számos olyan eset van, amikor nem szeretné, hogy az oldalak megjelenjenek a SERP-kben, és ez a blogbejegyzés azt tárgyalja, hogy ezt hogyan tehetjük meg.
a fő módja annak, hogy egy oldalt távol tartson a keresési eredményektől:
- Noindex címkék
- blokkoló robotok.txt
- az oldal törlése
- A Google Search Console eltávolítási eszköze.
- kanonikus címkék
- milyen tartalmat nem szeretnénk megjeleníteni a SERP-kben?
- hogyan jelenik meg a Google a keresési eredmények között?
- hogyan szabályozhatjuk, hogy mely oldalak rangsorolják a keresési eredményeket?
- Noindex címkék
- blokkolás robotok txt
- az oldal törlése
- a Google Search Console eltávolító eszköze
- kanonikus címkék
- Final thoughts…
milyen tartalmat nem szeretnénk megjeleníteni a SERP-kben?
számos különböző típusú oldal létezik, amelyeket nem szeretnénk kereshetővé tenni a Google-on vagy más keresőmotorokban.
példák:
- PPC nyitóoldalak
- köszönöm oldalak
- Admin oldalak
- belső keresési eredmények
több okból is el szeretnénk rejteni az oldalakat a Google elől, többek között:
- oldal duplikáció – annak megakadályozása, hogy ugyanazon oldal számos verziója megjelenjen a keresési eredmények között.
- kulcsszó kannibalizáció – annak megakadályozása, hogy két vagy több hasonló oldal versenyezzen egymással egy adott kulcsszóért
- feltérképezési költségkeret – pazarlás-ebben a szakaszban tárgyalom a feltérképezést, de ez arra utal, hogy a Google túl sok időt tölt az alacsonyabb értékű oldalak felfedezésével a webhelyén, ahelyett, hogy a fontos dolgokat rangsorolná.
hogyan jelenik meg a Google a keresési eredmények között?
mielőtt belemerülnénk a különböző módokba, amelyekkel megakadályozhatjuk az oldalak megjelenését a keresési eredmények között, érdemes megérteni azt a folyamatot, amelyet a Google az oldalak keresésére és végső rangsorolására használ.
1) feltérképezés – ez a Google módja az új tartalmak felfedezésére. A gyakran pókoknak vagy robotoknak nevezett programok segítségével a Google különböző weboldalakat látogat meg, és követi az azokon található linkeket, hogy új oldalakat találjon. Minden webhelynek van egy bizonyos “feltérképezési költségvetése” vagy az egyes webhelyekhez rendelt erőforrások mennyisége.
2) indexelés – miután a Google megtalálta a tartalmat, fenntartja a tartalom másolatát, és tárolja azt az úgynevezett indexben.
3) rangsor-ezeknek a különböző oldalaknak a sorrendje a keresési eredmények között rangsorolás néven ismert. A Google lekérdezést kap, kitalálja a lekérdezés mögött meghúzódó Keresési szándékot, majd az Indexre néz, hogy a lehető legjobb eredményeket adja vissza.
a Google számos különböző számítást, úgynevezett algoritmusokat használ annak meghatározására, hogy melyik a legjobb eredmény, és megrendeli őket a legrelevánsabbtól a legkevésbé relevánsig.
hogyan szabályozhatjuk, hogy mely oldalak rangsorolják a keresési eredményeket?
Noindex címkék
a Noindex címkék olyan irányelv, amely azt mondja a Google-nak: “nem akarom, hogy ez az oldal indexelve legyen, ezért nem akarom, hogy megjelenjen a keresési eredmények között.”
amikor a Google legközelebb feltérképezi az oldalt, és meglátja a noindex irányelveket, eltávolítja az oldalt az indexéből és így a keresési eredményekből.
ezek a noindex címkék kétféleképpen valósíthatók meg:
- azáltal, hogy beilleszti őket az oldal HTML kódjába
- noindex fejléc visszaküldésével a HTTP kérésben.
a HTML-ben végrehajtott Noindex címkék így néznének ki:<meta name="robots" content="noindex">
a HTTP fejlécen keresztül megvalósított Noindex címkék így néznének ki:HTTP/... 200 OK
…
X-Robots-Tag: noindex
a CMS platformok, például a WordPress, lehetővé teszik noindex címkék hozzáadását az oldalakhoz, ami azt jelenti, hogy ennek megvalósításához nincs szüksége fejlesztőre.
fontos, hogy a Google-nak képesnek kell lennie feltérképezni ezeket az oldalakat, hogy láthassa a “noindex” címkét, majd eltávolítsa az oldalt az indexéből.
mikor kell használni a noindex címkéket – ha a webhelyén vannak olyan oldalak, amelyek továbbra is célt szolgálnak, de nem szeretne megjelenni a keresési eredmények között, ez egy jó lehetőség.
blokkolás robotok txt
robotok.a txt egy szöveges fájl, amely arra szolgál, hogy utasítsa a webes robotokat, hogyan viselkedjenek, amikor meglátogatják az Ön webhelyét, és felhasználható arra, hogy diktálja a keresőmotorok robotjainak, hogy képesek-e feltérképezni egy webhely egyes részeit.
Lásd az alábbi példát a Nike robotjairól.TXT fájl, amely itt él https://www.nike.com/robots.txt
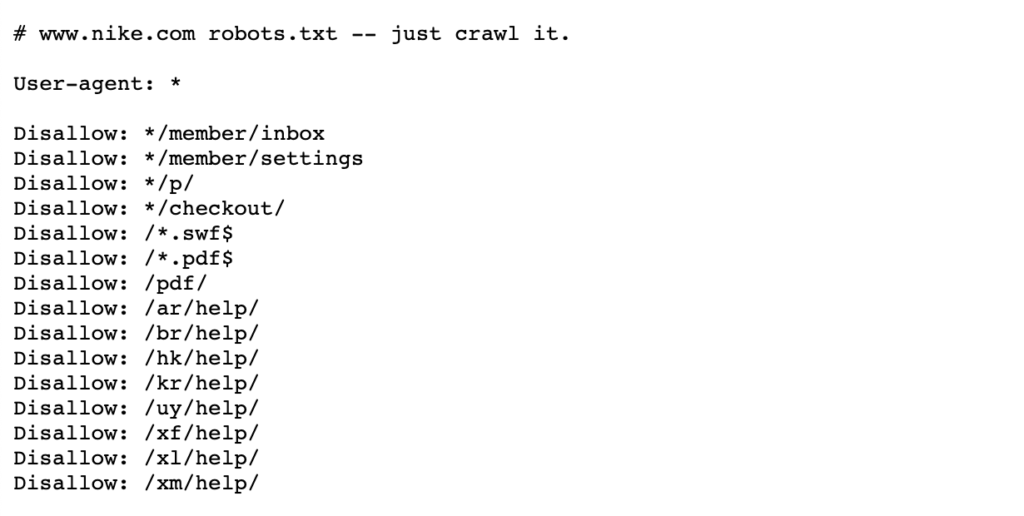
robotok használata.bizonyos oldalútvonalak, például az /admin/ blokkolása azt jelenti, hogy a Googlebot vagy más keresőrobotok nem is látogatják meg ezeket az oldalakat – ezért nem jelennek meg a keresési eredmények között. Ez megőrizheti a fontosabb oldalak feltérképezési költségkeretét, ahelyett, hogy a kevésbé fontos oldalakra összpontosítana.
Megjegyzés: oldal elérési útjának blokkolása robotokban.a txt elsősorban megakadályozza a Google-t az oldal mentésében, de nem törli vagy módosítja a mentetteket. Ezért, ha egy oldal már megjelenik a keresési eredmények között, akkor a Google már feltérképezte, majd indexelte ezt az oldalt.
ha törölni kell egy oldalt, akkor blokkolja azt robotokban.a txt aktívan megakadályozza, hogy ez megtörténjen. Ebben az esetben a legjobb dolog egy noindex címke hozzáadása, hogy eltávolítsa ezeket az oldalakat a Google indexéből, és miután eltávolították őket, blokkolhatja a robotokat.txt.
további részletek a Google Keresés központi oldalán találhatók.
mikor kell blokkolni az oldalakat a robotokban.txt-ha konkrét oldalútvonalakkal vagy webhelyének nagyobb szakaszaival rendelkezik, amelyeket nem szeretne a Google feltérképezni, ez a legjobb megoldás.
ha egy oldal vagy oldalgyűjtemény már megjelenik a SERP-kben, akkor először meg kell várni, amíg eltávolítják őket, mielőtt hozzáadnák a robotokat.txt fájl.
az oldal törlése
a legnyilvánvalóbb válasz, gondolhatta, az lenne, ha egyszerűen törölné az oldalt, függetlenül attól, hogy 404-es vagy 410-es állapotkódot ad neki.
mindkét állapotkód ugyanazt a funkciót szolgálja, mivel a Google eltávolítja az oldalt az indexéből, amikor legközelebb feltérképezi az oldalt, bár a 410-es állapot kissé gyorsabb lehet A Google John Mueller szerint.
SEO szempontból, ha ezek az oldalak értéket képviselnek, legyen szó backlinkekről vagy forgalomról, érdemes lenne 301 átirányítani egy releváns oldalra annak érdekében, hogy megszilárdítsa a link tőkéjét a webhelyen.
Alternatív megoldásként, ha az oldal Belső hivatkozásokkal rendelkezik, és nem rendelkezik megfelelő oldallal, amelyre átirányíthatja, ezeket a belső hivatkozásokat el kell távolítani, vagy 200-as állapotkóddal kell helyettesíteni.
mikor kell törölni egy oldalt – ha az oldal semmilyen célt nem szolgál, és kevés értéke van a linkek vagy a forgalom szempontjából, érdemes lehet törölni. Ha van valamilyen érték felhasználói vagy SEO szempontból, fontolja meg, hogy noindex címkével vagy 301-gyel átirányítja egy megfelelő oldalra.
a Google Search Console eltávolító eszköze
a Google Search Console eltávolító eszköze arra használható, hogy ideiglenesen blokkolja az Ön webhelyén található keresési eredményeket a Google Search Console-ban található webhelyek esetében. Érdemes megjegyezni, hogy ez nem állandó javítás.
ha gyorsan el akar távolítani egy oldalt a keresési eredmények közül, ez jó lehetőség. Ha véglegesen el akar távolítani egy oldalt, a Google azt javasolja, hogy 404-es vagy 410-es állapotot adjon meg, jelszóval blokkolja a Tartalomhoz való hozzáférést, vagy noindex címkét adjon az oldalnak.
további részletek a Google webmesterek oldalán találhatók.
mikor kell használni a Google Search Console eltávolítási eszközét – amikor gyorsan meg kell szabadulnia egy oldaltól. Ha véglegesen el kell távolítania az oldalt, használjon noindex címkét, vagy adjon 404 vagy 410 állapotot.
kanonikus címkék
a kanonikus címke egy HTML-kódrészlet, amely az oldal < fejében> található, és a hasonló vagy duplikált oldalak elsődleges verziójának meghatározására szolgál. A kanonikus címkék segítenek megelőzni a több URL-en megjelenő duplikált vagy közel duplikált tartalom okozta problémákat.
Lásd az alábbi példát egy kanonikus címkére a Brainlabs honlapján:

ha kanonizálja az egyik oldalt a másikra, akkor azt mondja, hogy nem szeretné, hogy az oldal megjelenjen a keresési eredmények között, és inkább az oldal másik verzióját szeretné megjeleníteni.
a noindex címkékkel szemben, amelyek megrendelések, a kanonikus címkéket a Google figyelmen kívül hagyhatja. A Google továbbra is feltérképezheti ezeket az oldalakat, megtekintheti a kanonikus címkéket, majd eldöntheti, hogy az oldal megjelenjen-e a keresési eredmények között.
mikor kell kanonikus címkéket használni – a kanonikus címkéket akkor kell használni, ha több duplikált vagy hasonló oldal van rangsorolva. A nem fő verziókat egy oldal elsődleges verziójára szeretné kanonizálni, hogy jelezze a Google számára, hogy a fő verzió az egyetlen verzió, amelyet a keresési eredmények között szeretne. Ez konszolidálja az egyes URL-ek jeleit is az egy mesteroldalra.
a kanonikus címkék használatának kiváló példája a paraméterekkel rendelkező oldalak. Ezeknek az oldalaknak pontosan ugyanaz a tartalma, de ezeknek a paramétereknek köszönhetően eltérő URL-ek lehetnek. A kanonikus címkék segíthetnek az oldal rangsorolásának helyes verziójának biztosításában, nem pedig a többi verzióban.
példa

Final thoughts…
számos módon lehet eltávolítani vagy szabályozni, hogy milyen tartalom jelenjen meg a keresési eredmények között. A legfontosabb annak biztosítása, hogy az adott helyzethez a legjobb lehetőséget választja, ne próbálja meg egyszerre megtenni őket!
