existuje řada případů, kdy možná nebudete chtít, aby se stránky zobrazovaly v SERP, a tento blogový příspěvek popisuje různé způsoby, jak to můžeme udělat.
hlavní způsoby, jak udržet stránku mimo výsledky vyhledávání, jsou:
- noindex tagy
- blokování na robotech.txt
- odstranění stránky
- Nástroj pro odstranění Google Search Console.
- kanonické značky
- jaký druh obsahu bychom nechtěli objevit v SERP?
- jak Google najde obsah, který se objeví ve výsledcích vyhledávání?
- jak můžeme kontrolovat, jaké stránky se ve výsledcích vyhledávání řadí?
- noindex tagy
- blokování v robotech txt
- odstranění stránky
- Nástroj pro odstranění Google Search Console
- Canonical tag
- Závěrečné myšlenky …
jaký druh obsahu bychom nechtěli objevit v SERP?
existuje řada různých typů stránek, které bychom nechtěli prohledávat na Googlu nebo jiných vyhledávačích.
příklady zahrnují:
- PPC vstupní stránky
- Děkuji stránky
- Admin stránky
- interní výsledky vyhledávání
můžeme také chtít skrýt stránky od společnosti Google z mnoha důvodů, včetně:
- duplikace stránky-aby se zabránilo zobrazení mnoha verzí stejné stránky ve výsledcích vyhledávání.
- kanibalizace klíčových slov-Chcete-li zabránit dvěma nebo více podobným stránkám v vzájemné konkurenci pro konkrétní klíčové slovo
- Procházet plýtvání rozpočtem-budu diskutovat o procházení v této části – ale to se týká toho, že Google tráví příliš mnoho času objevováním stránek s nižší hodnotou na vašem webu, spíše než upřednostňovat důležité věci.
jak Google najde obsah, který se objeví ve výsledcích vyhledávání?
než se ponoříme do různých způsobů, jak zabránit zobrazování stránek ve výsledcích vyhledávání, stojí za to pochopit proces, který Google používá k vyhledání a konečnému hodnocení stránek.
1) procházení-to je způsob, jakým Google objevuje nový obsah. Pomocí programů, často označovaných jako pavouci nebo prolézací moduly, Google navštěvuje různé webové stránky a sleduje odkazy na nich, aby našel nové stránky. Každý web má určitý „rozpočet procházení“ nebo množství zdrojů, které přiděluje každému webu.
2) indexování – jakmile Google najde obsah, uchovává kopii tohoto obsahu a ukládá jej do tzv. indexu.
3) Žebříčky-pořadí těchto různých stránek ve výsledcích vyhledávání je známé jako hodnocení. Google dostane dotaz, zjistí záměr vyhledávání za tímto dotazem a poté se podívá na index, aby vrátil nejlepší možné výsledky.
Google používá řadu různých výpočtů, známých jako algoritmy, k určení nejlepších výsledků, které mají sloužit, a objednává je od nejrelevantnějších po nejméně relevantní.
jak můžeme kontrolovat, jaké stránky se ve výsledcích vyhledávání řadí?
noindex tagy
noindex tagy jsou směrnice, která říká společnosti Google “ nechci, aby byla tato stránka indexována, a proto nechci, aby se objevila ve výsledcích vyhledávání.“
když Google next prohledá tuto stránku a uvidí směrnice noindex, odstraní tuto stránku z jejího indexu, a tedy z výsledků vyhledávání.
tyto značky noindex lze implementovat dvěma způsoby:
- zahrnutím do HTML kódu stránky
- vrácením hlavičky noindex v požadavku HTTP.
značky Noindex implementované v HTML by vypadaly asi takto:<meta name="robots" content="noindex">
značky Noindex implementované pomocí hlavičky HTTP by vypadaly takto:HTTP/... 200 OK
…
X-Robots-Tag: noindex
platformy CMS, jako je WordPress, vám umožňují přidávat značky noindex na stránky, což znamená, že k implementaci nepotřebujete vývojáře.
důležité je, že Google bude muset procházet tyto stránky, aby viděl značku“ noindex “ a poté stránku odebral z indexu.
kdy použít značky noindex – pokud jsou na vašem webu stránky, které stále slouží účelu, ale nechcete se zobrazovat ve výsledcích vyhledávání, je to dobrá volba.
blokování v robotech txt
roboty.txt je textový soubor používaný k instruovat webové roboty, jak se chovat, když navštíví vaše stránky a mohou být použity k diktovat prohledávače vyhledávačů, zda mohou nebo nemohou procházet části webových stránek.
viz níže uvedený příklad robotů Nike.txt soubor, který žije na https://www.nike.com/robots.txt
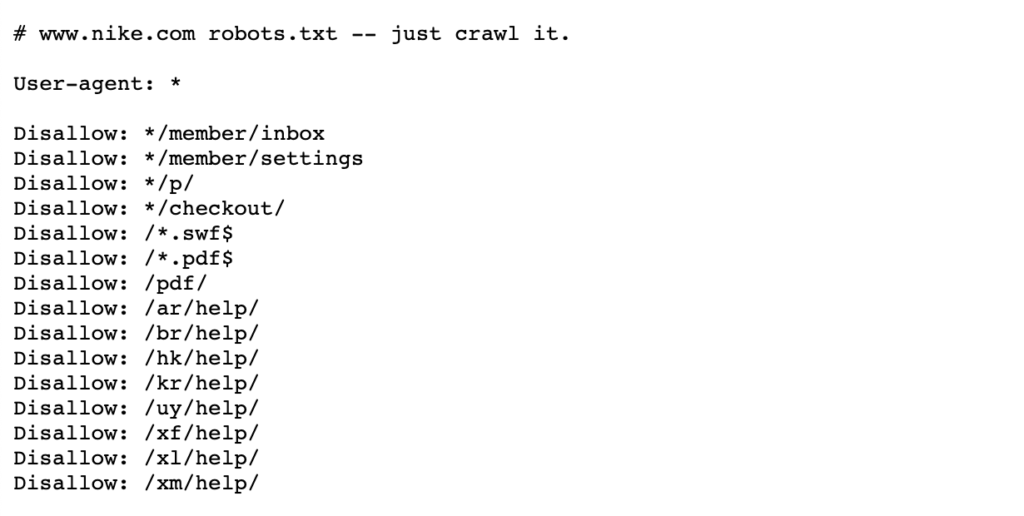
pomocí robotů.txt blokování určitých cest stránek, jako je například / admin/, znamená, že Googlebot nebo jiné prohledávače vyhledávání tyto stránky ani nenavštíví – proto se ve výsledcích vyhledávání nezobrazí. To může zachovat rozpočet procházení pro důležitější stránky, spíše než se zaměřit na méně důležité stránky.
Poznámka: blokování cesty ke stránce v robotech.txt zastaví Google v ukládání stránky na prvním místě, ale neodstraní ani nezmění to, co bylo uloženo. Pokud se tedy stránka již zobrazuje ve výsledcích vyhledávání, Google již tuto stránku procházel a poté indexoval.
pokud potřebujete stránku smazat, zablokujte ji v robotech.txt tomu aktivně zabrání. V takovém případě je nejlepší přidat značku noindex pro odstranění těchto stránek z indexu Google a jakmile jsou všechny odstraněny,můžete je zablokovat v robotech.txt.
další podrobnosti naleznete na této centrální stránce Vyhledávání Google.
kdy blokovat stránky v robotech.txt – pokud máte konkrétní cesty ke stránkám nebo větší části vašeho webu, které nechcete, aby Google procházel, je to vaše nejlepší sázka.
pokud se v SERP již objeví stránka nebo sbírka stránek, musíte je nejprve noindexovat a počkat, až budou odstraněny, než přidáte roboty.txt soubor.
odstranění stránky
nejviditelnější odpovědí, kterou jste si možná mysleli, by bylo jednoduše odstranit stránku, ať už je to tím, že jí dáte 404 nebo 410 stavový kód.
oba stavové kódy slouží stejné funkci v tom, že Google odstraní stránku z indexu při příštím procházení této stránky, i když stav 410 může být podle Johna Muellera společnosti Google o něco rychlejší.
z pohledu SEO, pokud tyto stránky mají hodnotu, ať už prostřednictvím zpětných odkazů nebo provozu, stálo by za to přesměrovat 301 na příslušnou stránku, aby se konsolidoval tento odkaz na webu.
alternativně, pokud stránka obsahuje interní odkazy a nemáte příslušnou stránku, na kterou byste mohli přesměrovat, tyto interní odkazy by měly být odstraněny nebo nahrazeny stránkou stavového kódu 200.
kdy odstranit stránku – pokud stránka neslouží žádnému účelu a má malou hodnotu z hlediska zpětných odkazů nebo provozu, může se vyplatit smazat. Pokud existuje nějaká hodnota z pohledu uživatele nebo z pohledu SEO, zvažte její ponechání se značkou noindex nebo přesměrování 301 na příslušnou stránku.
Nástroj pro odstranění Google Search Console
Nástroj pro odstranění Google Search Console lze použít k dočasnému blokování výsledků vyhledávání z vašeho webu pro weby, které vlastníte ve Vyhledávací konzoli Google. Stojí za zmínku, že to není trvalá oprava.
pokud chcete rychle odstranit stránku z výsledků vyhledávání, je to dobrá volba. Pokud chcete stránku trvale odstranit, Google doporučuje buď jí dát stav 404 nebo 410, zablokovat přístup k obsahu pomocí hesla nebo dát stránce značku noindex.
další podrobnosti naleznete na této stránce webmasterů Google.
kdy použít nástroj pro odstranění Google Search Console – když se potřebujete rychle zbavit stránky. Pokud potřebujete stránku trvale odstranit, použijte značku noindex nebo jí dejte stav 404 nebo 410.
Canonical tag
Canonical tag je úryvek HTML kódu, který žije v <hlavě> stránky a používá se k definování primární verze pro stránky, které jsou podobné nebo duplikáty. Kanonické značky pomáhají předcházet problémům způsobeným duplicitním nebo téměř duplicitním obsahem zobrazeným na více adresách URL.
viz níže uvedený příklad kanonické značky na domovské stránce Brainlabs:

pokud kanonizujete jednu stránku na druhou, říkáte, že nechcete, aby se tato stránka zobrazovala ve výsledcích vyhledávání, a místo toho byste preferovali jinou verzi této stránky.
na rozdíl od značek noindex, které jsou příkazy, mohou být kanonické značky společností Google ignorovány. Google může tyto stránky stále procházet, zobrazit kanonické značky a poté rozhodnout, zda by se stránka měla ve výsledcích vyhledávání objevit nebo ne.
kdy použít kanonické značky-kanonické značky by měly být použity, pokud existuje několik duplicitních nebo podobných stránek. Budete chtít kanonikalizovat jiné než hlavní verze na jednu primární verzi stránky, abyste Google označili, že hlavní verze je jediná verze, kterou chcete ve výsledcích vyhledávání. Tím se také konsolidují signály z každé z těchto adres URL na jednu hlavní stránku.
ukázkovým příkladem použití kanonických značek jsou stránky, které mají parametry. Tyto stránky mohou mít přesně stejný obsah, ale různé adresy URL kvůli těmto parametrům. Kanonické značky mohou pomoci zajistit správnou verzi hodností stránky, nikoli žádnou z ostatních verzí.
příklad

Závěrečné myšlenky …
existuje řada způsobů, jak odstranit nebo kontrolovat, jaký obsah se ve výsledcích vyhledávání objevuje. Klíčem je zajistit, že vybíráte nejlepší možnost pro vaši konkrétní situaci, nesnaží se je dělat všechny najednou!
