přímá cesta zápis zahrnuje následující: vložky / aktualizace, objekty jsou zapsány do, tabulkové prostory jsou zapsány do A ty datové soubory, které tvoří tablespace(y).
je to také IO, které rychle ověřujeme ve třídě čekání v popředí:
pohled na horní SQL podle uplynulého času potvrzuje, že se jedná o pracovní zátěž sestávající ze všech vložek:
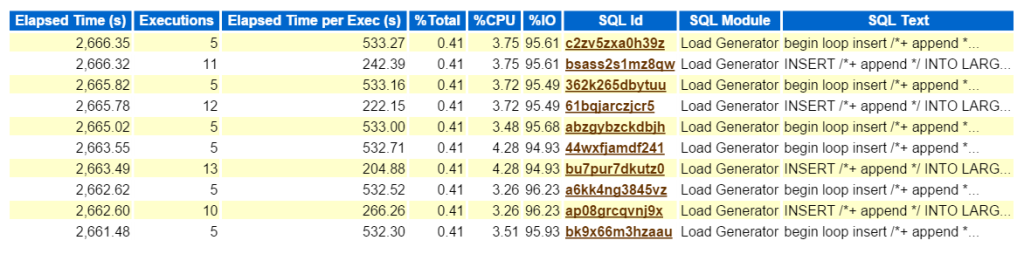
kliknutím na SQL ID, mě zavede do úplného seznamu SQL textu a ukazuje mi, co Bad Boy Kurt dělá, aby produkoval jeho testovací zátěž:

Páni, ten Kurt je docela rebel, co? 🙂
vložte do smyčky do jedné tabulky ze stejné tabulky, vraťte se zpět a ukončete smyčku, díky za hraní. Kope nějaké pneumatiky a dělá to s úzkostí! Nebojte se lidí, jak jsem řekl, Kurt dělá svou práci pomocí modulu zvaného „generátor zatížení“. Byl bych blázen, kdybych to neuznal jako něco jiného, než co to je-generování pracovní zátěže, abych něco otestoval. Mám jen další výhodu, že mám pracovní zátěž, abych udělal blogový příspěvek o používání dat AWR … 🙂
nyní, pokud to byl skutečný problém a snažil jsem se zjistit, jaký tento typ výkonu ovlivňuje tento typ vložky na životní prostředí, kam jít dál ve zprávě AWR? Horní SQL podle uplynulého času je důležitý, protože by měl být tam, kde soustředíte své úsilí. Ostatní sekce členěné SQL je hezké mít ,ale vždy pamatujte: „pokud nejste naladěni na čas, ztrácíte čas.“Nic nemůže přijít z optimalizačního cvičení, pokud po dokončení práce není vidět žádná úspora času. Takže tím, že nejprve vezmeme horní SQL podle uplynulého času, pak se podíváme na příkaz, nyní můžeme vidět, jaké objekty jsou součástí příkazu (large_block149 ,191, 194, 145).
také víme, že problém je IO, takže bychom měli skočit dolů z podrobných informací SQL a přejít na informace o úrovni objektu. Tyto sekce jsou označeny segmenty podle xxx.
- segmenty podle logických čtení
- segmenty podle fyzických čtení
- segmenty podle požadavků na čtení
- segmenty podle skenů tabulky
tak dále a tak dále….
všechny ukazují velmi podobný vzor a procento pro objekty, které vidíme v našem horním SQL. Pamatujte, že Kurt četl každou z těchto tabulek, pak znovu vložil stejné řádky zpět do tabulky a pak se vrátil zpět. Protože se jedná o scénář pracovní zátěže, na rozdíl od většiny problémů s výkonem, které vidím, neexistuje žádný vynikající objekt zobrazující více než 10% dopad v jakékoli oblasti.

protože se jedná o Exadata, existuje spousta informací, které vám pomohou pochopit vykládku, (inteligentní skenování) flash cache atd. to pomůže při předávání informací, které potřebujete, abyste se ujistili, že dosáhnete požadovaného výkonu pomocí navrženého systému, ale rád bych to uložil na další příspěvek a jen se dotkněte několika zpráv IO, protože jsme prováděli skenování tabulek, takže se chceme ujistit, že jsou vyloženy do buněčných uzlů (inteligentní skenování) vs. provádí se na databázovém uzlu.
můžeme začít tím, že se podíváme na nejvyšší propustnost IO databáze:

a pak si prohlédněte nejvyšší požadavky databáze na propustnost buňky (bez názvů uzlů buněk), abyste viděli, jak se porovnávají: