eu tive uma solicitação recente para escrever uma atualização sobre como trabalhar com relatórios AWR, de modo que, como prometido, aqui está!
the automatic Workload Repository
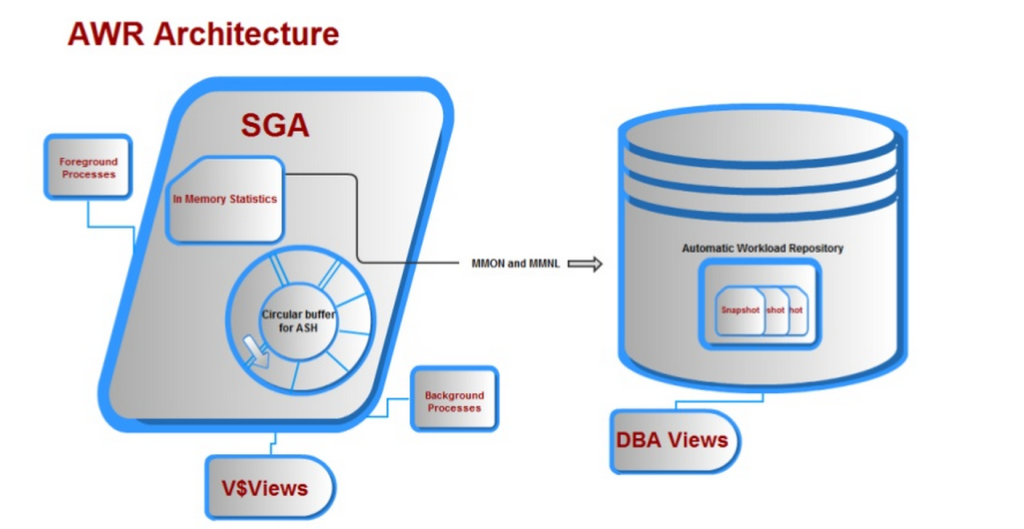
the Automatic Workload Repository, (AWR) foi um dos melhores aprimoramentos para o Oracle na versão 10g. havia uma meta bem colocada na frente do grupo de desenvolvimento quando eles foram solicitados a desenvolver um produto que:
1. Forneceu recomendações significativas de desempenho e aprimoramentos de dados de eventos de espera em relação ao seu antecessor statspack.
2. Estava sempre ligado, o que significa que os dados seriam coletados continuamente sem intervenção manual do administrador do banco de dados.
3. Não impactaria o processamento atual, tendo seus próprios processos em segundo plano e buffer de memória, tablespace designado, (SYSAUX).
4. O buffer de memória escreveria na direção oposta vs. direção que o usuário lê, eliminando problemas de simultaneidade.
junto com muitos outros requisitos, todos os itens acima foram oferecidos com o repositório de carga de trabalho automática e acabamos com uma arquitetura que se parece com isso:
Usando RMA Dados
O RMA dados é identificada pelo DBID, (Identificador do Banco de dados) e um SNAP_ID, (instantâneo identificador, que tem um begin_interval_time e end_interval_time para isolar a data e a hora da coleta de dados.) e informações sobre o que está atualmente retido no banco de dados podem ser consultadas a partir do DBA_HIST_SNAPSHOT. Os dados AWR também contêm amostras de ASH (Histórico de sessão ativa) junto com os dados de instantâneo, por padrão, cerca de 1 em cada 10 amostras.
o objetivo de usar dados AWR efetivamente realmente tem a ver com o seguinte:
1. Você identificou um verdadeiro problema de desempenho como parte de uma revisão de desempenho?
2. Houve uma reclamação do usuário ou uma solicitação para investigar uma degradação do desempenho?
3. Existe um desafio de negócios ou pergunta que precisa ser respondida para a qual a AWR pode oferecer uma resposta? (vamos quando usar AWR vs. outros recursos…)
revisão de desempenho
uma revisão de desempenho é onde você identificou um problema ou foi designado para investigar o ambiente para resolver problemas de desempenho. Tenho alguns ambientes de Gerente Corporativo disponíveis para mim, mas optei por sair para um em particular e cruzar os dedos na esperança de ter algum processamento pesado para atender aos requisitos deste post.
a maneira mais rápida de ver a carga de trabalho em seu ambiente de banco de dados a partir do Em12c, clique em destinos –> bancos de dados. Escolha visualizar por mapa de carga e, em seguida, exibirá bancos de dados por carga de trabalho. Ao ir para um ambiente específico do Enterprise Manager, descobri que foi meu dia de sorte!
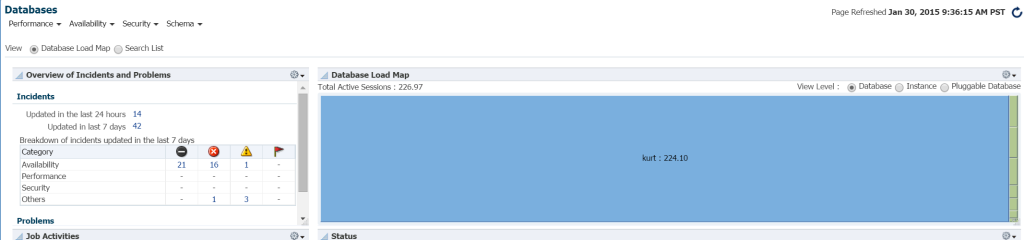 eu realmente não sei quem é Kurt que tem um banco de dados monitorado neste ambiente de controle de nuvem EM12c, mas garoto, ele é minha pessoa favorita hoje! 🙂
eu realmente não sei quem é Kurt que tem um banco de dados monitorado neste ambiente de controle de nuvem EM12c, mas garoto, ele é minha pessoa favorita hoje! 🙂
passando o cursor sobre o nome do banco de dados, (kurt) você pode ver a carga de trabalho que ele tem em execução em seu banco de dados de teste atualmente: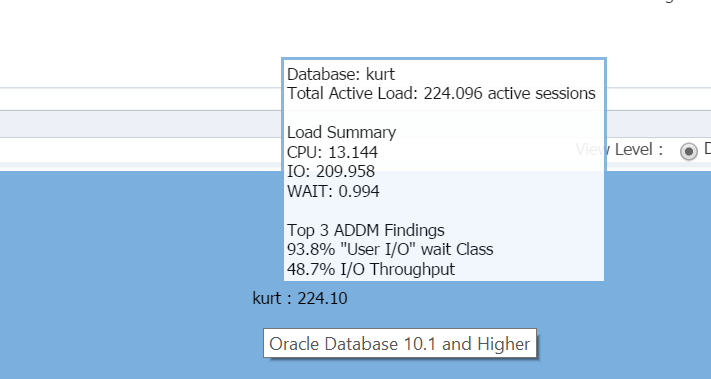
garoto, Kurt é minha pessoa favorita hoje!
página inicial do banco de dados EM12c
fazendo login no banco de dados, Posso ver o uso significativo de IO e recursos para o banco de dados e o host da página inicial do banco de dados:
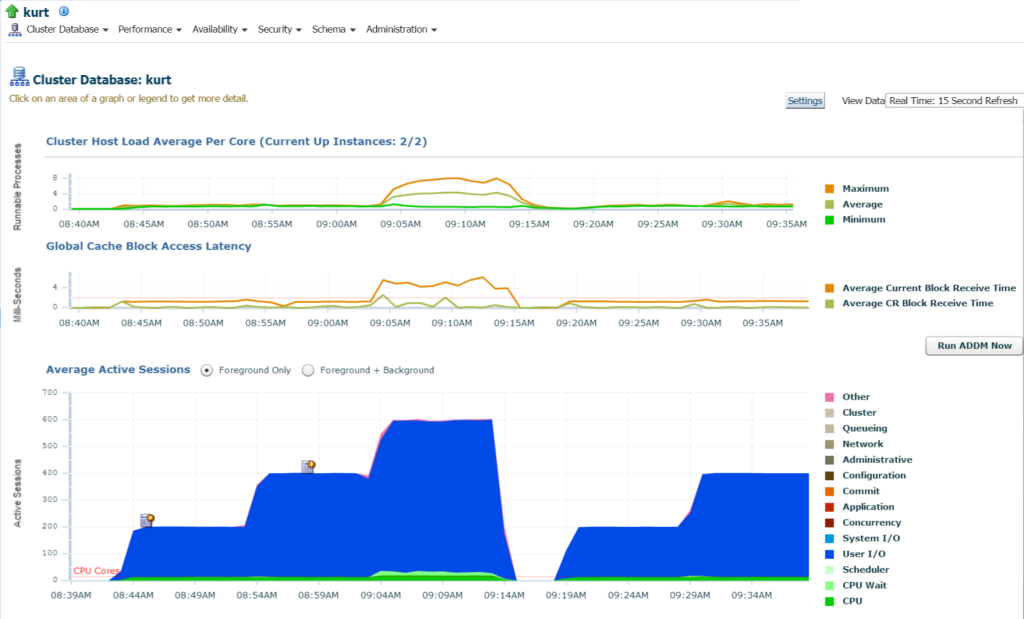
Se nós mover para o Topo da Atividade, (Desempenho de menu, Topo de Atividade) eu começar para ver mais detalhes sobre o processamento e diferentes eventos espera:
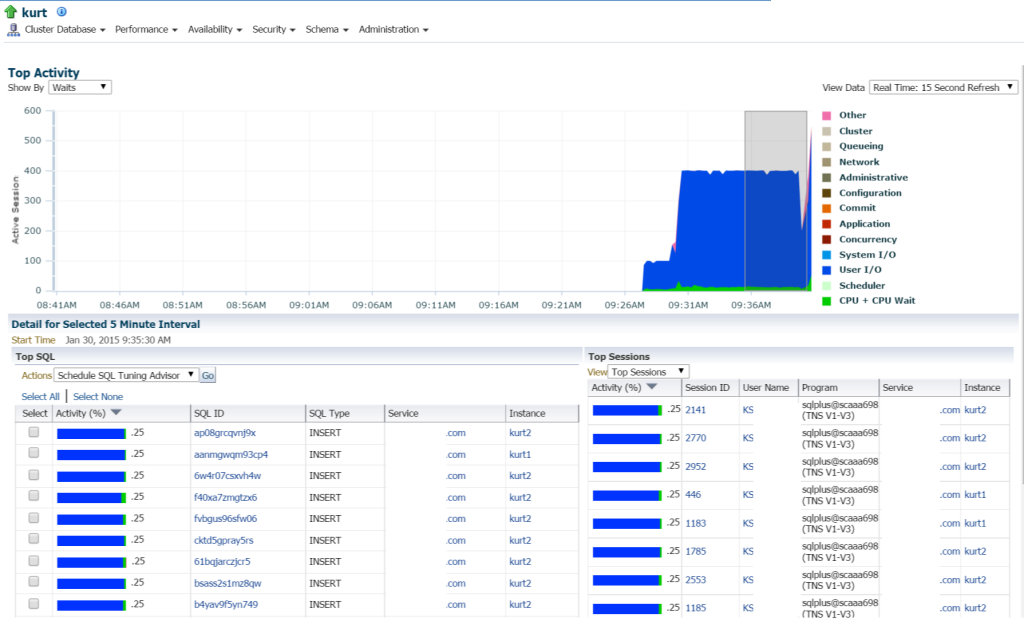
Kurt está fazendo todos os TIPOS de pastilhas, (visto por diferentes SQL_IDs, por Tipo de SQL “INSERIR”. Posso detalhar as instruções individuais e investigar isso, mas, na verdade, há uma tonelada de instruções e SQL_ID’s aqui, não seria apenas mais fácil visualizar a carga de trabalho com um relatório AWR?
executando o relatório AWR
eu escolho clicar em desempenho, AWR, relatório AWR. Agora tenho uma escolha. Eu poderia solicitar que um novo instantâneo fosse executado imediatamente ou eu poderia esperar até o topo da hora, já que o intervalo é definido de hora em hora neste banco de dados. Eu escolhi o último, para esta demonstração, mas se você quisesse criar um instantâneo imediatamente, você pode fazer isso facilmente a partir de EM12c ou solicitar um instantâneo executando o seguinte a partir SQLPlus com um usuário com privilégios de execução o DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
Para este exemplo, eu simplesmente esperou, como não havia pressa ou preocupação aqui e solicitou que o relatório para a hora anterior e instantâneo mais recente:
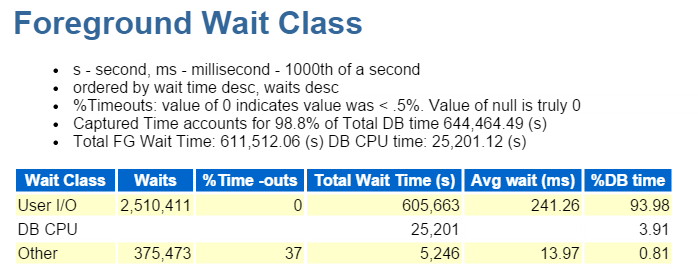
eu sempre começo nos dez principais eventos de primeiro plano e geralmente olho para aqueles com altas porcentagens de espera:
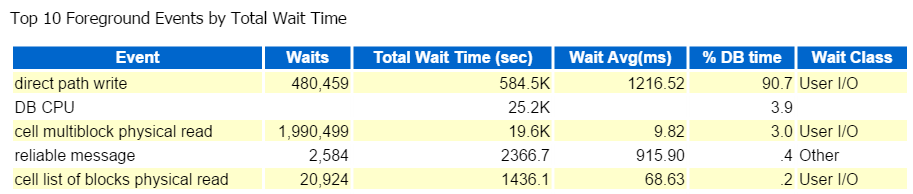
caminho direto escrever, é isso. Nada mais para ver aqui… 🙂
Direct path write envolve o seguinte: inserções / atualizações, objetos sendo gravados, espaços de tabela sendo gravados e aqueles arquivos de dados que compõem o(s) tablespace (s).
também é IO, que verificamos rapidamente na classe de espera Em Primeiro Plano:
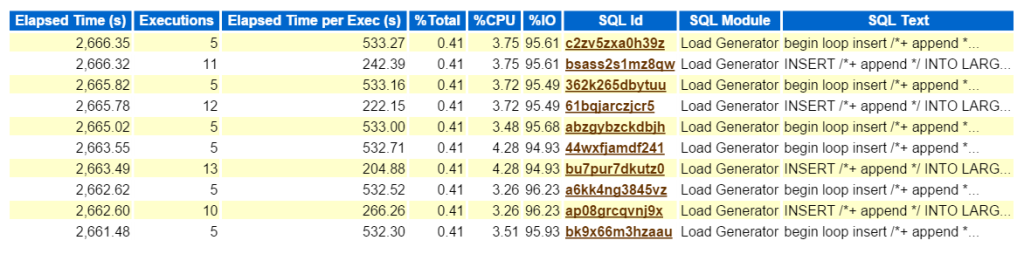
Olhando para o Topo do SQL pelo Tempo Decorrido confirma que estamos a lidar com uma carga de trabalho consistindo de todas as pastilhas:
Clicando sobre a IDENTIFICAÇÃO de SQL, me leva para a Lista Completa de Texto SQL e mostra-me o que Bad Boy Kurt está fazendo para produzir o seu teste de carga de trabalho:

Wow, que Kurt é muito rebelde, hein? 🙂
insira em um loop em uma tabela da mesma tabela, reversão e, em seguida, termine o loop, obrigado por jogar. Ele está chutando alguns pneus e fazendo isso com angústia! Não se preocupe com as pessoas, como eu disse, Kurt está fazendo seu trabalho, usando um módulo chamado “gerador de carga”. Eu seria um tolo não reconhecer isso como algo diferente do que é-gerar carga de trabalho para testar algo. Acabei de receber o benefício adicional de ter uma carga de trabalho para fazer um post sobre a utilização de RMA dados… 🙂
Agora, se esse era um problema real e eu estava tentando descobrir o que esse tipo de impacto no desempenho deste tipo de inserir estava criando no ambiente, onde ir em seguida na AWR relatório? O SQL superior por tempo decorrido é importante, pois deve ser onde você concentra seus esforços. Outras seções divididas por SQL é bom ter, mas lembre-se sempre: “se você não está ajustando para o tempo, você está perdendo tempo.”Nada pode resultar de um exercício de otimização se nenhuma economia de tempo for vista depois que você concluir o trabalho. Portanto, tomando primeiro o SQL superior por tempo decorrido e, em seguida, olhando para a instrução, agora podemos ver quais objetos fazem parte da instrução (large_block149, 191, 194, 145).
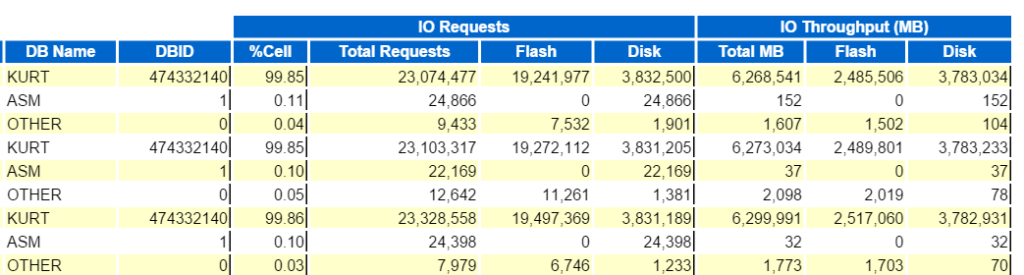
também sabemos que o problema é IO, portanto, devemos pular das informações detalhadas do SQL e ir para as informações do nível do objeto. Essas seções são identificadas por segmentos por xxx.
- Segmentos Lógicos Lê
- Segmentos Física Lê
- Segmentos por Solicitações de Leitura
- Segmentos por Verificações de Tabela
e assim por diante….
todos eles mostram um padrão e uma porcentagem muito semelhantes para os objetos que vemos em nosso SQL superior. Lembre-se, Kurt estava lendo cada uma dessas tabelas, depois inserindo essas mesmas linhas de volta na tabela novamente e depois voltando. Como este é um cenário de carga de trabalho, ao contrário da maioria dos problemas de desempenho que vejo, não há nenhum Objeto pendente mostrando com um impacto de mais de 10% em qualquer área.

como este é um Exadata, há uma tonelada de informações para ajudá-lo a entender o descarregamento, o cache flash (Smart scans) etc. que vai ajudar a transmitir a informação que você precisa para se certificar de que está a atingir o desempenho que você deseja com um sistema criado, mas eu gostaria de guardar para um outro post e basta tocar em algumas das IO relatórios, como estávamos realizando varreduras de tabela, por isso queremos a certeza de que aqueles foram sendo transferida para a célula de nós, (smart scans) vs. sendo executada em um nó de banco de dados.
podemos começar olhando para a taxa de transferência IO do banco de dados Superior:

e então veja os pedidos de Base de dados Superiores pela taxa de transferência da pilha, (sans os nomes de nó da pilha) para ver como comparam: