přejít do sekce
- SQL Úvod
- Jak pracovat s SQL Joins
- vnitřní spojení
- levý spoj
- pravé připojení
- plné vnější spojení
- křížové spojení
- Jak pracovat s předem SQL připojí
- vlevo připojit
- plné vnější spojení
- typy klíčů v SQL
- kandidátský klíč
- primární klíč
- Unikátní klíč
- alternativní klíč
- kompozitní klíč
- Super klíč
- cizí klíč
- Jak pracovat s SQL funkcemi
- funkce LEFT ()
- RIGHT () funkce
- funkce CHARINDEX ()
- podřetězec () funkce
- REPLICATE () Function
- funkce SPACE ()
- PATINDEX() funkce
- nahradit () funkce
- STUFF() funkce
- Funkce Data time
- funkce isDate ()
- měsíc () funkce
- rok() funkce
- datename() funkce
- funkce DatePart ()
- DateAdd() funkce
- DatedDiff () funkce
- funkce Cast() A Convert ()
- uživatelsky definované funkce
- skalární funkce
- funkce s hodnotou Inline tabulky
- MULTI-STATEMENT table VALUED FUNCTION
- závěr
SQL Úvod
SQL je zkratka pro strukturovaný dotazovací jazyk. Používá se hlavně pro manipulaci s daty, úpravu dat a vyhledávání dat. To přichází s relační databáze Management System (RDBMS).
dozvíme se o pokročilejších funkcích SQL, jako jsou spojení a funkce.
Jak pracovat s SQL Joins
jednoduché spojení znamená kombinovat dvě nebo více tabulek v dané databázi. Spojit pracuje na společném subjektu ze dvou tabulek.
spojení obsahuje 5 dílčích spojení, které jako; vnitřní spojení, vnější spojení, levé spojení, pravé spojení a křížové spojení.
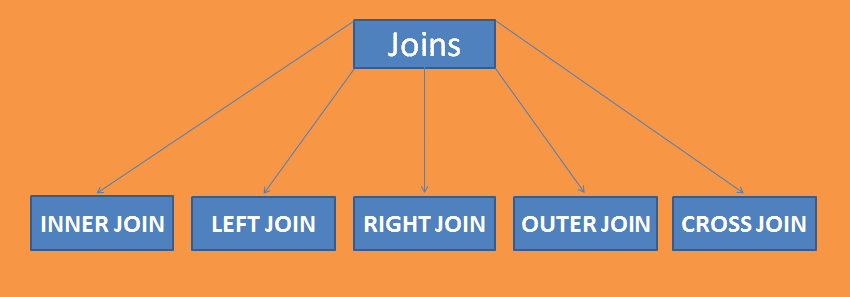
vnitřní spojení
vnitřní spojení se používá k výběru záznamů, které obsahují společné nebo odpovídající hodnoty v obou tabulkách (tabulka A I tabulka B). Neshoda je vyloučena.
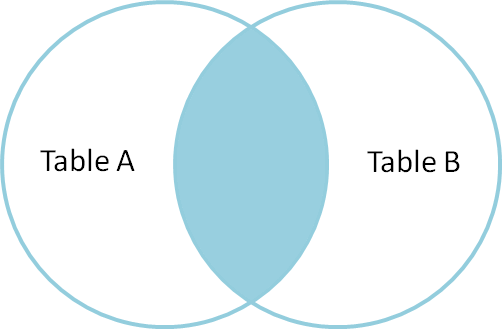
pojďme tedy pochopit typ spojení a běžné příklady a rozdíly mezi nimi.
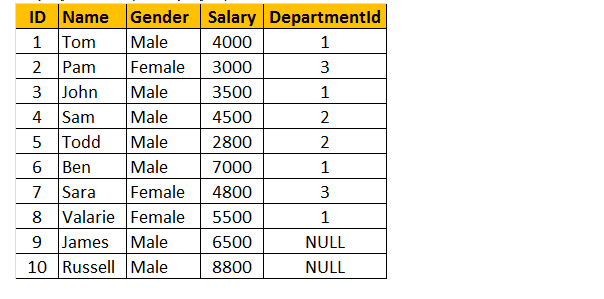
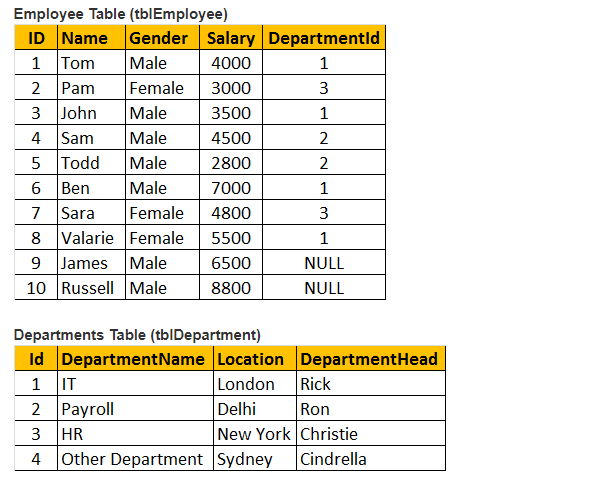
Tabulka 1: tabulka zaměstnanců (tbl employee)
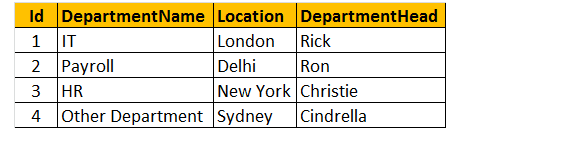
Tabulka 2: Tabulka oddělení (tblDepartments)
takže vytvoříme tabulku tbloddělení pro provádění programu.

Nyní vložte záznamy do tabulky tbloddělení.

vytvoříme další tabulku tblzaměstnanec pro provádění programu.

takže vložte záznamy do tabulky tblzaměstnanec.

proto obecný vzorec pro spojení.

Chcete-li dotaz najít jméno, Rod, plat a Odděleníjméno z obou tabulek tblployee a tblDepartments.

Poznámka: spojení nebo vnitřní spojení znamená totéž. Ale vždy je lepší použít vnitřní spojení, a to výslovně specifikuje váš záměr.
výstup: nyní bude konečná výstupní tabulka vypadat takto;
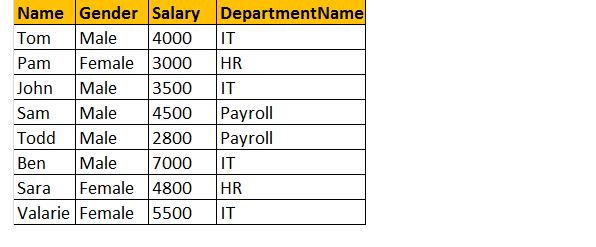
pokud se podíváte na výstupní okno, máme pouze 8 řádků, ale v tabulce tblployee máme 10 řádků. Nedostali jsme záznamy Jamese a Russella. Je to proto, že oddělení, v tabulce tblployee je pro tyto dva zaměstnance nulová a neodpovídá jejich sloupci ID v tabulce tblDepartments.
takže v závěrečném prohlášení vnitřní spojení vrací pouze odpovídající řádky z obou tabulek a neodpovídající řádky jsou vyloučeny kvůli jeho poddotazu.
levý spoj
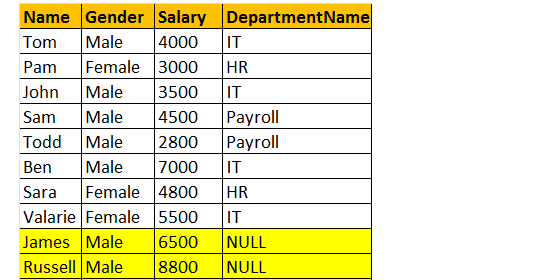
LEFT Join vrací všechny odpovídající řádky a neodpovídající řádky z levého postranního stolu. Kromě toho se vnitřní spojení a levé spojení navzájem značně používají.
takže si vezměme příklad, chci všechny řádky z tabulky tblployee, včetně záznamů Jamese a Russella. Pak bude výstup vypadat jako;

pravé připojení
RIGHT Join vrací všechny odpovídající řádky a neodpovídající řádky z pravé boční tabulky.
Vezměme si příklad; chci všechny řádky z pravých tabulek zapojených do spojení. V důsledku toho by bylo jako;

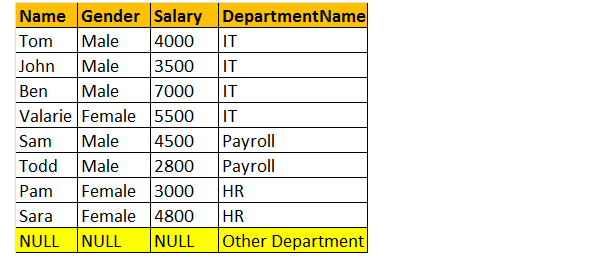
plné vnější spojení

OUTER join nebo FULL OUTER Join vrací všechny řádky z levé i pravé tabulky a včetně neodpovídajících řádků z tabulek.
Vezměme si příklad; chci všechny řádky z obou tabulek zapojených do spojení.

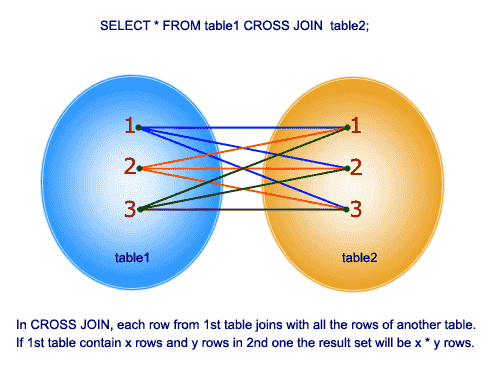
křížové spojení
toto spojení dává kartézský součin 2 tabulek ve funkci Spojení. Toto spojení neobsahuje klauzuli ON.
takže pojďme pochopit příklad: V tabulce tblployee máme 10 řádků a v tabulce tblpartments máme 4 řádky. Kříž se tedy spojí mezi těmito 2 tabulkami a vytvoří 40 řádků.

Jak pracovat s předem SQL připojí
v této relaci vysvětlím tyto věci následovně;
- pokročilé nebo inteligentní připojení v SQL Serveru.
- načte data pouze neodpovídající řádky z levé tabulky.
- načíst data pouze neodpovídající řádky z pravé tabulky.
- načte data pouze neodpovídající řádky z levé i pravé tabulky.
podívejme se tedy na tabulky tblployee a tblDepartment.
vlevo připojit
takže, pojďme pochopit příklad, chci načíst pouze neodpovídající řádky z levého bočního stolu.

výstup: nakonec bude výstup vypadat takto;

pravé připojení
takže, pojďme pochopit příklad, chci načíst pouze neodpovídající řádky z pravé boční tabulky.

výstup: nakonec bude výstup vypadat takto;

plné vnější spojení
pojďme tedy pochopit příklad, chci načíst pouze neodpovídající řádky z pravého bočního stolu a levého bočního stolu a odpovídající řádky by měly být odstraněny.

výstup: nakonec bude výstup vypadat takto;
typy klíčů v SQL
klíč v SQL je datové pole, které výhradně identifikuje záznam. Jinými slovy, klíč je sada sloupců, která se používá k jedinečné identifikaci záznamu v tabulce.
- Vytvořte vztahy mezi dvěma tabulkami.
- Udržujte jedinečnost a odpovědnost v tabulce.
- Udržujte konzistentní a platná data v databázi.
- může pomoci při rychlém získávání dat usnadněním indexů ve sloupcích.
SQL server obsahuje následující klíče;
- kandidátský klíč
- primární klíč
- Unikátní klíč
- alternativní klíč
- kompozitní klíč
- Super klíč
- cizí klíč
než budete pokračovat, podívejte se prosím na obrázek níže;
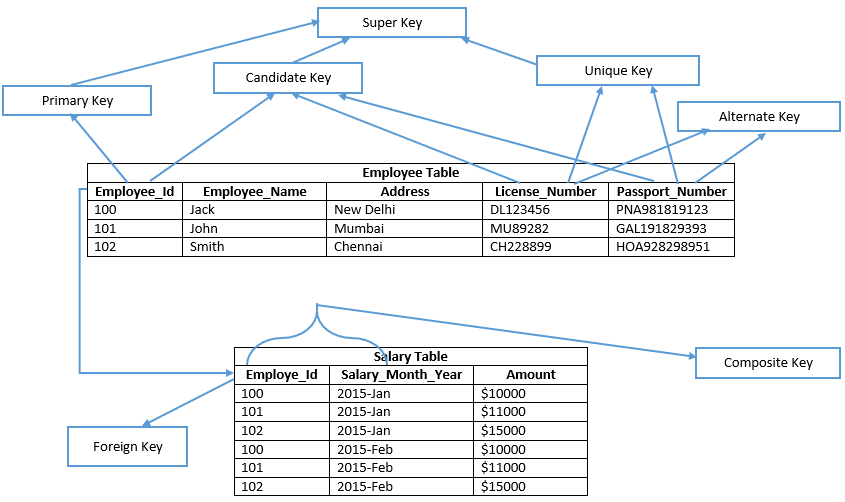
pojďme pochopit každý klíč v detailech
kandidátský klíč
kandidátský klíč je klíčem tabulky, která může být vybrána jako primární klíč tabulky a tabulka může mít více kandidátských klíčů, proto jeden může být vybrán jako primární klíč.
příklad: Employee_Id, License_Number, & Passport_Number zobrazuje kandidátské klíče
primární klíč
primární klíč je podobný vybranému kandidátskému klíči tabulky, aby se ověřil každý datový záznam jedinečně v tabulce. Proto primární klíč neobsahuje žádnou hodnotu null v žádném ze sloupců tabulky a také udržuje jedinečné hodnoty ve sloupci. V daném příkladu Employee_Id definuje primární klíč tabulky zaměstnanců. V důsledku toho, v SQL Server Management Studio, primární klíč ve výchozím nastavení vytvoří seskupený index v tabulce haldy a tabulka, která nespočívá v seskupeném indexu, je známá jako tabulka haldy. Zda definuje nonclustered primární klíč v tabulce podle typu indexu explicitně.
kromě toho může mít tabulka pouze jeden primární klíč a primární klíč lze definovat v SQL Serveru pomocí příkazů SQL:
- prohlášení o tabulce Kréta (v době vytvoření tabulky) – v důsledku toho systém definuje název primárního klíče.
- příkaz ALTER TABLE (použití omezení primárního klíče) – v důsledku toho uživatel sám deklaruje název omezení primárního klíče.
příklad: Employee_Id je primární klíč tabulky zaměstnanců.
Unikátní klíč
jedinečný klíč je stejně jako primární klíč a neobsahuje duplicitní hodnoty ve sloupci. Má nižší rozdíly ve srovnání primárního klíče:
- to umožňuje jednu hodnotu null ve sloupci.
- ve výchozím nastavení vytváří non-clusteru index a haldy tabulky.
alternativní klíč
alternativní klíč je podobný kandidátskému klíči, ale není vybrán jako primární klíč tabulky.
příklad: License_Number a Passport_Number jsou alternativní klíče.
kompozitní klíč
kompozitní klíč (také známý jako složený klíč nebo zřetězený klíč) je skupina dvou nebo více sloupců, která identifikuje každý řádek tabulky jedinečně. Kromě toho jeden sloupec jednotky složeného klíče nemusí být schopen jednoznačně ověřit datové záznamy. Jako výsledek, to může být buď primární klíč nebo kandidát klíč také.
příklad: v tabulce Employee_Id & Salary_Month_Year oba sloupce ověřují každý řádek jedinečně v tabulce platů. Proto Employee_Id nebo Salary_Month_Year sloupec v tabulce, které nemohou identifikovat každý řádek jedinečně. Jeden složený primární klíč můžeme vytvořit v tabulce platů pomocí názvů sloupců Employee_Id a Salary_Month_Year.
Super klíč
Super klíč je sada sloupců, na kterých jsou funkčně závislé všechny sloupce tabulky. Vzhledem k sadě sloupců, které jednoznačně identifikují každý řádek v tabulce. Jinými slovy, tento klíč obsahuje několik dalších sloupců, které nejsou striktně vyžadovány pro jednoznačné ověření každého řádku v tabulce. Vypadá to, že primární klíč a kandidátské klíče jsou minimální superkeys nebo můžete říci podmnožinu superkeys.
podívejme se tedy na výše uvedený příklad, v tabulce zaměstnanců název sloupce Employee_Id sotva postačuje k jednoznačnému ověření libovolného řádku tabulky. Takže každá sada sloupce z tabulky zaměstnanců, která obsahuje Employee_Id, je superkey pro tabulku zaměstnanců.
například: {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id, Employee_Name, Address} atd.
License_Number a Passport_Number jsou sloupce Název, může také jednoznačně ověřit některý z řádků tabulky. Každý z názvu sloupce, který se skládá z License_Number nebo Passport_Number nebo Employee_Id, je superklíčem tabulky.
například: {License_Number, Employee_Name, Address}, {License_Number, Employee_Name, Passport_Number}, {Passport_Number, Employee_Name, Address, License_Number}, {Passport_Number, Employee_Name}, {Passport_Number, Employee_Id} atd.
cizí klíč
FK definuje vztah mezi dvěma nebo více než dvěma tabulkami najednou. Primární klíč jedné tabulky je v jiné tabulce označován jako cizí klíč. Cizí klíč může mít duplicitní hodnoty v tabulce a také může mít hodnoty null, pokud je název sloupce definován tak, aby akceptoval hodnoty null.
například název sloupce „Employee_Id“ (což je primární klíč tabulky zaměstnanců ) je cizí klíč v tabulce platů.
Poznámka: klíče jako primární klíč a jedinečný klíč vytváří indexy se sloupci klíčů. Organizovaná data v uzlu struktury B-stromu (Balanced Tree: Leaf uzly jsou na jiné úrovni než kořenová strana) v SQL Serveru. Proto, Nonclustered index vytváří samostatnou strukturu ze základní datové tabulky, ale clustered index převádí základní datovou tabulku ze struktury haldy na strukturu B-stromu.
kromě toho seskupený index nevytváří samostatnou strukturu kromě základní tabulky, a proto můžeme v tabulce vytvořit pouze jeden seskupený index. Proto můžeme tabulku Seřadit pouze jedním způsobem (může mít více sloupců k třídění, ale třídění lze provést pouze jedním způsobem), což je pořadí seskupeného indexu.
Jak pracovat s SQL funkcemi
funkce je entita program, který je uložen v databázi SQL Server buď můžete předat parametry do nebo vrátit hodnotu. Dále se budeme těšit na některé velmi užitečné vestavěné funkce a uživatelsky definované funkce.
funkce Coalesce
Coalesce (): tato funkce vrací pouze první nulovou hodnotu. Vezměme si příklad nad funkcí Coalesce ().
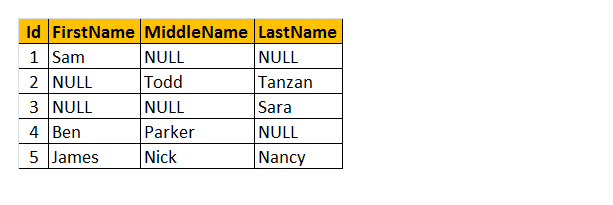 rozumíme tabulce jako název „zaměstnanec“ výše. Jako výsledek, můžete vidět, že někteří zaměstnanci mají své křestní jméno chybí, někteří mají prostřední jméno a někteří z nich mají příjmení chybí. Takže chci vrátit pouze „jméno“ zaměstnance.
rozumíme tabulce jako název „zaměstnanec“ výše. Jako výsledek, můžete vidět, že někteří zaměstnanci mají své křestní jméno chybí, někteří mají prostřední jméno a někteří z nich mají příjmení chybí. Takže chci vrátit pouze „jméno“ zaměstnance.
jak to bude fungovat? Pochopte, zpracováváme sloupce křestní jméno, prostřední jméno a příjmení jako parametry funkce COALESCE (). Proto tato funkce vrátí jedinou první nenulovou hodnotu ze 3 sloupců.
dotaz: vyberte Id, COALESCE (křestní jméno, prostřední jméno, příjmení) jako jméno z tblployee
nakonec bude výstup vypadat takto;
 funkce LEFT ()
funkce LEFT ()
LEFT (Character_Expression, Integer_Expression) – tato funkce vrací zadaný počet znaků z levé strany daného výrazu znakové hodnoty.
příklad: vyberte vlevo (‚ABCDE‘, 3)
výstup: ABC
RIGHT () funkce
RIGHT (Character_Expression, Integer_Expression) – tato funkce vrací zadaný počet znaků z pravé strany daného výrazu znakové hodnoty.
příklad: vyberte vpravo (‚ABCDE‘, 3)
výstup: CDE
funkce CHARINDEX ()
CHARINDEX (‚Expression_To_Find‘, ‚Expression_To_Search‘,‘ Start_Location‘) – tato funkce vrací výchozí pozici zadaného výrazu hodnoty v podřetězci znaků. Parametr Start_Location je volitelný.
příklad: pojďme pochopit, uděláme počáteční pozici znaku ‚ @ ‚ v řetězci e-mailu ‚[email protected]‘.
vyberte CHARINDEX(‚@‘,’[email protected]‘,1)
výstup: 5
podřetězec () funkce
podřetězec (výraz‘, ‚Start‘,‘ Délka‘) – tato funkce vrací podřetězec (podčást řetězce) z daného výrazu hodnoty. Kromě toho, když zadáte výchozí pozici pomocí parametru „start“ a další počet znaků v podřetězci pomocí parametru „Délka“. Všechny tři parametry jsou povinné.
příklad: chci zobrazit pouze část domény daného e-mailu ‚[email protected]‘.
vyberte podřetězec (‚[email protected]‘,6, 7)
výstup: bbb.com
v důsledku toho jsme provedli kódování s výchozí polohou a parametry délky. Namísto pevného kódování parametrů je můžeme dynamicky načíst pomocí řetězcových funkcí CHARINDEX() a LEN (), jak je uvedeno níže.
příklad:
vyberte podřetězec (‚[email protected]“, (CHARINDEX (‚@ ‚, ‚[email protected]“) + 1), (LEN („[email protected]‘) – CHARINDEX (‚@‘, ‚[email protected]‘)))
výstup: bbb.com
Vezměme si tedy skutečný příklad s použitím funkcí LEN (), CHARINDEX() a SUBSTRING (). Pojďme si myslet, že máme tabulku, jak je uvedeno níže;
 Otázkou tedy je, jak najdete celkový počet e-mailů podle jejich domény.
Otázkou tedy je, jak najdete celkový počet e-mailů podle jejich domény.
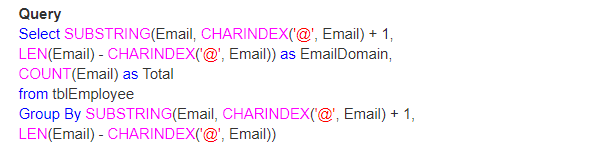
výstup: nakonec bude výstup vypadat takto;
 REPLICATE () Function
REPLICATE () Function
REPLICATE (String_To_Be_Replicated, Number_Of_Times_To_Replicate) – tato funkce opakuje daný bod řetězce a pro zadaný počet opakování.
příklad: vyberte replikovat (‚Pragim‘, 3)
výstup: Pragim Pragim Pragim
promluvme si o praktickém příkladu použití funkce replikovat (): Tuto tabulku budeme používat většinu času, a pro zbytek našich příkladů v tomto článku.
předpokládejme tedy, že máme tabulku, jak je uvedeno níže;
 dotaz: vyberte jméno, příjmení, podřetězec(e-mail, 1, 2) + replikovat(‚*‘,5) +
dotaz: vyberte jméno, příjmení, podřetězec(e-mail, 1, 2) + replikovat(‚*‘,5) +
SUBSTRING(e – mail, CHARINDEX(‚@‘,e-mail), LEN(E-Mail) – CHARINDEX(‚@‘,e-mail)+1) jako E-mail
od tblployee
udělejme e-mail s 5 * (hvězdičkou) symboly. Pak by výstup byl takový
 funkce SPACE ()
funkce SPACE ()
SPACE (Number_Of_Spaces) – Tato funkce vrací jediný počet mezer a je určena argumentem výrazu Number_Of_Spaces.
příklad: funkce SPACE (5)vloží 5 mezer mezi křestní jméno a příjmení
vyberte FirstName + SPACE(5) + LastName jako FullName z tblployee
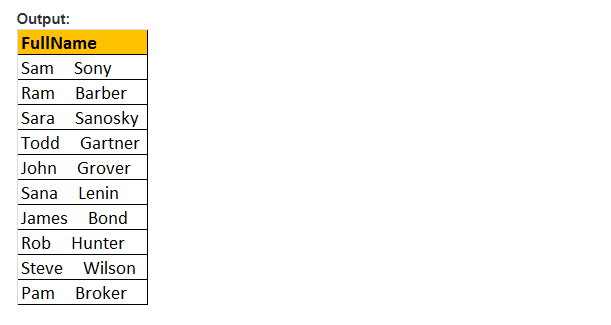 PATINDEX() funkce
PATINDEX() funkce
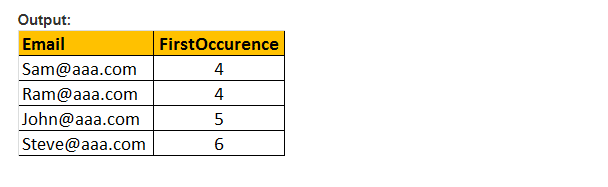
Tato funkce vrací pouze počáteční umístění prvního výskytu vzoru v zadaném efektivním výrazu. Proto trvá pouze dva argumenty a vzor, který má být prohledán, a výraz. Proto je PATINDEX() podobný CHARINDEXU(). S CHARINDEX () nemůžeme používat zástupné znaky, zatímco PATINDEX () zahrnuje tuto schopnost. Pokud zadaná hodnota vzoru není nalezena, vrátí PATINDEX () nulu.
příklad: vyberte Email, PATINDEX (‚%aaa.com, e-mail‘) jako první výskyt z tblployee kde PATINDEX (‚%@aaa.s‘, e-mailem) > 0
 nahradit () funkce
nahradit () funkce
nahradit (String_Expression, Pattern, Replacement_Value), tato funkce nahrazuje všechny výskyty pozice zadané hodnoty řetězce jinou hodnotou řetězce.
příklad: všechny řetězce. COM jsou nahrazeny. Net
vyberte E-mail, nahradit (e-mail,‘. com‘,‘.net‘) jako ConvertedEmail z tblployee
 STUFF() funkce
STUFF() funkce
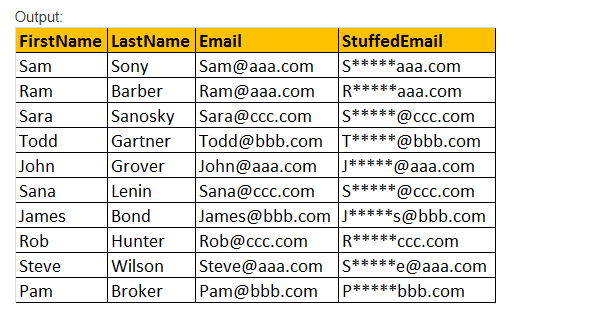
STUFF(Original_Expression, Start, Length, Replacement_expression), tato funkce STUFF() vloží pouze Replacement_expression, který je zadán na výchozí pozici, spolu s odstraněním znaků zadaných pomocí výrazu hodnoty parametru délky.
příklad: vyberte jméno, příjmení, e-mail,věci (E-Mail,2,3,’*****‘) jako StuffedEmail od tblployee.
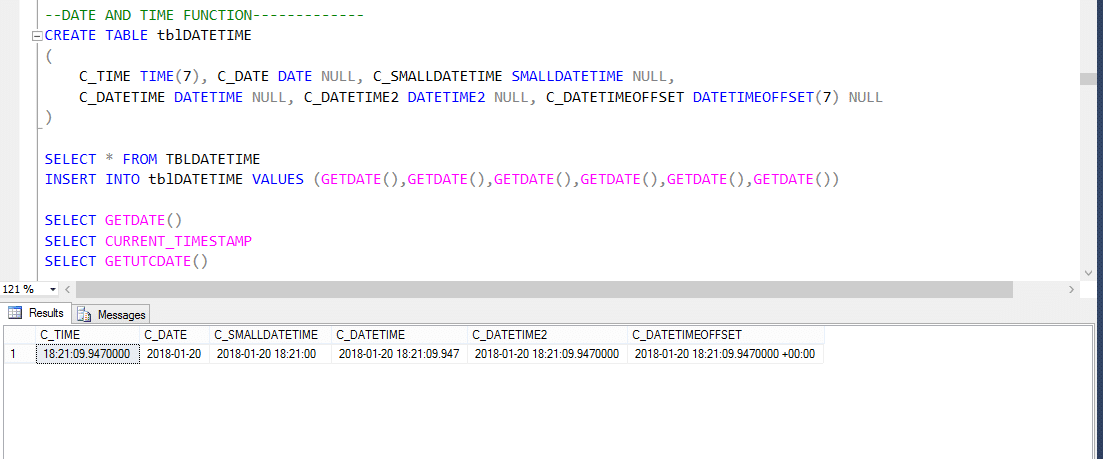
 Funkce Data time
Funkce Data time
v databázi SQL Server je k dispozici několik vestavěných funkcí DateTime. Většina z následujících funkcí může být použita k získání aktuálního data a času systému a místa, kde máte nainstalován SQL server.
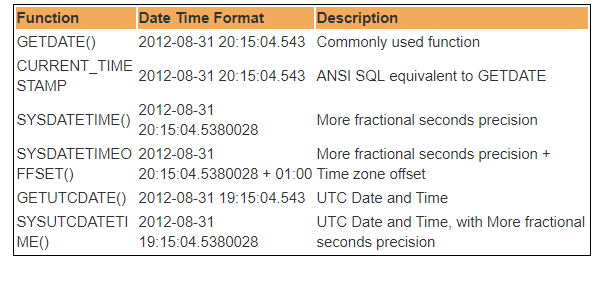 UTC tedy znamená koordinovaný univerzální čas, na základě kterého svět reguluje hodiny a časová data. Pozoruhodný. mezi GMT a UTC existují malé rozdíly, ale pro většinu běžných účelů, UTC je synonymem pro GMT.
UTC tedy znamená koordinovaný univerzální čas, na základě kterého svět reguluje hodiny a časová data. Pozoruhodný. mezi GMT a UTC existují malé rozdíly, ale pro většinu běžných účelů, UTC je synonymem pro GMT.
Vezměme si tedy další příklad, jak je uvedeno níže;
funkce isDate ()
ISDATE () – tato funkce kontroluje, zda je pouze daná hodnota a existuje platné datum, čas nebo DateTime. Pak se vrátí 1 pro úspěch, 0 pro selhání.
příklad:
vyberte ISDATE (‚PRAGIM‘) — vrátí 0
příklad:
vyberte ISDATE (Getdate ()) – vrátí SE1
příklad:
vyberte ISDATE(‚2018-01-20 21:02:04.167‘) — vrátí 1
Poznámka: pro hodnoty datetime2 vrací IsDate nulu.
příklad:
vyberte ISDATE(‚2018-01-20 22:02:05.158.1918447‘) — vrátí se 0.
den () Funkce
den () – Tato funkce vrací pouze „číslo dne v měsíci“ daného data.
příklady:
vyberte den(GETDATE()) — vydá výstup jménem čísla dne v měsíci a na základě aktuálního systémového DateTime.
vyberte den (’01/14/2018′) – vrátí 14
měsíc () funkce
měsíc () – Tato funkce poskytne výstup jménem „čísla měsíce roku“ daného data.
příklady:
Vyberte měsíc (GETDATE ()) – Tato funkce poskytne výstup jménem „čísla měsíce roku“ a na základě aktuálního data a času systému.
Vyberte měsíc(’05/14/2018) — vrátí 5
rok() funkce
rok() – tato funkce poskytne výstup jménem „čísla roku“ daného data
příklady:
vyberte rok(GETDATE()) — Vrátí číslo roku a na základě aktuálního data systému
vyberte rok (’01/20/2018) — bude vrací 2018
datename() funkce
datename(datepart, date) – Tato funkce vrací pouze výraz řetězce, který představuje pouze část daného data. Tyto funkce se skládají ze 2 parametrů.
první parametr ‚DatePart‘ určuje část data, kterou chceme. Druhým parametrem je skutečné datum, od kterého chceme část data.
 Příklad 1:
Příklad 1:
vyberte datum (den, ‚2017-04-20 13:47:47.350‘) — vrátí 20
příklad 2:
vyberte datum (den v týdnu, ‚2017-04-20 13:47:47.350‘) — vrátí se čtvrtek
příklad 3:
vyberte datum (měsíc, ‚2017-04-20 13:47:47.350‘) — vrátí Duben
takže si vezměme příklad pomocí některých z těchto funkcí DateTime. Zvažte tabulku tblzaměstnanci.
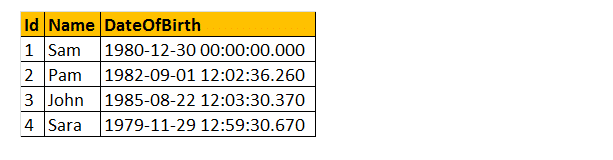 příklad: chci vrátit všechny jméno, datum narození, den, Měsíc, Měsíc a rok, jak je uvedeno níže.
příklad: chci vrátit všechny jméno, datum narození, den, Měsíc, Měsíc a rok, jak je uvedeno níže.
vyberte jméno, datum narození, datum narození(den v týdnu,datum narození) jako , měsíc(datum narození) jako měsíční číslo, datum narození(měsíc, datum narození) jako, rok (datum narození) od tblployees

funkce DatePart ()
DatePart (DatePart, Date) – Tato funkce dává celé číslo představující zadanou hodnotu DatePart. Většinou funkce je podobná funkci DateName (). DateName () vrací pouze hodnotu nvarchar, zatímco DatePart () vrací pouze celočíselnou hodnotu. Platné hodnoty parametru DatePart jsou uvedeny níže.
příklady:
vyberte DATEPART (den v týdnu, ‚2012-08-30 19:45:31.793‘) — vrátí se 5
vyberte datum (den v týdnu, ‚2012-08-30 19:45:31.793‘) — vrátí čtvrtek
DateAdd() funkce
DATEADD (datepart, NumberToAdd, date) – tato funkce SQL poskytuje pouze DateTime, po zadaném termínu NumberToAdd a datepart zadané daného data.
příklady:
vyberte DateAdd (den, 10, ‚2018-01-20 19:45:31.793‘) — vrátí se ‚2018-01-30 19:45:31.793‘
vyberte DateAdd (den, -10, ‚2012-08-30 19:45:31.793‘)– vrátí se ‚2018-01-20 19:45:31.793‘
DatedDiff () funkce
DATEDIFF (datepart, startdate, enddate) – Tato funkce udává počet zadaných hranic datepart překročených mezi zadaným startdate a enddate.
příklady:
vyberte DATEDIFF (měsíc, ’11/30/2005′,’01/31/2006′) — vrátí se 2
vyberte DATEDIFF (den, ’11/30/2005′,’01/31/2006′) — vrátí 62
takže si vezměme příklad, předpokládejme, že máme níže uvedenou tabulku;
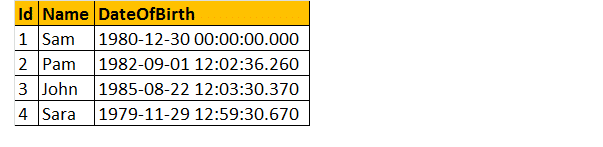
takže napište dotaz, abyste zjistili věk osoby, kdy je uvedeno datum narození.

nakonec bude výstup vypadat, jak je uvedeno níže.
funkce Cast() A Convert ()
Chcete-li převést datový typ jedné jednotky na jiný, lze použít funkce CAST a CONVERT.
syntaxe funkce CAST a CONVERT:
CAST (výraz jako data_type)
CONVERT (data_type , výraz )
navíc, jak vidíte, funkce CONVERT() má volitelnou hodnotu parametru style, zatímco funkce CAST() tuto schopnost postrádá.
Vezměme si příklad, vezmeme níže uvedenou tabulku;
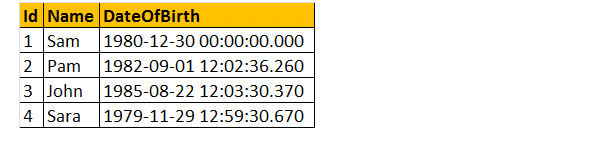 následující 2 dotazy převádějí datový typ Dateofbirth na nvarchar. První Dotaz používá funkci CAST() a druhý používá funkci CONVERT (). Nakonec je výstup přesně stejný pro oba dotazy, jak je uvedeno níže.
následující 2 dotazy převádějí datový typ Dateofbirth na nvarchar. První Dotaz používá funkci CAST() a druhý používá funkci CONVERT (). Nakonec je výstup přesně stejný pro oba dotazy, jak je uvedeno níže.
vyberte ID, Name DateOfBirth, Cast (DateOfBirth jako nvarchar) jako ConvertedDOB od tblployees.
vyberte ID, Název DateOfBirth, převést (DateOfBirth jako nvarchar) jako ConvertedDOB od tblployees.
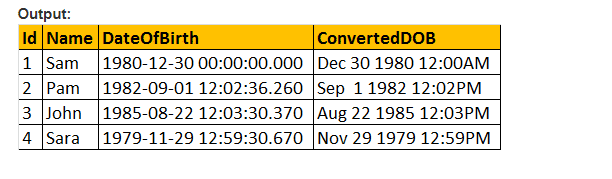 takže uděláme parametr stylu hodnoty funkce CONVERT () a formátujeme Datum tak,jak bychom chtěli. Takže používáme 103 jako předání parametru argumentu pro styl v níže uvedeném dotazu a který formátuje Datum jako dd / mm / rr.
takže uděláme parametr stylu hodnoty funkce CONVERT () a formátujeme Datum tak,jak bychom chtěli. Takže používáme 103 jako předání parametru argumentu pro styl v níže uvedeném dotazu a který formátuje Datum jako dd / mm / rr.
vyberte ID, jméno, DateOfBirth, Convert (nvarchar, DateOFBirth, 103) jako ConvertedDOB od tblployees.
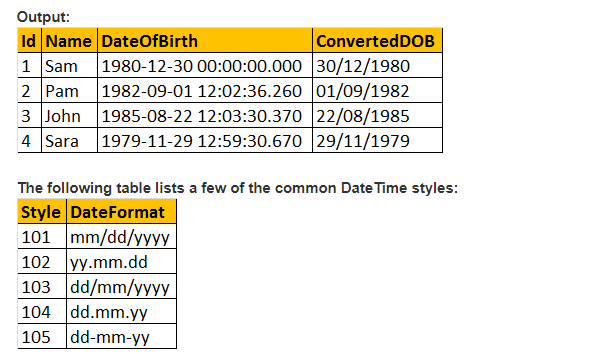
podívejme se tedy na praktický příklad pomocí funkce CAST ();
předpokládejme, že máme registrační tabulku níže jako;
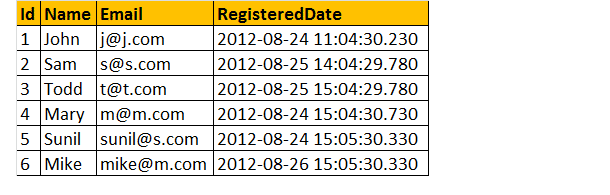 nyní najdeme celkový počet registrací podle dne.
nyní najdeme celkový počet registrací podle dne.
příklad: vyberte CAST (RegisteredDate as DATE) jako RegistrationDate, COUNT (Id) jako TotalRegistrations tblRegistrations Group by CAST (RegisteredDate as DATE)
výstup: nakonec bude výstup vypadat jako ;
uživatelsky definované funkce
v SQL Serveru jsou 3 typy uživatelem definovaných funkcí, které jako
- skalární funkce
- Inline tabulkové funkce
- vícestupňové tabulkové funkce
skalární funkce
skalární funkce se liší v parametrech, které mohou nebo nemusí mít parametry, a vždy dává jednu (skalární) hodnotu v SQL Serveru.výstup. Vrácená hodnota tedy může mít jakýkoli formát datového typu kromě textové hodnoty, textu, obrázku, kurzoru a časového razítka.
příklad: Pojďme tedy vyvinout funkci, která vypočítá a vrátí věk osoby ve výstupu. V důsledku toho porovnat věk, který jsme požadovali, datum narození. Pojďme tedy jako parametr předat datum narození. Proto funkce AGE () vrátí celé číslo a přijme parametr date.
 vyberte dbo.Věk (dbo.Věk (’10/08/1982′).
vyberte dbo.Věk (dbo.Věk (’10/08/1982′).
Vezměme si tedy praktický příklad v následující tabulce;
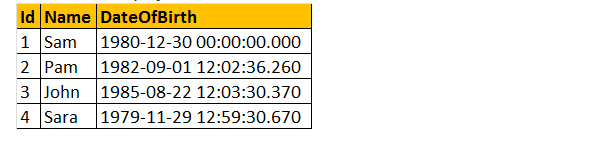
skalární uživatelem definované funkce lze použít v klauzuli Select, jak je uvedeno níže.
vyberte jméno, DateOfBirth, dbo.Věk (DateOfBirth) jako Věk od tblployees
 většinou zobrazit text funkce Použijte Sp_helptext FunctionName.
většinou zobrazit text funkce Použijte Sp_helptext FunctionName.
funkce s hodnotou Inline tabulky
funkce s hodnotou inline tabulky vždy vrátí tabulku jako výstup.
Vezměme si příklad níže; Vytvořte funkci, která vrací zaměstnance podle pohlaví.
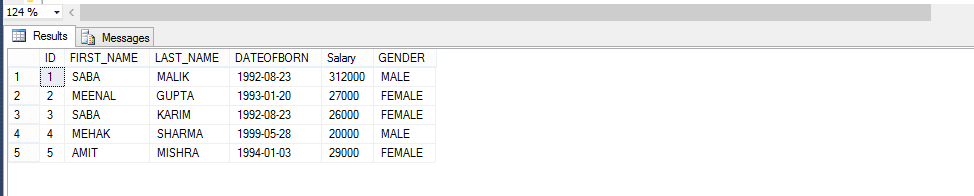
vzhledem k volání metody pro uživatelem definované funkce,
Select * From Fn_EMPLOYEEbyGender (‚male‘)
MULTI-STATEMENT table VALUED FUNCTION
Multi-statement table valued functions jsou mnohem více podobné Inline tabulkovým funkcím a s určitými rozdíly. Podívejme se tedy na příklad a pak si všimneme rozdílů.
tabulka zaměstnanců
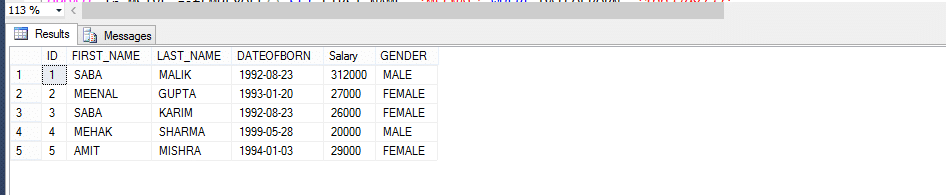
funkce hodnotící tabulku s více příkazy (MSTVF):
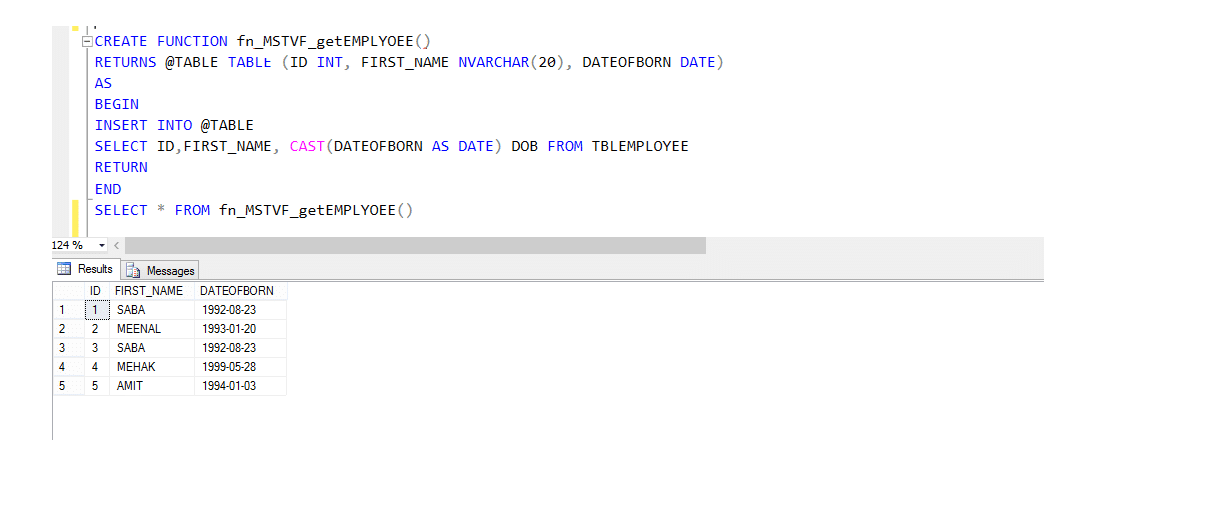 vzhledem k volání metody pro vthe Multi-statement tabulka hodnotné funkce:
vzhledem k volání metody pro vthe Multi-statement tabulka hodnotné funkce:
vyberte * z fn_MSTVF_GetEmployees ()
závěr
spojení je velmi srozumitelný termín pro začátečníky během fáze učení příkazů SQL. V důsledku toho se v rozhovoru tazatel zeptá alespoň na jednu otázku týkající se spojení SQL a funkcí. Takže v tomto příspěvku se snažím zjednodušit věci pro nové studenty SQL a usnadnit pochopení spojení SQL. Kromě toho, funkce v SQL, mnoho lidí má potíže pochopit skutečnou pracovní funkci. Protože SQL obsahuje velké množství dat hromadně v různých názvech databází a tabulek. Funkce je uložený program v databázi SQL Server, kde můžete předat parametry a vrátit hodnotu. Tak, dal jsem nějaký užitečnější termín o fungování funkcí.
- o
- poslední příspěvky

- rozdíl mezi SQL a MySQL-14. dubna 2020
- jak pracovat s Poddotazem v dolování dat – 23. března 2018
- jak používat funkce prohlížeče Javascript? – Březen 9, 2018
