miałem ostatnio prośbę o napisanie aktualizacji na temat pracy z raportami AWR, więc zgodnie z obietnicą, oto jest!
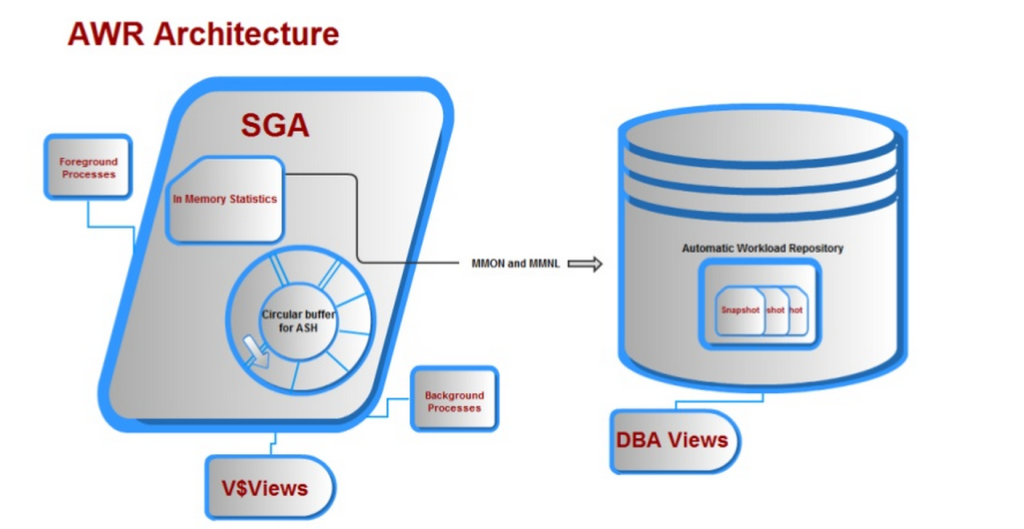
automatyczne repozytorium obciążeń
automatyczne repozytorium obciążeń (AWR) było jednym z najlepszych ulepszeń Oracle w wersji 10g. grupa programistów postawiła przed sobą cel, gdy została poproszona o opracowanie produktu, który:
1. Zapewniła znaczące zalecenia dotyczące wydajności i ulepszenia danych o zdarzeniach oczekiwania w stosunku do swojego poprzednika statspack.
2. Był zawsze włączony, co oznacza, że dane będą stale zbierać bez ręcznej interwencji administratora bazy danych.
3. Nie wpłynie na bieżące przetwarzanie, posiadające własne procesy w tle i bufor pamięci, oznaczony przestrzenią tabel (sysaux).
4. Bufor pamięci zapisywałby w przeciwnym kierunku niż w kierunku, który czyta użytkownik, eliminując problemy z współbieżnością.
wraz z wieloma innymi wymaganiami, wszystkie powyższe były oferowane z automatycznym repozytorium obciążeń i kończymy z architekturą, która wygląda mniej więcej tak:
przy użyciu danych AWR
dane AWR są identyfikowane przez Dbid (identyfikator bazy danych) i SNAP_ID (identyfikator migawki, który ma begin_interval_time i end_interval_time, aby wyizolować datę i godzinę zbierania danych.), a informacje o tym, co jest obecnie przechowywane w bazie danych, można odpytywać z DBA_HIST_SNAPSHOT. AWR data zawiera również próbki ASH (aktywna historia sesji) wraz z danymi migawki, domyślnie około 1 na 10 próbek.
cel efektywnego wykorzystania danych AWR ma związek z następującymi:
1. Czy zidentyfikowałeś prawdziwy problem z wydajnością w ramach przeglądu wydajności?
2. Czy zgłoszono skargę użytkownika lub prośbę o zbadanie pogorszenia wydajności?
3. Czy istnieje wyzwanie biznesowe lub pytanie, na które należy odpowiedzieć, że AWR może zaoferować odpowiedź?
przegląd wydajności
przegląd wydajności to miejsce, w którym zidentyfikowano problem lub przydzielono go do zbadania środowiska pod kątem problemów z wydajnością do rozwiązania. Mam do dyspozycji kilka środowisk Enterprise Manager, ale wybrałem się do jednego w szczególności i trzymam kciuki, mając nadzieję, że będę miał jakieś ciężkie przetwarzanie, aby spełnić wymagania tego postu.
najszybszy sposób, aby zobaczyć obciążenie w środowisku bazy danych z EM12c, kliknij cele – > bazy danych. Wybierz wyświetlanie według wczytanej mapy, a następnie przeglądaj bazy danych według obciążenia. Po przejściu do określonego środowiska Enterprise Manager dowiedziałem się, że to mój szczęśliwy dzień!
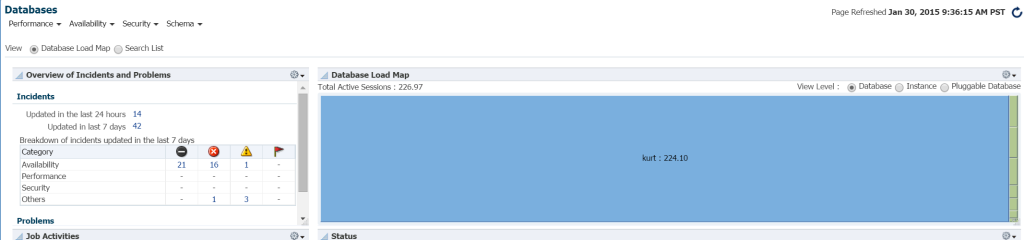 naprawdę Nie wiem, kim jest Kurt, który ma bazę danych monitorowaną w tym środowisku sterowania chmurą EM12c, ale kurcze, jest dziś moją ulubioną osobą! 🙂
naprawdę Nie wiem, kim jest Kurt, który ma bazę danych monitorowaną w tym środowisku sterowania chmurą EM12c, ale kurcze, jest dziś moją ulubioną osobą! 🙂
najeżdżając kursorem na nazwę bazy danych, (kurt) możesz zobaczyć obciążenie, które uruchomił w swojej testowej bazie danych: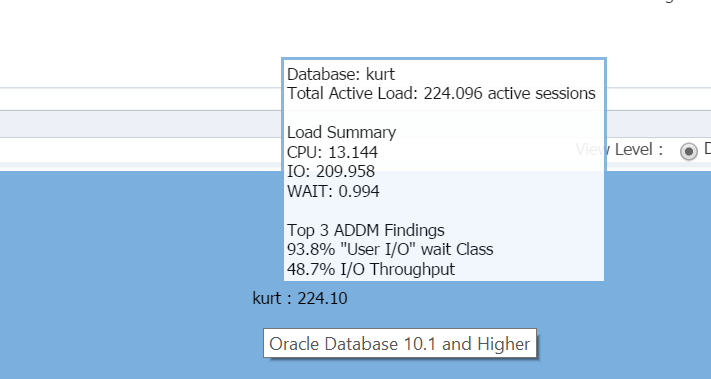
kurcze, Kurt jest dziś moją ulubioną osobą!
Strona główna bazy danych EM12c
logując się do bazy danych, widzę znaczące wykorzystanie IO i zasobów dla bazy danych i hosta ze strony głównej bazy danych:
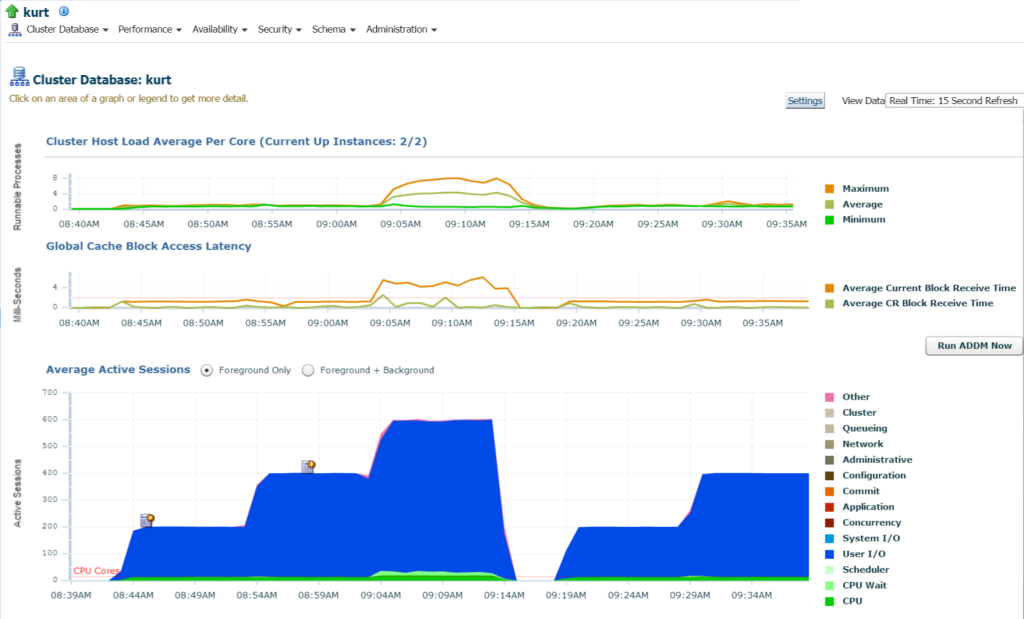
jeśli przejdziemy do górnej aktywności, (Menu wydajności, Górna aktywność) zaczynam przeglądać więcej szczegółów na temat przetwarzania i różnych zdarzeń oczekiwania:
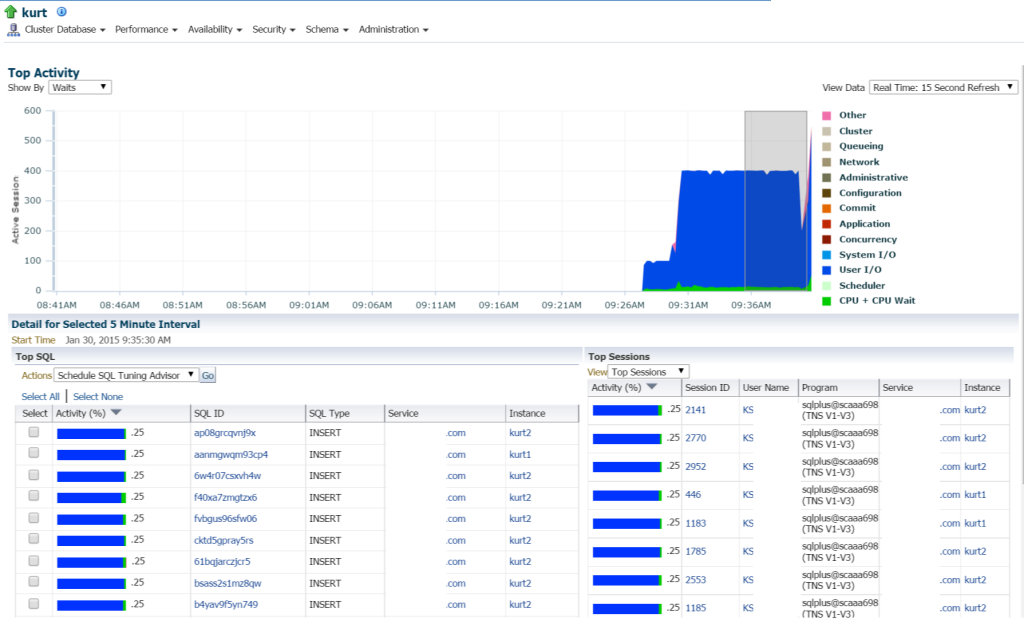
Kurt robi wszelkiego rodzaju wstawki (widziane przez różne SQL_IDs, przez SQL typu „INSERT”. Mogę zagłębić się w poszczególne oświadczenia i zbadać to, ale tak naprawdę jest tu mnóstwo oświadczeń i SQL_ID, czy nie byłoby łatwiej zobaczyć obciążenie pracą za pomocą raportu AWR?
uruchamiając raport AWR
klikam Performance, AWR, AWR Report. Teraz mam wybór. Mogę poprosić o wykonanie nowej migawki natychmiast lub mogę poczekać do góry godziny, ponieważ interwał jest ustawiany co godzinę w tej bazie danych. Wybrałem ten ostatni dla tej demonstracji, ale jeśli chcesz natychmiast utworzyć migawkę, możesz to zrobić łatwo z EM12c lub zażądać migawki, wykonując następujące czynności z SQLPlus z użytkownikiem z uprawnieniami wykonywania na DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
na ten przykład po prostu czekałem, ponieważ nie było pośpiechu ani obaw i poprosiłem o raport za poprzednią godzinę i najnowszą migawkę:
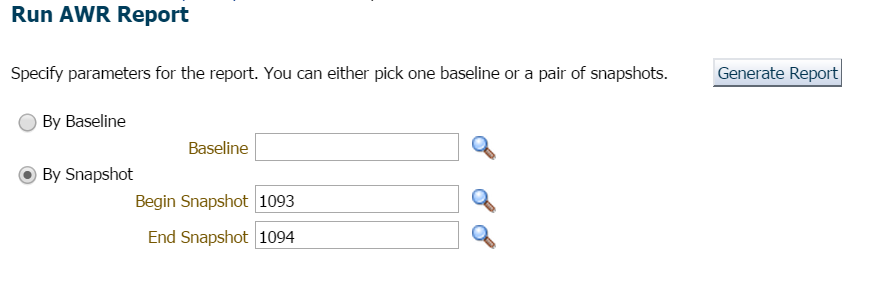
zawsze zaczynam od pierwszej dziesiątki wydarzeń na pierwszym planie i często patrzę na te z wysokim procentem oczekiwania:
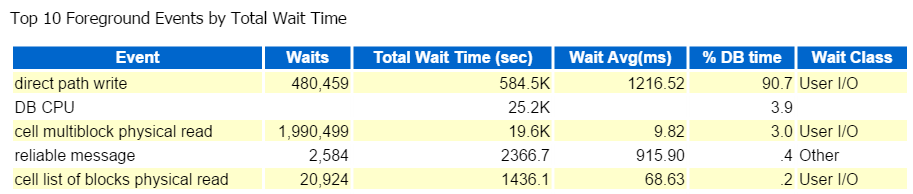
Direct Path Write, to wszystko. Nic więcej do zobaczenia tutaj … 🙂
bezpośredni zapis ścieżki obejmuje następujące elementy: wstawki / aktualizacje, obiekty zapisywane do, przestrzenie tabel zapisywane do I Te pliki danych, które składają się na przestrzenie tabel.
to też IO, które szybko sprawdzamy na pierwszym planie:
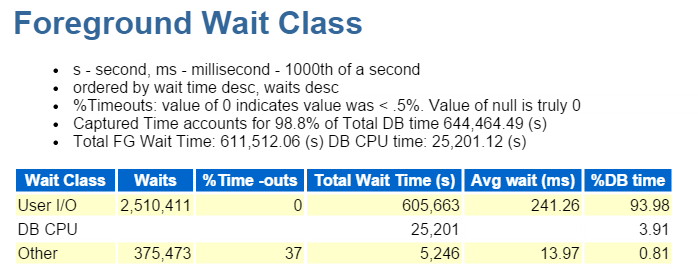
patrzenie na Top SQL przez Upłynięty czas potwierdza, że mamy do czynienia z obciążeniem składającym się ze wszystkich wstawek:
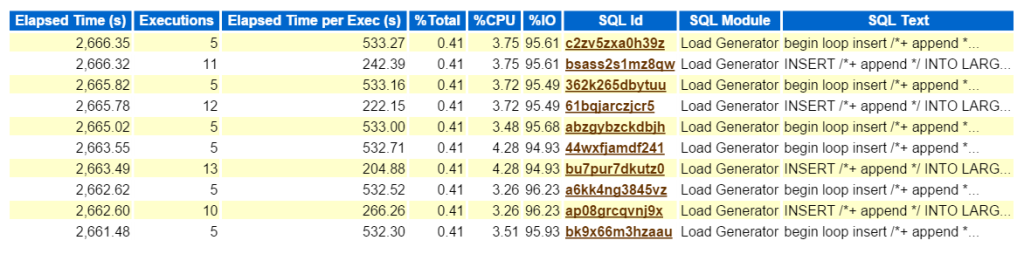
klikając na SQL ID, przenosi mnie do pełnej listy tekstu SQL i pokazuje mi, co Bad Boy Kurt robi, aby wyprodukować swoje obciążenie testowe:

Wow, ten Kurt to niezły buntownik, co? 🙂
włóż pętlę do jednego stołu z tego samego stołu, wycofaj, a następnie zakończ pętlę, dzięki za grę. Kopie Opony i robi to z niepokojem! Nie martwcie się ludzie, jak mówiłem, Kurt wykonuje swoją pracę, używając modułu o nazwie „Load Generator”. Byłbym głupcem nie uznając tego za coś innego niż to, co to jest – generowanie obciążenia pracą, aby coś przetestować. Po prostu dostaję dodatkową korzyść z posiadania obciążenia pracą, aby zrobić post na blogu na temat korzystania z danych AWR … 🙂
teraz, jeśli to był prawdziwy problem i próbowałem dowiedzieć się, co ten typ wydajności wpływa na ten typ wkładki tworzy na środowisko, gdzie iść dalej w raporcie AWR? Górny SQL według upływającego czasu jest ważny, ponieważ powinien być miejscem, w którym skupiasz swoje wysiłki. Inne sekcje w podziale na SQL jest miło mieć, ale zawsze pamiętaj: „jeśli nie dostrajasz się na czas, marnujesz czas.”Nic nie może pochodzić z ćwiczenia optymalizacji, jeśli nie widać oszczędności czasu po zakończeniu pracy. Tak więc, biorąc najpierw Górny SQL przez upłynął czas, a następnie patrząc na instrukcję, możemy teraz zobaczyć, jakie obiekty są częścią instrukcji (large_block149, 191, 194, 145).
wiemy również, że problemem jest IO, więc powinniśmy skoczyć ze szczegółowych informacji SQL i przejść do informacji na poziomie obiektu. Sekcje te są identyfikowane przez segmenty według xxx.
- segmenty według odczytów logicznych
- segmenty według odczytów fizycznych
- segmenty według żądań odczytu
- segmenty według skanowania tabeli
itd….
te wszystkie pokazują bardzo podobny wzorzec i procent dla obiektów, które widzimy w naszym górnym SQL. Pamiętaj, Kurt czytał każdą z tych tabel, potem wstawiał te same wiersze z powrotem do tabeli, a następnie cofał. Ponieważ jest to scenariusz obciążenia pracą, w przeciwieństwie do większości problemów z wydajnością, nie ma wybitnego obiektu o wpływie ponad 10% w żadnym obszarze.

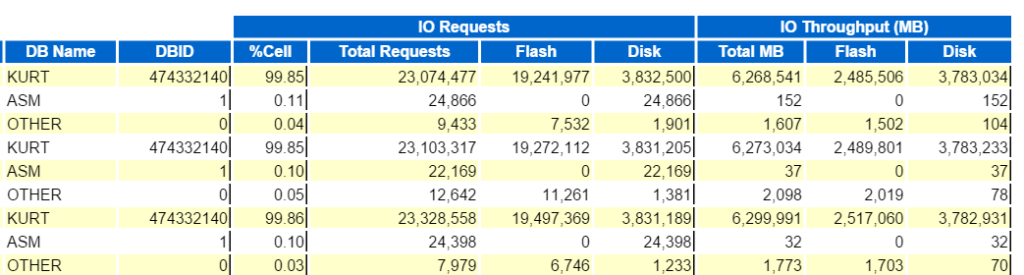
ponieważ jest to Exadata, istnieje mnóstwo informacji, które pomogą Ci zrozumieć odciążanie, (inteligentne skanowanie) pamięć podręczną flash itp. pomoże to w przekazywaniu informacji potrzebnych do uzyskania pożądanej wydajności dzięki zaprojektowanemu systemowi, ale chciałbym zapisać to na inny post i po prostu dotknąć kilku raportów IO, gdy wykonywaliśmy skanowanie tabeli, więc chcemy się upewnić, że zostały one rozładowane do węzłów komórkowych (inteligentne skanowanie), a nie są wykonywane na węźle bazy danych.
możemy zacząć od sprawdzenia najwyższej przepustowości IO bazy danych:

a następnie przeglądaj górne żądania bazy danych na przepustowość komórki (bez nazw węzłów komórek), aby zobaczyć, jak się porównują: