er zijn een aantal gevallen waarin u niet wilt dat pagina ‘ s in de SERPS verschijnen, en deze blogpost bespreekt de verschillende manieren waarop we dit kunnen doen.
de belangrijkste manieren om een pagina uit de zoekresultaten te houden zijn:
- geen index tags
- blokkeren op robots.txt
- het verwijderen van de pagina
- het Verwijderhulpprogramma van de Google Search Console.
- canonieke tags
- wat voor soort inhoud zouden we niet in de SERPs willen verschijnen?
- hoe vindt Google inhoud om in de zoekresultaten te verschijnen?
- Hoe kunnen we bepalen welke pagina ‘ s in de zoekresultaten staan?
- Noindex-Tags
- Blocking in Robots txt
- de pagina verwijderen
- Verwijderhulpprogramma van de Google Search Console
- canonieke tags
- laatste gedachten …
wat voor soort inhoud zouden we niet in de SERPs willen verschijnen?
er zijn een aantal verschillende soorten pagina ‘ s die we niet doorzoekbaar zouden willen zijn op Google of andere zoekmachines.
voorbeelden zijn::
- PPC landing pages
- Dank u pagina ‘s
- Admin pagina’ s
- interne zoekresultaten
we kunnen ook pagina ‘ s voor Google verbergen om een aantal redenen, waaronder:
- Paginaduplicatie – om te voorkomen dat meerdere versies van dezelfde pagina in de zoekresultaten verschijnen.
- Keyword kannibalisatie – om te voorkomen dat twee of meer soortgelijke pagina ’s met elkaar concurreren om een bepaald keyword
- Crawl budget verspilling – Ik zal het hebben over kruipen in deze sectie, maar dit verwijst naar Google die te veel tijd besteedt aan het ontdekken van pagina’ s met een lagere waarde op uw site, in plaats van prioriteit te geven aan de belangrijke dingen.
hoe vindt Google inhoud om in de zoekresultaten te verschijnen?
voordat we ingaan op de verschillende manieren waarop we kunnen voorkomen dat pagina ’s in de zoekresultaten verschijnen, is het de moeite waard om het proces te begrijpen dat Google gebruikt om pagina’ s te vinden en uiteindelijk te rangschikken.
1) crawlen-Dit is Google ‘ s manier om nieuwe content te ontdekken. Met behulp van programma ‘s, vaak aangeduid als spiders of crawlers, Google bezoekt verschillende webpagina’ s en volgt de links op hen om nieuwe pagina ‘ s te vinden. Elke site heeft een bepaalde “crawl budget” of hoeveelheid middelen die het toewijst aan elke site.
2) indexeren – zodra Google de inhoud heeft gevonden, bewaart het een kopie van die inhoud en slaat het op in wat een index wordt genoemd.
3) Rankings-de volgorde van deze verschillende pagina ‘ s in de zoekresultaten staat bekend als ranking. Google krijgt een query, erachter komt de zoekopdracht achter die query, en dan kijkt naar de index om de best mogelijke resultaten terug te keren.
Google maakt gebruik van een reeks verschillende berekeningen, bekend als algoritmen, om te bepalen welke de beste resultaten zijn om te dienen en orders ze van Meest relevant naar minst relevant.
Hoe kunnen we bepalen welke pagina ‘ s in de zoekresultaten staan?
Noindex-Tags
Noindex-tags zijn een richtlijn die Google vertelt: “Ik wil niet dat deze pagina wordt geïndexeerd en daarom niet in de zoekresultaten verschijnt.”
wanneer Google next die pagina doorzoekt en de noindex richtlijnen ziet, zal het die pagina uit zijn index verwijderen en dus de zoekresultaten.
deze noindex-tags kunnen op twee manieren geïmplementeerd worden:
- door ze op te nemen in de HTML-code
- door een noindex-header terug te geven in het HTTP-verzoek.
geen index tags geà mplementeerd in de HTML zou er ongeveer zo uitzien:<meta name="robots" content="noindex">
Noindex tags geïmplementeerd via HTTP header zou er zo uitzien:HTTP/... 200 OK
…
X-Robots-Tag: noindex
met CMS-platforms, zoals WordPress, kunt u noindex-tags toevoegen aan pagina ‘ s, wat betekent dat u geen ontwikkelaar nodig hebt om dit te implementeren.
belangrijk is dat Google deze pagina ‘ s moet kunnen crawlen om de tag “noindex” te zien en de pagina vervolgens uit de index te verwijderen.
wanneer gebruikt u geen index-tags – als er pagina ‘ s op uw site zijn die nog een doel dienen, maar u wilt niet in de zoekresultaten verschijnen, is dit een goede optie.
Blocking in Robots txt
Robots.txt is een tekstbestand dat wordt gebruikt om webrobots te instrueren hoe ze zich moeten gedragen wanneer ze uw site bezoeken en kan worden gebruikt om te dicteren aan zoekmachine crawlers of ze al dan niet delen van een website kunnen crawlen.
zie het onderstaande voorbeeld van Nike ‘ s robots.txt-bestand dat leeft op https://www.nike.com/robots.txt
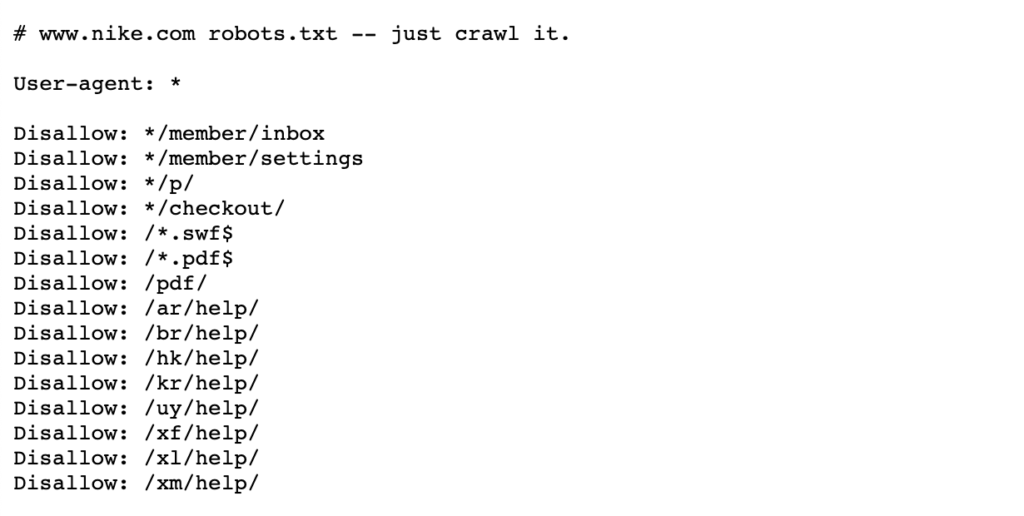
met robots.txt om bepaalde paginapaden zoals /admin / te blokkeren, bijvoorbeeld, betekent dat Googlebot of andere zoekmachines deze pagina ‘ s niet eens zullen bezoeken – vandaar dat ze niet zullen verschijnen in de zoekresultaten. Dit kan crawl budget behouden voor meer belangrijke pagina ’s in plaats van zich te concentreren op minder belangrijke pagina’ s.
opmerking: het blokkeren van een paginapad in robots.txt stopt Google van het opslaan van de pagina in de eerste plaats, maar het niet verwijderen of wijzigen Wat is opgeslagen. Daarom, als een pagina wordt al weergegeven in de zoekresultaten, Dan Google heeft al gekropen en vervolgens geïndexeerd deze pagina.
als u een pagina wilt verwijderen, Blokkeer deze dan in robots.txt zal actief voorkomen dat dat gebeurt. In dat geval, het beste ding om te doen is het toevoegen van een noindex tag om deze pagina ’s te verwijderen uit Google’ s index en zodra ze allemaal zijn verwijderd, kunt u vervolgens blokkeren in robots.txt.
meer details zijn te vinden op deze Google Search Central pagina.
wanneer pagina ‘ s in robots moeten worden geblokkeerd.txt-wanneer u specifieke pagina paden of Grotere secties van uw site die u niet wilt dat Google te crawlen, dit is uw beste weddenschap.
als een pagina of verzameling pagina ’s al in de SERP’ s verschijnt, moet u deze eerst niet indexeren en wachten tot ze verwijderd zijn voordat u de robots toevoegt.txt-bestand.
de pagina verwijderen
het meest voor de hand liggende antwoord, dacht je misschien, zou zijn om gewoon de pagina te verwijderen, of dat nu is door het geven van een 404 of een 410 statuscode.
beide statuscodes hebben dezelfde functie in die zin dat Google de pagina uit de index zal verwijderen als het de volgende keer op die pagina kruipt, hoewel een 410-status iets sneller kan zijn volgens John Mueller van Google.
vanuit een SEO-perspectief, als deze pagina ‘ s waarde hebben, of dat nu via backlinks of traffic is, zou het de moeite waard zijn 301 om te leiden naar een relevante pagina om die link equity op de site te consolideren.
als de pagina interne links heeft en u geen geschikte pagina hebt om naar door te leiden, moeten deze interne links worden verwijderd of vervangen door een pagina met 200 statuscodes.
wanneer een pagina moet worden verwijderd – als de pagina geen doel heeft en weinig waarde heeft in termen van backlinks of verkeer, kan het de moeite waard zijn om te verwijderen. Als er enige waarde, hetzij vanuit een gebruiker perspectief of een SEO perspectief, overwegen om het te houden met een noindex tag of 301 omleiden naar een relevante pagina.
Verwijderhulpprogramma van de Google Search Console
Verwijderhulpprogramma van de Google Search Console kan worden gebruikt om zoekresultaten van uw site tijdelijk te blokkeren voor sites die u bezit op de Google Search Console. Het is vermeldenswaard dat dit geen permanente oplossing is.
als u snel een pagina uit de zoekresultaten wilt verwijderen, is dit een goede optie. Als u een pagina permanent wilt verwijderen, raadt Google aan het een 404-of 410-status te geven, de toegang tot de inhoud te blokkeren met behulp van een wachtwoord of de pagina een noindex-tag te geven.
meer details zijn te vinden op deze Google Webmasters pagina.
wanneer het Verwijderhulpprogramma van de Google Search Console moet worden gebruikt-wanneer u een pagina snel moet verwijderen. Als u de pagina permanent moet verwijderen, gebruik dan een noindex tag of geef het een 404 of 410 status.
een canonieke tag is een fragment van HTML-code dat leeft in de <head> van de pagina en wordt gebruikt om de primaire versie te definiëren voor pagina ‘ s die vergelijkbaar zijn of duplicaten zijn. Canonieke tags helpen problemen te voorkomen die worden veroorzaakt door dubbele of bijna dubbele inhoud die op meerdere URL ‘ s wordt weergegeven.
zie het voorbeeld hieronder van een canonieke tag op de Brainlabs homepage:

Als u de ene pagina naar de andere canonicaliseert, zegt u dat u niet wilt dat die pagina in de zoekresultaten wordt weergegeven en dat u liever een andere versie van die pagina wilt weergeven.
in tegenstelling tot geen index-tags die orders zijn, kunnen canonieke tags door Google worden genegeerd. Google kan deze pagina ‘ s nog steeds doorzoeken, de canonieke tags bekijken en vervolgens beslissen of de pagina wel of niet in de zoekresultaten moet worden weergegeven.
wanneer canonieke tags worden gebruikt-canonieke tags moeten worden gebruikt wanneer er meerdere dubbele of soortgelijke pagina ‘ s worden gerangschikt. U wilt de niet-masterversies canonicaliseren naar één primaire versie van een pagina om aan Google aan te geven dat de masterversie de enige versie is die u wilt in de zoekresultaten. Dit zal ook de signalen van elk van deze URL ‘ s te consolideren op de ene hoofdpagina.
een goed voorbeeld voor het gebruik van canonieke tags is voor pagina ‘ s met parameters. Deze pagina ’s kunnen precies dezelfde inhoud hebben, maar verschillende URL’ s vanwege deze parameters. Canonieke tags kunnen helpen om ervoor te zorgen dat de juiste versie van een pagina rangschikt, niet een van de andere versies.
voorbeeld

laatste gedachten …
er zijn een aantal manieren om te verwijderen of te controleren welke inhoud in de zoekresultaten wordt weergegeven. De sleutel is ervoor te zorgen dat u kiest voor de beste optie voor uw specifieke situatie, niet een poging om ze allemaal tegelijk te doen!
