există o serie de cazuri în care este posibil să nu doriți ca paginile să apară în SERP-uri, iar această postare pe blog discută diferitele moduri în care putem face acest lucru.
principalele modalități de a păstra o pagină în afara rezultatelor căutării sunt:
- noindex tag-uri
- blocarea pe roboți.Txt
- ștergerea paginii
- instrumentul de eliminare a consolei de căutare Google.
- etichete canonice
- ce fel de conținut nu am dori să apară în SERP?
- cum găsește Google conținut să apară în rezultatele căutării?
- cum putem controla ce pagini se clasifică în rezultatele căutării?
- etichetele Noindex
- blocarea în roboți Txt
- ștergerea paginii
- instrumentul de eliminare Google Search Console
- etichete canonice
- gânduri finale…
ce fel de conținut nu am dori să apară în SERP?
există o serie de tipuri diferite de pagini pe care nu am dori să le căutăm pe Google sau pe alte motoare de căutare.
Exemplele includ:
- pagini de destinație PPC
- Vă mulțumim pagini
- Admin pagini
- rezultatele căutării interne
de asemenea, putem dori să ascundem pagini de la Google din mai multe motive, inclusiv:
- duplicarea paginilor – pentru a preveni apariția mai multor versiuni ale aceleiași pagini în rezultatele căutării.
- canibalizarea cuvintelor cheie – pentru a opri două sau mai multe pagini similare să concureze între ele pentru un anumit cuvânt cheie
- risipa bugetului de accesare cu crawlere – voi discuta despre accesarea cu crawlere în această secțiune, dar aceasta se referă la faptul că Google petrece prea mult timp descoperind pagini cu valoare mai mică pe site-ul dvs., mai degrabă decât să acorde prioritate lucrurilor importante.
cum găsește Google conținut să apară în rezultatele căutării?
înainte de a ne arunca cu capul în diferitele moduri în care putem împiedica paginile să apară în rezultatele căutării, merită să înțelegem procesul pe care Google îl folosește pentru a găsi și, în cele din urmă, pentru a clasifica paginile.
1) Crawling – acesta este modul Google de a descoperi conținut nou. Folosind programe, denumite adesea păianjeni sau crawlere, Google vizitează diferite pagini web și urmărește linkurile de pe ele pentru a găsi pagini noi. Fiecare site are un anumit „buget de accesare cu crawlere” sau o cantitate de resurse pe care le alocă fiecărui site.
2) indexare – odată ce Google a găsit conținutul, menține o copie a acelui conținut și îl stochează în ceea ce se numește index.
3) clasamente – ordonarea acestor pagini diferite în rezultatele căutării este cunoscută sub numele de clasare. Google primește o interogare, își dă seama de intenția de căutare din spatele acelei interogări și apoi se uită la index pentru a returna cele mai bune rezultate posibile.
Google folosește o serie de calcule diferite, cunoscute sub numele de algoritmi, pentru a determina care sunt cele mai bune rezultate pentru a le servi și le comandă de la cele mai relevante la cele mai puțin relevante.
cum putem controla ce pagini se clasifică în rezultatele căutării?
etichetele Noindex
etichetele Noindex sunt o directivă care spune Google „nu vreau ca această pagină să fie indexată și, prin urmare, nu vreau să apară în rezultatele căutării.”
când Google va accesa cu crawlere pagina respectivă și va vedea directivele noindex, va elimina pagina respectivă din index și, prin urmare, din rezultatele căutării.
aceste etichete noindex pot fi implementate în două moduri:
- prin includerea lor în codul HTML al paginii
- prin returnarea unui antet noindex în cererea HTTP.
tag-uri Noindex puse în aplicare în HTML ar arata ceva de genul asta:<meta name="robots" content="noindex">
etichetele Noindex implementate prin antetul HTTP ar arăta astfel:HTTP/... 200 OK
…
X-Robots-Tag: noindex
platformele CMS, cum ar fi WordPress, vă permit să adăugați etichete noindex la pagini, ceea ce înseamnă că nu aveți nevoie de un dezvoltator pentru a implementa acest lucru.
