Ci sono un certo numero di casi in cui potresti non volere che le pagine appaiano nelle SERP, e questo post del blog discute i diversi modi in cui possiamo farlo.
I modi principali per mantenere una pagina fuori dai risultati della ricerca sono:
- Noindex tag
- Blocco sui robot.txt
- Eliminazione della pagina
- Strumento di rimozione di Google Search Console.
- Tag canonici
- Che tipo di contenuto non vorremmo apparire nelle SERP?
- In che modo Google trova i contenuti da visualizzare nei risultati di ricerca?
- Come possiamo controllare quali pagine si classificano nei risultati di ricerca?
- Tag Noindex
- Blocco in robot txt
- Eliminazione della pagina
- Strumento di rimozione di Google Search Console
- Tag canonici
- Considerazioni finali
Che tipo di contenuto non vorremmo apparire nelle SERP?
Esistono diversi tipi di pagine che non vorremmo fossero ricercabili su Google o altri motori di ricerca.
Esempi includono:
- Pagine di destinazione PPC
- Pagine di ringraziamento
- Pagine di amministrazione
- Risultati di ricerca interni
Potremmo anche voler nascondere le pagine da Google per una serie di motivi, tra cui:
- Duplicazione pagina – Per evitare che numerose versioni della stessa pagina vengano visualizzate nei risultati di ricerca.
- Cannibalizzazione delle parole chiave-Per impedire a due o più pagine simili di competere tra loro per una particolare parola chiave
- Crawl budget wastage – Discuterò la scansione in questa sezione, ma questo si riferisce a Google che trascorre troppo tempo a scoprire pagine di valore inferiore sul tuo sito, piuttosto che dare priorità alle cose importanti.
In che modo Google trova i contenuti da visualizzare nei risultati di ricerca?
Prima di immergerci nei diversi modi in cui possiamo impedire che le pagine vengano visualizzate nei risultati di ricerca, vale la pena comprendere il processo che Google utilizza per trovare e, infine, classificare le pagine.
1) Crawling – Questo è il modo di Google di scoprire nuovi contenuti. Utilizzando programmi, spesso indicati come spider o crawler, Google visita diverse pagine web e segue i link su di loro per trovare nuove pagine. Ogni sito ha un certo “budget di scansione” o quantità di risorse che assegna a ciascun sito.
2) Indicizzazione – Una volta che Google ha trovato il contenuto, mantiene una copia di quel contenuto e lo memorizza in quello che viene chiamato un indice.
3) Classifiche-L’ordine di queste diverse pagine nei risultati di ricerca è noto come ranking. Google ottiene una query, calcola l’intento di ricerca dietro quella query e quindi cerca l’indice per restituire i migliori risultati possibili.
Google utilizza una serie di calcoli diversi, noti come algoritmi, per determinare quali sono i migliori risultati da servire e ordinarli dal più rilevante al meno rilevante.
Come possiamo controllare quali pagine si classificano nei risultati di ricerca?
Tag Noindex
I tag Noindex sono una direttiva che dice a Google “Non voglio che questa pagina venga indicizzata e quindi non voglio che appaia nei risultati di ricerca.”
Quando Google esegue la scansione successiva di quella pagina e vede le direttive noindex, rimuoverà quella pagina dal suo indice e quindi dai risultati della ricerca.
Questi tag noindex possono essere implementati in due modi:
- Includendoli nel codice HTML della pagina
- Restituendo un’intestazione noindex nella richiesta HTTP.
I tag Noindex implementati nell’HTML sarebbero simili a questo:<meta name="robots" content="noindex">
I tag Noindex implementati tramite intestazione HTTP sarebbero simili a questo:HTTP/... 200 OK
…
X-Robots-Tag: noindex
Le piattaforme CMS, come WordPress, ti consentono di aggiungere tag noindex alle pagine, il che significa che non avresti bisogno di uno sviluppatore per implementarlo.
È importante sottolineare che Google dovrà essere in grado di eseguire la scansione di queste pagine per vedere il tag “noindex” e quindi rimuovere la pagina dal suo indice.
Quando usare i tag noindex – Se ci sono pagine sul tuo sito che hanno ancora uno scopo, ma non vuoi apparire nei risultati di ricerca questa è una buona opzione.
Blocco in robot txt
Robot.txt è un file di testo utilizzato per istruire i robot web come comportarsi quando visitano il tuo sito e può essere utilizzato per dettare ai crawler dei motori di ricerca se possono o non possono eseguire la scansione di parti di un sito web.
Vedi l’esempio seguente dei robot Nike.file txt che vive a https://www.nike.com/robots.txt
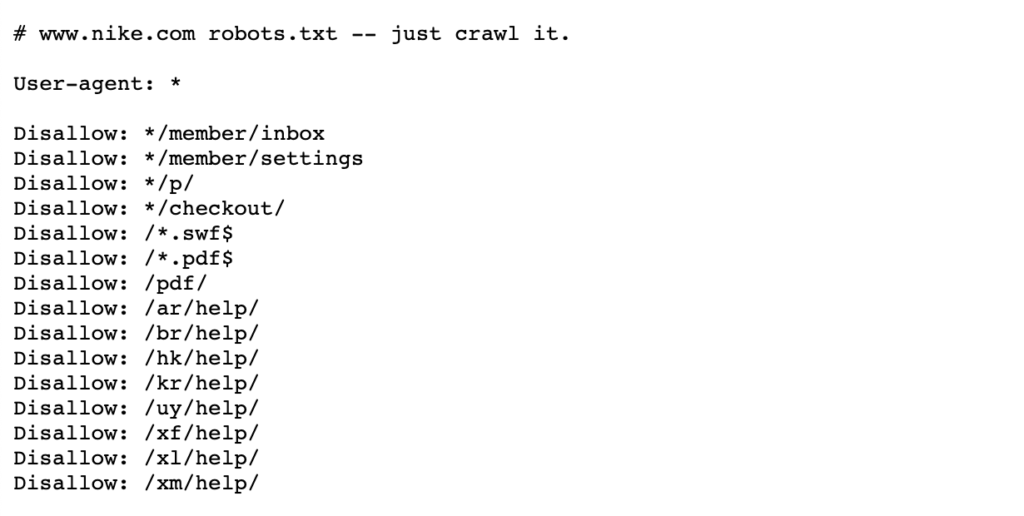
Utilizzo di robot.txt per bloccare determinati percorsi di pagina come / admin/, ad esempio, significa che Googlebot o altri crawler di ricerca non visiteranno nemmeno queste pagine, quindi non appariranno nei risultati di ricerca. Ciò può preservare il budget di scansione per le pagine più importanti piuttosto che concentrarsi su pagine meno importanti.
Nota: blocco del percorso di una pagina nei robot.txt impedisce a Google di salvare la pagina in primo luogo, ma non elimina o modifica ciò che è stato salvato. Pertanto, se una pagina viene già visualizzata nei risultati di ricerca, Google ha già eseguito la scansione e quindi indicizzato questa pagina.
Se hai bisogno di una pagina cancellata, bloccala nei robot.txt impedirà attivamente che ciò accada. In tal caso, la cosa migliore da fare è aggiungere un tag noindex per rimuovere queste pagine dall’indice di Google e una volta rimosse tutte, è possibile bloccare i robot.txt.
Maggiori dettagli possono essere trovati in questa pagina Centrale di ricerca di Google.
Quando bloccare le pagine nei robot.txt-Quando hai percorsi di pagina specifici o sezioni più grandi del tuo sito che non vuoi che Google esegua la scansione, questa è la soluzione migliore.
Se una pagina o una raccolta di pagine è già presente nelle SERP, tuttavia, è necessario prima noindex e attendere che vengano rimossi prima di aggiungere i robot.file txt.
Eliminazione della pagina
La risposta più ovvia, potresti aver pensato, sarebbe semplicemente eliminare la pagina, sia che si tratti di assegnarle un codice di stato 404 o 410.
Entrambi i codici di stato hanno la stessa funzione in quanto Google rimuoverà la pagina dal suo indice quando esegue la scansione successiva di quella pagina, anche se uno stato 410 potrebbe essere leggermente più veloce secondo John Mueller di Google.
Dal punto di vista SEO, se queste pagine hanno un valore, sia che si tratti di backlink o traffico, varrebbe la pena di reindirizzare 301 a una pagina pertinente per consolidare tale equità di collegamento sul sito.
In alternativa, se la pagina ha collegamenti interni e non si dispone di una pagina appropriata a cui reindirizzare, questi collegamenti interni dovrebbero essere rimossi o sostituiti con una pagina di codice di stato 200.
Strumento di rimozione di Google Search Console
Lo strumento di rimozione di Google Search Console può essere utilizzato per bloccare temporaneamente i risultati di ricerca dal tuo sito per i siti che possiedi su Google Search Console. Vale la pena notare che questa non è una soluzione permanente.
Se si desidera rimuovere rapidamente una pagina dai risultati di ricerca, questa è una buona opzione. Se si desidera rimuovere definitivamente una pagina, Google consiglia di assegnarle uno stato 404 o 410, bloccare l’accesso al contenuto utilizzando una password o assegnare alla pagina un tag noindex.
Maggiori dettagli possono essere trovati su questa pagina Webmaster di Google.
Quando utilizzare lo strumento di rimozione di Google Search Console – Quando è necessario eliminare rapidamente una pagina. Se è necessario rimuovere la pagina in modo permanente, utilizzare un tag noindex o assegnargli uno stato 404 o 410.
Tag canonici
Un tag canonico è un frammento di codice HTML che vive nella < testa > della pagina e viene utilizzato per definire la versione primaria per le pagine che sono simili o duplicati. I tag canonici aiutano a prevenire i problemi causati da contenuti duplicati o quasi duplicati che appaiono su più URL.
Vedi l’esempio seguente di un tag canonico sulla homepage di Brainlabs:

Se si canonicalizza una pagina a un’altra, si sta dicendo che non si desidera che la pagina che appare nei risultati di ricerca e si preferisce un’altra versione di quella pagina a comparire invece.
Al contrario dei tag noindex che sono ordini, i tag canonici possono essere ignorati da Google. Google può ancora eseguire la scansione di queste pagine, vedere i tag canonici e quindi decidere se la pagina deve apparire o meno nei risultati di ricerca.
Quando usare i tag canonici-I tag canonici dovrebbero essere usati quando ci sono diverse pagine duplicate o simili. Vorrai canonicalizzare le versioni non master in una versione primaria di una pagina per indicare a Google che la versione master è l’unica versione che desideri nei risultati di ricerca. Ciò consoliderà anche i segnali da ciascuno di questi URL nella pagina principale.
Un primo esempio per l’utilizzo di tag canonici è per le pagine che hanno parametri. Queste pagine possono avere esattamente lo stesso contenuto ma URL diversi a causa di questi parametri. I tag canonici possono aiutare a garantire la versione corretta di una pagina, non di nessuna delle altre versioni.
Esempio

Considerazioni finali
Esistono diversi modi per rimuovere o controllare il contenuto visualizzato nei risultati di ricerca. La chiave è garantire che si sta scegliendo l’opzione migliore per la vostra situazione particolare, non tentare di fare tutti in una volta!
