istnieje wiele przypadków, w których możesz nie chcieć, aby strony pojawiały się w SERPach, a ten post na blogu omawia różne sposoby, w jakie możemy to zrobić.
główne sposoby na to, aby strona nie znalazła się w wynikach wyszukiwania to:
- tagi Noindex
- blokowanie robotów.txt
- usuwanie strony
- Narzędzie Do Usuwania Google Search Console.
- Tagi kanoniczne
- jakiego rodzaju treści nie chcielibyśmy pojawiać się w SERPach?
- jak Google znajduje treści, które mają pojawić się w wynikach wyszukiwania?
- jak możemy kontrolować, jakie strony są pozycjonowane w wynikach wyszukiwania?
- Tagi Noindex
- Blokowanie w robotach txt
- usuwanie strony
- Narzędzie Do Usuwania Google Search Console
- znaczniki kanoniczne
- myśli końcowe…
jakiego rodzaju treści nie chcielibyśmy pojawiać się w SERPach?
istnieje wiele różnych typów stron, których nie chcielibyśmy przeszukiwać w Google lub innych wyszukiwarkach.
przykłady:
- strony docelowe PPC
- strony podziękowania
- strony administratora
- wewnętrzne wyniki wyszukiwania
możemy również chcieć ukryć strony przed Google z wielu powodów, w tym:
- duplikacja strony – aby zapobiec pojawianiu się wielu wersji tej samej strony w wynikach wyszukiwania.
- kanibalizacja słów kluczowych – aby powstrzymać dwie lub więcej podobnych stron przed konkurowaniem ze sobą o konkretne słowo kluczowe
- Crawl marnowanie budżetu – omówię indeksowanie w tej sekcji, ale odnosi się to do tego, że Google spędza zbyt dużo czasu na odkrywaniu stron o niższej wartości w Twojej witrynie, zamiast priorytetyzować ważne rzeczy.
jak Google znajduje treści, które mają pojawić się w wynikach wyszukiwania?
zanim zagłębimy się w różne sposoby zapobiegania pojawianiu się Stron w wynikach wyszukiwania, warto zrozumieć proces, za pomocą którego Google wyszukuje i ostatecznie pozycjonuje strony.
1) Crawling – to sposób Google na odkrywanie nowych treści. Korzystając z programów, często określanych jako pająki lub roboty, Google odwiedza różne strony internetowe i podąża za linkami na nich, aby znaleźć nowe strony. Każda witryna ma określony „budżet indeksowania” lub ilość zasobów, które przydziela każdej witrynie.
2) indeksowanie-gdy Google znajdzie treść, zachowuje kopię tej treści i przechowuje ją w tak zwanym indeksie.
3) rankingi-kolejność tych różnych stron w wynikach wyszukiwania jest znana jako ranking. Google dostaje zapytanie, oblicza intencję wyszukiwania za tym zapytaniem, a następnie patrzy na indeks, aby zwrócić najlepsze możliwe wyniki.
Google wykorzystuje szereg różnych obliczeń, znanych jako algorytmy, aby określić, które są najlepsze wyniki do obsługi i zleca je od najbardziej odpowiednich do najmniej istotnych.
jak możemy kontrolować, jakie strony są pozycjonowane w wynikach wyszukiwania?
Tagi Noindex
tagi Noindex to dyrektywa, która mówi Google „nie chcę, aby ta strona była indeksowana i dlatego nie chcę, aby pojawiała się w wynikach wyszukiwania.”
gdy Google przeszukiwa tę stronę i widzi dyrektywy noindex, usunie tę stronę z jej indeksu, a tym samym wyników wyszukiwania.
te znaczniki noindex można zaimplementować na dwa sposoby:
- umieszczając je w kodzie HTML strony
- zwracając nagłówek noindex w żądaniu HTTP.
znaczniki noindex zaimplementowane w HTML wyglądałyby mniej więcej tak:<meta name="robots" content="noindex">
znaczniki noindex zaimplementowane przez nagłówek HTTP wyglądałyby następująco:HTTP/... 200 OK
…
X-Robots-Tag: noindex
platformy CMS, takie jak WordPress, umożliwiają dodawanie tagów noindex do stron, co oznacza, że nie potrzebujesz programisty, aby to wdrożyć.
co ważne, Google musi mieć możliwość indeksowania tych stron, aby zobaczyć tag „noindex”, a następnie usunąć stronę z indeksu.
kiedy używać tagów noindex-jeśli w Twojej witrynie są strony, które nadal służą celowi, ale nie chcesz pojawiać się w wynikach wyszukiwania, jest to dobra opcja.
