jeg har haft en nylig anmodning om at skrive en opdatering om at arbejde med Apr rapporter, så som lovet, her er det!
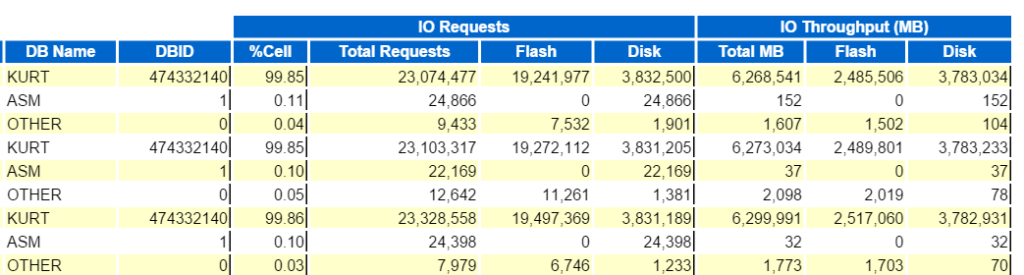
den automatiske arbejdsbyrde Repository
den automatiske arbejdsbyrde Repository, var en af de bedste forbedringer til Oracle tilbage i release 10g. der var noget af et mål sat foran udviklingsgruppen, da de blev bedt om at udvikle et produkt, der:
1. Forudsat betydelige ydeevne anbefaling og vente begivenhed data forbedringer i forhold til sin forgænger statspack.
2. Var altid tændt, hvilket betyder, at dataene løbende indsamles uden manuel indgriben fra databaseadministratoren.
3. Ville ikke påvirke den aktuelle behandling, der har sine egne baggrundsprocesser og hukommelsesbuffer, betegnet tablespace.
4. Hukommelsesbufferen ville skrive i den modsatte retning vs. retning, som brugeren læser, hvilket eliminerer problemer med samtidighed.
sammen med mange andre krav blev alt ovenstående tilbudt med det automatiske arbejdsbyrde-lager, og vi ender med arkitektur, der ser sådan ud:
ved hjælp af data for årsværk
identificeres data for årsværk med dbid, (Databaseidentifikator) og et SNAP_ID, (snapshot-id, som har en begin_interval_time og end_interval_time til at isolere dato og klokkeslæt for dataindsamlingen.) og oplysninger om, hvad der i øjeblikket bevares i databasen, kan forespørges fra DBA_HIST_SNAPSHOT. Ash – data indeholder også Ash-prøver (Aktiv Sessionshistorik) sammen med snapshot-data som standard omkring 1 ud af hver 10 prøver.
målet om at bruge data effektivt har virkelig at gøre med følgende:
1. Har du identificeret et ægte præstationsproblem som en del af en præstationsanmeldelse?
2. Har der været en brugerklager eller en anmodning om at undersøge en ydelsesforringelse?
3. Er der en forretningsudfordring eller et spørgsmål, der skal besvares, som ARC kan tilbyde et svar på?
præstationsanmeldelse
en præstationsanmeldelse er, hvor du enten har identificeret et problem eller er blevet tildelt til at undersøge miljøet for præstationsproblemer at løse. Jeg har et par Enterprise Manager-miljøer til rådighed for mig, men jeg valgte at gå ud til en især og krydse mine fingre i håb om, at jeg ville have en tung behandling, der passer til kravene i dette indlæg.
den hurtigste måde at se arbejdsbyrde i dit databasemiljø fra EM12c, klik på mål – > databaser. Vælg at se efter load map, og du vil derefter se databaser efter arbejdsbyrde. Da jeg gik til et specifikt Enterprise Manager-miljø, fandt jeg ud af, at det var min heldige dag!
