det finns ett antal fall där du kanske inte vill att sidor ska visas i SERP: erna, och det här blogginlägget diskuterar de olika sätten vi kan göra detta på.
de viktigaste sätten att hålla en sida utanför sökresultaten är:
- Noindex taggar
- blockering på robotar.txt
- radera sidan
- Google Search consoles borttagningsverktyg.
- kanoniska taggar
- vilken typ av innehåll skulle vi inte vilja visas i SERP: erna?
- Hur hittar Google innehåll som ska visas i sökresultaten?
- Hur kan vi kontrollera vilka sidor som rankas i sökresultaten?
- Noindex-taggar
- blockering i robotar txt
- radera sidan
- Google Search consoles borttagningsverktyg
- kanoniska taggar
- slutliga tankar…
vilken typ av innehåll skulle vi inte vilja visas i SERP: erna?
det finns ett antal olika typer av sidor som vi inte vill vara sökbara på Google eller andra sökmotorer.
exempel inkluderar:
- PPC målsidor
- tack sidor
- Admin sidor
- interna sökresultat
vi kanske också vill dölja sidor från Google för ett antal skäl, inklusive:
- duplicering av sidor – för att förhindra att många versioner av samma sida visas i sökresultaten.
- Keyword cannibalisation – för att stoppa två eller flera liknande sidor från att konkurrera med varandra för ett visst sökord
- Crawl budget wasteage – jag kommer att diskutera genomsökning i detta avsnitt, men detta hänvisar till Google spenderar för mycket tid att upptäcka lägre värde sidor på din webbplats, snarare än att prioritera viktiga saker.
Hur hittar Google innehåll som ska visas i sökresultaten?
innan vi dyker in på de olika sätten vi kan förhindra att sidor visas i sökresultaten är det värt att förstå processen som Google använder för att hitta och slutligen rangordna sidor.
1) genomsökning – Detta är Googles sätt att upptäcka nytt innehåll. Med hjälp av program, ofta kallade spindlar eller sökrobotar, besöker Google olika webbsidor och följer länkarna på dem för att hitta nya sidor. Varje webbplats har en viss ”genomsökningsbudget” eller mängd resurser som den allokerar till varje webbplats.
2) indexering – när Google har hittat innehållet behåller det en kopia av innehållet och lagrar det i det som kallas ett index.
3) rankningar – beställningen av dessa olika sidor i sökresultaten kallas rankning. Google får en fråga, räknar ut sökintentionen bakom den frågan och tittar sedan på indexet för att returnera bästa möjliga resultat.
Google använder en rad olika beräkningar, så kallade algoritmer, för att avgöra vilka som är de bästa resultaten för att tjäna och beställer dem från mest relevanta till minst relevanta.
Hur kan vi kontrollera vilka sidor som rankas i sökresultaten?
Noindex-taggar
Noindex-taggar är ett direktiv som säger till Google ”Jag vill inte att den här sidan ska indexeras och vill därför inte att den ska visas i sökresultaten.”
när Google next genomsöker den sidan och ser noindex-direktiven kommer den att ta bort den sidan från dess index och därmed sökresultaten.
dessa noindex-taggar kan implementeras på två sätt:
- genom att inkludera dem i sidans HTML-kod
- genom att returnera en noindex-rubrik i HTTP-begäran.
Noindex-taggar som implementeras i HTML skulle se ut så här:<meta name="robots" content="noindex">
Noindex-taggar implementerade via HTTP-rubrik skulle se ut så här:HTTP/... 200 OK
…
X-Robots-Tag: noindex
CMS-plattformar, som WordPress, låter dig lägga till noindex-taggar på sidor, vilket innebär att du inte behöver en utvecklare för att implementera detta.
viktigt är att Google måste kunna genomsöka dessa sidor för att se ”noindex” – taggen och sedan ta bort sidan från dess index.
när du ska använda noindex-taggar – om det finns sidor på din webbplats som fortfarande tjänar ett syfte, men du inte vill visas i sökresultaten är detta ett bra alternativ.
blockering i robotar txt
robotar.txt är en textfil som används för att instruera webbrobotar hur de ska bete sig när de besöker din webbplats och kan användas för att diktera för sökrobotar om de kan eller inte kan genomsöka delar av en webbplats.
se nedanstående exempel på Nikes robotar.txt-fil som bor på https://www.nike.com/robots.txt
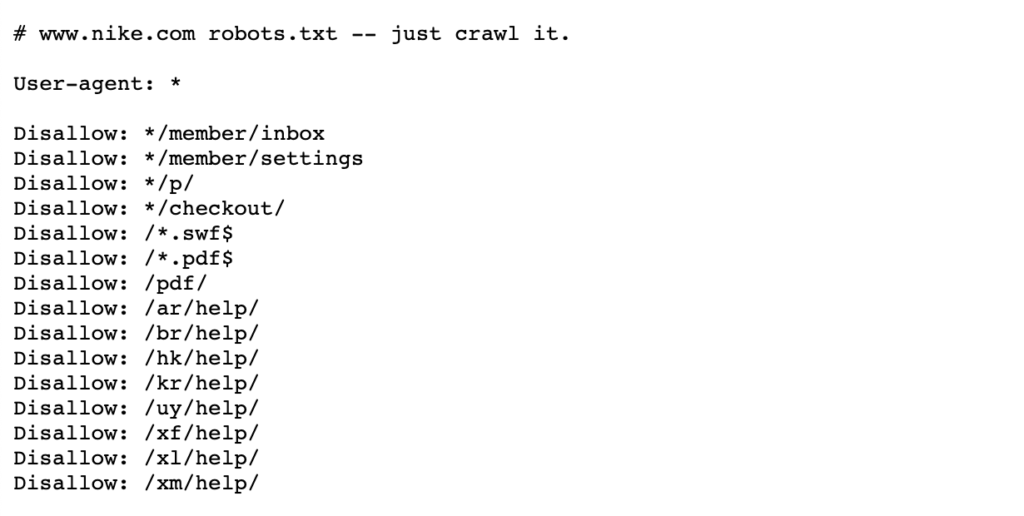
använda robotar.txt för att blockera vissa sidvägar som/ admin/, till exempel, betyder att Googlebot eller andra sökrobotar inte ens besöker dessa sidor – därför visas de inte i sökresultaten. Detta kan bevara genomsökningsbudgeten för viktigare sidor snarare än att fokusera på mindre viktiga sidor.
Obs: blockera en sidväg i robotar.txt hindrar Google från att spara sidan i första hand, men det tar inte bort eller ändrar det som har sparats. Därför, om en sida redan visas i sökresultaten, har Google redan genomsökt och sedan indexerat den här sidan.
om du behöver en sida raderad, blockerar du den i robotar.txt kommer aktivt att förhindra att det händer. I så fall är det bästa att lägga till en noindex-tagg för att ta bort dessa sidor från Googles index och när de alla har tagits bort kan du sedan blockera i robotar.txt.
mer information finns på denna Google Search Central-sida.
när ska man blockera sidor i robotar.txt-när du har specifika sidvägar eller större delar av din webbplats som du inte vill att Google ska genomsöka är det här din bästa insats.
om en sida eller en samling sidor redan visas i SERP: erna måste du dock noindex dem först och vänta på att de ska tas bort innan du lägger till robotarna.txt-fil.
radera sidan
det mest uppenbara svaret, du kanske trodde, skulle vara att helt enkelt ta bort sidan om det är genom att ge den en 404 eller en 410 statuskod.
båda statuskoderna tjänar samma funktion genom att Google tar bort sidan från dess index när den nästa kryper den sidan, även om en 410-status kan vara något snabbare enligt Googles John Mueller.
ur ett SEO-perspektiv, om dessa sidor håller värde, oavsett om det är genom bakåtlänkar eller trafik, skulle det vara värt 301 omdirigering till en relevant sida för att konsolidera det länkkapitalet på webbplatsen.
alternativt, om sidan har Interna Länkar och du inte har en lämplig sida att omdirigera till, bör dessa interna länkar tas bort eller ersättas med en 200 statuskod sida.
när ska man ta bort en sida – om sidan inte tjänar något syfte och har lite värde när det gäller bakåtlänkar eller trafik kan det vara värt att ta bort. Om det finns något värde antingen ur ett användarperspektiv eller ett SEO-perspektiv, överväg att hålla det med en noindex-tagg eller 301 omdirigering till en relevant sida.
Google Search consoles borttagningsverktyg
Google Search consoles borttagningsverktyg kan användas för att tillfälligt blockera sökresultat från din webbplats för webbplatser som du äger på Google Search Console. Det är värt att notera att detta inte är en permanent fix.
om du snabbt vill ta bort en sida från sökresultaten är detta ett bra alternativ. Om du vill ta bort en sida permanent rekommenderar Google att du antingen ger den en 404-eller 410-status, blockerar åtkomst till innehållet med ett lösenord eller ger sidan en noindex-tagg.
mer information finns på denna Google Webmasters-sida.
När ska du använda Google Search consoles borttagningsverktyg – när du behöver bli av med en sida snabbt. Om du behöver ta bort sidan permanent, använd en noindex-tagg eller ge den en 404 eller 410-status.
kanoniska taggar
en kanonisk tagg är ett utdrag av HTML-kod som bor i < huvudet> på sidan och används för att definiera den primära versionen för sidor som liknar eller dubbletter. Kanoniska taggar hjälper till att förhindra problem som orsakas av duplicerat eller nära duplicerat innehåll som visas på flera webbadresser.
se exemplet nedan för en kanonisk tagg på Brainlabs hemsida:

om du kanoniserar en sida till en annan säger du att du inte vill att den sidan ska visas i sökresultaten och du föredrar att en annan version av den sidan ska visas istället.
i motsats till noindex-taggar som är order kan kanoniska taggar ignoreras av Google. Google kan fortfarande genomsöka dessa sidor, se de kanoniska taggarna och sedan bestämma om sidan ska visas i sökresultaten eller inte.
När ska man använda kanoniska taggar – kanoniska taggar ska användas när det finns flera dubbla eller liknande sidor ranking. Du vill kanonisera de icke-huvudversionerna till en primär version av en sida för att indikera för Google att huvudversionen är den enda versionen du vill ha i sökresultaten. Detta kommer också att konsolidera signalerna från var och en av dessa webbadresser till en huvudsida.
ett utmärkt exempel för att använda kanoniska taggar är för sidor som har parametrar. Dessa sidor kan ha exakt samma innehåll men olika webbadresser på grund av dessa parametrar. Kanoniska taggar kan hjälpa till att säkerställa rätt version av en sida rankas, inte någon av de andra versionerna.
exempel

slutliga tankar…
det finns ett antal sätt att ta bort eller kontrollera vilket innehåll som visas i sökresultaten. Nyckeln är att se till att du väljer det bästa alternativet för just din situation, inte försöker göra dem alla på en gång!