Blokowanie w robotach txt
roboty.txt to plik tekstowy używany do instruowania robotów internetowych, jak zachowywać się, gdy odwiedzają Twoją witrynę i może być używany do dyktowania robotom INDEKSUJĄCYM Wyszukiwarki, czy mogą, czy nie mogą indeksować części witryny.
zobacz poniższy przykład robotów Nike.plik txt, który mieszka w https://www.nike.com/robots.txt
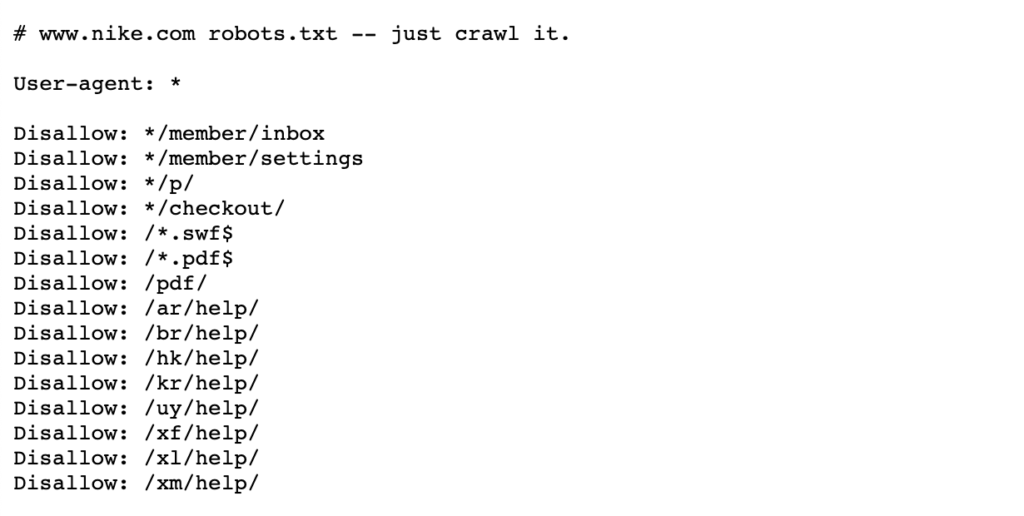
za pomocą robotów.txt blokowanie niektórych ścieżek stron, takich jak na przykład/ admin/, oznacza, że Googlebot lub inne roboty indeksujące nie będą nawet odwiedzać tych stron – dlatego nie pojawią się w wynikach wyszukiwania. Może to zachować budżet indeksowania dla ważniejszych stron, zamiast skupiać się na mniej ważnych stronach.
Uwaga: blokowanie ścieżki strony w robotach.txt powstrzymuje Google przed zapisaniem strony w pierwszej kolejności, ale nie usuwa ani nie zmienia tego, co zostało zapisane. Dlatego jeśli strona pojawia się już w wynikach wyszukiwania, Google już przeszukiwał, a następnie zindeksował tę stronę.
jeśli chcesz usunąć stronę, to blokuj ją w robotach.txt aktywnie temu zapobiegnie. W takim przypadku najlepiej jest dodać tag noindex, aby usunąć te strony z indeksu Google, a gdy wszystkie zostaną usunięte, możesz zablokować roboty.txt.
więcej szczegółów można znaleźć na tej stronie głównej wyszukiwarki Google.
kiedy blokować strony w robotach.txt-jeśli masz określone ścieżki strony lub większe sekcje witryny, których nie chcesz, aby Google indeksował, jest to najlepszy wybór.
jeśli strona lub zbiór stron jest już wyświetlany w SERPach, musisz najpierw je odindeksować i poczekać, aż zostaną usunięte przed dodaniem robotów.plik txt.
