Ho avuto una recente richiesta di scrivere un aggiornamento sul lavoro con i report AWR, quindi, come promesso, eccolo qui!
The Automatic Workload Repository
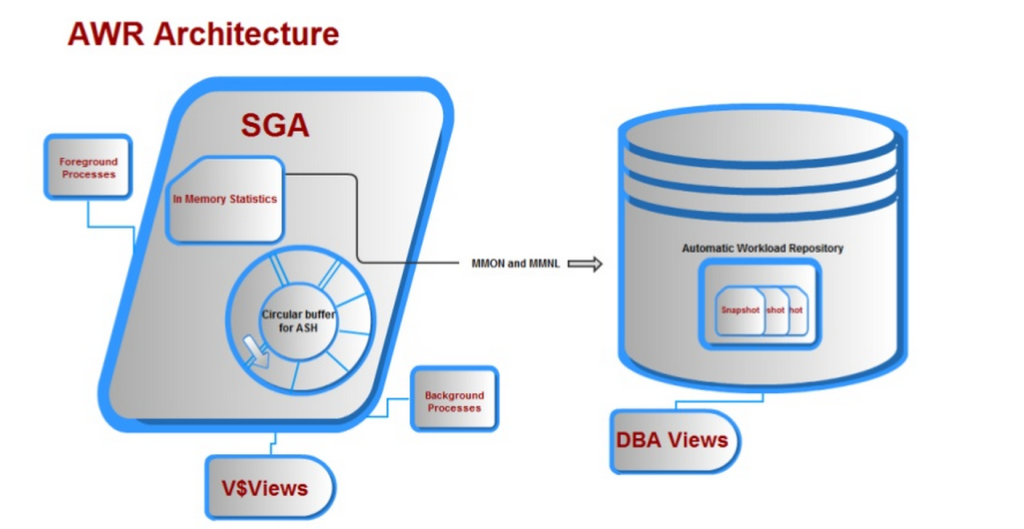
The Automatic Workload Repository, (AWR) è stato uno dei migliori miglioramenti di Oracle nella versione 10g. C’era un bel obiettivo messo di fronte al gruppo di sviluppo quando è stato chiesto di sviluppare un prodotto che:
1. Fornito raccomandazioni sulle prestazioni significative e attendere miglioramenti dei dati degli eventi rispetto al suo predecessore statspack.
2. Era sempre attivo, il che significa che i dati venivano raccolti continuamente senza l’intervento manuale dell’amministratore del database.
3. Non influenzerebbe l’elaborazione corrente, avendo i propri processi in background e buffer di memoria, tablespace designato, (SYSAUX).
4. Il buffer di memoria scriverebbe nella direzione opposta rispetto alla direzione letta dall’utente, eliminando i problemi di concorrenza.
Insieme a molti altri requisiti, tutto quanto sopra è stato offerto con il repository automatico del carico di lavoro e finiamo con un’architettura simile a questa:
Utilizzo dei dati AWR
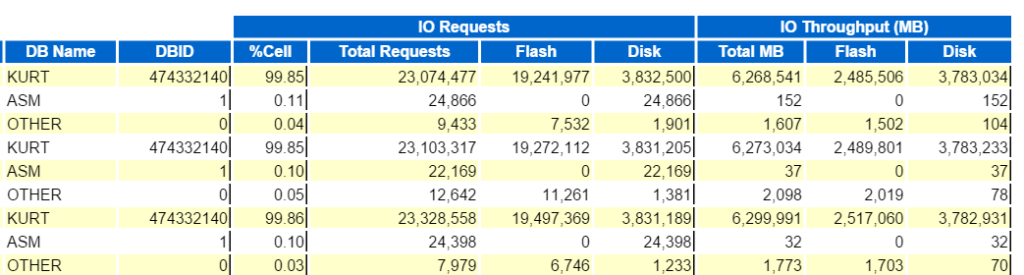
I dati AWR vengono identificati dal DBID (Database Identifier) e da SNAP_ID (snapshot identifier, che ha un begin_interval_time e end_interval_time per isolare la data e l’ora della raccolta dei dati.) e le informazioni su ciò che è attualmente conservato nel database possono essere interrogate da DBA_HIST_SNAPSHOT. I dati AWR contengono anche campioni ASH (Active Session History) insieme ai dati snapshot, per impostazione predefinita, circa 1 su 10 campioni.
L’obiettivo di utilizzare i dati AWR in modo efficace ha davvero a che fare con quanto segue:
1. Hai identificato un vero problema di prestazioni come parte di una revisione delle prestazioni?
2. C’è stato un reclamo dell’utente o una richiesta di indagare su un degrado delle prestazioni?
3. C’è una sfida aziendale o una domanda che deve essere risolta a cui AWR può offrire una risposta? (andremo quando utilizzare AWR rispetto ad altre funzionalità…)
Revisione delle prestazioni
Una revisione delle prestazioni è in cui è stato identificato un problema o è stato assegnato per indagare l’ambiente per problemi di prestazioni da risolvere. Ho un paio di ambienti Enterprise Manager a mia disposizione, ma ho scelto di andare a uno in particolare e incrociare le dita sperando di avere qualche elaborazione pesante per soddisfare i requisiti di questo post.
Il modo più rapido per visualizzare il carico di lavoro nell’ambiente di database da EM12c, fare clic su Target – > Database. Scegliere di visualizzare in base alla mappa di caricamento e quindi visualizzare i database in base al carico di lavoro. Dopo aver visitato uno specifico ambiente Enterprise Manager, ho scoperto che era il mio giorno fortunato!
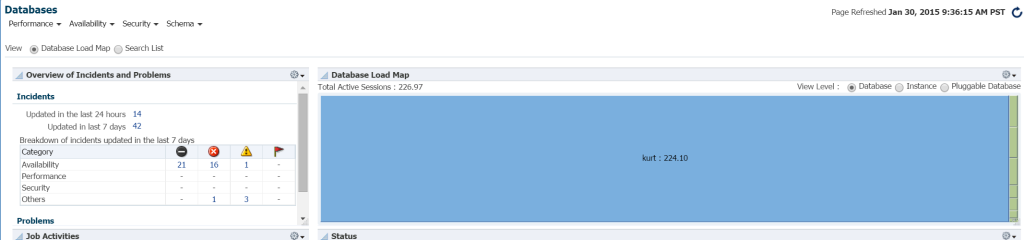 Non so davvero chi sia Kurt che ha un database monitorato su questo ambiente di controllo cloud EM12c, ma ragazzo, è lui la mia persona preferita oggi! ing
Non so davvero chi sia Kurt che ha un database monitorato su questo ambiente di controllo cloud EM12c, ma ragazzo, è lui la mia persona preferita oggi! ing
Passando il cursore sul nome del database, (kurt) è possibile visualizzare il carico di lavoro che ha attualmente in esecuzione sul suo database di test: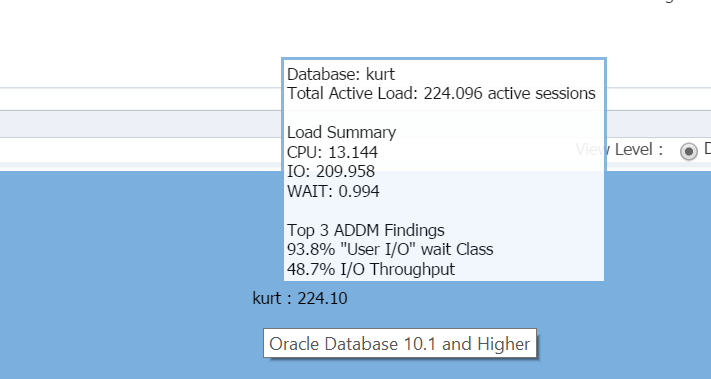
Ragazzo, Kurt è la mia persona preferita oggi!
