Zum Abschnitt springen
- SQL Einführung
- Arbeiten mit SQL-Joins
- Inner Join
- Linker Join
- Rechts beitreten
- Volle äußere Verbindung
- Cross Join
- So arbeiten Sie mit Advance SQL Joins
- Linker Join
- Volle äußere Verbindung
- Schlüsseltypen in SQL
- Kandidatenschlüssel
- Primärschlüssel
- Eindeutiger Schlüssel
- Alternativer Schlüssel
- Zusammengesetzter Schlüssel
- Super Key
- Fremdschlüssel
- Arbeiten mit SQL-Funktionen
- LEFT() Funktion
- RIGHT() Funktion
- CHARINDEX() Funktion
- SUBSTRING() Funktion
- REPLICATE() Funktion
- SPACE() Funktion
- PATINDEX() -Funktion
- REPLACE() Funktion
- STUFF() Function
- Datums-/ Uhrzeitfunktion
- IsDate() Funktion
- Month() Funktion
- Year() Funktion
- Dataame() Funktion
- DatePart() -Funktion
- DateAdd()
- DatedDiff() Funktion
- Cast() – und Convert() -Funktionen
- Benutzerdefinierte Funktionen
- Skalarfunktionen
- Inline-Funktionen mit Tabellenwerten
- MULTI-STATEMENT TABLE VALUED FUNCTION
- Conclusion
SQL Einführung
SQL steht für Structured Query Language. Es wird hauptsächlich für Datenmanipulation, Datenänderung und Datenabruf verwendet. Dies geschieht mit dem relationalen Datenbankverwaltungssystem (RDBMS).
Wir werden über erweiterte Funktionen von SQL wie Joins und Funktionen lernen.
Arbeiten mit SQL-Joins
Ein einfaches Join-Mittel besteht darin, zwei oder mehr Tabellen in einer bestimmten Datenbank zu kombinieren. Ein Join arbeitet an einer gemeinsamen Entität von zwei Tabellen.
Ein Join enthält 5 Sub-Joins wie: Inner Join, Outer Join, Left Join, Right Join und Cross Join.
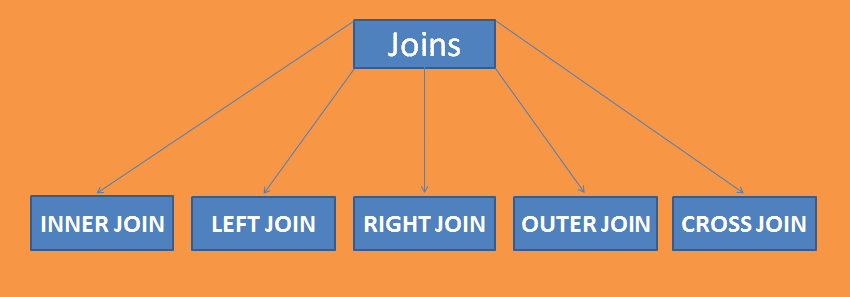
Inner Join
Ein Inner Join wird verwendet, um Datensätze auszuwählen, die gemeinsame oder übereinstimmende Werte in beiden Tabellen (Tabelle A und Tabelle B) enthalten. Nicht übereinstimmende werden eliminiert.
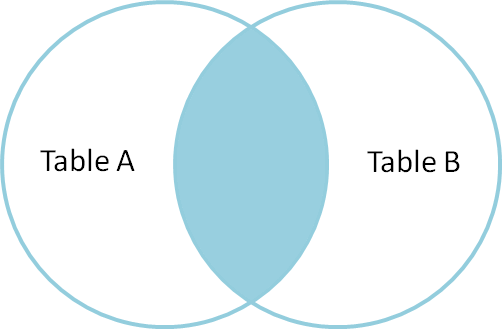
Lassen Sie uns also die Art der Verknüpfungen anhand allgemeiner Beispiele und der Unterschiede zwischen ihnen verstehen.
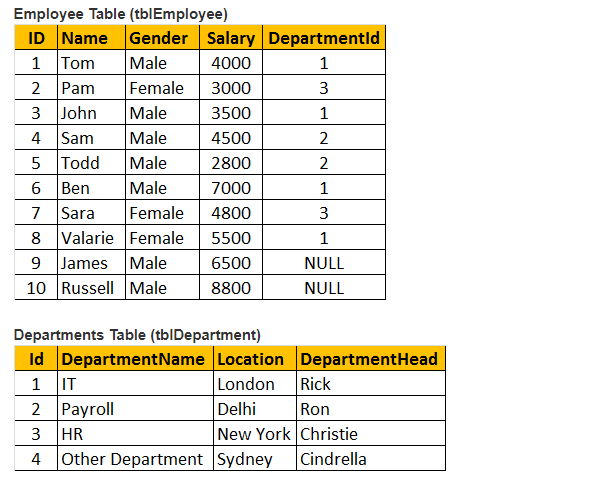
Tabelle 1: Mitarbeitertabelle (tblEmployee)
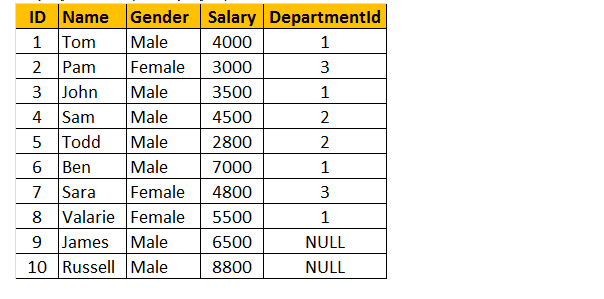
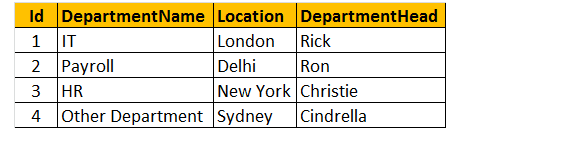
Tabelle 2: Abteilungstabelle (tblDepartments)
Erstellen wir also die Tabelle tblDepartments zur Ausführung eines Programms.

Fügen Sie nun Datensätze in die Tabelle tblDepartments ein.

Lassen Sie uns eine weitere Tabelle tblEmployee für die Ausführung eines Programms erstellen.

Fügen Sie also Datensätze in die Tabelle tblEmployee ein.

Daher eine allgemeine Formel für Joins.

Um eine Abfrage durchzuführen, um Name, Geschlecht, Gehalt und Abteilungsname aus den Tabellen tblEmployee und tblDepartments zu finden.

Hinweis: JOIN oder INNER JOIN bedeutet dasselbe. Aber immer besser, INNER JOIN zu verwenden, und dies gibt Ihre Absicht explizit an.
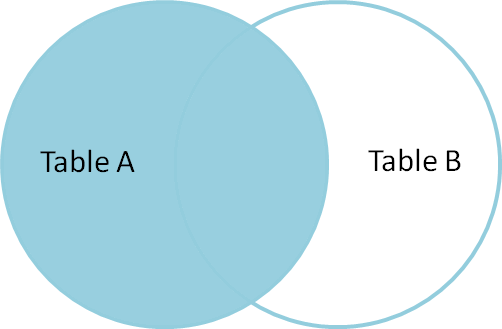
Ausgabe: Die endgültige Ausgabetabelle sieht nun folgendermaßen aus;
Wenn Sie sich das Ausgabefenster ansehen, haben wir nur 8 Zeilen, aber in der Tabelle tblEmployee haben wir 10 Zeilen. Wir haben keine JAMES- und RUSSELL-Platten bekommen. Dies liegt daran, dass die DEPARTMENTID in der Tabelle tblEmployee für diese beiden Mitarbeiter NULL ist und nicht mit ihrer ID-Spalte in der Tabelle tblDepartments übereinstimmt.
In einer abschließenden Anweisung geben Innere Verknüpfungen also nur übereinstimmende Zeilen aus den Tabellen zurück, und nicht übereinstimmende Zeilen werden aufgrund ihrer Unterabfrage eliminiert.
Linker Join
LEFT Join gibt alle übereinstimmenden Zeilen und nicht übereinstimmenden Zeilen aus der linken Seitentabelle zurück. Darüber hinaus werden Inner Join und Left Join gegenseitig ausgiebig verwendet.
Nehmen wir also ein Beispiel: Ich möchte alle Zeilen aus der tblEmployee-Tabelle, einschließlich JAMES- und RUSSELL-Datensätzen. Dann wird die Ausgabe wie folgt aussehen;

Rechts beitreten
RIGHT Join gibt alle übereinstimmenden Zeilen und nicht übereinstimmenden Zeilen aus der rechten Seitentabelle zurück.
Nehmen wir also ein Beispiel; Ich möchte, dass alle Zeilen aus den Tabellen in den Join einbezogen werden. Als Ergebnis wäre wie;

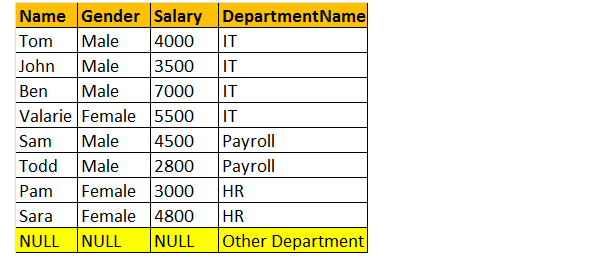
Volle äußere Verbindung

OUTER Join oder FULL OUTER Join gibt alle Zeilen aus der linken und rechten Tabelle zurück, einschließlich der nicht übereinstimmenden Zeilen aus den Tabellen.
Nehmen wir also ein Beispiel. Ich möchte alle Zeilen aus beiden Tabellen, die am Join beteiligt sind.

Cross Join
Dieser Join ergibt das kartesische Produkt der 2 Tabellen in der Join-Funktion. Dieser Join enthält keine ON-Klausel.
Also, lasst uns ein Beispiel verstehen: In der Tabelle tblEmployee haben wir 10 Zeilen und in der Tabelle tblDepartments 4 Zeilen. Eine Kreuzverknüpfung zwischen diesen 2 Tabellen erzeugt also 40 Zeilen.
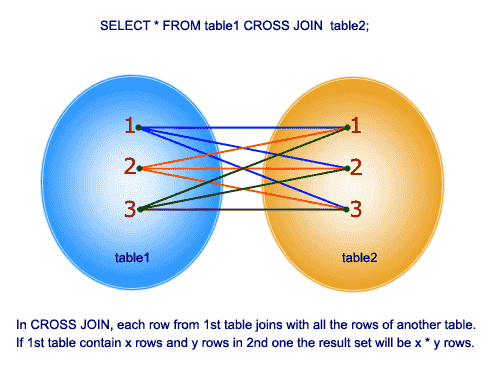

So arbeiten Sie mit Advance SQL Joins
In dieser Sitzung werde ich diese Dinge wie folgt erklären;
- Erweiterte oder intelligente Joins in SQL Server.
- Abrufen von Daten nur die nicht übereinstimmenden Zeilen aus der linken Tabelle.
- Ruft nur die nicht übereinstimmenden Zeilen aus der rechten Tabelle ab.
- Abrufen von Daten nur die nicht übereinstimmenden Zeilen aus der linken und rechten Tabelle.
Betrachten wir also sowohl die Tabellen tblEmployee als auch tblDepartment .
Linker Join
Also, lassen Sie uns ein Beispiel verstehen, ich möchte nur die nicht übereinstimmenden Zeilen aus der linken Seitentabelle abrufen.

Ausgabe: Schließlich sieht die Ausgabe folgendermaßen aus;

Rechts beitreten
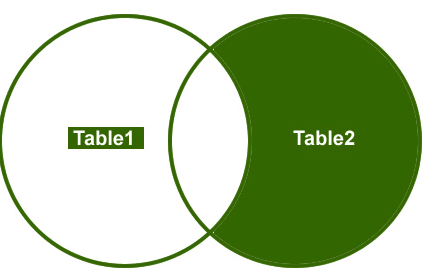
Also, lassen Sie uns ein Beispiel verstehen, ich möchte nur die nicht übereinstimmenden Zeilen aus der rechten Seitentabelle abrufen.

Ausgabe: Schließlich sieht die Ausgabe folgendermaßen aus;

Volle äußere Verbindung
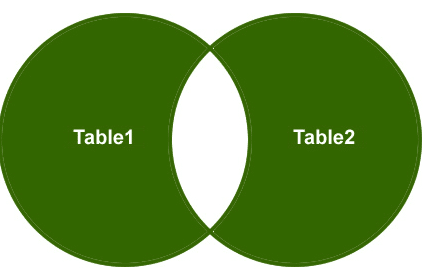
Also, lassen Sie uns ein Beispiel verstehen, ich möchte nur die nicht übereinstimmenden Zeilen aus der rechten Seitentabelle und der linken Seitentabelle abrufen und übereinstimmende Zeilen sollten eliminiert werden.

Ausgabe: Schließlich sieht die Ausgabe folgendermaßen aus:
Schlüsseltypen in SQL
Ein Schlüssel in SQL ist ein Datenfeld, das ausschließlich einen Datensatz identifiziert. Mit anderen Worten, ein Schlüssel ist eine Reihe von Spalten, die verwendet werden, um den Datensatz in einer Tabelle eindeutig zu identifizieren.
- Erstellen Sie Beziehungen zwischen zwei Tabellen.
- Eindeutigkeit und Haftung in einer Tabelle beibehalten.
- Bewahren Sie konsistente und gültige Daten in einer Datenbank auf.
- Kann beim schnellen Abrufen von Daten helfen, indem Indizes für Spalten erleichtert werden.
Ein SQL Server enthält Schlüssel wie folgt;
- Kandidatenschlüssel
- Primärschlüssel
- Eindeutiger Schlüssel
- Alternativer Schlüssel
- Zusammengesetzter Schlüssel
- Superschlüssel
- Fremdschlüssel
Bevor Sie fortfahren, schauen Sie sich bitte das Bild unten an;
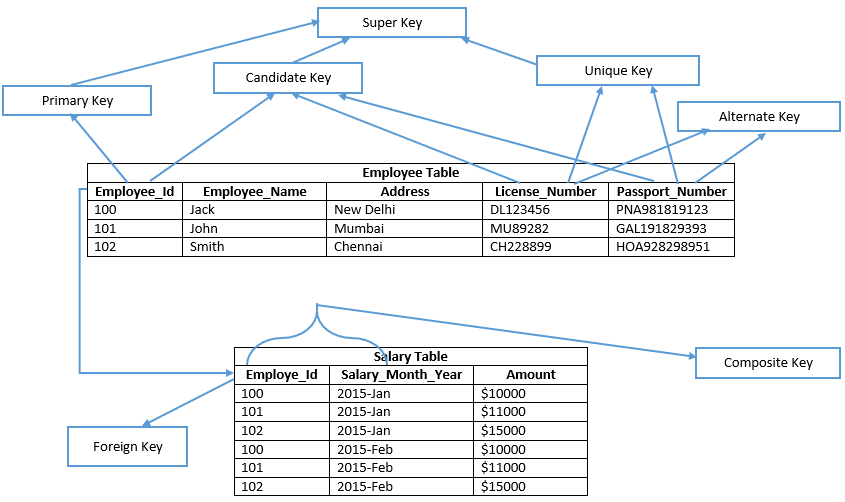
Lassen Sie uns jeden Schlüssel im Detail verstehen
Kandidatenschlüssel
Ein Kandidatenschlüssel ist ein Schlüssel einer Tabelle, der als Primärschlüssel der Tabelle ausgewählt werden kann, und eine Tabelle kann mehrere Kandidatenschlüssel haben, daher kann einer als Primärschlüssel ausgewählt werden.
Beispiel: Employee_Id, License_Number, & Passport_Number zeigt Kandidatenschlüssel
Primärschlüssel
Ein Primärschlüssel ähnelt dem ausgewählten Kandidatenschlüssel der Tabelle, um jeden Datensatz eindeutig in der Tabelle zu überprüfen. Daher enthält der Primärschlüssel in keiner der Spalten einer Tabelle einen Nullwert und behält auch eindeutige Werte in der Spalte bei. Im angegebenen Beispiel definiert Employee_Id den Primärschlüssel der Employee-Tabelle. Daher erstellt der Primärschlüssel in SQL Server Management Studio standardmäßig einen Clusterindex für eine Heap-Tabelle, und eine Tabelle, die keinen Clusterindex enthält, wird als Heap-Tabelle bezeichnet. Definiert explizit einen nicht gruppierten Primärschlüssel für eine Tabelle nach Indextyp.
Darüber hinaus kann eine Tabelle nur einen Primärschlüssel haben und der Primärschlüssel kann in SQL Server mithilfe von SQL-Anweisungen definiert werden:
- – TABLE-Anweisung (zum Zeitpunkt der Tabellenerstellung) – als Ergebnis definiert das System den Namen des Primärschlüssels.
- ALTER TABLE-Anweisung (unter Verwendung einer Primärschlüsseleinschränkung) – Als Ergebnis deklariert der Benutzer selbst den Namen der Primärschlüsseleinschränkung.
Beispiel: Employee_Id ist ein Primärschlüssel der Employee-Tabelle.
Eindeutiger Schlüssel
Ein eindeutiger Schlüssel entspricht dem Primärschlüssel und enthält keine doppelten Werte in der Spalte. Es hat folgende Unterschiede im Vergleich des Primärschlüssels:
- Es erlaubt einen Nullwert in der Spalte.
- Standardmäßig werden ein nicht gruppierter Index und Heap-Tabellen erstellt.
Alternativer Schlüssel
Der alternative Schlüssel ähnelt dem Kandidatenschlüssel, ist jedoch nicht als Primärschlüssel der Tabelle ausgewählt.
Beispiel: License_Number und Passport_Number sind alternative Schlüssel.
Zusammengesetzter Schlüssel
Zusammengesetzter Schlüssel (auch als zusammengesetzter Schlüssel oder verketteter Schlüssel bezeichnet) ist eine Gruppe von zwei oder mehr Spalten, die jede Zeile einer Tabelle eindeutig identifiziert. Darüber hinaus kann eine einzelne Einheitsspalte eines zusammengesetzten Schlüssels die Datensätze möglicherweise nicht eindeutig verifizieren. Als Ergebnis kann es entweder Primärschlüssel oder Kandidatenschlüssel auch sein.
Beispiel: In der Tabelle Employee_Id & Salary_Month_Year überprüfen beide Spalten jede Zeile eindeutig in der Gehaltstabelle. Daher die Spalte Employee_Id oder Salary_Month_Year in der Tabelle, die nicht jede Zeile eindeutig identifizieren kann. Wir können einen einzelnen zusammengesetzten Primärschlüssel für die Gehaltstabelle erstellen, indem wir die Spaltennamen Employee_Id und Salary_Month_Year .
Super Key
Super key ist ein Satz von Spalten, von denen alle Spalten der Tabelle funktional abhängig sind. Aufgrund der Menge von Spalten, die jede Zeile in einer Tabelle eindeutig identifiziert. Mit anderen Worten, dieser Schlüssel enthält einige zusätzliche Spalten, die nicht unbedingt erforderlich sind, um jede Zeile in der Tabelle eindeutig zu überprüfen. Es scheint, dass Primärschlüssel und Kandidatenschlüssel minimale Superschlüssel sind, oder Sie können eine Teilmenge von Superschlüsseln sagen.
Schauen wir uns also das obige Beispiel an: In der Tabelle Employee reicht der Spaltenname Employee_Id kaum aus, um eine Zeile der Tabelle eindeutig zu überprüfen. Also, dass jeder Satz einer Spalte aus der Employee-Tabelle, die Employee_Id enthält, ein Superkey für die Employee-Tabelle ist.
Zum Beispiel: {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id, Employee_Name, Address} usw.
License_Number und Passport_Number sind die Spaltennamen, sie können auch jede Zeile der Tabelle eindeutig überprüfen. Jeder Spaltennamensatz, der aus License_Number oder Passport_Number oder Employee_Id besteht, ist ein Superkey der Tabelle.
Zum Beispiel: {License_Number, Employee_Name, Adresse}, {License_Number, Employee_Name, Passport_Number}, {Passport_Number, Employee_Name, Adresse, Lizenznummer}, {Passport_Number, Employee_Name}, {Passport_Number, Employee_Id} usw.
Fremdschlüssel
Ein FK definiert die Beziehung zwischen zwei oder mehr als zwei Tabellen gleichzeitig. Ein Primärschlüssel einer einzelnen Tabelle wird auf einen Fremdschlüssel in einer anderen Tabelle verwiesen. Ein Fremdschlüssel kann doppelte Werte in einer Tabelle haben und auch Nullwerte haben, wenn der Spaltenname so definiert ist, dass er noch Nullwerte akzeptiert.
Zum Beispiel ist der Spaltenname „Employee_Id“ (der ein Primärschlüssel der Employee-Tabelle ist) ein Fremdschlüssel in der Gehaltstabelle.
Hinweis: Schlüssel wie Primärschlüssel und eindeutiger Schlüssel erstellen Indizes mit Schlüsselspalten. Organisierte Daten im B-Baumstrukturknoten (Ausgeglichener Baum: Blattknoten befinden sich alle auf einer anderen Ebene als die Stammseite) in SQL Server. Daher erstellt der nicht gruppierte Index eine separate Struktur von der Basisdatentabelle, aber der gruppierte Index konvertiert die Basisdatentabelle von der Heap-Struktur in eine B-Baumstruktur.
Darüber hinaus erstellt der Clustered Index keine separate Struktur neben der Basistabelle, weshalb wir nur einen Clustered Index für eine Tabelle erstellen können. Daher können wir eine Tabelle nur auf eine Weise sortieren (sie kann mehrere Spalten zum Sortieren haben, aber das Sortieren kann nur auf eine Weise erfolgen), nämlich in der Reihenfolge des gruppierten Index.
Arbeiten mit SQL-Funktionen
Eine Funktion ist ein Entitätsprogramm, das in der SQL Server-Datenbank gespeichert ist. Darüber hinaus werden wir uns auf einige sehr nützliche integrierte Funktionen und benutzerdefinierte Funktionen freuen.
Coalesce-Funktion
Coalesce() : Diese Funktion gibt nur den ersten Wert Ungleich NULL zurück. Nehmen wir also ein Beispiel über die Funktion Coalesce().
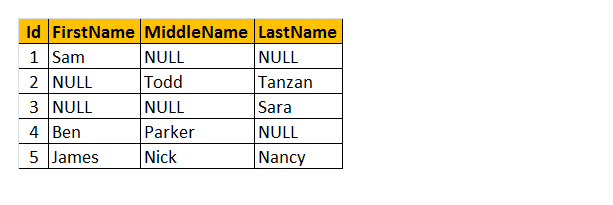 Lassen Sie uns die Tabelle als Name ‚Employee‘ oben verstehen. Infolgedessen können Sie sehen, dass bei einigen Mitarbeitern der Vorname fehlt, bei einigen der zweite Vorname und bei einigen der Nachname. Ich möchte also nur den „Namen“ des Mitarbeiters zurückgeben.
Lassen Sie uns die Tabelle als Name ‚Employee‘ oben verstehen. Infolgedessen können Sie sehen, dass bei einigen Mitarbeitern der Vorname fehlt, bei einigen der zweite Vorname und bei einigen der Nachname. Ich möchte also nur den „Namen“ des Mitarbeiters zurückgeben.
Wie wird es funktionieren? Verstehen Sie, wir verarbeiten die Spalten FirstName, MiddleName und LastName als Parameter für die Funktion COALESCE(). Daher gibt diese Funktion den einzigen ersten Wert ungleich Null aus 3 der Spalten zurück.
Abfrage: Select Id, COALESCE(FirstName, MiddleName, LastName) AS Name FROM tblEmployee
Schließlich sieht die Ausgabe folgendermaßen aus;
 LEFT() Funktion
LEFT() Funktion
LEFT(Character_Expression, Integer_Expression) – Diese Funktion gibt die angegebene Anzahl von Zeichen von der linken Seite des angegebenen Zeichenausdrucks zurück.
Beispiel: Select LEFT(‚ABCDE‘, 3)
Ausgabe: ABC
RIGHT() Funktion
RIGHT(Character_Expression, Integer_Expression) – Diese Funktion gibt die angegebene Anzahl von Zeichen von der rechten Seite des angegebenen Zeichenausdrucks zurück.
Beispiel: RECHTS auswählen(‚ABCDE‘, 3)
Ausgang: CDE
CHARINDEX() Funktion
CHARINDEX(‚Expression_To_Find‘, ‚Expression_To_Search‘, ‚Start_Location‘) – Diese Funktion gibt die Startposition des angegebenen Werteausdrucks in einer Zeichenfolge zurück. Der Parameter Start_Location ist optional.
Beispiel: Lassen Sie uns verstehen, wir machen die Startposition von ‚@‘ Zeichen in der E-Mail-Zeichenfolge ’[email protected] ‚.
Wählen Sie CHARINDEX(‚@‘,’[email protected]‘,1)
Ausgang: 5
SUBSTRING() Funktion
SUBSTRING(expression‘, ‚Start‘, ‚Length‘) – Diese Funktion gibt Substring (Teil der Zeichenfolge) aus dem angegebenen Wertausdruck zurück. Wenn Sie außerdem die Startposition mit dem Parameter ’start‘ und die andere Anzahl von Zeichen in der Teilzeichenfolge mit dem Parameter ‚Length‘ angeben. Alle drei Parameter sind obligatorisch.
Beispiel: Ich möchte nur ‚Teil der angegebenen E-Mail ‚ [email protected] ‚.
TEILZEICHENFOLGE auswählen(‚[email protected]‘,6, 7)
Ausgang: bbb.com
Als Ergebnis haben wir die Codierung mit der Startposition und den Längenparametern vorgenommen. Anstatt die Parameter fest zu codieren, können wir sie dynamisch mit den Zeichenfolgenfunktionen CHARINDEX() und LEN() abrufen, wie unten gezeigt.
Beispiel:
Select SUBSTRING(‚[email protected] ‚,(CHARINDEX(‚@‘, ‚[email protected] ‚) + 1), (LEN(‚[email protected] ‚) – CHARINDEX(‚@‘,’[email protected]‘)))
Ausgang: bbb.com
Nehmen wir also ein reales Beispiel mit der Verwendung der Funktionen LEN() , CHARINDEX() und SUBSTRING() . Nehmen wir an, wir haben eine Tabelle wie unten gezeigt;
 Die Frage ist also, wie Sie die Gesamtzahl der E-Mails nach ihrer Domain ermitteln können.
Die Frage ist also, wie Sie die Gesamtzahl der E-Mails nach ihrer Domain ermitteln können.
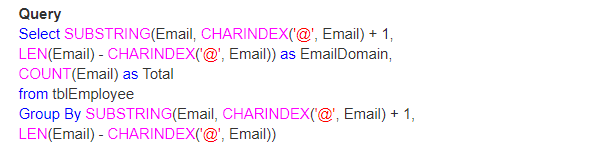
Ausgabe: Schließlich sieht die Ausgabe folgendermaßen aus;
 REPLICATE() Funktion
REPLICATE() Funktion
REPLICATE(String_To_Be_Replicated, Number_Of_Times_To_Replicate) – Diese Funktion wiederholt den angegebenen Punkt der Zeichenfolge und für die angegebene Anzahl von Malen.
Beispiel: SELECT REPLICATE(‚Pragim‘, 3)
Ausgabe: Pragim Pragim Pragim
Lassen Sie uns über ein praktisches Beispiel für die Verwendung der Funktion REPLICATE() sprechen: Wir werden diese Tabelle die meiste Zeit verwenden, und für den Rest unserer Beispiele in diesem Artikel.
Nehmen wir also an, wir haben eine Tabelle wie unten gezeigt;
 Abfrage: Wählen Sie Vorname, Nachname, TEILZEICHENFOLGE (E-Mail, 1, 2) + REPLIZIEREN(‚*‘,5) +
Abfrage: Wählen Sie Vorname, Nachname, TEILZEICHENFOLGE (E-Mail, 1, 2) + REPLIZIEREN(‚*‘,5) +
SUBSTRING(E–Mail, CHARINDEX(‚@‘,E-Mail), LEN(E-Mail) – CHARINDEX(‚@‘,E-Mail)+1) als E-Mail
von tblEmployee
Erstellen wir eine E-Mail mit 5 * (Stern) Symbolen. Dann wäre die Ausgabe wie folgt:
 SPACE() Funktion
SPACE() Funktion
SPACE(Number_Of_Spaces) – Diese Funktion gibt die einzige Anzahl von Leerzeichen zurück, die durch den Begriff Number_Of_Spaces angegeben wird Argument.
Beispiel: Die Funktion SPACE(5)fügt 5 Leerzeichen zwischen Vorname und Nachname ein
Select FirstName + SPACE(5) + LastName as FullName From tblEmployee
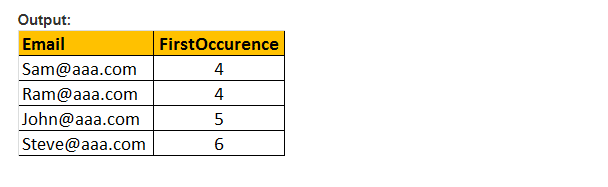
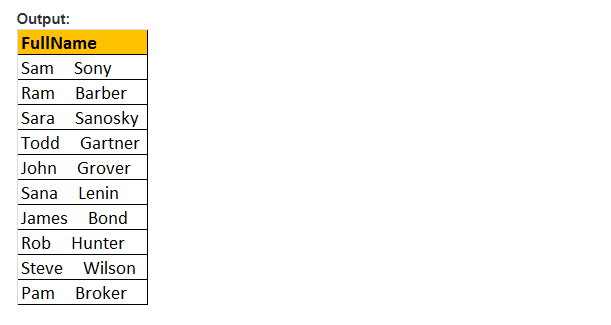 PATINDEX() -Funktion
PATINDEX() -Funktion
Diese Funktion gibt nur die Startposition des ersten Auftretens eines Musters in einem angegebenen effektiven Ausdruck zurück. Daher sind nur zwei Argumente und das zu durchsuchende Muster und der Ausdruck erforderlich. Daher ist PATINDEX() ähnlich wie CHARINDEX() . Mit CHARINDEX() können wir keine Platzhalter verwenden, während PATINDEX() diese Funktion beinhaltet. Wenn der angegebene Musterwert nicht gefunden wird, gibt PATINDEX() NULL zurück.
Beispiel: Wählen Sie E-Mail, PATINDEX(‚%aaa.com , Email‘) als FirstOccurence von tblEmployee wobei PATINDEX(‚%@aaa.com‘, E-Mail) > 0
 REPLACE() Funktion
REPLACE() Funktion
REPLACE(String_Expression, Pattern, Replacement_Value), Diese Funktion ersetzt alle Vorkommen Position eines angegebenen String-Wert mit einem anderen String-Wert.
Beispiel: Alle .COM-Zeichenfolgen werden durch .NET ersetzt
Select Email, REPLACE(Email, ‚.com‘, ‚.net‘) als ConvertedEmail from tblEmployee
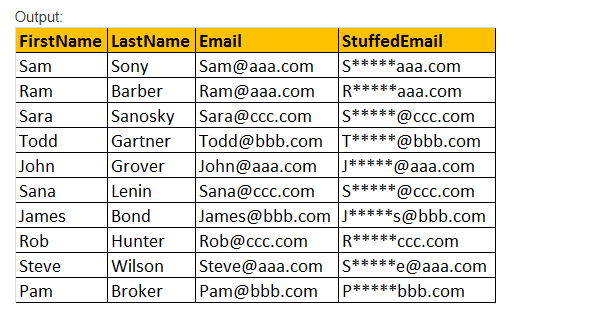
 STUFF() Function
STUFF() Function
STUFF(Original_Expression, Start, Length, Replacement_expression) fügt diese STUFF() Funktion nur Replacement_expression ein, das an der Startposition angegeben ist, und entfernt die Zeichen, die mit Length parameter value expression angegeben wurden.
Beispiel: Wählen Sie Vorname, Nachname, E-Mail, ZEUG (E-Mail,2,3,’*****‘) als StuffedEmail von tblEmployee.
 Datums-/ Uhrzeitfunktion
Datums-/ Uhrzeitfunktion
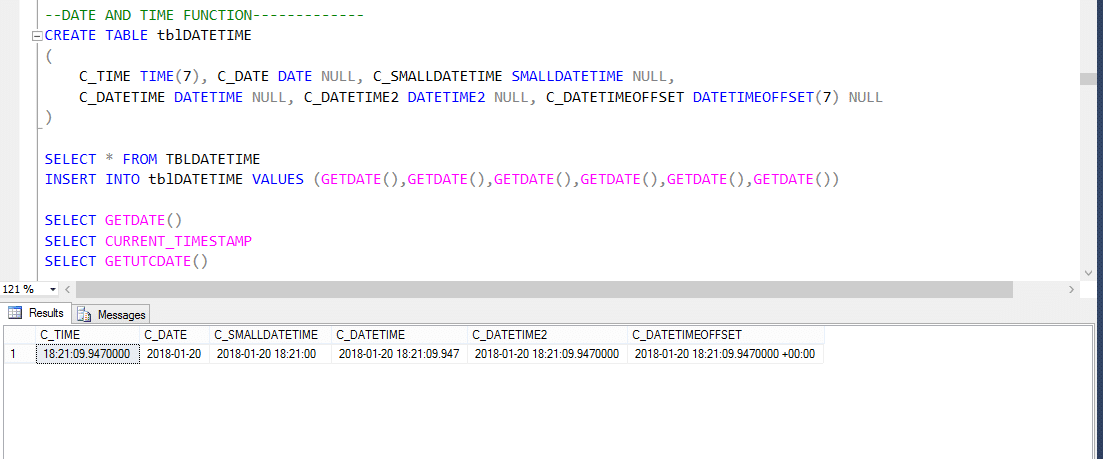
In der SQL Server-Datenbank sind mehrere integrierte DateTime-Funktionen verfügbar. Die meisten der folgenden Funktionen können verwendet werden, um das aktuelle Systemdatum und die aktuelle Systemzeit abzurufen, und wo Sie SQL Server installiert haben.
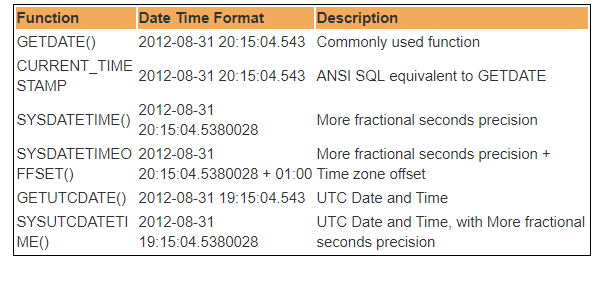 Daher steht UTC für Coordinated Universal Time, auf deren Grundlage die Welt Uhren und Zeitdaten regelt. Bemerkenswert. es gibt geringfügige Unterschiede zwischen GMT und UTC, aber für die häufigsten Zwecke ist UTC gleichbedeutend mit GMT.
Daher steht UTC für Coordinated Universal Time, auf deren Grundlage die Welt Uhren und Zeitdaten regelt. Bemerkenswert. es gibt geringfügige Unterschiede zwischen GMT und UTC, aber für die häufigsten Zwecke ist UTC gleichbedeutend mit GMT.
Nehmen wir also ein anderes Beispiel, wie unten gezeigt;
IsDate() Funktion
ISDATE() – Diese Funktion prüft, ob der einzige angegebene Wert, und existiert ein gültiges Datum, Uhrzeit oder DateTime. Dann gibt es 1 für Erfolg, 0 für Misserfolg zurück.
Beispiel:
Select ISDATE(‚PRAGIM‘) – es wird zurückgegeben 0
Beispiel:
Select ISDATE(Getdate()) – es wird zurückgegeben1
Beispiel:
Select ISDATE(‚2018-01-20 21:02:04.167‘) — es wird 1
Hinweis: Für datetime2-Werte gibt IsDate NULL zurück.
Beispiel:
Select ISDATE(‚2018-01-20 22:02:05.158.1918447‘) — es wird 0 zurückgegeben.
Day() Funktion
Day() – Diese Funktion gibt nur die ‚Tagesnummer des Monats‘ des angegebenen Datums zurück.
Beispiele:
Select DAY(GETDATE()) — Es wird die Ausgabe im Namen der Tagesnummer des Monats und basierend auf der aktuellen System-DateTime .
Select DAY(’01/14/2018′) – es wird zurückgegeben 14
Month() Funktion
Month() – Diese Funktion gibt die Ausgabe im Namen der ‚Monatsnummer des Jahres‘ des angegebenen Datums aus.
Beispiele:
Select Month(GETDATE()) — Diese Funktion gibt die Ausgabe im Namen der ‚Monatsnummer des Jahres‘ und basierend auf dem aktuellen Systemdatum und der aktuellen Systemzeit aus.
Select Month(’05/14/2018) — es wird zurückgegeben 5
Year() Funktion
Year() – Diese Funktion gibt die Ausgabe im Namen der ‚Year number‘ des angegebenen Datums
Beispiele:
Select Year(GETDATE()) — Gibt die Jahreszahl zurück und basiert auf dem aktuellen Systemdatum
Select Year(’01/20/2018) — es wird 2018
Dataame() Funktion
Dataame(DatePart, Date) – Diese Funktion gibt nur einen Zeichenfolgenausdruck zurück, der nur einen Teil des angegebenen Datums darstellt. Diese Funktionen bestehen aus 2 Parametern.
Der erste Parameter ‚DatePart‘ gibt den gewünschten Teil des Datums an. Der zweite Parameter ist das reale Datum, von dem wir den Teil des Datums wollen.
 Beispiel 1:
Beispiel 1:
Select DATA NAME(Tag, ‚2017-04-20 13:47:47.350‘) — es wird 20
Beispiel 2:
Select DATA(WOCHENTAG, ‚2017-04-20 13:47:47.350‘) — es wird Donnerstag
Beispiel 3:
Select DATA(MONTH, ‚2017-04-20 13:47:47.350‘) — es wird April
Also nehmen wir ein Beispiel mit einigen dieser DateTime-Funktionen. Betrachten Sie die Tabelle TBLMITARBEITER.
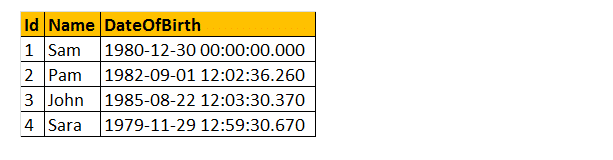 Beispiel: Ich möchte alle Namen, Geburtsdaten, Tage, Monatsnummern, Monatsnamen und Jahre wie unten gezeigt zurückgeben.
Beispiel: Ich möchte alle Namen, Geburtsdaten, Tage, Monatsnummern, Monatsnamen und Jahre wie unten gezeigt zurückgeben.
Wählen Sie Name, Geburtsdatum, Dateiname (WOCHENTAG, Geburtsdatum) als , Monat (Geburtsdatum) als MonthNumber, Dateiname (MONAT, Geburtsdatum) als , Jahr (Geburtsdatum) als Von tblEmployees

DatePart() -Funktion
DatePart(DatePart, Date) – Diese Funktion gibt eine Ganzzahl an, die den angegebenen DatePart-Wert darstellt. Diese Funktion ähnelt der Funktion Dataame() . Dataame() gibt nur den nvarchar-Wert zurück, während DatePart() nur einen ganzzahligen Wert zurückgibt. Die gültigen DatePart-Parameterwerte werden unten angezeigt.
Beispiele:
Select DATEPART(Wochentag, ‚2012-08-30 19:45:31.793‘) — es wird 5
Select DATAAME(Wochentag) zurückgegeben, ‚2012-08-30 19:45:31.793‘) — es gibt die Funktion
DateAdd()
DATEADD (datepart, NumberToAdd, date) – Diese SQL-Funktion gibt nur die DateTime nach dem angegebenen Begriff NumberToAdd und dem angegebenen Datepart des angegebenen Datums an.
Beispiele:
Datum auswählenadd(DAY, 10, ‚2018-01-20 19:45:31.793‘) — es wird zurückkommen ‚2018-01-30 19:45:31.793‘
Datum auswählenadd(DAY, -10, ‚2012-08-30 19:45:31.793‘)– es wird zurückkommen ‚2018-01-20 19:45:31.793‘
DatedDiff() Funktion
DATEDIFF(datepart, startdate, enddate) – Diese Funktion gibt die Anzahl der angegebenen Datepart-Grenzen an, die zwischen dem angegebenen startdate und enddate überschritten wurden.
Beispiele:
DATUM AUSWÄHLENDIFF(MONAT, ’11/30/2005′,’01/31/2006′) — es wird 2
Select DATEDIFF(DAY, ’11/30/2005′,’01/31/2006′) — es wird 62
Also, nehmen wir ein Beispiel, Nehmen wir an, wir haben eine Tabelle unten;
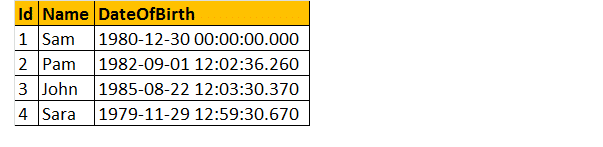
Schreiben Sie also eine Abfrage, um das Alter einer Person herauszufinden, wenn das Geburtsdatum angegeben ist.

Schließlich sieht die Ausgabe wie unten gezeigt aus.
Cast() – und Convert() -Funktionen
Um einen einzelnen Unit-Datentyp in einen anderen zu konvertieren, können CAST- und CONVERT-Funktionen verwendet werden.
Syntax der CAST- und CONVERT-Funktion:
CAST ( expression AS data_type )
CONVERT ( data_type , expression )
Wie Sie sehen können, hat die CONVERT() -Funktion einen optionalen Style-Parameterwert, während der CAST() -Funktion diese Fähigkeit fehlt.
Nehmen wir also ein Beispiel, wir nehmen eine Tabelle unten;
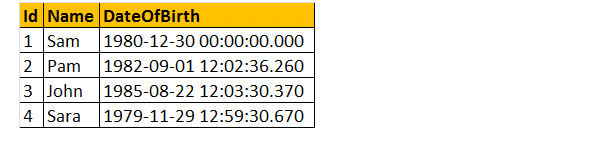 Die folgenden 2 Abfragen konvertieren den DateTime-Datentyp von DateOfBirth in NVARCHAR . Die erste Abfrage verwendet die Funktion CAST() und die zweite die Funktion CONVERT(). Schließlich ist die Ausgabe für beide Abfragen genau gleich, wie unten gezeigt.
Die folgenden 2 Abfragen konvertieren den DateTime-Datentyp von DateOfBirth in NVARCHAR . Die erste Abfrage verwendet die Funktion CAST() und die zweite die Funktion CONVERT(). Schließlich ist die Ausgabe für beide Abfragen genau gleich, wie unten gezeigt.
Wählen Sie ID, Name DateOfBirth, Cast(DateOfBirth als nvarchar) als ConvertedDOB von tblemployees .
Wählen Sie ID, Name DateOfBirth, Convert(DateOfBirth als nvarchar) als ConvertedDOB von tblemployees .
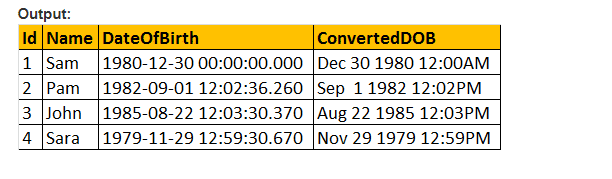 Also, lassen Sie uns den Style-Parameter des CONVERT() Funktionswert machen, und das Datum zu formatieren, wie wir es möchten. Wir verwenden also 103 als Argument für den Stilparameter in der folgenden Abfrage und formatieren das Datum als TT / MM / JJ.
Also, lassen Sie uns den Style-Parameter des CONVERT() Funktionswert machen, und das Datum zu formatieren, wie wir es möchten. Wir verwenden also 103 als Argument für den Stilparameter in der folgenden Abfrage und formatieren das Datum als TT / MM / JJ.
Wählen Sie ID, Name, DateOfBirth, Convert (nvarchar, DateOfBirth, 103) als ConvertedDOB von tblEmployees .
Schauen wir uns also ein praktisches Beispiel mit Hilfe der Funktion CAST() an.
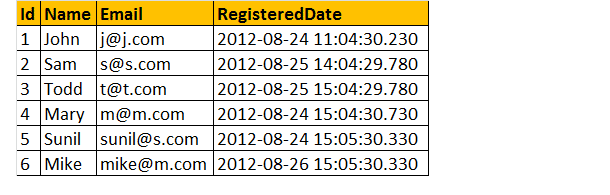
Nehmen wir an, wir haben unten eine Registrierungstabelle als;
 Lassen Sie uns nun die Gesamtzahl der Registrierungen pro Tag ermitteln.
Lassen Sie uns nun die Gesamtzahl der Registrierungen pro Tag ermitteln.
Beispiel: Select CAST(RegisteredDate as DATE) as RegistrationDate, COUNT(Id) as TotalRegistrations tblRegistrations Group By CAST(RegisteredDate as DATE)
Ausgabe: Schließlich sieht die Ausgabe wie folgt aus ;
Benutzerdefinierte Funktionen
Es gibt 3 Arten von benutzerdefinierten Funktionen in SQL Server, die als
- Skalarfunktionen
- Inline-Tabellenwertfunktionen
- Multistatement-Tabellenwertfunktionen
Skalarfunktionen
Skalarfunktionen variieren in Parametern, die möglicherweise Parameter haben oder nicht, und geben immer einen einzelnen (skalaren) Wert in der Ausgabe aus. Daher kann der zurückgegebene Wert ein beliebiges Datentypformat haben, mit Ausnahme von Textwert, Text, Bild, Cursor und Zeitstempel.
Beispiel: Lassen Sie uns also eine Funktion entwickeln, die das Alter einer Person in der Ausgabe berechnet und zurückgibt. Folglich, um das Alter zu vergleichen, für das wir benötigt haben, Geburtsdatum. Lassen Sie uns also das Geburtsdatum als Parameter übergeben. Daher gibt die Funktion AGE () eine Ganzzahl zurück und akzeptiert den Datumsparameter.
 Wählen Sie dbo.Alter( dbo.Alter(’10/08/1982′).
Wählen Sie dbo.Alter( dbo.Alter(’10/08/1982′).
Nehmen wir also ein praktisches Beispiel in der folgenden Tabelle;
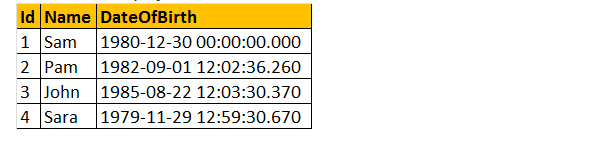
Skalare benutzerdefinierte Funktionen können in der Select-Klausel wie unten gezeigt verwendet werden.
Wählen Sie Name, Geburtsdatum, dbo.Age(DateOfBirth) als Age von tblEmployees
 Um den Text der Funktion anzuzeigen, verwenden Sie sp_helptext functionName .
Um den Text der Funktion anzuzeigen, verwenden Sie sp_helptext functionName .
Inline-Funktionen mit Tabellenwerten
Eine Inline-Funktion mit Tabellenwerten gibt immer eine Tabelle als Ausgabe zurück.
Nehmen wir also ein Beispiel unten; Erstellen Sie eine Funktion, die MITARBEITER nach GESCHLECHT zurückgibt.
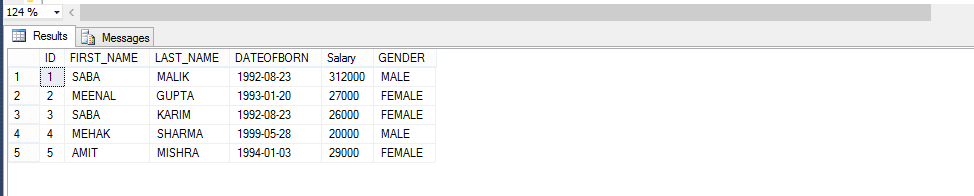
aufgrund der Aufrufmethode für die benutzerdefinierte Funktion
Select * From Fn_EMPLOYEEbyGender(‚male‘)
MULTI-STATEMENT TABLE VALUED FUNCTION
Multi-statement table-valued functions sind Inline Table-valued functions und mit einigen Unterschieden viel ähnlicher. Schauen wir uns also ein Beispiel an und notieren Sie dann die Unterschiede.
Mitarbeiter-Tabelle
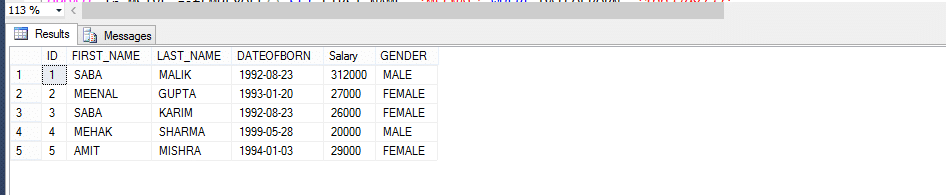
Tabellenwertfunktion mit mehreren Anweisungen (MSTVF):
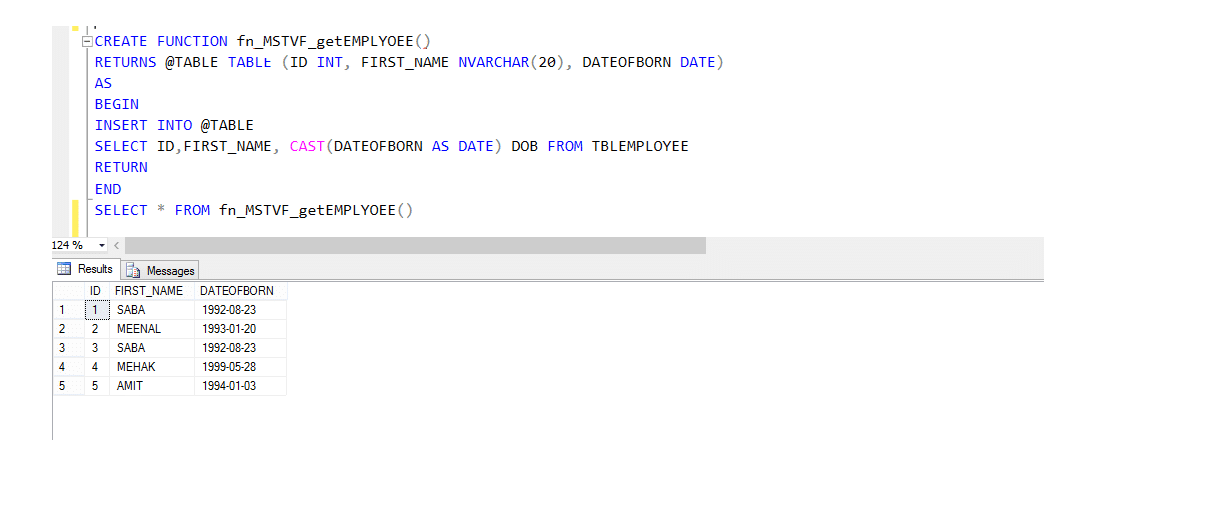 Aufgrund der aufrufenden Methode für vthe Multi-statement Table Valued Function:
Aufgrund der aufrufenden Methode für vthe Multi-statement Table Valued Function:
Select * from fn_MSTVF_GetEmployees()
Conclusion
Die JOINs sind ein sehr verständnisvoller Begriff für Anfänger während der Lernphase von SQL-Befehlen. Folglich stellt der Interviewer im Interview mindestens eine Frage zu den SQL-Joins und -Funktionen. In diesem Beitrag versuche ich, die Dinge für neue SQL-Lernende zu vereinfachen und das Verständnis der SQL-Joins zu erleichtern. Darüber hinaus haben die Funktionen in SQL, Viele Leute Probleme, die tatsächliche Arbeitsfunktion zu verstehen. Weil SQL viele Daten in großen Mengen in verschiedenen Datenbank- und Tabellennamen enthält. Eine Funktion ist ein gespeichertes Programm in der SQL Server-Datenbank, in das Sie Parameter übergeben und einen Wert zurückgeben können. Also habe ich einen nützlicheren Begriff über das Arbeiten von Funktionen gegeben.
- Über
- Neueste Beiträge

- Unterschied zwischen SQL und MySQL – April 14, 2020
- So arbeiten Sie mit Unterabfragen im Data Mining – März 23, 2018
- Wie verwende ich Browserfunktionen von Javascript? – März 9, 2018
