Il y a un certain nombre de cas où vous ne souhaitez peut-être pas que des pages apparaissent dans les SERPS, et cet article de blog discute des différentes façons dont nous pouvons le faire.
Les principaux moyens de garder une page hors des résultats de recherche sont:
- Balises Noindex
- Blocage sur les robots.txt
- Suppression de la page
- Outil de suppression de Google Search Console.
- Balises canoniques
- Quel type de contenu ne voudrions-nous pas apparaître dans les SERPs?
- Comment Google trouve-t-il du contenu à afficher dans les résultats de recherche?
- Comment contrôler le classement des pages dans les résultats de recherche ?
- Balises Noindex
- Blocage dans les robots txt
- Suppression de la page
- Outil de suppression de Google Search Console
- Balises canoniques
- Pensées finales
Quel type de contenu ne voudrions-nous pas apparaître dans les SERPs?
Il existe différents types de pages que nous ne voudrions pas pouvoir rechercher sur Google ou d’autres moteurs de recherche.
Les exemples incluent:
- Pages de destination PPC
- Pages de remerciement
- Pages d’administration
- Résultats de recherche internes
Nous pouvons également vouloir masquer des pages de Google pour un certain nombre de raisons, notamment:
- Duplication de page – Pour empêcher de nombreuses versions d’une même page d’apparaître dans les résultats de recherche.
- Cannibalisation des mots clés – Pour empêcher deux pages similaires ou plus de se concurrencer pour un mot clé particulier
- Gaspillage de budget d’analyse – Je discuterai de l’exploration dans cette section, mais cela fait référence à Google qui passe trop de temps à découvrir des pages de valeur inférieure sur votre site, plutôt que de hiérarchiser les choses importantes.
Comment Google trouve-t-il du contenu à afficher dans les résultats de recherche?
Avant de nous pencher sur les différentes façons d’empêcher les pages d’apparaître dans les résultats de recherche, il convient de comprendre le processus utilisé par Google pour trouver et finalement classer les pages.
1) Ramper – C’est la façon dont Google découvre de nouveaux contenus. À l’aide de programmes, souvent appelés araignées ou robots d’exploration, Google visite différentes pages Web et suit les liens qui s’y trouvent pour trouver de nouvelles pages. Chaque site dispose d’un certain « budget d’exploration » ou de la quantité de ressources qu’il alloue à chaque site.
2) Indexation – Une fois que Google a trouvé le contenu, il conserve une copie de ce contenu et le stocke dans ce qu’on appelle un index.
3) Classements – L’ordre de ces différentes pages dans les résultats de recherche est appelé classement. Google obtient une requête, détermine l’intention de recherche derrière cette requête, puis se tourne vers l’index pour renvoyer les meilleurs résultats possibles.
Google utilise une gamme de calculs différents, appelés algorithmes, pour déterminer quels sont les meilleurs résultats à fournir et les classe du plus pertinent au moins pertinent.
Comment contrôler le classement des pages dans les résultats de recherche ?
Balises Noindex
Les balises Noindex sont une directive qui indique à Google « Je ne veux pas que cette page soit indexée et ne souhaite donc pas qu’elle apparaisse dans les résultats de recherche. »
Lorsque Google explore ensuite cette page et voit les directives noindex, il supprimera cette page de son index et donc des résultats de recherche.
Ces balises noindex peuvent être implémentées de deux manières:
- En les incluant dans le code HTML de la page
- En renvoyant un en-tête noindex dans la requête HTTP.
Les balises Noindex implémentées dans le HTML ressembleraient à ceci:<meta name="robots" content="noindex">
Les balises Noindex implémentées via l’en-tête HTTP ressembleraient à ceci:HTTP/... 200 OK
…
X-Robots-Tag: noindex
Les plates-formes CMS, telles que WordPress, vous permettent d’ajouter des balises noindex aux pages, ce qui signifie que vous n’auriez pas besoin d’un développeur pour l’implémenter.
Il est important que Google puisse analyser ces pages afin de voir la balise « noindex », puis supprimer la page de son index.
Quand utiliser les balises noindex – S’il y a des pages sur votre site qui servent toujours à quelque chose, mais que vous ne souhaitez pas apparaître dans les résultats de recherche, c’est une bonne option.
Blocage dans les robots txt
Robots.txt est un fichier texte utilisé pour indiquer aux robots Web comment se comporter lorsqu’ils visitent votre site et peut être utilisé pour dicter aux robots d’exploration des moteurs de recherche s’ils peuvent ou non explorer des parties d’un site Web.
Voir l’exemple ci-dessous des robots Nike.fichier txt qui vit à https://www.nike.com/robots.txt
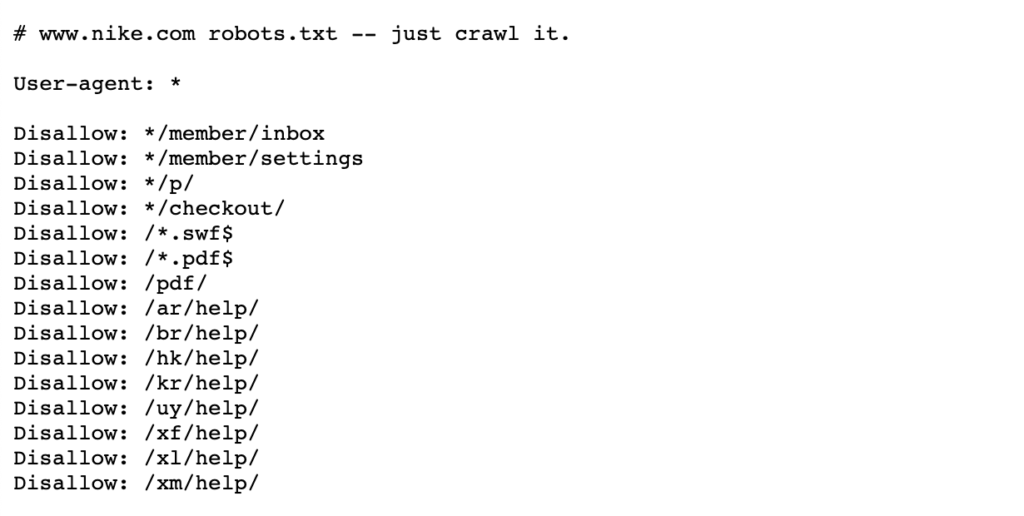
Utilisant des robots.txt pour bloquer certains chemins de page tels que /admin/, par exemple, signifie que Googlebot ou d’autres robots de recherche ne visiteront même pas ces pages – ils n’apparaîtront donc pas dans les résultats de recherche. Cela peut préserver le budget d’analyse pour les pages plus importantes plutôt que de se concentrer sur les pages moins importantes.
Remarque : blocage d’un chemin de page dans les robots.txt empêche Google d’enregistrer la page en premier lieu, mais il ne supprime ni ne modifie ce qui a été enregistré. Par conséquent, si une page apparaît déjà dans les résultats de recherche, Google a déjà exploré puis indexé cette page.
Si vous avez besoin d’une page supprimée, bloquez-la dans les robots.txt empêchera activement cela de se produire. Dans ce cas, la meilleure chose à faire est d’ajouter une balise noindex pour supprimer ces pages de l’index de Google et une fois qu’elles sont toutes supprimées, vous pouvez ensuite bloquer les robots.txt.
Plus de détails peuvent être trouvés sur cette page centrale de recherche Google.
Quand bloquer les pages dans les robots.txt – Lorsque vous avez des chemins de page spécifiques ou des sections plus grandes de votre site que vous ne souhaitez pas que Google explore, c’est votre meilleur pari.
Si une page ou une collection de pages apparaît déjà dans les SERPs, vous devrez d’abord ne pas les indexer et attendre qu’elles soient supprimées avant d’ajouter les robots.fichier txt.
Suppression de la page
La réponse la plus évidente, vous avez peut-être pensé, serait de simplement supprimer la page, que ce soit en lui donnant un code d’état 404 ou 410.
Les deux codes d’état remplissent la même fonction en ce sens que Google supprimera la page de son index lors de l’exploration suivante de cette page, bien qu’un statut 410 puisse être légèrement plus rapide selon John Mueller de Google.
D’un point de vue SEO, si ces pages ont de la valeur, que ce soit par le biais de backlinks ou de trafic, il vaudrait la peine de rediriger 301 vers une page pertinente afin de consolider cette équité de lien sur le site.
Alternativement, si la page contient des liens internes et que vous ne disposez pas d’une page appropriée vers laquelle rediriger, ces liens internes doivent être supprimés ou remplacés par une page de code d’état 200.
Quand supprimer une page – Si la page ne sert à rien et a peu de valeur en termes de backlinks ou de trafic, elle peut valoir la peine d’être supprimée. S’il y a une certaine valeur du point de vue de l’utilisateur ou du point de vue du référencement, envisagez de la conserver avec une balise noindex ou une redirection 301 vers une page pertinente.
Outil de suppression de Google Search Console
L’outil de suppression de Google Search Console peut être utilisé pour bloquer temporairement les résultats de recherche de votre site pour les sites que vous possédez sur Google Search Console. Il est à noter que ce n’est pas une solution permanente.
Si vous souhaitez supprimer rapidement une page des résultats de recherche, c’est une bonne option. Si vous souhaitez supprimer définitivement une page, Google recommande de lui donner un statut 404 ou 410, de bloquer l’accès au contenu en utilisant un mot de passe ou de donner à la page une balise noindex.
Plus de détails peuvent être trouvés sur cette page Google Webmasters.
Quand utiliser l’outil de suppression de Google Search Console – Lorsque vous devez vous débarrasser rapidement d’une page. Si vous devez supprimer définitivement la page, utilisez une balise noindex ou donnez-lui un statut 404 ou 410.
Balises canoniques
Une balise canonique est un extrait de code HTML qui se trouve dans la < tête > de la page et est utilisée pour définir la version principale des pages similaires ou en double. Les balises canoniques aident à prévenir les problèmes causés par le contenu en double ou en quasi-double apparaissant sur plusieurs URL.
Voir l’exemple ci-dessous d’une balise canonique sur la page d’accueil de Brainlabs:

Si vous canonisez une page sur une autre, vous dites que vous ne souhaitez pas que cette page apparaisse dans les résultats de recherche et que vous préféreriez qu’une autre version de cette page apparaisse à la place.
Contrairement aux balises noindex qui sont des ordres, les balises canoniques peuvent être ignorées par Google. Google peut toujours explorer ces pages, voir les balises canoniques, puis décider si la page doit apparaître ou non dans les résultats de recherche.
Quand utiliser les balises canoniques – Les balises canoniques doivent être utilisées lorsqu’il existe plusieurs classements de pages en double ou similaires. Vous voudrez canoniser les versions non maîtres en une version principale d’une page pour indiquer à Google que la version principale est la seule version que vous souhaitez dans les résultats de recherche. Cela consolidera également les signaux de chacune de ces URL sur une page maître.
Un excellent exemple d’utilisation de balises canoniques est pour les pages qui ont des paramètres. Ces pages peuvent avoir exactement le même contenu mais des URL différentes en raison de ces paramètres. Les balises canoniques peuvent aider à garantir la version correcte d’un classement de page, pas n’importe laquelle des autres versions.
Exemple

Pensées finales
Il existe un certain nombre de façons de supprimer ou de contrôler le contenu qui apparaît dans les résultats de recherche. La clé est de vous assurer que vous choisissez la meilleure option pour votre situation particulière, sans essayer de les faire toutes en même temps!
