Hay una serie de casos en los que es posible que no desee que las páginas aparezcan en las SERPS, y esta publicación de blog analiza las diferentes formas en que podemos hacer esto.
Las principales formas de mantener una página fuera de los resultados de búsqueda son:
- Etiquetas Noindex
- Bloqueo en robots.txt
- Eliminar la página
- Herramienta de eliminación de Google Search Console.
- Etiquetas canónicas
- ¿Qué tipo de contenido no querríamos que apareciera en las SERPs?
- ¿Cómo encuentra Google el contenido que aparecerá en los resultados de búsqueda?
- ¿Cómo podemos controlar qué páginas se clasifican en los resultados de búsqueda?
- Etiquetas Noindex
- Bloqueo en robots txt
- Borrado de la página
- La herramienta de eliminación de Google Search Console
- Etiquetas canónicas
- Pensamientos finales
¿Qué tipo de contenido no querríamos que apareciera en las SERPs?
Hay varios tipos diferentes de páginas que no querríamos que se pudieran buscar en Google u otros motores de búsqueda.
Los ejemplos incluyen:
- Páginas de destino PPC
- Páginas de agradecimiento
- Páginas de administración
- Resultados de búsqueda internos
Es posible que también queramos ocultar páginas de Google por varias razones,:
- Duplicación de páginas: para evitar que aparezcan numerosas versiones de la misma página en los resultados de búsqueda.
- Canibalización de palabras clave – Para evitar que dos o más páginas similares compitan entre sí por una palabra clave en particular
- Desperdicio de presupuesto de rastreo – Discutiré el rastreo en esta sección, pero esto se refiere a que Google pasa demasiado tiempo descubriendo páginas de menor valor en tu sitio, en lugar de priorizar las cosas importantes.
¿Cómo encuentra Google el contenido que aparecerá en los resultados de búsqueda?
Antes de profundizar en las diferentes formas en que podemos evitar que las páginas aparezcan en los resultados de búsqueda, vale la pena comprender el proceso que utiliza Google para encontrar y, en última instancia, clasificar las páginas.
1) Rastreo: Esta es la forma de Google de descubrir contenido nuevo. Usando programas, a menudo denominados arañas o rastreadores, Google visita diferentes páginas web y sigue los enlaces en ellas para encontrar nuevas páginas. Cada sitio tiene un cierto «presupuesto de rastreo» o cantidad de recursos que asigna a cada sitio.
2) Indexación – Una vez que Google ha encontrado el contenido, mantiene una copia de ese contenido y lo almacena en lo que se llama un índice.
3) Clasificaciones: El orden de estas diferentes páginas en los resultados de búsqueda se conoce como clasificación. Google obtiene una consulta, calcula la intención de búsqueda detrás de esa consulta y luego mira el índice para obtener los mejores resultados posibles.
Google utiliza una variedad de cálculos diferentes, conocidos como algoritmos, para determinar cuáles son los mejores resultados para servir y ordenarlos de los más relevantes a los menos relevantes.
¿Cómo podemos controlar qué páginas se clasifican en los resultados de búsqueda?
Etiquetas Noindex
Las etiquetas Noindex son una directiva que le dice a Google » No quiero que esta página se indexe y, por lo tanto, no quiero que aparezca en los resultados de búsqueda.»
Cuando Google next rastree esa página y vea las directivas noindex, eliminará esa página de su índice y, por lo tanto, de los resultados de búsqueda.
Estas etiquetas noindex se pueden implementar de dos maneras:
- Incluyéndolos en el código HTML de la página
- Devolviendo un encabezado noindex en la solicitud HTTP.
Las etiquetas Noindex implementadas en el HTML se verían algo como esto:<meta name="robots" content="noindex">
Las etiquetas Noindex implementadas a través del encabezado HTTP se verían así:HTTP/... 200 OK
…
X-Robots-Tag: noindex
Las plataformas CMS, como WordPress, le permiten agregar etiquetas noindex a las páginas, lo que significa que no necesitaría un desarrollador para implementar esto.
Es importante destacar que Google necesitará poder rastrear estas páginas para ver la etiqueta «noindex» y luego eliminar la página de su índice.
Cuándo usar etiquetas noindex: Si hay páginas en su sitio que aún sirven para un propósito, pero no desea aparecer en los resultados de búsqueda, esta es una buena opción.
Bloqueo en robots txt
Robots.txt es un archivo de texto que se usa para instruir a los robots web sobre cómo comportarse cuando visitan su sitio y se puede usar para dictar a los rastreadores de motores de búsqueda si pueden o no rastrear partes de un sitio web.
Vea el siguiente ejemplo de robots de Nike.archivo txt que vive en https://www.nike.com/robots.txt
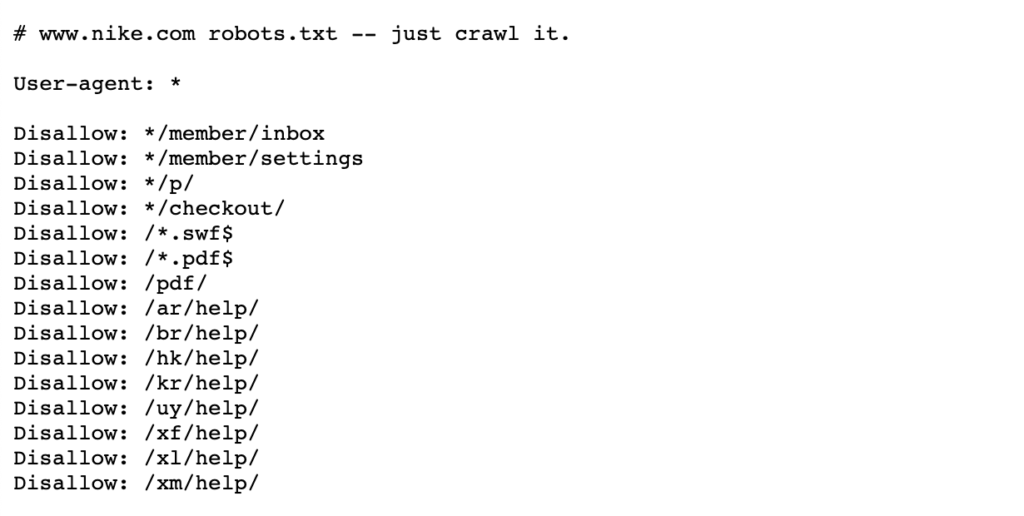
Usando robots.txt para bloquear ciertas rutas de página, como /admin/, por ejemplo, significa que el Googlebot u otros rastreadores de búsqueda ni siquiera visitarán estas páginas – por lo que no aparecerán en los resultados de búsqueda. Esto puede preservar el presupuesto de rastreo para páginas más importantes en lugar de enfocarse en páginas menos importantes.
Nota: bloquear una ruta de página en robots.txt impide que Google guarde la página en primer lugar, pero no elimina ni cambia lo que se ha guardado. Por lo tanto, si una página ya está apareciendo en los resultados de búsqueda, Google ya ha rastreado y luego indexado esta página.
Si necesita eliminar una página, bloquearla en robots.txt evitará activamente que eso suceda. En ese caso, lo mejor es agregar una etiqueta noindex para eliminar estas páginas del índice de Google y una vez que se eliminen todas, puede bloquear los robots.txt.
Se pueden encontrar más detalles en esta página Central de búsqueda de Google.
Cuándo bloquear páginas en robots.txt: Cuando tienes rutas de página específicas o secciones más grandes de tu sitio que no quieres que Google rastree, esta es tu mejor opción.
Sin embargo, si una página o colección de páginas ya está apareciendo en las SERPs, primero tendrá que no indexarlas y esperar a que se eliminen antes de agregar los robots.archivo txt.
Borrado de la página
La respuesta más obvia, usted puede haber pensado, sería simplemente eliminar la página, ya sea dándole un 404 o 410 del código de estado.
Ambos códigos de estado tienen la misma función, ya que Google eliminará la página de su índice la próxima vez que rastree esa página, aunque un estado 410 puede ser un poco más rápido según John Mueller de Google.
Desde una perspectiva SEO, si estas páginas tienen valor, ya sea a través de backlinks o tráfico, valdría la pena redirigir a una página relevante para consolidar ese valor de enlace en el sitio.
Alternativamente, si la página tiene enlaces internos y no tiene una página adecuada a la que redirigir, estos enlaces internos deben eliminarse o reemplazarse por una página de código de estado de 200.
Cuándo eliminar una página – Si la página no tiene ningún propósito y tiene poco valor en términos de enlaces de retroceso o tráfico, puede valer la pena eliminarla. Si hay algún valor, ya sea desde la perspectiva del usuario o desde la perspectiva del SEO, considera mantenerlo con una etiqueta noindex o redireccionar 301 a una página relevante.
La herramienta de eliminación de Google Search Console
La herramienta de eliminación de Google Search Console se puede utilizar para bloquear temporalmente los resultados de búsqueda de su sitio para los sitios que posee en Google Search Console. Vale la pena señalar que esto no es una solución permanente.
Si desea eliminar rápidamente una página de los resultados de búsqueda, esta es una buena opción. Si desea eliminar permanentemente una página, Google recomienda darle un estado 404 o 410, bloquear el acceso al contenido mediante una contraseña o darle a la página una etiqueta noindex.
Se pueden encontrar más detalles en esta página de Google Webmasters.
Cuándo usar la herramienta de eliminación de Google Search Console: Cuando necesita deshacerse de una página rápidamente. Si necesitas eliminar la página de forma permanente, usa una etiqueta noindex o dale un estado 404 o 410.
Etiquetas canónicas
Una etiqueta canónica es un fragmento de código HTML que se encuentra en el encabezado <> de la página y se utiliza para definir la versión principal para páginas similares o duplicadas. Las etiquetas canónicas ayudan a evitar problemas causados por el contenido duplicado o casi duplicado que aparece en varias URL.
Vea el ejemplo a continuación de una etiqueta canónica en la página de inicio de Brainlabs:

Si canonizas una página a otra, estás diciendo que no quieres que esa página aparezca en los resultados de búsqueda y que preferirías que aparezca otra versión de esa página en su lugar.
A diferencia de las etiquetas noindex que son pedidos, las etiquetas canónicas pueden ser ignoradas por Google. Google aún puede rastrear estas páginas, ver las etiquetas canónicas y luego decidir si la página debe aparecer o no en los resultados de búsqueda.
Cuándo usar etiquetas canónicas: Las etiquetas canónicas se deben usar cuando hay varias páginas duplicadas o similares en la clasificación. Querrá canonizar las versiones no maestras a una versión principal de una página para indicar a Google que la versión maestra es la única versión que desea en los resultados de búsqueda. Esto también consolidará las señales de cada una de estas URL en una sola página maestra.
Un ejemplo principal para usar etiquetas canónicas es para páginas que tienen parámetros. Estas páginas pueden tener exactamente el mismo contenido pero diferentes URLs debido a estos parámetros. Las etiquetas canónicas pueden ayudar a garantizar que la versión correcta de una página se clasifique, no cualquiera de las otras versiones.
Ejemplo

Pensamientos finales
Hay varias formas de eliminar o controlar el contenido que aparece en los resultados de búsqueda. La clave es asegurarse de que está eligiendo la mejor opción para su situación particular, ¡no intentar hacerlas todas a la vez!