 jeg ved virkelig ikke, hvem Kurt er, der har en database overvåget på dette EM12c cloud control miljø, men dreng, er han min favorit person i dag! 1878 >
jeg ved virkelig ikke, hvem Kurt er, der har en database overvåget på dette EM12c cloud control miljø, men dreng, er han min favorit person i dag! 1878 >
svæver min markør over databasenavnet, (kurt) du kan se den arbejdsbyrde, han har kørt på sin testdatabase i øjeblikket: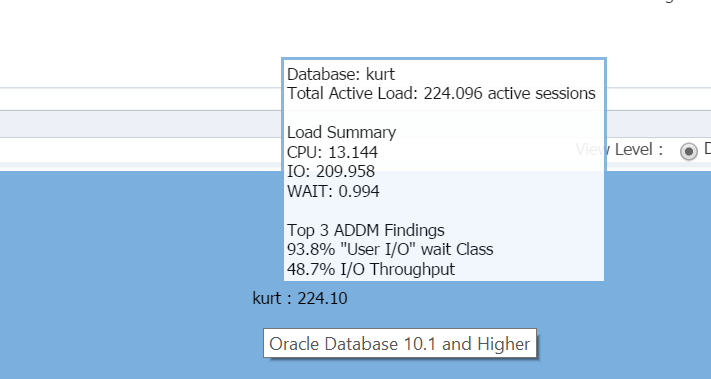
dreng, er Kurt min favorit person i dag!
EM12c Database Startside
Log ind i databasen, jeg kan se den betydelige Io og ressourceforbrug til databasen og værten fra databasens startside:
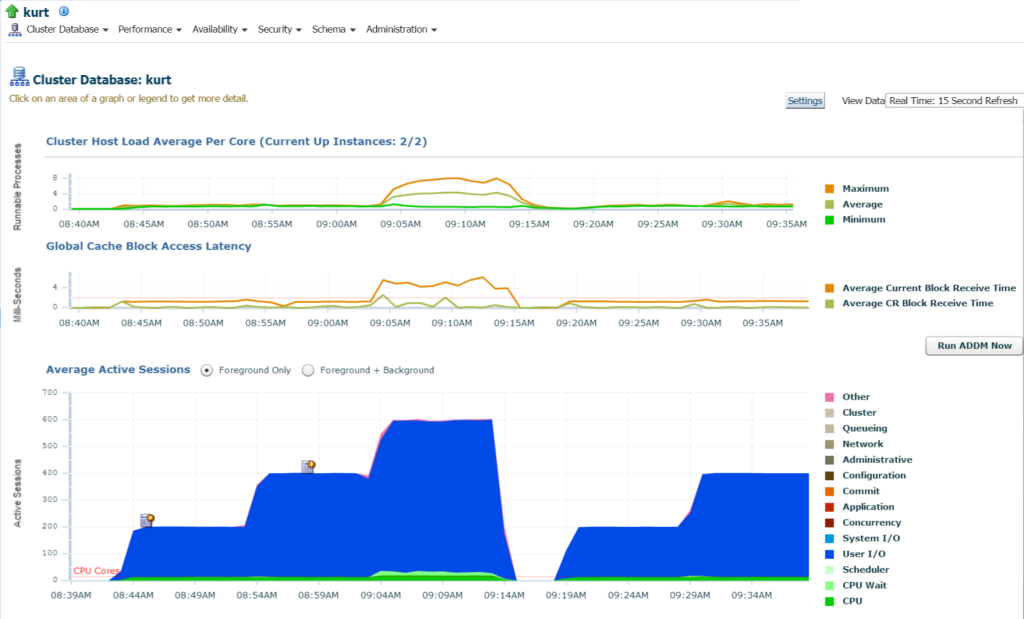
hvis vi flytter til topaktivitet, (Præstationsmenu, topaktivitet) begynder jeg at se flere detaljer om behandlingen og forskellige ventehændelser:
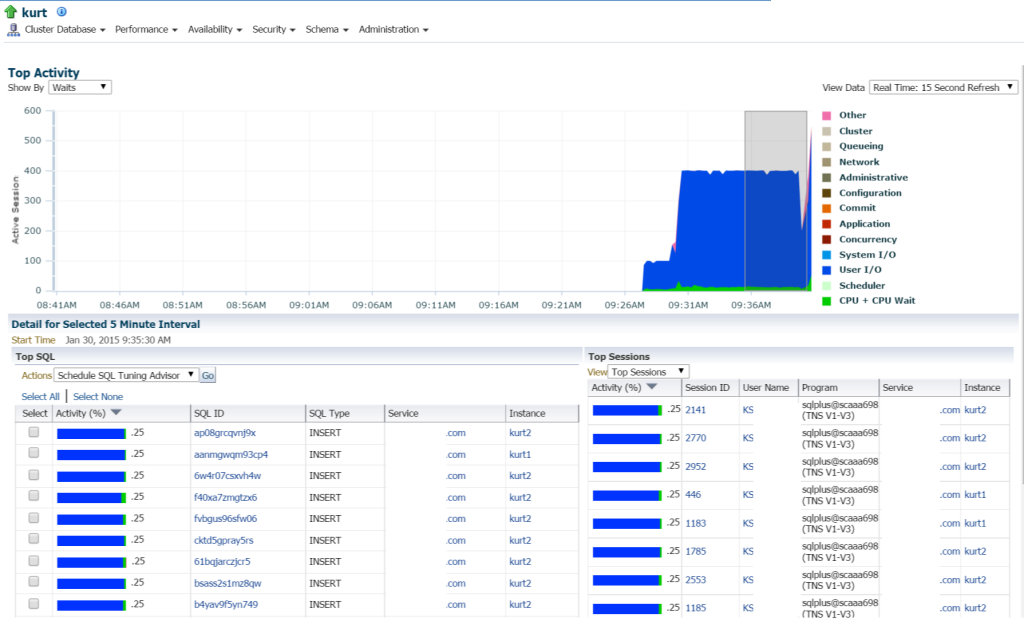
Kurt laver alle slags indsatser, (set af de forskellige Kvl_id ‘ er, af KVL Type “indsæt”. Jeg kan bore ned i de enkelte udsagn og undersøge dette, men virkelig er der masser af udsagn og KVL_ID ‘ er her, ville det ikke bare være lettere at se arbejdsbyrden med en APR-rapport?
kører ÅRSREGNSKABSRAPPORTEN
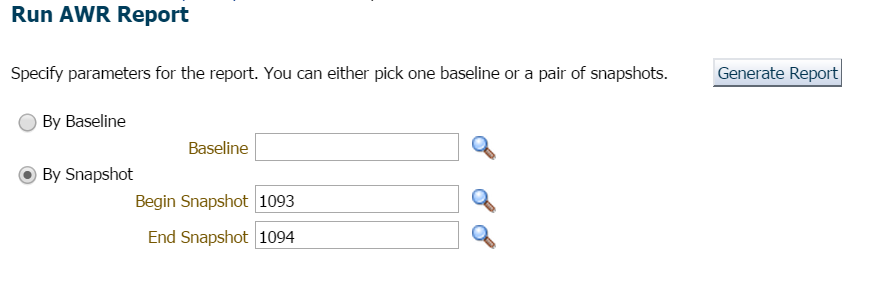
jeg vælger at klikke på Performance, ÅRSREGNSKABSRAPPORT. Nu har jeg et valg. Jeg kunne anmode om et nyt øjebliksbillede, der skal udføres med det samme, eller jeg kunne vente til toppen af timen, da intervallet er indstillet hver time i denne database. Jeg valgte sidstnævnte til denne demonstration, men hvis du ønskede at oprette et øjebliksbillede med det samme, kan du gøre det nemt fra EM12c eller anmode om et øjebliksbillede ved at udføre følgende fra
BEGINDBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT ();END;/
for dette eksempel ventede jeg simpelthen, da der ikke var travlt eller bekymring her og anmodede om rapporten for den foregående time og det seneste øjebliksbillede:
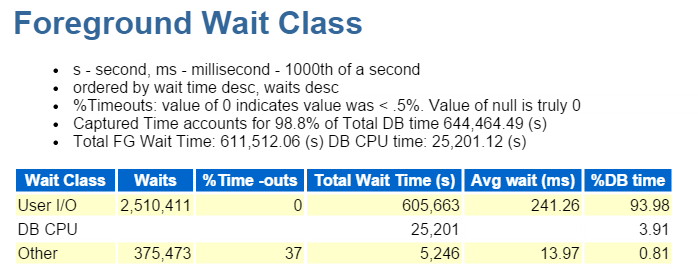
jeg starter altid ved de ti øverste Forgrundsbegivenheder og ser ofte på dem med høje venteprocenter:
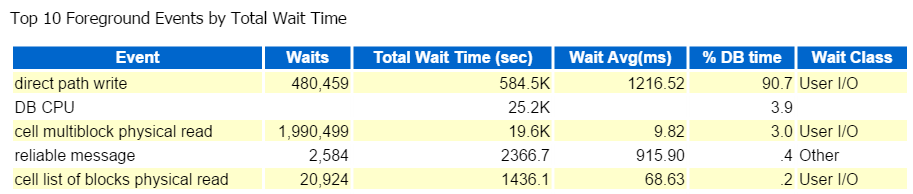
direkte sti skrive, det er det. Intet andet at se her… krit
direkte stiskrivning involverer følgende: indsatser/opdateringer, objekter, der skrives til, tablespaces skrives til og de datafiler, der udgør tablespace(s).
det er også IO, som vi hurtigt verificerer ned i forgrunden Venteklasse:
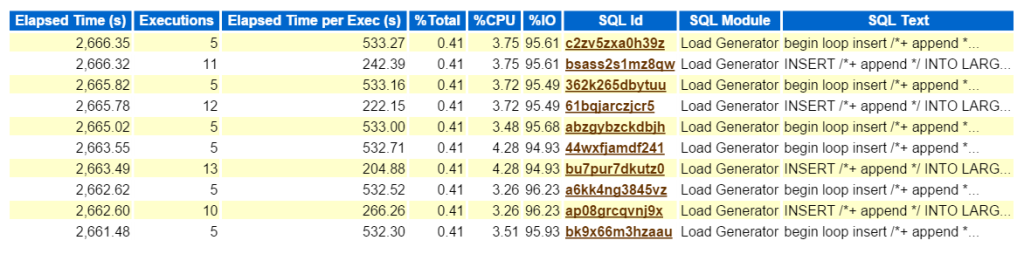
at se på den øverste KVL efter forløbet tid bekræfter, at vi har at gøre med en arbejdsbyrde bestående af alle indsatser:
ved at klikke på ID ‘ et, fører mig til den komplette liste over tekst og viser mig, hvad Bad Boy Kurt gør for at producere sin testarbejdsbelastning:

at Kurt er noget af en rebel, ikke? Venstre
Indsæt i en løkke i en tabel fra samme tabel, rollback og derefter afslutte løkken, tak for at spille. Han sparker nogle dæk og gør det med angst! Bare rolig folk, som jeg sagde, Kurt gør sit job ved hjælp af et modul kaldet “Load Generator”. Jeg ville være en fjols for ikke at genkende dette som noget andet end hvad det er – generere arbejdsbyrde for at teste noget. Jeg får bare den ekstra fordel ved at have en arbejdsbyrde til at lave et blogindlæg om brug af ar-data… Karl
nu, hvis dette var et reelt problem, og jeg forsøgte at finde ud af, hvad denne type præstationspåvirkning denne type indsats skabte på miljøet, hvor skal man gå næste i ar-rapporten? Den øverste KVL efter forløbet tid er vigtig, da det skal være, hvor du fokuserer din indsats. Andre sektioner opdelt efter KVL er rart at have, men husk altid, “hvis du ikke indstiller tid, spilder du tid.”Intet kan komme af en optimeringsøvelse, hvis der ikke ses tidsbesparelser, efter at du har afsluttet arbejdet. Så ved først at tage den øverste KVL efter forløbet tid og derefter se på udsagnet, kan vi nu se, hvilke objekter der er en del af udsagnet (large_block149, 191, 194, 145).
vi ved også, at problemet er IO, så vi skal hoppe ned fra de detaljerede oplysninger og gå til objektniveauoplysningerne. Disse sektioner er identificeret af segmenter af
- segmenter af logiske læser
- segmenter af fysiske læser
- segmenter af læse anmodninger
- segmenter af tabel scanninger
så videre og så videre….
disse viser alle et meget lignende mønster og procentdel for de objekter, vi ser i vores topkvm. Husk, Kurt læste hver af disse tabeller, derefter indsætte de samme rækker tilbage i tabellen igen, derefter rulle tilbage. Da dette er et arbejdsbelastningsscenarie, i modsætning til de fleste ydelsesproblemer, jeg ser, er der ingen fremragende objektvisning med en over 10% effekt i ethvert område.

da dette er en Eksadata, er der masser af oplysninger, der hjælper dig med at forstå aflæsning, (smart scanninger) flash cache osv. det vil hjælpe med at videresende de oplysninger, du har brug for for at sikre dig, at du opnår den ydelse, du ønsker med et konstrueret system, men jeg vil gerne gemme det til et andet indlæg og bare røre ved et par af IO-rapporterne, da vi udførte bordscanninger, så vi ønsker at sikre, at de blev aflæst til celleknudepunkterne (smarte scanninger) vs. udføres på en databaseknude.
vi kan starte med at se på Top Database IO Throughput:

og se derefter de øverste Databaseanmodninger pr. Cellegennemstrømning (sans cellenodenavnene) for at se, hvordan de sammenligner: