Es gibt eine Reihe von Fällen, in denen Sie möglicherweise nicht möchten, dass Seiten in den SERPS angezeigt werden, und in diesem Blogbeitrag werden die verschiedenen Möglichkeiten erläutert, wie wir dies tun können.
Die wichtigsten Möglichkeiten, eine Seite aus den Suchergebnissen herauszuhalten, sind:
- Noindex-Tags
- Blockieren von Robotern.txt
- Löschen der Seite
- Entfernungstool der Google Search Console.
- Kanonische Tags
- Welche Art von Inhalt möchten wir nicht in den SERPs erscheinen lassen?
- Wie findet Google Inhalte, die in den Suchergebnissen erscheinen?
- Wie können wir kontrollieren, welche Seiten in den Suchergebnissen rangieren?
- Noindex-Tags
- Blockieren in Robotern txt
- Löschen der Seite
- Tool zum Entfernen der Google Search Console
- Kanonische Tags
- Final thoughts…
Welche Art von Inhalt möchten wir nicht in den SERPs erscheinen lassen?
Es gibt verschiedene Arten von Seiten, die bei Google oder anderen Suchmaschinen nicht durchsuchbar sein sollen.
Beispiele sind:
- PPC-Zielseiten
- Danke Seiten
- Admin-Seiten
- Interne Suchergebnisse
Möglicherweise möchten wir Seiten auch aus verschiedenen Gründen vor Google ausblenden, darunter:
- Seitenduplizierung – Um zu verhindern, dass zahlreiche Versionen derselben Seite in den Suchergebnissen angezeigt werden.
- Keyword–Kannibalisierung – Um zu verhindern, dass zwei oder mehr ähnliche Seiten um ein bestimmtes Keyword konkurrieren
- Crawl-Budget-Verschwendung – Ich werde in diesem Abschnitt auf das Crawlen eingehen, aber dies bezieht sich darauf, dass Google zu viel Zeit damit verbringt, Seiten mit niedrigerem Wert auf Ihrer Website zu entdecken, anstatt die wichtigen Dinge zu priorisieren.
Wie findet Google Inhalte, die in den Suchergebnissen erscheinen?
Bevor wir uns mit den verschiedenen Möglichkeiten befassen, wie wir verhindern können, dass Seiten in den Suchergebnissen angezeigt werden, sollten Sie den Prozess verstehen, mit dem Google Seiten findet und letztendlich bewertet.
1) Crawling – Dies ist Googles Art, neue Inhalte zu entdecken. Mithilfe von Programmen, die oft als Spider oder Crawler bezeichnet werden, besucht Google verschiedene Webseiten und folgt den darauf befindlichen Links, um neue Seiten zu finden. Jede Site verfügt über ein bestimmtes „Crawl-Budget“ oder eine bestimmte Menge an Ressourcen, die jeder Site zugewiesen werden.
2) Indizierung – Sobald Google den Inhalt gefunden hat, verwaltet es eine Kopie dieses Inhalts und speichert ihn in einem sogenannten Index.
3) Rankings – Die Reihenfolge dieser verschiedenen Seiten in den Suchergebnissen wird als Ranking bezeichnet. Google ruft eine Abfrage ab, ermittelt die Suchabsicht hinter dieser Abfrage und sucht dann im Index nach den bestmöglichen Ergebnissen.
Google verwendet eine Reihe verschiedener Berechnungen, sogenannte Algorithmen, um festzustellen, welche Ergebnisse am besten zu liefern sind, und ordnet sie von den relevantesten zu den am wenigsten relevanten.
Wie können wir kontrollieren, welche Seiten in den Suchergebnissen rangieren?
Noindex-Tags
Noindex-Tags sind eine Direktive, die Google mitteilt: „Ich möchte nicht, dass diese Seite indiziert wird und daher nicht in den Suchergebnissen angezeigt wird.“
Wenn Google diese Seite das nächste Mal durchsucht und die Noindex-Direktiven sieht, wird diese Seite aus ihrem Index und damit aus den Suchergebnissen entfernt.
Diese Noindex-Tags können auf zwei Arten implementiert werden:
- Indem Sie sie in den HTML-Code der Seite
- Indem Sie einen Noindex-Header in der HTTP-Anforderung zurückgeben.
Noindex-Tags, die im HTML implementiert sind, würden ungefähr so aussehen:<meta name="robots" content="noindex">
Noindex-Tags, die über den HTTP-Header implementiert wurden, würden folgendermaßen aussehen:HTTP/... 200 OK
…
X-Robots-Tag: noindex
CMS-Plattformen wie WordPress ermöglichen es Ihnen, Noindex-Tags zu Seiten hinzuzufügen, was bedeutet, dass Sie keinen Entwickler benötigen, um dies zu implementieren.
Wichtig ist, dass Google in der Lage sein muss, diese Seiten zu crawlen, um das „noindex“ -Tag zu sehen und die Seite dann aus dem Index zu entfernen.
Verwendung von Noindex-Tags – Wenn es auf Ihrer Website Seiten gibt, die noch einem Zweck dienen, aber nicht in den Suchergebnissen angezeigt werden sollen, ist dies eine gute Option.
Blockieren in Robotern txt
Roboter.txt ist eine Textdatei, die verwendet wird, um Webroboter anzuweisen, sich zu verhalten, wenn sie Ihre Website besuchen, und kann verwendet werden, um Suchmaschinen-Crawlern zu diktieren, ob sie Teile einer Website crawlen können oder nicht.
Siehe das folgende Beispiel von Nikes Robotern.txt-Datei, die lebt https://www.nike.com/robots.txt
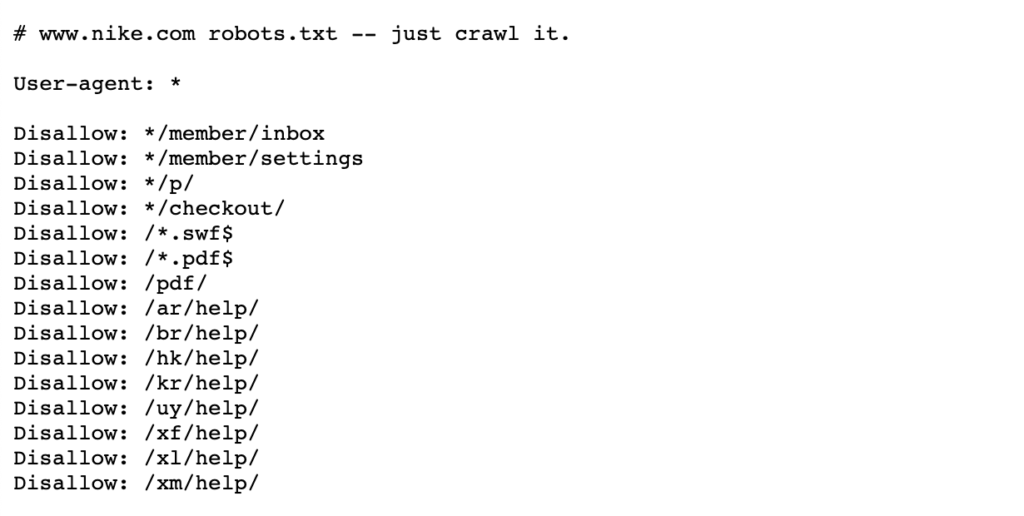
Mit Robotern.txt, um bestimmte Seitenpfade wie z. B. / admin / zu blockieren, bedeutet, dass Googlebot oder andere Such-Crawler diese Seiten nicht einmal besuchen – daher werden sie nicht in den Suchergebnissen angezeigt. Dadurch kann das Crawling-Budget für wichtigere Seiten beibehalten werden, anstatt sich auf weniger wichtige Seiten zu konzentrieren.
Hinweis: Blockieren eines Seitenpfads in Robots.txt verhindert, dass Google die Seite überhaupt speichert, löscht oder ändert jedoch nicht, was gespeichert wurde. Wenn also eine Seite bereits in den Suchergebnissen angezeigt wird, hat Google diese Seite bereits gecrawlt und dann indiziert.
Wenn Sie eine Seite löschen möchten, blockieren Sie sie in Robots.txt wird dies aktiv verhindern. In diesem Fall fügen Sie am besten ein Noindex-Tag hinzu, um diese Seiten aus dem Google-Index zu entfernen.txt.
Weitere Details finden Sie auf dieser zentralen Seite der Google-Suche.
Wann Seiten in Robots blockiert werden sollen.txt – Wenn Sie bestimmte Seitenpfade oder größere Abschnitte Ihrer Website haben, die Google nicht crawlen soll, ist dies die beste Wahl.
Wenn eine Seite oder eine Sammlung von Seiten jedoch bereits in den SERPs angezeigt wird, müssen Sie sie zuerst noindex und warten, bis sie entfernt wurden, bevor Sie die Roboter hinzufügen.txt-Datei.
Löschen der Seite
Die naheliegendste Antwort, die Sie vielleicht gedacht haben, wäre, die Seite einfach zu löschen, indem Sie ihr einen 404- oder einen 410-Statuscode geben.
Beide Statuscodes erfüllen dieselbe Funktion, da Google die Seite beim nächsten Crawlen dieser Seite aus dem Index entfernt, obwohl ein 410-Status laut John Mueller von Google möglicherweise etwas schneller ist.
Wenn diese Seiten aus SEO-Sicht einen Wert haben, sei es durch Backlinks oder Traffic, lohnt es sich, 301 auf eine relevante Seite umzuleiten, um dieses Link-Eigenkapital auf der Website zu konsolidieren.
Wenn die Seite interne Links enthält und Sie keine geeignete Seite zum Umleiten haben, sollten diese internen Links entfernt oder durch eine 200-Statuscodeseite ersetzt werden.
Wann man eine Seite löscht – Wenn die Seite keinen Zweck erfüllt und wenig Wert in Bezug auf Backlinks oder Traffic hat, kann es sich lohnen, sie zu löschen. Wenn es einen Wert aus Benutzer- oder SEO-Sicht gibt, sollten Sie ihn mit einem Noindex-Tag oder einer 301-Weiterleitung auf eine relevante Seite beibehalten.
Tool zum Entfernen der Google Search Console
Mit dem Tool zum Entfernen der Google Search Console können Sie die Suchergebnisse Ihrer Website für Websites, die Sie in der Google Search Console besitzen, vorübergehend blockieren. Es ist erwähnenswert, dass dies keine dauerhafte Lösung ist.
Wenn Sie eine Seite schnell aus den Suchergebnissen entfernen möchten, ist dies eine gute Option. Wenn Sie eine Seite dauerhaft entfernen möchten, empfiehlt Google, ihr entweder den Status 404 oder 410 zu geben, den Zugriff auf den Inhalt mithilfe eines Kennworts zu blockieren oder der Seite ein Noindex-Tag zu geben.
Weitere Details finden Sie auf dieser Google Webmaster-Seite.
Wann Sie das Entfernungstool der Google Search Console verwenden sollten – Wenn Sie eine Seite schnell entfernen müssen. Wenn Sie die Seite dauerhaft entfernen müssen, verwenden Sie ein Noindex-Tag oder geben Sie ihr den Status 404 oder 410.
Kanonische Tags
Ein kanonisches Tag ist ein HTML-Codeausschnitt, der sich im <head> der Seite befindet und zum Definieren der Primärversion für Seiten verwendet wird, die ähnlich oder dupliziert sind. Canonical-Tags helfen, Probleme zu vermeiden, die durch doppelte oder nahezu doppelte Inhalte auf mehreren URLs verursacht werden.
Siehe das folgende Beispiel eines Canonical-Tags auf der Brainlabs-Homepage:

Wenn Sie eine Seite auf eine andere kanonisieren, möchten Sie nicht, dass diese Seite in den Suchergebnissen angezeigt wird, und Sie möchten, dass stattdessen eine andere Version dieser Seite angezeigt wird.
Im Gegensatz zu Noindex-Tags, die Befehle sind, können kanonische Tags von Google ignoriert werden. Google kann diese Seiten weiterhin crawlen, die kanonischen Tags anzeigen und dann entscheiden, ob die Seite in den Suchergebnissen angezeigt werden soll oder nicht.
Verwendung kanonischer Tags – Kanonische Tags sollten verwendet werden, wenn mehrere doppelte oder ähnliche Seiten vorhanden sind. Sie sollten die Nicht-Master-Versionen auf eine primäre Version einer Seite kanonisieren, um Google anzuzeigen, dass die Master-Version die einzige Version ist, die Sie in den Suchergebnissen haben möchten. Dadurch werden auch die Signale von jeder dieser URLs auf der einen Masterseite konsolidiert.
Ein Paradebeispiel für die Verwendung kanonischer Tags sind Seiten mit Parametern. Diese Seiten können aufgrund dieser Parameter genau denselben Inhalt, aber unterschiedliche URLs haben. Canonical-Tags können dabei helfen, die korrekte Version einer Seite zu gewährleisten, nicht eine der anderen Versionen.
Beispiel

Final thoughts…
Es gibt eine Reihe von Möglichkeiten, den Inhalt in den Suchergebnissen zu entfernen oder zu steuern. Der Schlüssel ist, sicherzustellen, dass Sie die beste Option für Ihre spezielle Situation wählen, nicht versuchen, sie alle auf einmal zu tun!
