det er en rekke tilfeller der du kanskje ikke vil at sider skal vises I SERPS, og dette blogginnlegget diskuterer de forskjellige måtene vi kan gjøre dette på.
de viktigste måtene å holde en side ut av søkeresultatene er:
- Noindex tagger
- Blokkering på roboter.txt
- Slette siden
- Verktøyet For Fjerning Av Google Search Console.
- Canonical tags
- hva slags innhold ville vi ikke ønsker å vises i SERPs?
- Hvordan Finner Google innhold som skal vises i søkeresultatene?
- Hvordan kan vi kontrollere hvilke sider som rangeres i søkeresultatene?
- Noindex Tags
- Blokkering I Roboter txt
- Slette siden
- Verktøyet For Fjerning Av Google Search Console
- Canonical tags
- Final thoughts…
hva slags innhold ville vi ikke ønsker å vises i SERPs?
det finnes en rekke ulike typer sider vi ikke ønsker å være søkbare På Google eller andre søkemotorer.
Eksempler inkluderer:
- ppc destinasjonssider
- Takk sider
- Admin sider
- Interne søkeresultater
Vi kan også være lurt å skjule sider Fra Google for en rekke årsaker, inkludert:
- sideduplisering – for å hindre at flere versjoner av samme side vises i søkeresultatene.
- Nøkkelordkannibalisering – for å stoppe to eller flere lignende sider fra å konkurrere med hverandre for et bestemt søkeord
- Gjennomsøkingsbudsjettavfall – vil jeg diskutere Gjennomsøking i denne delen, Men Dette refererer Til At Google bruker for mye tid på å oppdage sider med lavere verdi på nettstedet ditt, i stedet For å prioritere de viktige tingene.
Hvordan Finner Google innhold som skal vises i søkeresultatene?
Før vi dykker inn i de forskjellige måtene vi kan forhindre at sider vises i søkeresultatene, er Det verdt å forstå prosessen Som Google bruker til å finne og til slutt rangere sider.
1) Crawling – Dette Er Googles måte å oppdage nytt innhold på. Ved hjelp av programmer, ofte referert til som edderkopper eller crawlere, Besøker Google forskjellige nettsider og følger koblingene på dem for å finne nye sider. Hvert nettsted har et bestemt «gjennomsøkingsbudsjett» eller mengden ressurser det tildeler til hvert nettsted.
2) Indeksering – Når Google har funnet innholdet, opprettholder Det en kopi av innholdet og lagrer det i det som kalles en indeks.
3) Rangering-rekkefølgen på disse forskjellige sidene i søkeresultatene kalles rangering. Google får en spørring, finner ut søkeintensjonen bak spørringen, og ser deretter på indeksen for å returnere de beste mulige resultatene.
Google bruker en rekke forskjellige beregninger, kjent som algoritmer, for å bestemme hvilke som er de beste resultatene å tjene og bestiller dem fra mest relevante til minst relevante.
Hvordan kan vi kontrollere hvilke sider som rangeres i søkeresultatene?
Noindex Tags
Noindex tags er et direktiv som forteller Google «jeg vil ikke at denne siden skal indekseres og derfor ikke vil at Den skal vises i søkeresultatene.»
Når Google neste gjennomsøker den siden og ser noindex-direktivene, vil den fjerne den siden fra indeksen og dermed søkeresultatene.
disse noindex-kodene kan implementeres på to måter:
- ved å inkludere dem i sidens HTML-kode
- ved å returnere en noindex-header I HTTP-forespørselen.
Noindex-koder implementert I HTML ville se noe ut som dette:<meta name="robots" content="noindex">
Noindex-koder implementert VIA HTTP-header vil se slik ut:HTTP/... 200 OK
…
X-Robots-Tag: noindex
CMS-plattformer, For Eksempel WordPress, lar deg legge til noindex-koder på sider, noe som betyr at du ikke trenger en utvikler for å implementere dette.
Det Er Viktig At Google må kunne gjennomsøke disse sidene for å se «noindex» – taggen og deretter fjerne siden fra indeksen.
Når du skal bruke noindex-tagger – hvis det er sider på nettstedet ditt som fortsatt tjener et formål, men du ikke vil vises i søkeresultatene, er dette et godt alternativ.
Blokkering I Roboter txt
Roboter.txt er en tekstfil som brukes til å instruere webroboter hvordan de skal oppføre seg når de besøker nettstedet ditt, og kan brukes til å diktere til søkemotorroboter om de kan eller ikke kan gjennomsøke deler av et nettsted.
Se eksemplet nedenfor På Nikes roboter.txt-fil som lever på https://www.nike.com/robots.txt
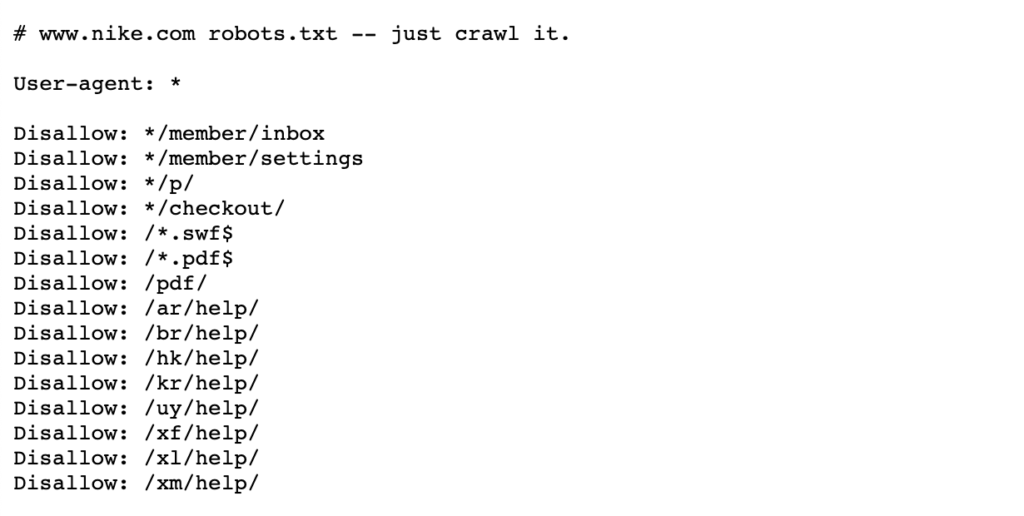
Bruke roboter.txt for å blokkere bestemte sidebaner, for eksempel /admin/, betyr At Googlebot eller andre søkeroboter ikke engang besøker disse sidene-derfor vises de ikke i søkeresultatene. Dette kan bevare gjennomsøkingsbudsjettet for viktige sider i stedet for å fokusere på mindre viktige sider.
Merk: blokkerer en sidebane i roboter.txt stopper Google fra å lagre siden i utgangspunktet, men det sletter ikke eller endrer det som er lagret. Derfor, Hvis en side allerede vises i søkeresultatene, Har Google allerede gjennomsøkt Og deretter indeksert denne siden.
hvis du trenger en side slettet, blokkerer du den i roboter.txt vil aktivt forhindre at det skjer. I så fall er det best å legge til en noindex-tag for å fjerne disse sidene Fra Googles indeks, og når de er fjernet, kan du da blokkere i roboter.txt.
Flere detaljer finner du på Denne Google Search Central-siden.
når skal du blokkere sider i roboter.txt-Når du har bestemte sidebaner eller større deler Av nettstedet ditt som Du ikke Vil At Google skal gjennomgå, er dette det beste alternativet.
hvis en side eller samling av sider allerede vises I SERPs, må du først noindex dem og vente på at de skal fjernes før du legger til robotene.txt-fil.
Slette siden
det mest åpenbare svaret, du kanskje trodde, ville være å bare slette siden om det er ved å gi den en 404 eller en 410 statuskode.
Begge statuskoder tjener samme funksjon ved At Google vil fjerne siden fra indeksen når den neste gjennomsøker den siden, selv om en 410-status kan være litt raskere i Henhold Til Googles John Mueller.
FRA ET SEO-perspektiv, hvis disse sidene har verdi, enten det er gjennom tilbakekoblinger eller trafikk, ville det være verdt 301 omdirigering til en relevant side for å konsolidere den koblingsverdien på nettstedet.
Alternativt, Hvis siden har interne lenker og du ikke har en passende side å omdirigere til, bør disse interne koblingene fjernes eller erstattes med en 200 statuskodeside.
når du skal slette en side – hvis siden ikke tjener noe formål og har liten verdi når det gjelder tilbakekoblinger eller trafikk, kan det være verdt å slette. Hvis det er noen verdi enten fra et brukerperspektiv eller ET SEO-perspektiv, bør du vurdere å holde det med en noindex-tag eller 301 omdirigere til en relevant side.
Verktøyet For Fjerning Av Google Search Console
Verktøyet For Fjerning Av Google Search Console kan brukes til å midlertidig blokkere søkeresultater fra nettstedet ditt for nettsteder du eier På Google Search Console. Det er verdt å merke seg at dette ikke er en permanent løsning.
hvis du raskt vil fjerne en side fra søkeresultatene, er dette et godt alternativ. Hvis Du vil fjerne en side permanent, Anbefaler Google at Du enten gir den en 404-eller 410-status, blokkerer tilgang til innholdet ved å bruke et passord eller gir siden en noindex-kode.
Flere detaljer finner du på Denne Google Webmasters siden.
Når Skal Du bruke Google Search Console ‘ S Fjerningsverktøy – når du trenger å bli kvitt en side raskt. Hvis du trenger å fjerne siden permanent, bruk en noindex-kode eller gi den en 404-eller 410-status.
EN canonical tag er ET utdrag AV HTML-kode som lever i < hodet> på siden og brukes til å definere den primære versjonen for sider som er like eller duplikater. Kanoniske tagger bidrar til å forhindre problemer forårsaket av duplikat eller nær duplikat innhold som vises på flere Nettadresser.
Se eksemplet nedenfor på en kanonisk tag på Brainlabs hjemmeside:

Hvis du kanoniserer en side til en annen, sier du at du ikke vil at siden skal vises i søkeresultatene, og du foretrekker at en annen versjon av siden skal vises i stedet.
i motsetning til noindex-koder som er ordrer, kan kanoniske koder ignoreres Av Google. Google kan fortsatt gjennomgå disse sidene, se de kanoniske kodene, og deretter bestemme om siden skal vises i søkeresultatene eller ikke.
Når man skal bruke canonical tags – Canonical tags bør brukes når det er flere like eller lignende sider rangering. Du vil ønske å kanonisere de ikke-masterversjonene til en primærversjon Av en side for Å indikere For Google At masterversjonen er Den eneste versjonen du vil ha i søkeresultatene. Dette vil også konsolidere signalene fra Hver Av Disse Nettadressene på den ene malsiden.
et godt eksempel for bruk av kanoniske koder er for sider som har parametere. Disse sidene kan ha nøyaktig samme innhold, men forskjellige Nettadresser på grunn av disse parameterne. Canonical tags kan bidra til å sikre riktig versjon av en side rangerer, ikke noen av de andre versjonene.
Eksempel

Final thoughts…
det finnes en rekke måter å fjerne eller kontrollere hvilket innhold som vises i søkeresultatene. Nøkkelen er å sikre at du velger det beste alternativet for din situasjon, ikke prøver å gjøre dem alle på en gang!
