már volt egy újabb kérés, hogy írjon egy frissítést dolgozik AWR jelentések, így ahogy ígértem, itt van!
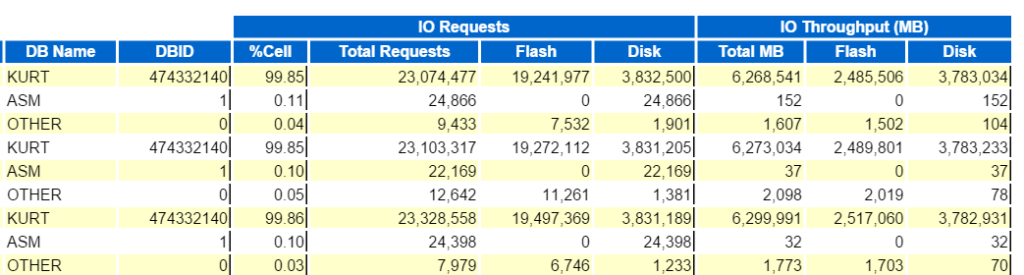
az automatikus munkaterhelés Repository
az automatikus munkaterhelés Repository, (AWR) volt az egyik legjobb fejlesztések az Oracle vissza kiadás 10g. volt elég cél elé A Fejlesztői csoport, amikor arra kérték, hogy dolgozzon ki egy terméket, amely:
1. Jelentős teljesítményajánlatot és várakozási eseményadatbővítéseket nyújtott elődjéhez, a statspack-hez képest.
2. Mindig be volt kapcsolva, ami azt jelenti, hogy az adatok folyamatosan gyűjtenek az adatbázis-adminisztrátor kézi beavatkozása nélkül.
3. Nem befolyásolja az aktuális feldolgozást, saját háttérfolyamatokkal és memóriapufferrel, kijelölt táblaterülettel (SYSAUX).
4. A memóriapuffer az ellenkező irányba írna, szemben a felhasználó által olvasott irányokkal, kiküszöbölve a párhuzamossági problémákat.
sok más követelmény mellett a fentiek mindegyikét felajánlottuk az automatikus munkaterhelés-tárolóval, és végül olyan architektúrát kapunk, amely valahogy így néz ki:
az AWR-adatok
használatával az AWR-adatokat a DBID (Database Identifier) és a SNAP_ID (snapshot identifier, snapshot identifier) azonosítja, amelyek begin_interval_time és end_interval_time azonosítóval rendelkeznek az adatgyűjtés dátumának és időpontjának elkülönítésére. a dba_hist_snapshot-ból lekérdezhetők az adatbázisban jelenleg tárolt információk. AWR adatok is tartalmaz ASH, (Active Session History) minták mellett a pillanatfelvétel adatok, alapértelmezés szerint körülbelül 1 ki minden 10 mintát.
az AWR adatok hatékony felhasználásának célja valóban a következőkhöz kapcsolódik:
1. Azonosított-e valódi teljesítményproblémát a teljesítményértékelés részeként?
2. Volt-e felhasználói panasz vagy kérelem a teljesítményromlás kivizsgálására?
3. Van-e olyan üzleti kihívás vagy kérdés, amelyet meg kell válaszolni, amelyre az AWR választ adhat?
Performance Review
a performance review az, ahol vagy azonosított egy problémát, vagy kijelölték a környezet vizsgálatára a megoldandó teljesítményproblémák érdekében. Van egy pár Enterprise Manager környezetben áll rendelkezésemre, de úgy döntöttem, hogy menjen ki az egyik különösen kereszt ujjaim remélve, hogy lenne néhány nehéz feldolgozás, hogy megfeleljen a követelményeknek ezt a bejegyzést.
a leggyorsabb módja annak, hogy a munkaterhelés az adatbázis környezetben EM12c, kattintson a célok –> adatbázisok. Válassza a megtekintés betöltési térkép alapján lehetőséget, majd az adatbázisokat munkaterhelés szerint fogja megtekinteni. Amikor egy adott vállalati menedzseri környezetbe kerültem, rájöttem, hogy ez volt a szerencsés napom!
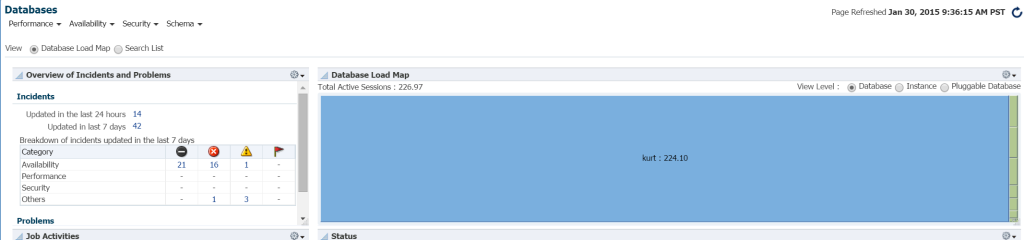 tényleg nem tudom, ki az A Kurt, akinek van egy adatbázisa ezen az EM12c felhővezérlő környezetben, de fiú, ő a kedvenc emberem ma! 6878 >
tényleg nem tudom, ki az A Kurt, akinek van egy adatbázisa ezen az EM12c felhővezérlő környezetben, de fiú, ő a kedvenc emberem ma! 6878 >
ha az egérmutatót az adatbázis neve fölé viszi, (kurt) megtekintheti a tesztadatbázisán jelenleg futó munkaterhelést: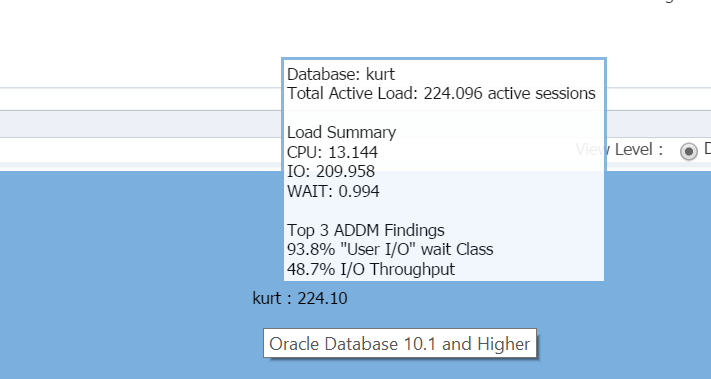
fiú, Kurt a kedvenc emberem ma!
EM12c Adatbázis Kezdőlap
az adatbázisba való bejelentkezéskor az adatbázis kezdőlapjáról látom az adatbázis és a gazdagép jelentős IO-és erőforrás-felhasználását:
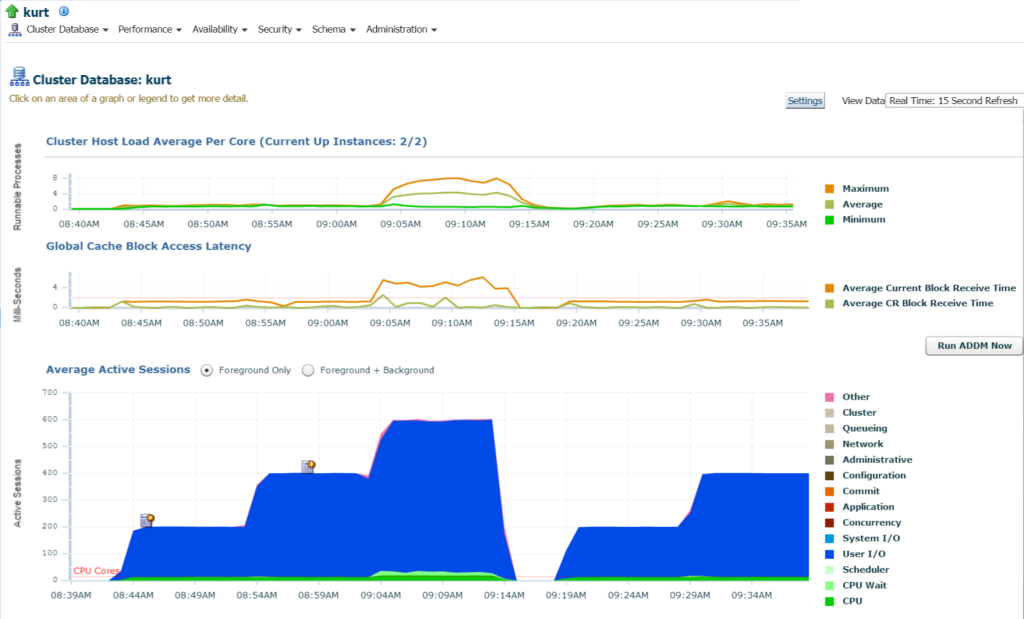
ha a Top Activity (teljesítmény menü, Top Activity) menüpontra lépünk, elkezdem megtekinteni a feldolgozás és a különböző várakozási események részleteit:
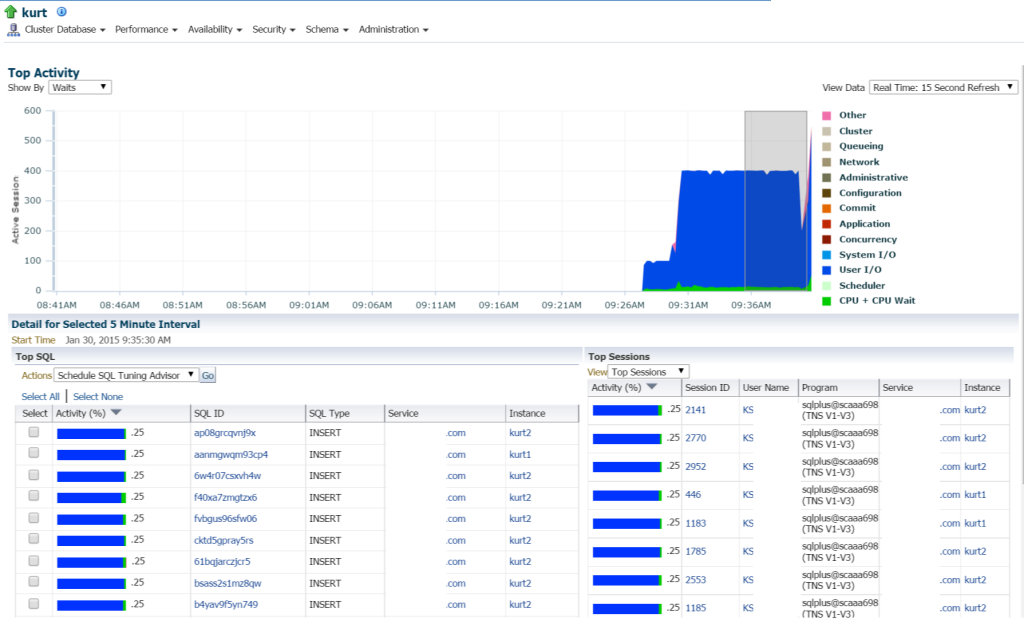
Kurt csinál mindenféle betétek, (látható a különböző SQL_IDs, SQL típusú “INSERT”. Le tudok mélyedni az egyes állításokba, és megvizsgálhatom ezt, de valójában rengeteg állítás és SQL_ID van itt, nem lenne egyszerűbb megtekinteni a munkaterhelést egy AWR jelentéssel?
az AWR Jelentés futtatása
úgy döntök, hogy rákattintok teljesítmény, AWR, AWR jelentés. Most már van választásom. Kérhetek egy új pillanatképet azonnal, vagy várhatok az óra tetejéig, mivel az intervallum óránként van beállítva ebben az adatbázisban. Ez utóbbit választottam ehhez a bemutatóhoz, de ha azonnal pillanatképet szeretne létrehozni, akkor ezt könnyen megteheti az EM12c-ről, vagy pillanatfelvételt kérhet az alábbiak végrehajtásával az SQLPlus-ból egy olyan felhasználóval, aki végrehajtási jogosultságokkal rendelkezik a DBMS_WORKLOAD_REPOSITORY – n:
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
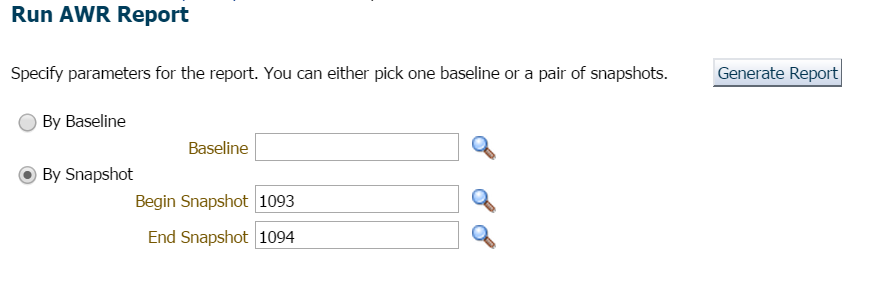
ebben a példában egyszerűen vártam, mivel itt nem volt sietség vagy aggodalom, és kértem a jelentést az előző órára és a legújabb pillanatképre:
mindig az első tíz előtérbeli eseményről indulok, és általában azokat nézem, akiknek magas a várakozási százaléka:
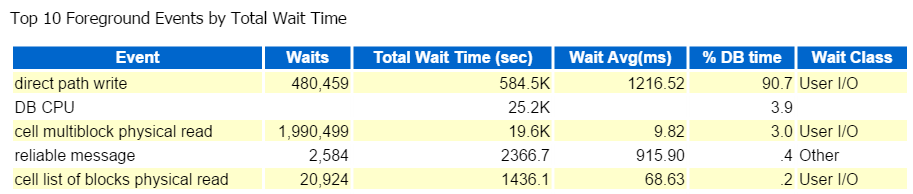
közvetlen út írni, ez az. Nincs más látnivaló itt… a(z)
közvetlen útvonal írása a következőket foglalja magában: Beszúrások/frissítések, objektumok írása, tablespacek írása és azok az adatfájlok, amelyek a tablespace (ek) et alkotják.
ez is IO, amelyet gyorsan ellenőrizünk az előtérben várakozó osztályban:
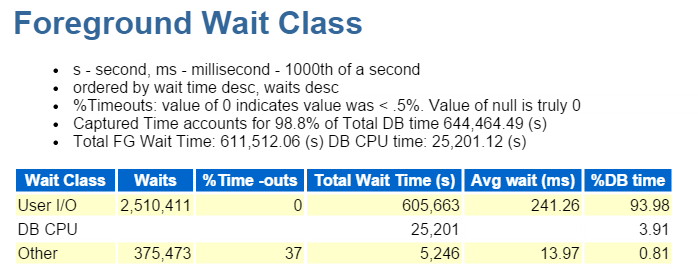
a felső SQL eltelt idő szerinti vizsgálata megerősíti, hogy az összes betétből álló munkaterheléssel van dolgunk:
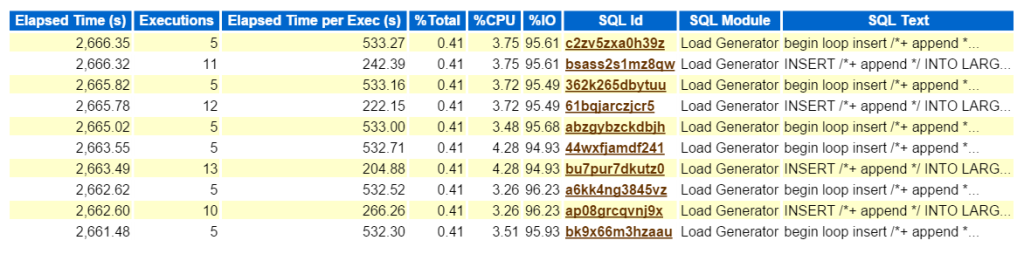
kattintson az SQL ID, elvisz a teljes listát az SQL szöveget, és megmutatja nekem, hogy mi a rossz fiú Kurt csinál, hogy készítsen a vizsgálati munkaterhelés:

Wow, ez a Kurt elég lázadó, mi? ^
helyezzen be egy hurkot egy asztalba ugyanabból az asztalból, húzza vissza, majd fejezze be a hurkot, köszönöm a játékot. Rugdossa a gumikat, és dühösen csinálja! Ne aggódj emberek, mint mondtam, Kurt a munkáját végzi, egy “Load Generator”nevű modult használ. Bolond lennék, ha ezt nem ismerném fel másnak, mint ami – munkaterhelést generál valami tesztelésére. Én csak kap a hozzáadott előnye, hogy a munkaterhelés, hogy nem egy blogbejegyzést segítségével AWR ADATOK… 6
most, ha ez egy igazi probléma, és én akartam, hogy megtudja, mi ez a fajta teljesítmény hatása az ilyen típusú betét volt létre a környezetre, hová menjen a következő AWR jelentés? A felső SQL az eltelt idő fontos, mivel ott kell lennie, ahol az erőfeszítéseit összpontosítja. Az SQL szerint lebontott egyéb szakaszok jó, ha vannak, de mindig emlékezzen: “ha nem hangol az időre, akkor pazarolja az időt.”Az optimalizálási gyakorlatból semmi sem származhat, ha a munka befejezése után nincs időmegtakarítás. Tehát ha először a felső SQL-t vesszük az eltelt idő szerint, majd megnézzük az állítást, akkor láthatjuk, hogy mely objektumok képezik az utasítás részét (large_block149, 191, 194, 145).
azt is tudjuk, hogy a probléma az IO, ezért ugorjunk le az SQL részletes információiról, és menjünk az objektum szintű információkra. Ezeket a szakaszokat xxx szegmensek azonosítják.
- szegmensek logikai olvasások szerint
- szegmensek fizikai olvasások szerint
- szegmensek olvasási kérések szerint
- szegmensek táblázatos beolvasások szerint
így tovább és így tovább….
ezek mind nagyon hasonló mintát és százalékot mutatnak a top SQL-ben látható objektumokhoz. Emlékezik, Kurt ezeket a táblázatokat olvasta, majd ugyanazokat a sorokat illesztette vissza az asztalhoz, majd visszagurult. Mivel ez egy munkaterhelési forgatókönyv, ellentétben a legtöbb teljesítményproblémával, amit látok, nincs olyan kiemelkedő objektum, amely bármely területen több mint 10% – os hatással lenne.

mivel ez egy Exadata, rengeteg információ segít megérteni a kirakodást, (intelligens beolvasások) flash gyorsítótár stb. ez segíteni fogja a szükséges információk továbbítását, hogy megbizonyosodjon arról, hogy egy tervezett rendszerrel eléri-e a kívánt teljesítményt, de ezt egy másik bejegyzésre szeretném menteni, és csak érinteni néhány IO jelentést, mivel asztali vizsgálatokat végeztünk, ezért szeretnénk megbizonyosodni arról, hogy ezeket a cellacsomópontokra (intelligens beolvasások) töltik ki, szemben az adatbázis csomóponton történő végrehajtással.
kezdjük azzal, hogy megnézzük a legjobb Adatbázis IO áteresztőképességét:

ezután tekintse meg a legfelső Adatbázis-kérelmeket Cellánkénti átviteli Sebességenként (a Cellacsomópontok nevei nélkül), hogy megnézze, hogyan hasonlítják össze őket: