SERPにページを表示したくない場合がいくつかありますが、このブログ記事ではこれを行うためのさまざまな方法について説明しています。
検索結果からページを除外する主な方法は次のとおりです:
- noindexタグ
- ロボットでブロックします。txt
- ページを削除する
- Google Search Consoleの削除ツール。
- Canonicalタグ
Serpにはどのようなコンテンツを表示したくないのですか?
Googleや他の検索エンジンでは検索したくないさまざまな種類のページがあります。
:
- PPCランディングページ
- ありがとうページ
- 管理ページ
- 内部検索結果
私たちはまた、以下のようないくつかの理由でGoogleからページを非表示にすること:
- ページの重複–同じページの多数のバージョンが検索結果に表示されないようにします。
- キーワードの共食い–特定のキーワード
- クロール予算の浪費のために互いに競合から二つ以上の類似したページを停止するには–私はこのセクションでクロー
Googleは検索結果に表示されるコンテンツをどのように検索しますか?
検索結果にページが表示されないようにするさまざまな方法に飛び込む前に、Googleがページを検索して最終的にランク付けするプロセスを理解する価値
1)クロール–これは新しいコンテンツを発見するGoogleの方法です。 頻繁にくもかクローラーと言われるプログラムを使用して、Googleは異なったwebページを訪問し、新しいページを見つけるためにそれらのリンクに続く。 各サイトには、特定の”クロール予算”または各サイトに割り当てるリソースの量があります。
2)インデックス作成–Googleはコンテンツを見つけたら、そのコンテンツのコピーを保持し、インデックスと呼ばれるものに保存します。
3)ランキング–検索結果内のこれらの異なるページの順序はランキングとして知られています。 Googleはクエリを取得し、そのクエリの背後にある検索インテントを把握し、インデックスを調べて可能な限り最高の結果を返します。
Googleは、アルゴリズムと呼ばれるさまざまな計算を使用して、提供する最良の結果を決定し、最も関連性の高いものから最も関連性の低いものに順
検索結果のページランクを制御するにはどうすればよいですか?
Noindexタグ
Noindexタグは、Googleに”このページをインデックス化したくないので、検索結果に表示したくない”と指示するディレクティブです。”
Google nextがそのページをクロールしてnoindexディレクティブを表示すると、そのページがインデックスから削除され、検索結果から削除されます。
これらのnoindexタグは、次の2つの方法で実装できます:
- HTTP要求でnoindexヘッダーを返すことによって、ページのHTMLコード
- にそれらを含めることによって。
HTMLに実装されたNoindexタグは次のようになります:<meta name="robots" content="noindex">
HTTPヘッダーを介して実装されたNoindexタグは次のようになります:HTTP/... 200 OK
…
X-Robots-Tag: noindex
WordPressなどのCMSプラットフォームでは、ページにnoindexタグを追加することができます。重要なことに、Googleはこれらのページをクロールして「noindex」タグを表示し、そのインデックスからページを削除できる必要があります。
noindexタグを使用する場合–サイトにまだ目的を果たしているページがあるが、検索結果に表示したくない場合は、これが良いオプションです。
txtは、彼らがあなたのサイトを訪問したときに動作する方法をウェブロボットに指示するために使用されるテキストファイルであり、彼らはまた
ナイキのロボットの下の例を参照してください。に住んでいるtxtファイルhttps://www.nike.com/robots.txt
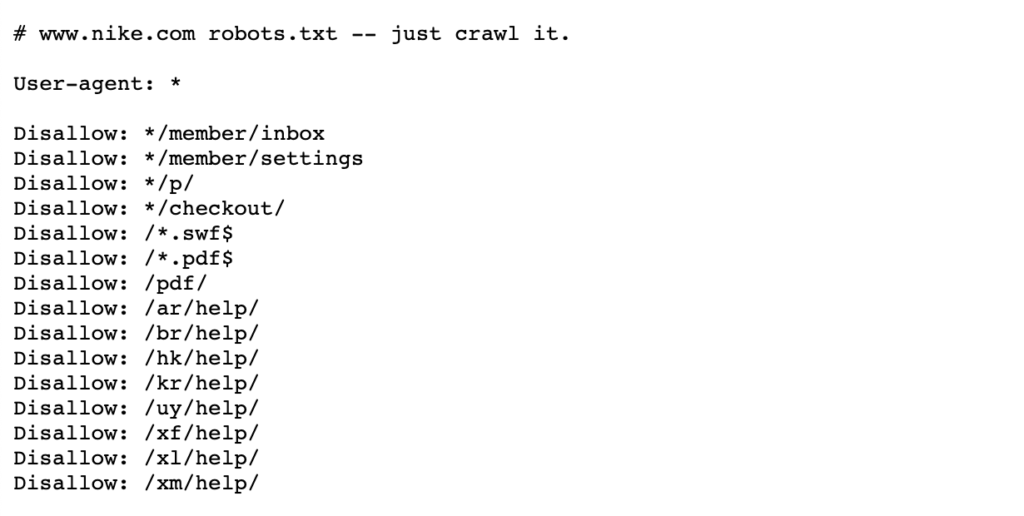
ロボットを使用しています。たとえば、/admin/などの特定のページパスをブロックするtxtは、Googlebotや他の検索クローラーがこれらのページにアクセスしないことを意味します。 これにより、重要度の低いページに集中するのではなく、重要度の高いページのクロール予算を維持できます。
注:ロボットのページパスをブロックします。txtは、最初の場所でページを保存するからGoogleを停止しますが、それは削除したり、保存されたものを変更しません。 したがって、ページがすでに検索結果に表示されている場合、Googleはすでにクロールしてからこのページのインデックスを作成しています。
ページを削除する必要がある場合は、ロボットでブロックします。txtは積極的に起こってからそれを防ぐことができます。 その場合、noindexタグを追加してGoogleのインデックスからこれらのページを削除し、それらがすべて削除されたら、ロボットでブロックすることができます。txt。
詳細はGoogle検索の中央ページで見つけることができます。
ロボットのページをブロックするとき。txt-Googleがクロールしたくない特定のページパスまたはサイトのより大きなセクションがある場合、これが最善の策です。
ただし、ページまたはページのコレクションがすでにSerpに表示されている場合は、最初にインデックスを付けず、ロボットを追加する前に削除されるのを待つ必要があります。txtファイル。
ページを削除する
最も明白な答えは、404または410ステータスコードを与えることによって、ページを削除することです。
両方のステータスコードは、googleが次にそのページをクロールするときにページをインデックスから削除するという点で同じ機能を果たしますが、GoogleのJohn Muellerによると410
SEOの観点から、これらのページが価値を保持すれば、それが被リンクか交通によってあるかどうか、場所のそのリンク公平を強化するために関連したページに方向を変える301の価値がある。
または、ページに内部リンクがあり、リダイレクト先の適切なページがない場合は、これらの内部リンクを削除するか、200ステータスコードページに置き換え
ページを削除するとき–ページが目的を果たさず、バックリンクやトラフィックの点でほとんど価値がない場合は、削除する価値があるかもしれません。 ユーザーの観点やSEOの観点から何らかの価値がある場合は、noindexタグまたは301を使用して関連するページにリダイレクトすることを検討してください。
Google Search Consoleの削除ツール
Google Search Consoleの削除ツールを使用すると、Google Search Consoleで所有しているサイトのサイトからの検索結果を一時的にブロックできます。 これは永続的な修正ではないことに注意する価値があります。
検索結果からページをすばやく削除したい場合は、これが良いオプションです。 ページを完全に削除する場合は、404または410のステータスを与えるか、パスワードを使用してコンテンツへのアクセスをブロックするか、ページにnoindexタグを与
より多くの細部はgoogleのウェブマスターのページで見つけることができる。
Google Search Consoleの削除ツールを使用する場合–ページをすばやく削除する必要がある場合。 ページを永久に削除する必要がある場合は、noindexタグを使用するか、404または410ステータスを指定します。
正規タグ
正規タグは、ページの<ヘッド>に存在するHTMLコードのスニペットであり、類似または重複しているページのプライマリバージョンを定義する 正規のタグは、複数のUrlに表示される重複または重複したコンテンツの近くに起因する問題を防ぐのに役立ちます。
Brainlabsホームページの正規タグの以下の例を参照してください:

あるページを別のページに正規化する場合は、そのページを検索結果に表示したくないと言っており、代わりにそのページの別のバージョンを表示することを
注文であるnoindexタグとは対照的に、正規のタグはGoogleによって無視することができます。 Googleはこれらのページをクロールし、正規のタグを表示してから、ページを検索結果に表示するかどうかを決定できます。
canonicalタグを使用する場合–Canonicalタグは、複数の重複または類似のページランキングがある場合に使用する必要があります。 マスターバージョン以外のバージョンをページのプライマリバージョンに正規化して、マスターバージョンが検索結果に必要な唯一のバージョンであることをGoogle これにより、これらの各Urlからのシグナルも1つのマスターページに統合されます。
標準タグを使用するための典型的な例は、パラメータを持つページのためのものです。 これらのページは、これらのパラメータのために、まったく同じコンテンツを持つことができますが、異なるUrlを持つことができます。 正規タグは、他のバージョンではなく、ページランクの正しいバージョンを保証するのに役立ちます。

最終的な考え…
検索結果に表示されるコンテンツを削除または制御するには、いくつかの方法があります。 キーはあなたの特定の状態のための最もよい選択を、それらをすべてすぐにするように試みていない選んでいることを保障することである!