important, Google va trebui să poată accesa cu crawlere aceste pagini pentru a vedea eticheta „noindex” și apoi să elimine pagina din index.
când să utilizați etichetele noindex – dacă există pagini pe site-ul dvs. care încă servesc unui scop, dar nu doriți să apară în rezultatele căutării, aceasta este o opțiune bună.
blocarea în roboți Txt
roboți.txt este un fișier text folosit pentru a instrui roboții web cum să se comporte atunci când vă vizitează site-ul și poate fi folosit pentru a dicta crawlerelor motoarelor de căutare dacă pot sau nu pot accesa cu crawlere părți ale unui site web.
vedeți exemplul de mai jos al roboților Nike.fișier txt care trăiește la https://www.nike.com/robots.txt
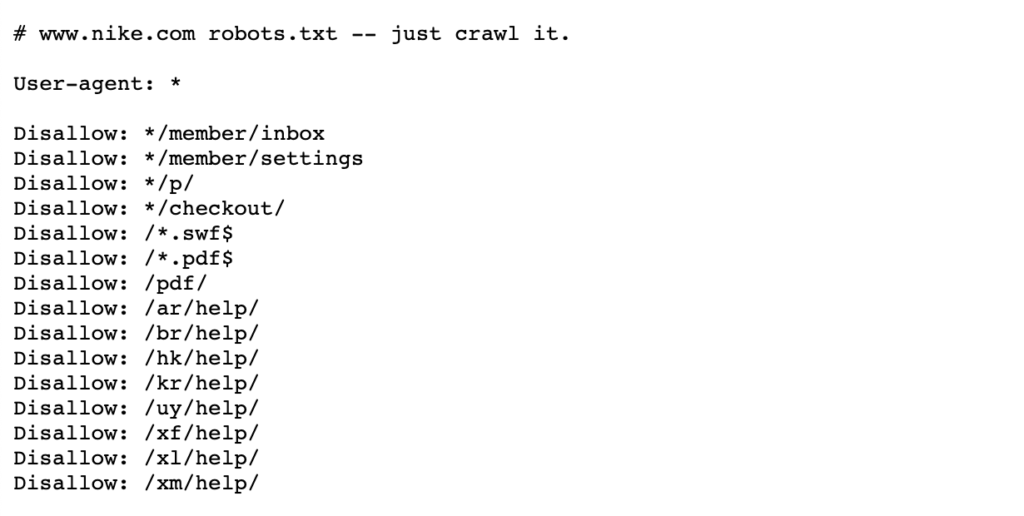
folosind roboți.TXT pentru a bloca anumite căi de pagină ,cum ar fi/ admin/, de exemplu, înseamnă că Googlebot sau alte crawlere de căutare nici măcar nu vor vizita aceste pagini – prin urmare, nu vor apărea în rezultatele căutării. Acest lucru poate păstra bugetul de accesare cu crawlere pentru pagini mai importante, mai degrabă decât să se concentreze pe pagini mai puțin importante.
notă: blocarea unei căi de pagină în roboți.txt oprește Google să salveze pagina în primul rând, dar nu șterge sau modifică ceea ce a fost salvat. Prin urmare, dacă o pagină apare deja în rezultatele căutării, atunci Google a accesat deja cu crawlere și apoi a indexat această pagină.
dacă aveți nevoie de o pagină ștearsă, atunci blocați-o în roboți.txt va împiedica în mod activ acest lucru. În acest caz, cel mai bun lucru de făcut este să adăugați o etichetă noindex pentru a elimina aceste pagini din indexul Google și, odată ce toate sunt eliminate, puteți bloca roboții.txt.
mai multe detalii pot fi găsite pe această pagină Centrală de căutare Google.
când să blocați paginile în roboți.txt-când aveți anumite căi de pagină sau secțiuni mai mari ale site-ului dvs. pe care nu doriți ca Google să le acceseze cu crawlere, acesta este cel mai bun pariu.
dacă o pagină sau o colecție de pagini apare deja în SERP-uri, totuși, va trebui să le eliminați mai întâi și să așteptați să fie eliminate înainte de a adăuga roboții.fișier txt.
ștergerea paginii
răspunsul cel mai evident, poate ați crezut, ar fi să ștergeți pur și simplu pagina dacă aceasta este oferindu-i un cod de stare 404 sau 410.
ambele coduri de stare au aceeași funcție, deoarece Google va elimina pagina din indexul său atunci când va accesa cu crawlere pagina respectivă, deși un statut 410 poate fi ușor mai rapid, potrivit lui John Mueller de la Google.
din punct de vedere SEO, dacă aceste pagini dețin valoare, fie că este vorba de backlink sau trafic, ar merita redirecționarea 301 către o pagină relevantă pentru a consolida acel link equity pe site.
alternativ, dacă pagina are legături interne și nu aveți o pagină adecvată la care să redirecționați, aceste legături interne ar trebui eliminate sau înlocuite cu o pagină cu 200 de coduri de stare.
când să ștergeți o pagină – dacă pagina nu servește nici unui scop și are o valoare mică în ceea ce privește backlink-urile sau traficul, poate merita să ștergeți. Dacă există o anumită valoare fie din perspectiva utilizatorului, fie din perspectiva SEO, luați în considerare păstrarea acesteia cu o etichetă noindex sau redirecționarea 301 către o pagină relevantă.
instrumentul de eliminare Google Search Console
instrumentul de eliminare Google Search Console poate fi utilizat pentru a bloca temporar rezultatele căutării de pe site-ul dvs. pentru site-urile pe care le dețineți pe Google Search Console. Este demn de remarcat faptul că aceasta nu este o soluție permanentă.
dacă doriți să eliminați rapid o pagină din rezultatele căutării, aceasta este o opțiune bună. Dacă doriți să eliminați definitiv o pagină, Google recomandă fie să îi acordați o stare 404 sau 410, blocarea accesului la conținut utilizând o parolă sau acordarea paginii o etichetă noindex.
mai multe detalii pot fi găsite pe această pagină webmasteri Google.
când să utilizați instrumentul de eliminare Google Search Console – când trebuie să scăpați rapid de o pagină. Dacă trebuie să eliminați pagina permanent, utilizați o etichetă noindex sau dați-i o stare 404 sau 410.
etichete canonice
o etichetă canonică este un fragment de cod HTML care trăiește în capul< > al paginii și este utilizat pentru a defini versiunea primară pentru paginile care sunt similare sau duplicate. Etichetele canonice ajută la prevenirea problemelor cauzate de conținutul duplicat sau aproape duplicat care apare pe Mai multe adrese URL.
vedeți exemplul de mai jos al unei etichete canonice pe pagina principală Brainlabs:

dacă canonicalizați o pagină pe alta, spuneți că nu doriți ca acea pagină să apară în rezultatele căutării și preferați să apară în schimb o altă versiune a acelei pagini.
spre deosebire de etichetele noindex care sunt comenzi, etichetele canonice pot fi ignorate de Google. Google poate încă să acceseze cu crawlere aceste pagini, să vadă etichetele canonice și apoi să decidă dacă pagina ar trebui să apară sau nu în rezultatele căutării.
când se utilizează etichete canonice – etichetele canonice trebuie utilizate atunci când există mai multe pagini duplicate sau similare. Veți dori să canonicalizați versiunile non master la o versiune principală a unei pagini pentru a indica Google că versiunea master este singura versiune dorită în rezultatele căutării. Acest lucru va consolida, de asemenea, semnalele de la fiecare dintre aceste adrese URL pe o pagină principală.
un prim exemplu pentru utilizarea etichetelor canonice este pentru paginile care au parametri. Aceste pagini pot avea exact același conținut, dar adrese URL diferite datorită acestor parametri. Etichetele canonice pot ajuta la asigurarea versiunii corecte a rangurilor unei pagini, nu la oricare dintre celelalte versiuni.
exemplu

gânduri finale…
există o serie de moduri de a elimina sau de a controla conținutul care apare în rezultatele căutării. Cheia este să vă asigurați că alegeți cea mai bună opțiune pentru situația dvs. particulară, nu încercați să le faceți pe toate simultan!