EM12C Home Page del database
Accedendo al database, posso vedere l’IO significativo e l’utilizzo delle risorse per il database e l’host dalla home page del database:
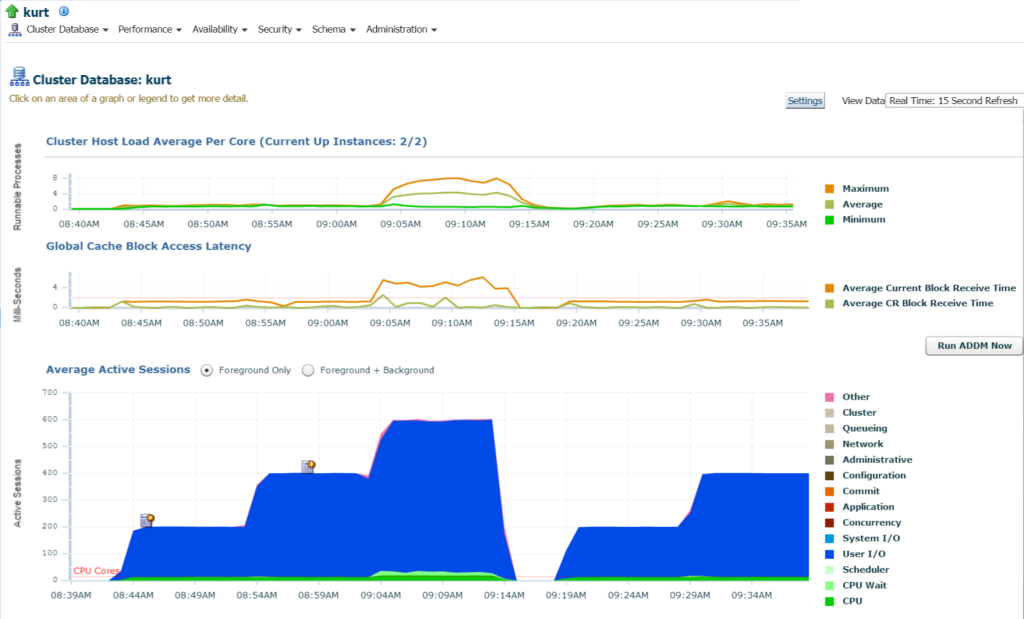
Se passiamo all’attività principale, (menu Prestazioni, Attività principale) comincio a visualizzare maggiori dettagli sull’elaborazione e sui diversi eventi di attesa:
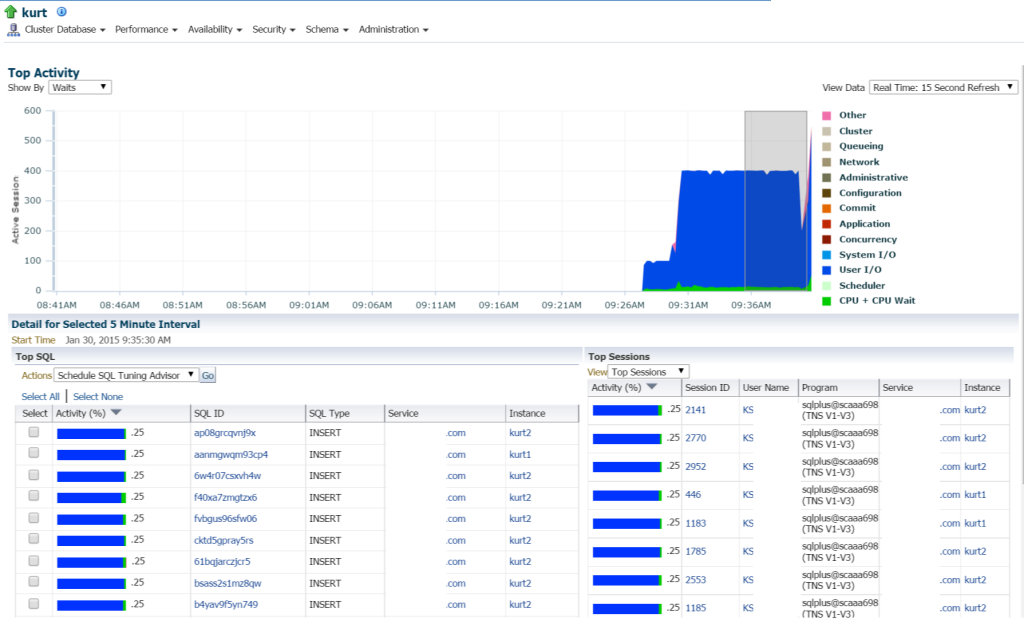
Kurt sta facendo tutti i TIPI di inserti, (visto dai diversi SQL_IDs, dal tipo SQL “INSERT”. Posso approfondire le singole dichiarazioni e indagare su questo, ma in realtà ci sono un SACCO di dichiarazioni e SQL_ID qui, non sarebbe solo più facile visualizzare il carico di lavoro con un rapporto AWR?
Esecuzione del rapporto AWR
Scelgo di fare clic su Prestazioni, AWR, Rapporto AWR. Ora ho una scelta. Potrei richiedere una nuova istantanea da eseguire immediatamente o potrei aspettare fino alla fine dell’ora, poiché l’intervallo è impostato ogni ora in questo database. Ho scelto quest’ultimo per questa dimostrazione, ma se si desidera creare immediatamente un’istantanea, è possibile farlo facilmente da EM12c o richiedere un’istantanea eseguendo quanto segue da SQLPlus con un utente con privilegi di esecuzione su DBMS_WORKLOAD_REPOSITORY:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
Per questo esempio, ho semplicemente aspettato, poiché non c’era fretta o preoccupazione qui e ho richiesto il rapporto per l’ora precedente e l’ultima istantanea:
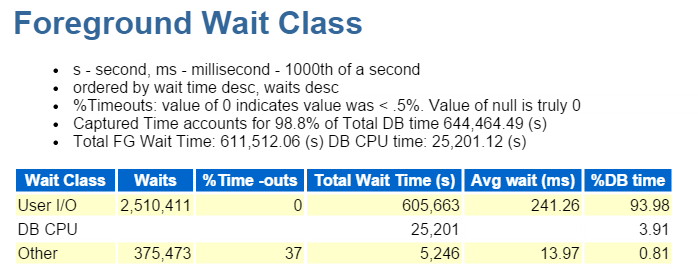
Comincio sempre dai primi dieci eventi in primo piano e comunemente guardo quelli con alte percentuali di attesa:
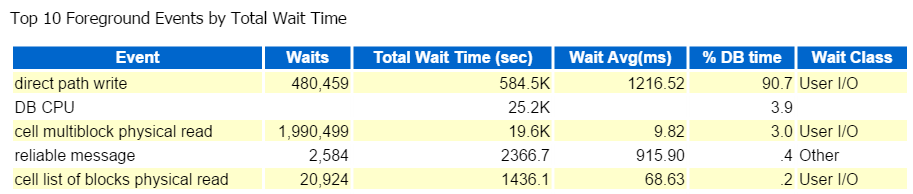
Percorso diretto Scrivere, questo è tutto. Nient’altro da vedere qui –
La scrittura diretta del percorso comporta quanto segue: inserti/aggiornamenti, oggetti in scrittura, tablespace in scrittura e quei file di dati che compongono il tablespace(s).
È anche IO, che verifichiamo rapidamente nella classe di attesa in primo piano:
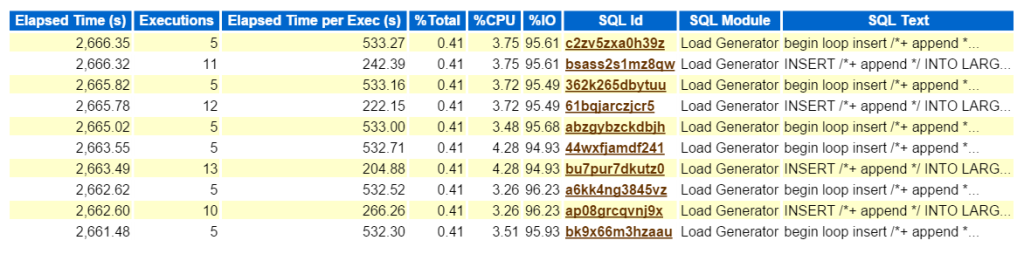
Guardare la parte Superiore SQL con il Tempo Trascorso conferma che abbiamo a che fare con un carico di lavoro composto da tutti gli inserti:
Cliccando sull’ID di SQL, mi prende per la Lista Completa di Testo SQL e mi mostra solo quello che Bad Boy Kurt sta facendo per produrre la sua prova del carico di lavoro:

Wow, che Kurt è abbastanza ribelle, eh? Insert
Inserire un ciclo in una tabella dalla stessa tabella, eseguire il rollback e quindi terminare il ciclo, grazie per aver giocato. Sta prendendo a calci alcune gomme e lo fa con angoscia! Non preoccupatevi gente, come ho detto, Kurt sta facendo il suo lavoro, utilizzando un modulo chiamato “Generatore di carico”. Sarei un pazzo a non riconoscere questo come qualcosa di diverso da quello che è-generando carico di lavoro per testare qualcosa. Ho solo il vantaggio di avere un carico di lavoro per fare un post sul blog sull’utilizzo dei dati AWR Now
Ora, se questo era un problema reale e stavo cercando di scoprire che cosa questo tipo di impatto sulle prestazioni questo tipo di inserto stava creando sull’ambiente, dove andare dopo nel rapporto AWR? Il top SQL per tempo trascorso è importante come dovrebbe essere dove si concentrano i vostri sforzi. Altre sezioni suddivise per SQL sono piacevoli da avere, ma ricorda sempre: “Se non stai sintonizzando per il tempo, stai perdendo tempo.”Nulla può venire da un esercizio di ottimizzazione se non si vede alcun risparmio di tempo dopo aver completato il lavoro. Quindi, prendendo prima l’SQL superiore per Tempo trascorso, quindi guardando l’istruzione, ora possiamo vedere quali oggetti fanno parte dell’istruzione, (large_block149, 191, 194, 145).
Sappiamo anche che il problema è IO, quindi dovremmo saltare giù dalle informazioni dettagliate SQL e andare alle informazioni a livello di oggetto. Queste sezioni sono identificate da Segmenti di xxx.
- Segmenti per letture logiche
- Segmenti per letture fisiche
- Segmenti per richieste di lettura
- Segmenti per scansioni di tabelle
così via e così via….
Tutti questi mostrano un modello e una percentuale molto simili per gli oggetti che vediamo nel nostro SQL superiore. Ricorda, Kurt stava leggendo ciascuna di queste tabelle, quindi inserendo di nuovo quelle stesse righe nel tavolo, quindi tornando indietro. Poiché si tratta di uno scenario di carico di lavoro, a differenza della maggior parte dei problemi di prestazioni che vedo, non vi è alcun oggetto in sospeso con un impatto superiore al 10% in nessuna area.

Poiché si tratta di un Exadata, ci sono un sacco di informazioni per aiutarti a capire lo scaricamento, la cache flash (scansioni intelligenti), ecc. ciò aiuterà a trasmettere le informazioni necessarie per assicurarsi di ottenere le prestazioni desiderate con un sistema ingegnerizzato, ma vorrei salvarlo per un altro post e toccare solo alcuni dei rapporti IO, mentre eseguivamo scansioni di tabelle, quindi vogliamo assicurarci che quelli fossero scaricati sui nodi delle celle, (scansioni intelligenti) rispetto a quelli eseguiti su un nodo di database.
Possiamo iniziare guardando il throughput IO del database superiore:

E quindi visualizzare le richieste di database principali per throughput di cella, (senza i nomi dei nodi di cella) per vedere come si confrontano: