Salte para Secção
- SQL Introdução
- como trabalhar com junções SQL
- junção interna
- LEFT Join
- Direito de Associação
- Full Outer join
- CROSS join
- Como trabalhar com o Avanço do SQL Joins
- LEFT Join
- junção exterior completa
- Tipos de Chaves no SQL
- Candidatos a Tecla
- Chave Primária
- chave única
- chave alternativa
- chave composta
- Super Key
- chave estrangeira
- como trabalhar com funções SQL
- função esquerda ()
- RIGHT ()
- CHARINDEX() função
- SUBSTRING() função
- REPLICATE() Função
- SPACE() função
- PATINDEX Função ()
- REPLACE () função
- COISAS Função ()
- função de data e hora
- IsDate () Function
- mês() função
- Ano() de Função
- DateName() Função
- Função DatePart ()
- Função DateAdd ()
- DatedDiff Função ()
- funções Cast() e Convert ()
- Funções Definidas pelo Utilizador
- Funções Escalares
- funções com valor de tabela em linha
- MULTI-DECLARAÇÃO de FUNÇÃO com valor de TABELA
- Conclusion
SQL Introdução
SQL significa Linguagem de Consulta Estruturada. É usado principalmente para manipulação de dados, modificação de dados e recuperação de dados. Isso ocorre com o sistema de gerenciamento de banco de dados relacional (RDBMS).
aprenderemos sobre recursos mais avançados do SQL, como junções e funções.
como trabalhar com junções SQL
um meio de junção simples é combinar duas ou mais tabelas em um determinado banco de dados. Uma junção funciona em uma entidade comum de duas tabelas.
uma junção contém 5 sub-junções que como; junção interna, junção externa, junção esquerda, junção direita e junção cruzada.
junção interna
uma junção interna é usada para selecionar registros que contenham valores comuns ou correspondentes em ambas as tabelas (tabela a e Tabela B). A não correspondência é eliminada.
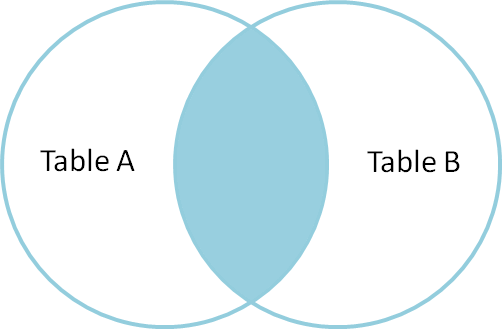
então, vamos entender o tipo de junção, e com exemplos comuns e as diferenças entre eles.
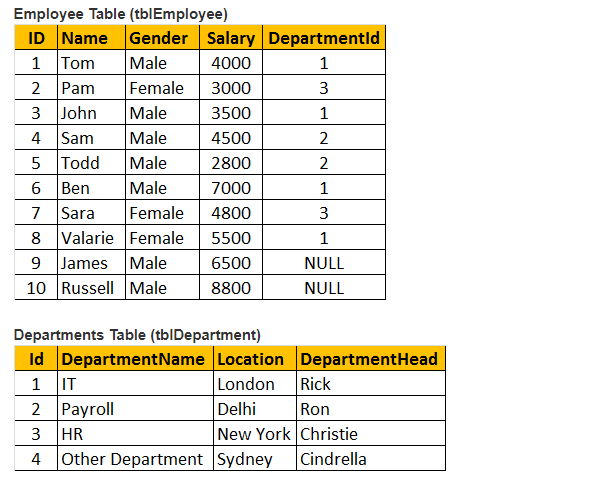
Tabela 1: Tabela de Empregados (tblEmployee)
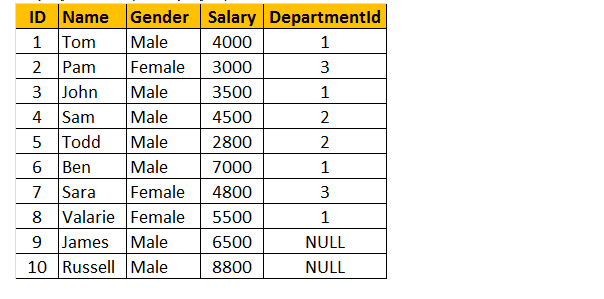
Tabela 2: Tabela de Departamentos (tblDepartments)
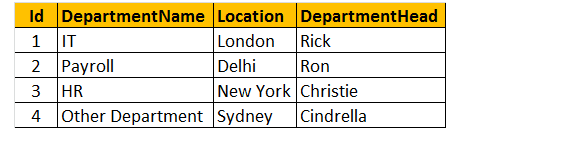
Então, vamos criar a tabela tblDepartments para a execução de um programa.

agora, insira registros na tabela tblDepartments.

vamos criar outra tabela paraempregado para a execução de um programa.

então, insira registros na tabela tblEmployee.

portanto, uma fórmula geral para junções.

para fazer uma consulta para encontrar Nome, gênero, salário e DepartmentName das tabelas tblEmployee e tblDepartments.

Nota: junção ou junção interna significa o mesmo. Mas sempre melhor usar INNER JOIN, e isso especifica sua intenção explicitamente.
> Saída: Agora o resultado final da tabela será parecido com este;
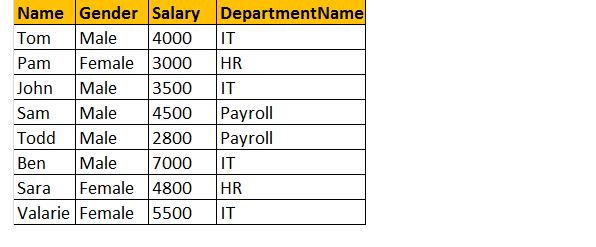
Se você olhar para a janela de saída, temos apenas 8 linhas, mas na tabela tblEmployee, temos 10 linhas. Não recebemos a James e a RUSSELL records. Isso ocorre porque o DEPARTMENTID, na tabela tblEmployee é nulo para esses dois funcionários e não corresponde à coluna ID na tabela tblDepartments.
portanto, em uma instrução final, as junções internas retornam apenas as linhas correspondentes das tabelas e das linhas não correspondentes são eliminadas devido à sua subconsulta.
LEFT Join
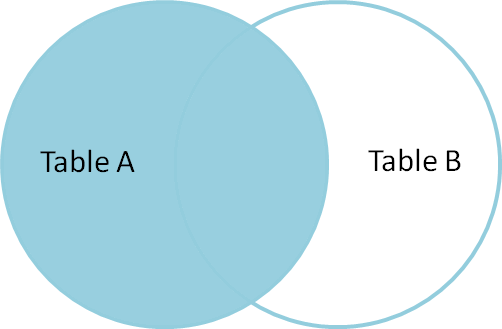
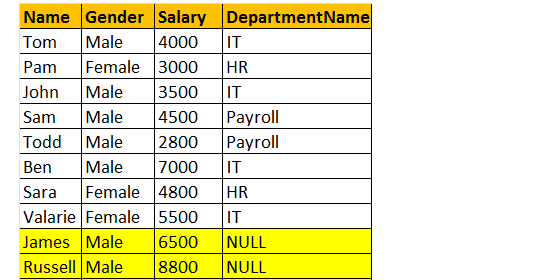
LEFT Join retorna todas as linhas correspondentes e linhas não correspondentes da tabela do lado esquerdo. Além disso, a junção interna e a junção esquerda são amplamente utilizadas.
então, vamos dar um exemplo, quero todas as linhas da tabela tblEmployee, incluindo registros JAMES e RUSSELL. Em seguida, a saída será semelhante como;

Direito de Associação
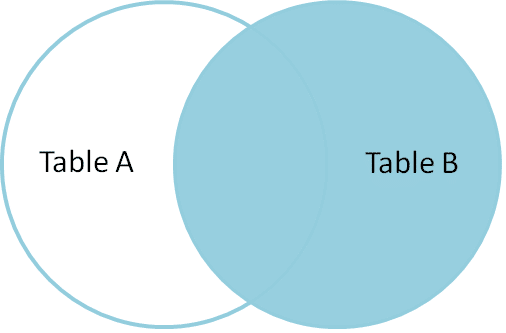
RIGHT Join retorna todas as linhas correspondentes e não correspondentes linhas do lado direito da tabela.
então, vamos dar um exemplo; quero todas as linhas das tabelas corretas envolvidas na junção. Como resultado seria como;

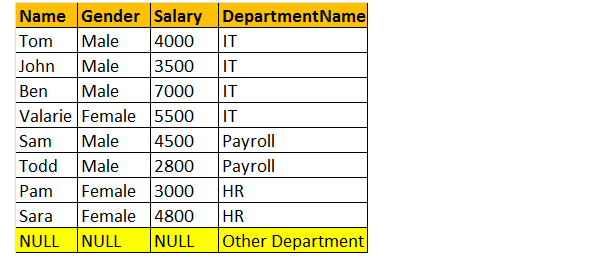
Full Outer join

OUTER join ou FULL OUTER Join retorna todas as linhas de ambas as tabelas de esquerda e direita, e incluindo a não-correspondência de linhas de tabelas.
então, vamos dar um exemplo; quero todas as linhas de ambas as tabelas envolvidas na junção.

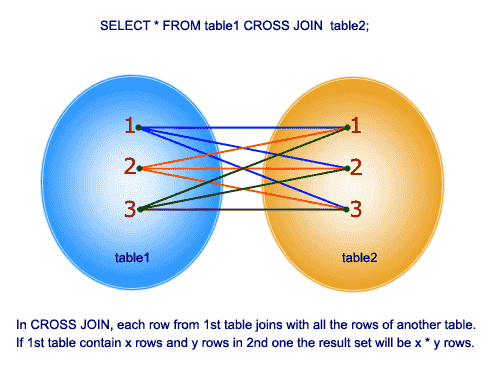
CROSS join
esta junção fornece o produto cartesiano das 2 tabelas na função join. Esta junção não contém a cláusula ON.
então, vamos entender um exemplo: Na tabela tblEmployee temos 10 linhas e na tabela tblDepartments temos 4 linhas. Portanto, uma junção cruzada entre essas 2 tabelas produz 40 linhas.

Como trabalhar com o Avanço do SQL Joins
nesta sessão, vou explicar estas coisas como se segue;
- Avançado ou inteligente ingressa no SQL Server.
- Recupere dados apenas as linhas não correspondentes da tabela à esquerda.
- buscar dados apenas as linhas não correspondentes da tabela à direita.
- Recupere dados apenas as linhas não correspondentes das tabelas esquerda e direita.
então, vamos considerar as tabelas tblEmployee e tblDepartment.
LEFT Join
então, vamos entender um exemplo, quero recuperar apenas as linhas não correspondentes da tabela do lado esquerdo.

Saída: Finalmente, a saída será semelhante a este;

Direito de Associação
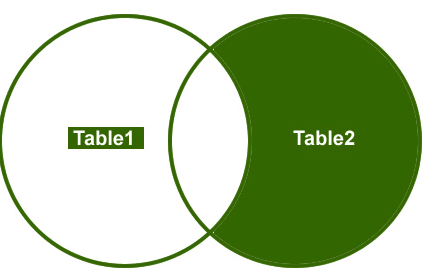
Então, vamos entender um exemplo, eu quero recuperar somente a não-correspondência de linhas a partir do lado direito da tabela.

saída: finalmente, a saída ficará assim;

junção exterior completa
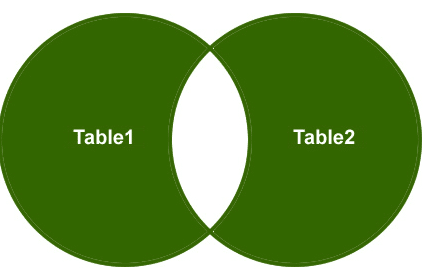
então, vamos entender um exemplo, quero recuperar apenas as linhas não correspondentes da tabela do lado direito e da tabela do lado esquerdo e as linhas correspondentes devem ser eliminadas.

Saída: Finalmente, a saída será semelhante a este;
Tipos de Chaves no SQL
UMA Chave no SQL é um campo de dados que identifica exclusivamente um registro. Em outra palavra, uma chave é um conjunto de colunas que é usado para identificar exclusivamente o registro em uma tabela.
- criar relações entre duas tabelas.
- manter exclusividade e responsabilidade em uma tabela.
- Mantenha dados consistentes e válidos em um banco de dados.
- pode ajudar na recuperação rápida de dados, facilitando índices na(S) coluna (S).
UM SQL server contém chaves seguinte;
- Candidato a Tecla
- Chave Primária
- Chave Única
- Chave Alternativa
- Chave Composta
- Super Tecla
- Chave Estrangeira
Antes de ir adiante, e por favor, dê uma olhada na imagem abaixo;
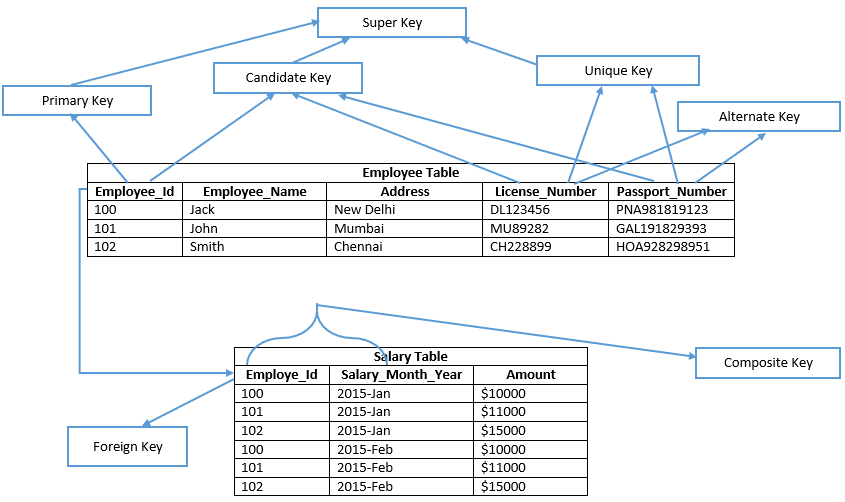
Vamos entender cada chave em detalhes
Candidatos a Tecla
Um candidato é uma chave em uma tabela que pode ser selecionada como uma chave primária da tabela e uma tabela pode ter várias chaves de candidatos, portanto, pode ser selecionado como uma chave primária.
Exemplo: Employee_Id, License_Number, & Passport_Number mostra candidato teclas
Chave Primária
Uma chave primária é semelhante ao candidato selecionado chave da tabela para verificar cada registro de dados exclusivamente na tabela. Portanto, a chave primária não contém nenhum valor nulo em nenhuma das colunas de uma tabela e também mantém valores exclusivos na coluna. No exemplo dado, Employee_Id define a chave primária da tabela de Funcionários. Consequentemente, no SQL Server Management Studio, A chave primária cria um índice em cluster em uma tabela heap por padrão e uma tabela que não consiste em um índice em cluster é conhecida como tabela heap. Se define uma chave primária não agrupada em uma tabela por tipo de índice explicitamente.
Além disso, uma tabela só pode ter uma chave primária e de chave primária pode ser definida no SQL Server usando instruções SQL:
- CRETA instrução de TABELA (no momento da criação da tabela) – como resultado, o sistema define o nome da chave primária.
- ALTER TABLE statement (usando uma restrição de chave primária) – como resultado, o próprio USUÁRIO declara o nome da restrição de chave primária.
exemplo: Employee_Id é uma chave primária da tabela de Funcionários.
chave única
uma chave única é tanto quanto a chave primária e que não contém valores duplicados na coluna. Tem abaixo diferenças na comparação da chave primária:
- ele permite um valor nulo na coluna.
- por padrão, ele cria um índice não agrupado e tabelas de heap.
chave alternativa
a chave alternativa é semelhante à chave candidata, mas não selecionada como chave primária da tabela.
Exemplo: License_Number e Passport_Number são chaves alternativas.
chave composta
chave composta (também conhecida como chave composta ou chave concatenada) é um grupo de duas ou mais colunas que identifica cada linha de uma tabela exclusivamente. Além disso, uma única coluna de unidade de uma chave composta pode não ser capaz de verificar exclusivamente os registros de dados. Como resultado, também pode ser chave primária ou chave candidata.
exemplo: na tabela, Employee_Id & Salary_Month_Year ambas as colunas verificam cada linha exclusivamente na Tabela Salarial. Portanto, Employee_Id ou Salary_Month_Year coluna na tabela, que não pode identificar cada linha exclusivamente. Podemos criar uma única chave primária composta na tabela de salários usando nomes de colunas Employee_Id e Salary_Month_Year.
Super Key
Super key é um conjunto de colunas nas quais todas as colunas da tabela são funcionalmente dependentes. Devido ao conjunto de colunas que identifica exclusivamente cada linha em uma tabela. Em outra palavra, essa chave contém algumas colunas adicionais que não são estritamente necessárias para verificar exclusivamente cada linha na tabela. Parece que a chave primária e as chaves candidatas são superkeys mínimas ou você pode dizer um subconjunto de superkeys.
então, vejamos o exemplo acima, na tabela Employee, o nome da coluna Employee_Id dificilmente é suficiente para verificar exclusivamente qualquer linha da tabela. Portanto, qualquer conjunto de uma coluna da tabela Employee que contém Employee_Id é uma superkey para a tabela Employee.Por exemplo: {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id, Employe_name, Address} etc.
License_Number e Passport_Number são o nome das colunas, ele também pode verificar exclusivamente qualquer linha da tabela. Qualquer pessoa do conjunto de nomes de coluna que consiste em License_Number ou Passport_Number ou Employee_Id é uma superchave da tabela.
Por exemplo: {License_Number, Employee_Name, Endereço}, {License_Number, Employee_Name, Passport_Number}, {Passport_Number, Employee_Name, Endereço, License_Number}, {Passport_Number, Employee_Name}, {Passport_Number, Employee_Id} etc.
chave estrangeira
um FK define a relação entre duas ou mais de duas tabelas por vez. Uma chave primária de uma única tabela é referida a uma chave estrangeira em outra tabela. Uma chave estrangeira pode ter valores duplicados em uma tabela e também pode ter valores nulos se o nome da coluna estiver definido para aceitar valores nulos ainda.
por exemplo, o nome da coluna “Employee_Id” (que é uma chave primária da tabela de funcionários ) é uma chave estrangeira na tabela de salários.
Nota: chaves como chave primária e chave única criam índices com colunas de chaves. Dados organizados no nó de estrutura de árvore B (árvore balanceada: nós de folha estão todos no nível diferente do lado raiz) no SQL Server. Portanto, o índice não agrupado cria uma estrutura separada da tabela de dados base, mas o índice agrupado converte a tabela de dados base da estrutura de heap em uma estrutura de árvore B.
além disso, o índice agrupado não cria uma estrutura separada além da tabela de base e essa é a razão pela qual podemos criar apenas um índice agrupado em uma tabela. Portanto, podemos classificar uma tabela de apenas uma maneira (pode ter várias colunas para classificar, mas a classificação pode ser feita de uma única maneira), que é a ordem do índice agrupado.
como trabalhar com funções SQL
uma função é um programa de entidade que é armazenado no banco de dados do SQL Server ou você pode passar parâmetros ou retornar um valor. Além disso, aguardaremos algumas funções internas muito úteis e funções definidas pelo Usuário.
função Coalesce
Coalesce (): esta função retorna apenas com o primeiro valor não nulo. Então, vamos dar um exemplo sobre a função Coalesce ().
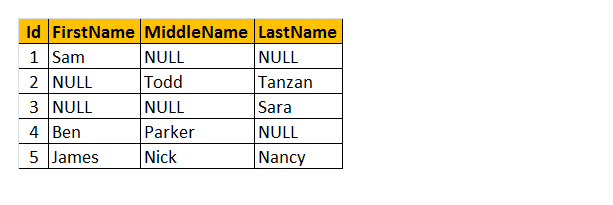 vamos entender a tabela como o nome ‘funcionário’ acima. Como resultado, você pode ver que alguns dos funcionários têm seu primeiro nome faltando, alguns têm um nome do meio e alguns deles têm sobrenome faltando. Então, quero devolver apenas o” nome ” do funcionário.
vamos entender a tabela como o nome ‘funcionário’ acima. Como resultado, você pode ver que alguns dos funcionários têm seu primeiro nome faltando, alguns têm um nome do meio e alguns deles têm sobrenome faltando. Então, quero devolver apenas o” nome ” do funcionário.
como vai funcionar? Entenda, estamos processando colunas FirstName, MiddleName e LastName como parâmetros para a função COALESCE (). Portanto, esta função retornará o único primeiro valor não nulo de 3 das colunas.
consulta: selecione Id, COALESCE(FirstName, MiddleName, LastName) como nome de tblEmployee
finalmente, a saída será assim;
 função esquerda ()
função esquerda ()
esquerda (Character_Expression, Integer_Expression)-esta função retorna o número especificado de caracteres do lado esquerdo da expressão de valor de caractere dada.
Exemplo: Selecione a ESQUERDA(‘ABCDE’, 3)
Saída: ABC
RIGHT ()
DIREITO(Character_Expression, Integer_Expression) – Esta função retorna o número especificado de caracteres a partir do lado direito do dado valor do caractere de expressão.
exemplo: Selecione à direita (‘ABCDE’, 3)
saída: CDE
CHARINDEX() função
CHARINDEX (‘Expression_To_Find’,’ Expression_To_Search’,’ Start_Location’) – esta função retorna a posição inicial da expressão de valor especificada em uma sub string de caractere. O parâmetro Start_Location é opcional.
exemplo: vamos entender, fazemos a posição inicial do caractere ‘ @ ‘ na string de E-mail ‘[email protected]’.
selecione CHARINDEX ( ‘ @ ‘ ,’[email protected]’,1)
saída: 5
SUBSTRING() função
SUBSTRING(expressão’, ‘Start’, ‘Length’) – esta função retorna substring (subparte da string), a partir da expressão de valor dada. Além disso, quando você especifica a posição inicial usando o parâmetro ‘Iniciar’ e o outro número de caracteres na substring usando o parâmetro ‘Length’. Todos os três parâmetros são obrigatórios.
exemplo: eu quero exibir apenas parte do domínio do E-mail fornecido ‘[email protected]’.
selecionar SUBSTRING (‘[email protected]’,6, 7)
saída: bbb.com
como resultado, fizemos a codificação com a posição inicial e os parâmetros de comprimento. Em vez de codificar os parâmetros, podemos buscá-los dinamicamente usando funções de string CHARINDEX() e LEN (), conforme mostrado abaixo.
Exemplo:
Select SUBSTRING(‘[email protected]’,(CHARINDEX(‘@’, ‘[email protected]’) + 1), (LEN(‘[email protected]’) – CHARINDEX(‘@’,’[email protected]’)))
Saída: bbb.com
Então, vamos dar um exemplo real com o uso de LEN(), CHARINDEX() e SUBSTRING() funções. Vamos pensar que temos uma tabela como mostrado abaixo;
 portanto, a questão é como você encontrará o número total de E-mails por seu domínio.
portanto, a questão é como você encontrará o número total de E-mails por seu domínio.
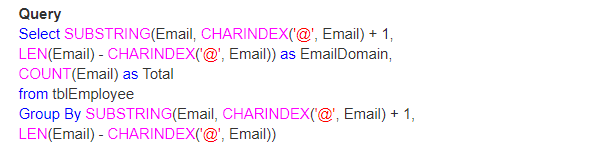
Saída: Finalmente, a saída será semelhante a este;
 REPLICATE() Função
REPLICATE() Função
REPLICAR(String_To_Be_Replicated, Number_Of_Times_To_Replicate) – Esta função repete um determinado ponto da cadeia, e para o número especificado de vezes.
Exemplo: SELECIONE DUPLICAR(‘Pragim’, 3)
Saída: Pragim Pragim Pragim
Vamos falar de um exemplo prático do uso de REPLICAR() função: Nós estaremos usando esta tabela na maioria das vezes, e para o resto de nossos exemplos neste artigo.
Então, vamos supor que temos uma tabela, como mostrado abaixo;
 Consulta: Select Nome, Sobrenome, SUBSTRING(e-Mail, 1, 2) + REPLICAR(‘*’,5) +
Consulta: Select Nome, Sobrenome, SUBSTRING(e-Mail, 1, 2) + REPLICAR(‘*’,5) +
SUBSTRING(e-Mail, CHARINDEX(‘@’,e-Mail), LEN(e-Mail) – CHARINDEX(‘@’,e-Mail)+1) como o e-Mail
a partir de tblEmployee
Vamos fazer e-mail com 5 * (estrela) símbolos. Então, a saída seria assim
 SPACE() função
SPACE() função
SPACE(Number_Of_Spaces) – esta função retorna o único número de espaços e especificado pelo termo argumento Number_Of_Spaces.
Exemplo: O ESPAÇO(5), Ele irá insere 5 espaços entre o Nome e Sobrenome
Select FirstName + ESPAÇO(5) + Sobrenome como FullName De tblEmployee
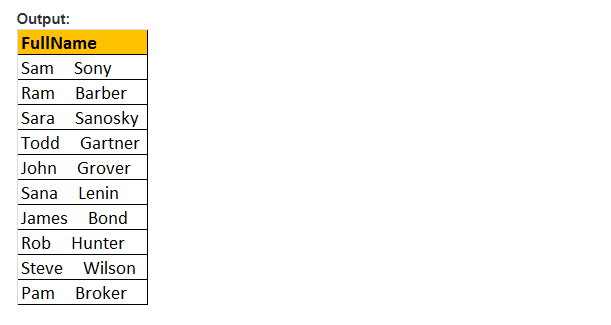 PATINDEX Função ()
PATINDEX Função ()
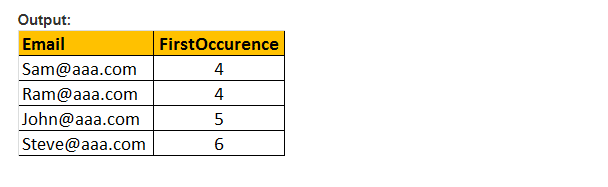
Esta função retorna apenas o local de partida da primeira ocorrência de um padrão em uma determinada expressão efectiva. Portanto, são necessários apenas dois argumentos, e o padrão a ser pesquisado e a expressão. Portanto, PATINDEX () é semelhante a CHARINDEX (). Com CHARINDEX() não podemos usar curingas, enquanto PATINDEX () envolve esse recurso. Se o valor padrão especificado não for encontrado, PATINDEX() retorna ZERO.
exemplo: selecione Email, PATINDEX (‘%aaa.com, Email’) como FirstOccurence de tblEmployee onde PATINDEX (‘%@aaa.com’, e-mail) > 0
 REPLACE () função
REPLACE () função
REPLACE (String_Expression, Pattern, Replacement_Value), esta função substitui todas as ocorrências posição de um valor de string especificado com outro valor de string.
exemplo: todas as strings .COM são substituídas por.Net
selecione Email, REPLACE(Email,’. com’,’.net’) como ConvertedEmail de tblEmployee
 COISAS Função ()
COISAS Função ()
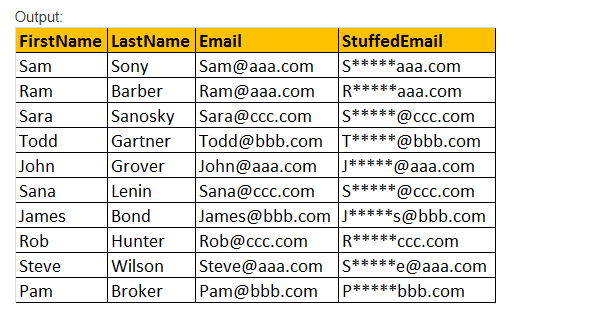
COISAS(Original_Expression, de Início, Duração, Replacement_expression), Este MATERIAL() função apenas insere Replacement_expression, que é especificado na posição inicial, juntamente com a remoção de caracteres especificado usando o parâmetro de Comprimento de expressão de valor.
exemplo: selecione FirstName, lastName, Email, STUFF(Email,2,3,’*****’) como StuffedEmail do tblEmployee.
 função de data e hora
função de data e hora
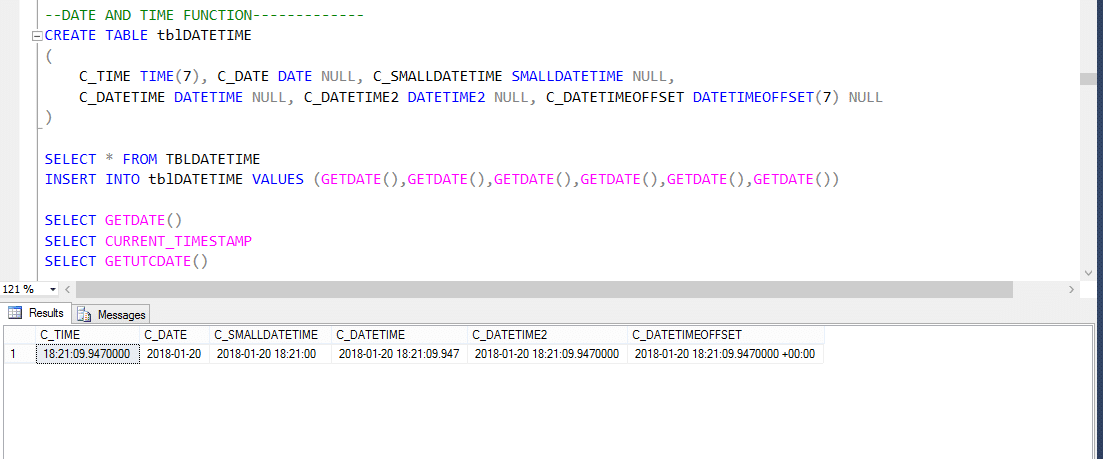
existem várias funções de data e hora integradas disponíveis no banco de dados do SQL Server. A maioria das funções a seguir pode ser usada para obter a data e hora atuais do sistema e onde você tem o SQL server instalado.
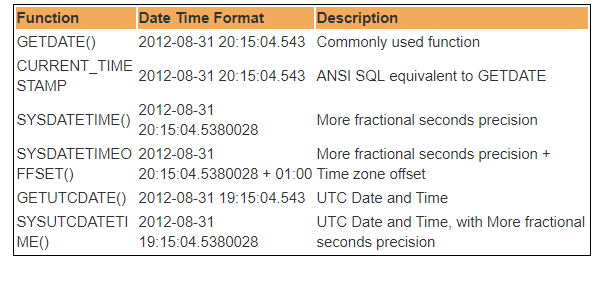 portanto, UTC significa Tempo Universal Coordenado, com base no qual, o mundo regula Relógios e dados de tempo. Notavel. existem pequenas diferenças entre GMT e UTC,mas para fins mais comuns, UTC é sinônimo de GMT.
portanto, UTC significa Tempo Universal Coordenado, com base no qual, o mundo regula Relógios e dados de tempo. Notavel. existem pequenas diferenças entre GMT e UTC,mas para fins mais comuns, UTC é sinônimo de GMT.
então, vamos dar outro exemplo como mostrado abaixo;
IsDate () Function
ISDATE–) – esta função verifica se o único valor dado e existe uma data, hora ou data e hora válidas. Então, ele retornará 1 para o sucesso, 0 para o fracasso.
Exemplo:
Selecione ISDATE(‘PRAGIM’) — ele retorna 0
Exemplo:
Selecione ISDATE(Getdate()) — ele vai returns1
Exemplo:
Selecione ISDATE(‘2018-01-20 21:02:04.167’) — ele retorna 1
Nota: Para datetime2 valores, IsDate retorna ZERO.
Exemplo:
Selecione ISDATE(‘2018-01-20 22:02:05.158.1918447’) — ele retorna 0.
Day() função
Day() – esta função retorna apenas o ‘número do dia do mês’ da data fornecida.
exemplos:
selecione o dia (GETDATE ()) – ele fornecerá a saída em nome do número do dia do mês e com base na data e hora do sistema atual.
selecione o dia(’01/14/2018′) — ele retornará 14
mês() função
mês () – esta função fornecerá a saída em nome do ‘número do mês do ano’ da data fornecida.
exemplos:
selecione o mês(GETDATE ()) – esta função fornecerá a saída em nome do ‘número do mês do ano’ e com base na data e hora atuais do sistema.
Seleccione o Mês(’05/14/2018) — ele retorna 5
Ano() de Função
Ano() – Essa função será dar a saída, em nome do “Ano número’ de determinada data
Exemplos:
Select Year(GETDATE()) — Retorna o número de ano, e baseado na data atual do sistema
Select Year(’01/20/2018) — que retorna de 2018
DateName() Função
DateName(DatePart, Data) – Esta função retorna apenas uma expressão de seqüência de caracteres, e que representa apenas uma parte de uma determinada data. Essas funções consistem em 2 parâmetros.
o primeiro parâmetro ‘DatePart’ especifica, a parte da data, que queremos. O segundo parâmetro é a data real, a partir da qual queremos a parte da data.
 Exemplo 1:
Exemplo 1:
Select DATENAME(Dia, ‘2017-04-20 13:47:47.350’) — ele retorna 20
Exemplo 2:
Select DATENAME(dia da SEMANA, ‘2017-04-20 13:47:47.350’) — ele irá retornar quinta-feira
Exemplo 3:
Select DATENAME(MÊS, ‘2017-04-20 13:47:47.350’) — ele retorna abril
Então, vamos dar um exemplo usando alguns desses DateTime funções. Considere a tabela tblEmployees.
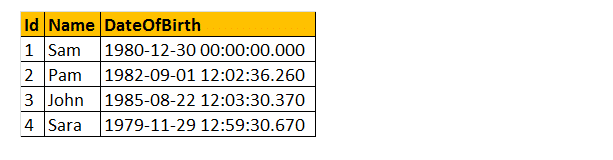 exemplo: quero retornar todos os nomes, DateOfBirth, Day, MonthNumber, MonthName e Year, conforme mostrado abaixo.
exemplo: quero retornar todos os nomes, DateOfBirth, Day, MonthNumber, MonthName e Year, conforme mostrado abaixo.
Select Nome, data de nascimento, DateName(dia da SEMANA,data de nascimento) como , Mês(data de nascimento) como MonthNumber, DateName(MÊS, data de nascimento) como , por Ano(data de nascimento) como De tblEmployees

Função DatePart ()
DatePart(DatePart, Data) – Esta função retorna um inteiro que representa o especificado DatePart valor. Principalmente a função é semelhante à função DateName (). DateName () retorna apenas o valor nvarchar, enquanto DatePart () retorna apenas um valor inteiro. Os valores válidos do parâmetro DatePart são mostrados abaixo.
Exemplos:
Select DATEPART(dia da semana, ‘2012-08-30 19:45:31.793’) — ele retorna 5
Select DATENAME(dia da semana, ‘2012-08-30 19:45:31.793’) — ele retorna quinta-feira
Função DateAdd ()
DATEADD (datepart, NumberToAdd, data) – Esta função SQL fornece apenas o DateTime, após determinado prazo NumberToAdd, e para o datepart especificado de determinada data.
exemplos:
Select DateAdd(DAY, 10, ‘2018-01-20 19:45:31.793’) — ele retorna ‘2018-01-30 19:45:31.793’
Select DateAdd(DAY, -10, ‘2012-08-30 19:45:31.793’)– ele retorna ‘2018-01-20 19:45:31.793’
DatedDiff Função ()
DATEDIFF(datepart, startdate enddate) – Esta função dá-se a contagem do datepart especificado limites cruzados entre o especificado startdate e enddate.
exemplos:
Select DATEDIFF(MÊS, ’11/30/2005′,’01/31/2006′) — ele retorna 2
Select DATEDIFF(DAY, ’11/30/2005′,’01/31/2006′) — ele retorna 62
Então, vamos dar um exemplo, Vamos supor que temos uma tabela dada abaixo;
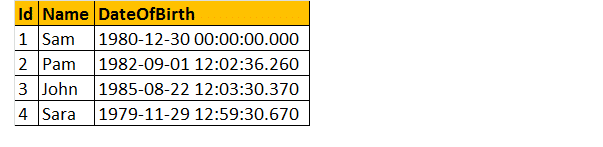
Assim, Escrever uma consulta para descobrir a idade de uma pessoa, quando a data de nascimento é dado.

Finalmente, a saída ficará como mostrado abaixo.
funções Cast() e Convert ()
para converter um único tipo de dados de unidade para outro, as funções CAST e CONVERT podem ser usadas.
sintaxe da função CAST e CONVERT:
CAST(expressão como data_type )
CONVERT ( data_type , expression)
além disso, como você pode ver, a função CONVERT () tem um valor de parâmetro de estilo opcional, enquanto a função CAST () não possui esse recurso.
então, vamos dar um exemplo, tomamos uma tabela abaixo;
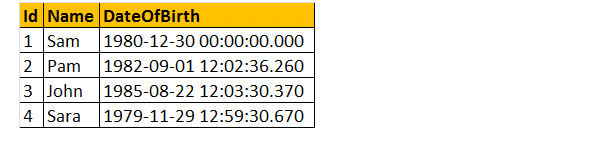 as 2 consultas a seguir convertem Dateofbirth’s DateTime datatype para NVARCHAR. A primeira consulta usa a função CAST() e a segunda usa a função CONVERT (). Finalmente, a saída é exatamente a mesma para ambas as consultas, conforme mostrado abaixo.
as 2 consultas a seguir convertem Dateofbirth’s DateTime datatype para NVARCHAR. A primeira consulta usa a função CAST() e a segunda usa a função CONVERT (). Finalmente, a saída é exatamente a mesma para ambas as consultas, conforme mostrado abaixo.
Select ID, Name DateOfBirth, Cast(DateOfBirth as nvarchar) as ConvertedDOB from tblemployees.
selecione ID, Nome DateOfBirth, Convert(DateOfBirth como nvarchar) como ConvertedDOB de tblemployees.
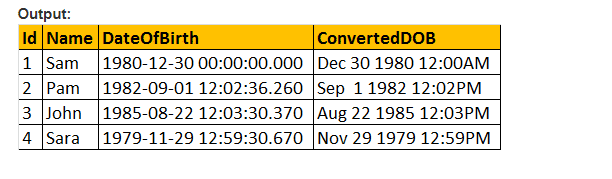 então, vamos fazer o parâmetro de estilo do valor da função CONVERT () e formatar a data como gostaríamos. Portanto, estamos usando 103 como passar o argumento para o parâmetro style na consulta abaixo fornecida e que formata a data como dd/mm/yy.
então, vamos fazer o parâmetro de estilo do valor da função CONVERT () e formatar a data como gostaríamos. Portanto, estamos usando 103 como passar o argumento para o parâmetro style na consulta abaixo fornecida e que formata a data como dd/mm/yy.
selecione ID, Nome, DateOfBirth, Convert (nvarchar, DateOFBirth, 103) como ConvertedDOB de tblEmployees.
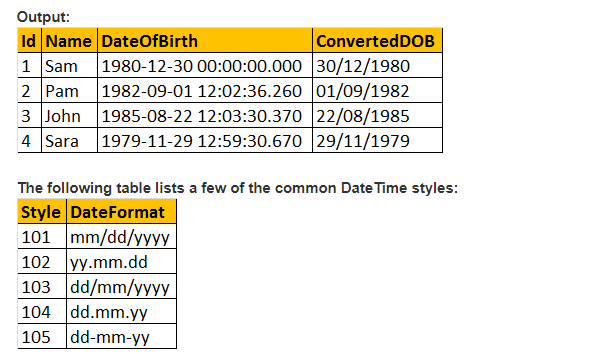
Então, vamos ter um olhar para o exemplo na prática e com a ajuda do ELENCO função ();
suponhamos que temos uma tabela de registro abaixo como;
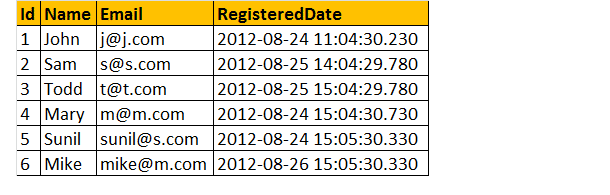 Agora, vamos encontrar o número total de registro por dia.
Agora, vamos encontrar o número total de registro por dia.
exemplo: Select CAST (RegisteredDate as DATE) as RegistrationDate, COUNT (Id) as TotalRegistrations Tblregistrations Group By CAST (RegisteredDate as DATE)
saída: finalmente, a saída parecerá como ;
Funções Definidas pelo Utilizador
Existem 3 tipos de Funções Definidas pelo Usuário no SQL Server que como
- funções Escalares
- Inline funções com valor de tabela
- várias instruções de funções com valor de tabela
Funções Escalares
funções Escalares variar em parâmetros que podem ou não ter parâmetros, e sempre dá um único (escalar) o valor na saída. Portanto, o valor retornado pode ser de qualquer formato de tipo de dados, exceto valor de texto, texto, imagem, cursor e carimbo de data / hora.
exemplo: Então, vamos desenvolver uma função que calcula e retorna a idade de uma pessoa na saída. Consequentemente, para comparar a idade necessária para, data de nascimento. Então, vamos passar a data de nascimento como parâmetro. Portanto, a função AGE () retornará um inteiro e aceitará o parâmetro date.
 selecione dbo.Idade (dbo.Idade(’10/08/1982′).
selecione dbo.Idade (dbo.Idade(’10/08/1982′).
então, vamos dar um exemplo prático na tabela abaixo da seguinte forma;
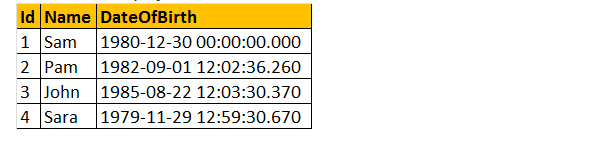
as funções definidas pelo Usuário escalar podem ser usadas na cláusula Select, conforme mostrado abaixo.
selecione o nome, DateOfBirth, dbo.Idade (DateOfBirth) como idade de tblEmployees
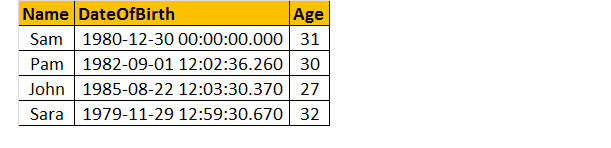 principalmente ver o texto da função usar sp_helptext FunctionName.
principalmente ver o texto da função usar sp_helptext FunctionName.
funções com valor de tabela em linha
uma função com valor de tabela em Linha sempre retorna uma tabela como saída.
então, vamos dar um exemplo abaixo; crie uma função que retorne funcionários por gênero.
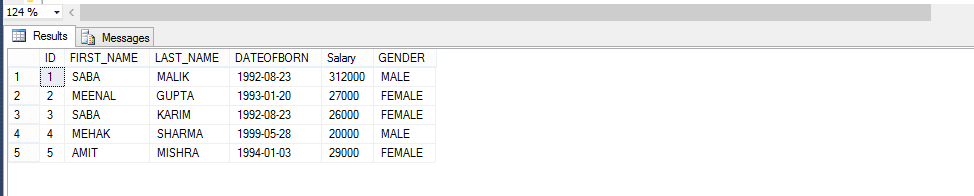
devido ao método de chamada para a função definida pelo usuário,
Select * From Fn_EMPLOYEEbyGender (“masculino”)
MULTI-DECLARAÇÃO de FUNÇÃO com valor de TABELA
Multi-declaração de funções com valor de tabela são muito mais semelhantes Inline funções com valor de Tabela e com algumas diferenças. Então, vamos dar uma olhada em um exemplo e, em seguida, observar as diferenças.
Empregado de Mesa
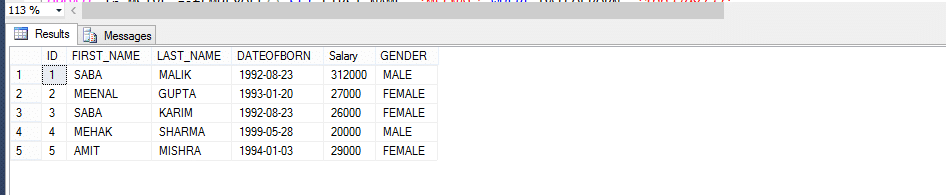
Multi-declaração de função com valor de Tabela(MSTVF):
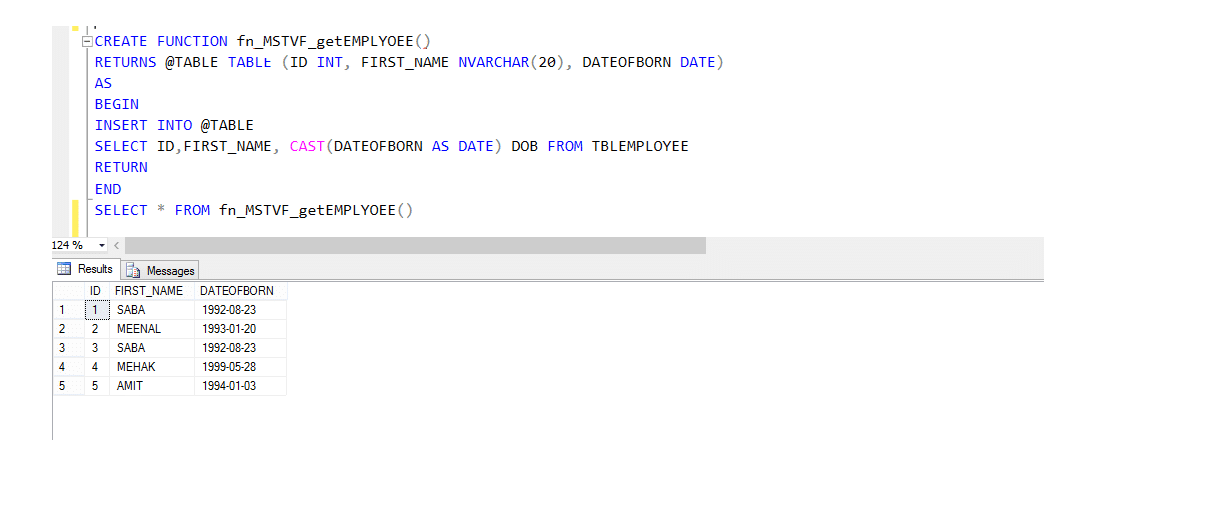 Devido ao método de chamada para v Multi-declaração de Função com valor de Tabela:
Devido ao método de chamada para v Multi-declaração de Função com valor de Tabela:
Select * from fn_MSTVF_GetEmployees ()
Conclusion
as junções são um termo muito compreensivo para iniciantes durante a fase de aprendizado dos comandos SQL. Consequentemente, na entrevista, o entrevistador faz pelo menos uma pergunta é sobre as junções SQL e funções. Portanto, neste post, estou tentando simplificar as coisas para novos alunos de SQL e facilitar a compreensão das junções SQL. Além disso, as funções no SQL, muitas pessoas estão tendo problemas para entender a função de trabalho real. Porque o SQL contém muitos dados em massa em diferentes nomes de banco de dados e tabelas. Uma função é um programa armazenado no banco de dados do SQL Server, onde você pode passar parâmetros e retornar um valor. Então, eu dei algum termo mais útil sobre o trabalho de funções.
- Sobre
- Posts mais Recentes

- Diferença Entre o SQL e MySQL – 14 de abril de 2020
- Como trabalhar com Subconsulta em Mineração de Dados – 23 de Março de 2018
- Como usar os recursos do navegador de Javascript? – Março 9, 2018
