existem vários casos em que você pode não querer que as Páginas apareçam nas SERPS, e esta postagem do blog discute as diferentes maneiras pelas quais podemos fazer isso.
as principais maneiras de manter uma página fora dos resultados da pesquisa são:
- noindex tags
- bloqueio em robôs.txt
- excluindo a página
- Ferramenta de remoção do Google Search Console.
- tags canônicas
- que tipo de conteúdo não gostaríamos de aparecer nas SERPs?
- como o Google encontra conteúdo para aparecer nos resultados da pesquisa?
- como podemos controlar o que as páginas classificam nos resultados da pesquisa?
- Tags noindex
- bloqueio em robôs txt
- excluindo a página
- a Ferramenta de remoção do Google Search Console
- tags canônicas
- Final pensamentos…
que tipo de conteúdo não gostaríamos de aparecer nas SERPs?
existem vários tipos diferentes de páginas que não gostaríamos de pesquisar no Google ou em outros mecanismos de pesquisa.
Exemplos incluem:
- PPC páginas de destino
- Obrigado páginas
- páginas de Administração
- Interna de resultados de pesquisa
Podemos também querer esconder páginas do Google para um número de razões, incluindo:
- duplicação de página – para evitar que várias versões da mesma página apareçam nos resultados da pesquisa.
- palavras-Chave cannibalisation – parar duas ou mais páginas similares de competir uns com os outros para uma determinada palavra-chave
- Rastreamento orçamento desperdício – eu vou discutir o Rastreamento desta seção, mas isso se refere ao Google gastar muito tempo em descobrir menor valor de páginas em seu site, em vez de priorizar as coisas importantes.
como o Google encontra conteúdo para aparecer nos resultados da pesquisa?
Antes de mergulharmos nas diferentes maneiras pelas quais podemos impedir que as Páginas apareçam nos resultados da pesquisa, vale a pena entender o processo que o Google usa para encontrar e, finalmente, classificar as páginas.
1) rastreamento-esta é a maneira do Google de descobrir novos conteúdos. Usando programas, muitas vezes chamados de spiders ou crawlers, o Google visita diferentes páginas da web e segue os links neles para encontrar novas páginas. Cada site tem um certo “orçamento de rastreamento” ou quantidade de recursos que aloca para cada site.
2) indexação-uma vez que o Google encontrou o conteúdo, ele mantém uma cópia desse conteúdo e o armazena no que é chamado de índice.
3) Rankings-a ordenação dessas diferentes páginas nos resultados da pesquisa é conhecida como ranking. O Google obtém uma consulta, descobre a intenção de pesquisa por trás dessa consulta e, em seguida, procura o índice para retornar os melhores resultados possíveis.O Google usa uma variedade de cálculos diferentes, conhecidos como algoritmos, para determinar quais são os melhores resultados para servir e encomendá-los do mais relevante para o menos relevante.
como podemos controlar o que as páginas classificam nos resultados da pesquisa?
Tags noindex
as tags noindex são uma diretiva que diz ao Google ” não quero que esta página seja indexada e, portanto, não quero que ela apareça nos resultados da pesquisa.”
quando o Google rastreia essa página e vê as diretivas noindex, ela removerá essa página de seu índice e, portanto, os resultados da pesquisa.
essas tags noindex podem ser implementadas de duas maneiras:
- ao incluí-los no código HTML da página
- , retornando um cabeçalho noindex na solicitação HTTP.
Noindex tags implementadas em HTML seria algo parecido com isto:<meta name="robots" content="noindex">
Noindex tags implementadas através do cabeçalho HTTP teria esta aparência:HTTP/... 200 OK
…
X-Robots-Tag: noindex
plataformas de CMS, como WordPress, permitem que você adicione noindex tags de páginas, o que significa que você não precisa de um programador para implementar isso.
importante, o Google precisará rastrear essas páginas para ver a tag “noindex” e, em seguida, remover a página de seu índice.
quando usar tags noindex-se houver páginas em seu site que ainda sirvam a um propósito, mas você não quiser aparecer nos resultados da Pesquisa, esta é uma boa opção.
bloqueio em robôs txt
robôs.txt é um arquivo de texto usado para instruir robôs da web como se comportar quando visitam seu site e pode ser usado para ditar aos rastreadores de mecanismos de pesquisa Se eles podem ou não rastrear partes de um site.
veja o exemplo abaixo dos robôs da Nike.arquivo txt que vive em https://www.nike.com/robots.txt
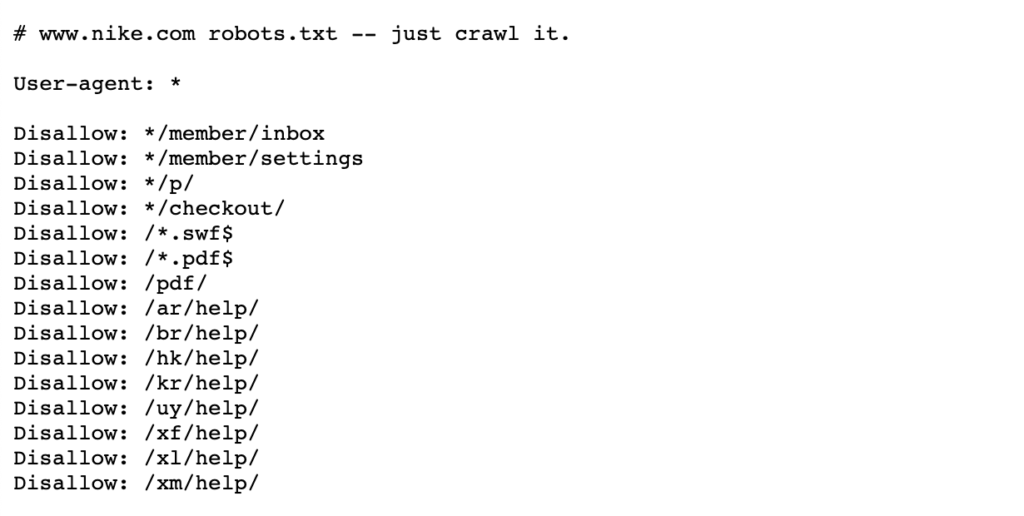
usando robôs.TXT para bloquear determinados caminhos de página, como / admin/, por exemplo, significa que o Googlebot ou outros rastreadores de pesquisa nem sequer visitam essas páginas – portanto, eles não aparecerão nos resultados da pesquisa. Isso pode preservar o orçamento de rastreamento para páginas mais importantes, em vez de se concentrar em páginas menos importantes.
Nota: bloqueando um caminho de página em robôs.o txt impede o Google de salvar a página em primeiro lugar, mas não exclui ou altera o que foi salvo. Portanto, se uma página já estiver aparecendo nos resultados da pesquisa, o Google já rastreou e indexou esta página.
se você precisar de uma página excluída, bloqueie-a em robôs.o txt impedirá ativamente que isso aconteça. Nesse caso, a melhor coisa a fazer é adicionar uma tag noindex para remover essas páginas do índice do Google e, uma vez que todas sejam removidas, você pode bloquear os robôs.txt.
mais detalhes podem ser encontrados nesta página Central de pesquisa do Google.
quando bloquear páginas em robôs.txt – quando você tem caminhos de página específicos ou seções maiores do seu site que você não quer que o Google rastreie, esta é a sua melhor aposta.
se uma página ou coleção de páginas já estiver aparecendo nas SERPs, você precisará noindexá-las primeiro e esperar que elas sejam removidas antes de adicionar os robôs.arquivo txt.
excluindo a página
a resposta mais óbvia, você pode ter pensado, seria simplesmente excluir a página, seja dando-lhe um código de status 404 ou 410.Ambos os códigos de status têm a mesma função em que o Google removerá a página de seu índice quando a próxima rastreia essa página, embora um status 410 possa ser um pouco mais rápido de acordo com John Mueller, do Google.
do ponto de vista de SEO, se essas páginas tiverem valor, seja por meio de backlinks ou tráfego, valeria a pena redirecionar 301 para uma página relevante para consolidar esse patrimônio do link no site.
Alternativamente, se a Página tiver links internos e você não tiver uma página apropriada para redirecionar, esses links internos devem ser removidos ou substituídos por uma página de código de status 200.
quando excluir uma página-se a página não serve para nada e tem pouco valor em termos de backlinks ou tráfego, pode valer a pena excluir. Se houver algum valor da perspectiva do usuário ou de SEO, considere mantê-lo com uma tag noindex ou 301 redirecionando para uma página relevante.
a Ferramenta de remoção do Google Search Console
a Ferramenta de remoção do Google Search Console pode ser usada para bloquear temporariamente os resultados da pesquisa do seu site para sites que você possui no Google Search Console. Vale a pena notar que esta não é uma correção permanente.
se você deseja remover rapidamente uma página dos resultados da Pesquisa, esta é uma boa opção. Se você deseja remover permanentemente uma página, o Google recomenda fornecer um status 404 ou 410, bloqueando o acesso ao conteúdo usando uma senha ou dando à página uma tag noindex.
mais detalhes podem ser encontrados nesta página do Google Webmasters.
quando usar a Ferramenta de remoção do Google Search Console-quando você precisa se livrar de uma página rapidamente. Se você precisar remover a página permanentemente, use uma tag noindex ou forneça um status 404 ou 410.
uma tag canônica é um trecho de código HTML que vive no <head> da página e é usado para definir a versão primária para Páginas semelhantes ou duplicadas. As tags canônicas ajudam a evitar problemas causados por conteúdo duplicado ou quase duplicado que aparece em vários URLs.
veja o exemplo abaixo de uma tag canônica na página inicial do Brainlabs:

se você canonicalizar uma página para outra, está dizendo que não deseja que essa página apareça nos resultados da pesquisa e prefere que outra versão dessa página apareça.
ao contrário das tags noindex que são pedidos, as tags canônicas podem ser ignoradas pelo Google. O Google ainda pode rastrear essas páginas, ver as tags canônicas e decidir se a página deve ou não aparecer nos resultados da pesquisa ou não.
quando usar tags canônicas-as tags canônicas devem ser usadas quando houver várias classificações de páginas duplicadas ou semelhantes. Você vai querer canonicalizar as versões não Mestre para uma versão principal de uma página para indicar ao Google que a versão mestre é a única versão que você gostaria nos resultados da pesquisa. Isso também consolidará os sinais de cada um desses URLs na página principal.
um excelente exemplo para usar tags canônicas é para páginas que possuem parâmetros. Essas páginas podem ter exatamente o mesmo conteúdo, mas URLs diferentes devido a esses parâmetros. As tags canônicas podem ajudar a garantir a versão correta das classificações de uma página, não de nenhuma das outras versões.
Exemplo

Final pensamentos…
Há um número de maneiras para remover ou controlar o conteúdo que aparece nos resultados da pesquisa. A chave é garantir que você está escolhendo a melhor opção para sua situação particular, não tentando fazê-los todos de uma vez!