usuwanie strony
najbardziej oczywistą odpowiedzią, być może myślałeś, byłoby po prostu usunąć stronę, czy to poprzez nadanie jej kodu statusu 404, czy 410.
oba kody statusu służą tej samej funkcji, w której Google usunie stronę z indeksu, gdy następnym razem wypełni tę stronę, chociaż status 410 może być nieco szybszy według Johna Muellera Google.
z punktu widzenia SEO, jeśli te strony mają wartość, czy to poprzez linki zwrotne, czy ruch, warto byłoby przekierować 301 na odpowiednią stronę w celu konsolidacji tego linku w witrynie.
alternatywnie, jeśli strona ma wewnętrzne linki i nie masz odpowiedniej strony do przekierowania, te wewnętrzne linki powinny zostać usunięte lub zastąpione stroną kodową stanu 200.
kiedy usunąć stronę-jeśli strona nie służy celowi i ma niewielką wartość pod względem linków zwrotnych lub ruchu, może warto ją usunąć. Jeśli istnieje jakaś wartość z perspektywy użytkownika lub z perspektywy SEO, rozważ utrzymanie go za pomocą tagu noindex lub przekierowania 301 na odpowiednią stronę.
Narzędzie Do Usuwania Google Search Console
narzędzie do usuwania Google Search Console może być używane do tymczasowego blokowania wyników wyszukiwania z twojej witryny dla witryn, które posiadasz w Google Search Console. Warto zauważyć, że nie jest to stałe rozwiązanie.
jeśli chcesz szybko usunąć stronę z wyników wyszukiwania, jest to dobra opcja. Jeśli chcesz trwale usunąć stronę, Google zaleca nadanie jej statusu 404 lub 410, zablokowanie dostępu do treści za pomocą hasła lub nadanie stronie tagu noindex.
więcej szczegółów można znaleźć na tej stronie webmasterów Google.
kiedy korzystać z narzędzia do usuwania Google Search Console-kiedy trzeba szybko pozbyć się strony. Jeśli chcesz trwale usunąć stronę, użyj tagu noindex lub nadaj jej status 404 lub 410.
znaczniki kanoniczne
znacznik kanoniczny jest fragmentem kodu HTML, który mieszka w <głowie> strony i jest używany do definiowania wersji podstawowej dla stron, które są podobne lub duplikaty. Tagi Canonical pomagają zapobiegać problemom powodowanym przez duplikaty lub prawie duplikaty treści pojawiających się na wielu adresach URL.
zobacz poniższy przykład tagu kanonicznego na stronie głównej Brainlabs:

jeśli nie chcesz, aby ta strona pojawiała się w wynikach wyszukiwania, a wolisz, aby zamiast tego pojawiła się inna wersja tej strony.
w przeciwieństwie do tagów noindex, które są zamówieniami, tagi canonical mogą być ignorowane przez Google. Google może nadal indeksować te strony, wyświetlać tagi kanoniczne, a następnie decydować, czy strona ma pojawić się w wynikach wyszukiwania, czy nie.
kiedy używać tagów kanonicznych – Tagi kanoniczne powinny być używane, gdy istnieje kilka duplikatów lub podobnych stron w rankingu. Będziesz chciał kanonizować wersje inne niż master do jednej podstawowej wersji strony, aby wskazać Google, że wersja master jest jedyną wersją, którą chcesz w wynikach wyszukiwania. Spowoduje to również konsolidację sygnałów z każdego z tych adresów URL na jednej stronie wzorcowej.
najlepszym przykładem użycia tagów canonical jest dla stron, które mają parametry. Te strony mogą mieć dokładnie tę samą treść, ale różne adresy URL ze względu na te parametry. Tagi Canonical mogą pomóc w zapewnieniu poprawnej wersji rankingu strony, a nie żadnej z innych wersji.
przykład

myśli końcowe…
istnieje wiele sposobów na usunięcie lub kontrolowanie tego, jaka treść pojawia się w wynikach wyszukiwania. Kluczem jest upewnienie się, że wybierasz najlepszą opcję dla konkretnej sytuacji, a nie próba zrobienia ich wszystkich na raz!
