Vai alla sezione
- SQL Introduzione
- Come lavorare con SQL Join
- Inner Join
- Unire a sinistra
- Destra Join
- Pieno esterno join
- Cross join
- Come lavorare con Advance SQL Join
- Sinistra Join
- Pieno esterno join
- Tipi di chiavi in SQL
- Chiave candidata
- Chiave primaria
- Chiave univoca
- Chiave alternativa
- Chiave composita
- Super Key
- Chiave esterna
- Come lavorare con le funzioni SQL
- LEFT() Function
- Funzione RIGHT ()
- Funzione CHARINDEX ()
- SUBSTRING() Function
- REPLICATE() Funzione
- Funzione SPACE ()
- Funzione PATINDEX ()
- REPLACE () Funzione
- Funzione STUFF ()
- Funzione Data ora
- isDate() Function
- Funzione Mese ()
- Anno di Funzione ()
- DateName() la Funzione
- DatePart() Function
- DateAdd() Function
- DatedDiff() la Funzione
- Funzioni Cast() e Convert ()
- Funzioni Definite dall’Utente
- Funzioni Scalari
- Funzioni a valori di tabella in linea
- MULTI-STATEMENT TABLE VALUED FUNCTION
- Conclusione
SQL Introduzione
SQL sta per Structured Query Language. Viene utilizzato principalmente per la manipolazione dei dati, la modifica dei dati e il recupero dei dati. Questo viene in giro con Relational Database Management System (RDBMS).
Impareremo a conoscere le funzionalità più avanzate di SQL come Join e funzioni.
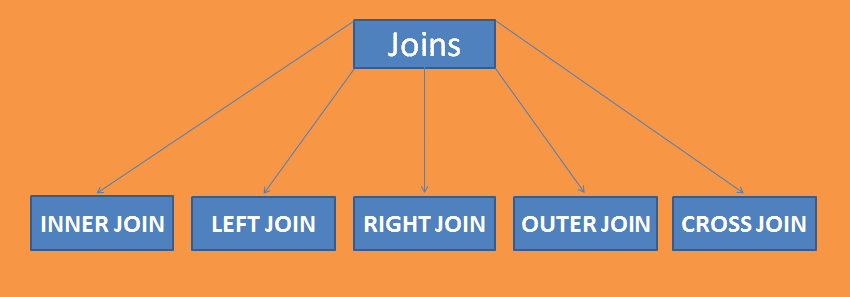
Come lavorare con SQL Join
Un semplice join significa combinare due o più tabelle in un dato database. Un join funziona su un’entità comune di due tabelle.
Un join contiene 5 sub-join che come; Inner join, Outer Join, Left Join, Right Join e Cross Join.
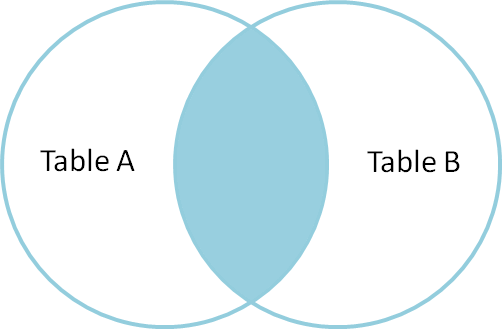
Inner Join
Un inner join viene utilizzato per selezionare i record che contengono valori comuni o corrispondenti in entrambe le tabelle (Tabella A e Tabella B). Non corrispondenti vengono eliminati.
Quindi, capiamo il tipo di join e con esempi comuni e le differenze tra loro.
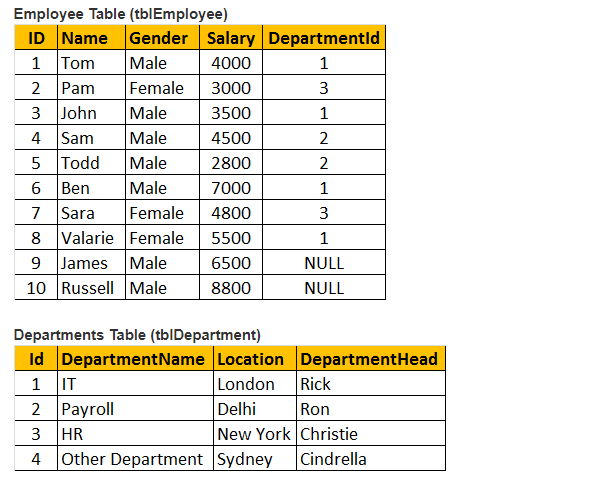
Tabella 1: Tabella dei dipendenti (tblEmployee)
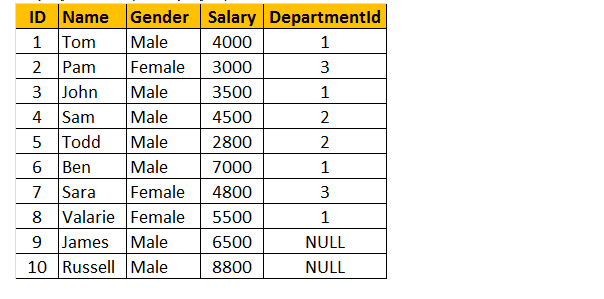
Tabella 2: Tabella dei dipartimenti (tblDepartments)
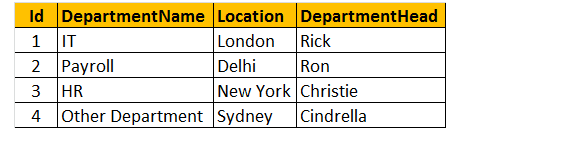
Quindi, creiamo tabella TBLDPARTMENTS per l’esecuzione di un programma.

Ora, inserire i record nella tabella tblDepartments.

Creiamo un’altra tabella tblEmployee per l’esecuzione di un programma.

Quindi, inserisci i record nella tabella tblEmployee.

Pertanto, una formula generale per join.

Per fare una query per trovare Nome, Genere, Stipendio e DepartmentName da entrambe le tabelle tblEmployee e tblDepartments.

Nota: JOIN o INNER JOIN significa lo stesso. Ma sempre meglio usare INNER JOIN, e questo specifica esplicitamente la tua intenzione.
Output: ora la tabella di output finale sarà simile a questa;
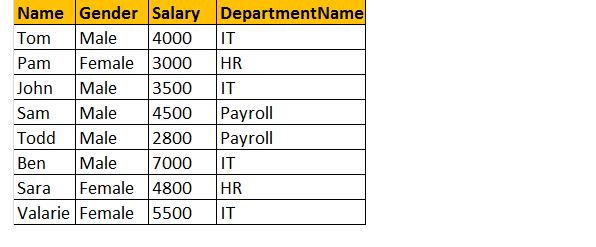
Se guardi la finestra di output, abbiamo solo 8 righe, ma nella tabella tblEmployee, abbiamo 10 righe. Non abbiamo i dischi di JAMES e RUSSELL. Questo perché il DEPARTMENTID, nella tabella tblEmployee è NULL per questi due dipendenti e non corrisponde con la loro colonna ID nella tabella tblDepartments.
Quindi, in un’istruzione finale, i join interni restituiscono solo le righe corrispondenti da entrambe le tabelle e le righe non corrispondenti vengono eliminate a causa della sua sottoquery.
Unire a sinistra
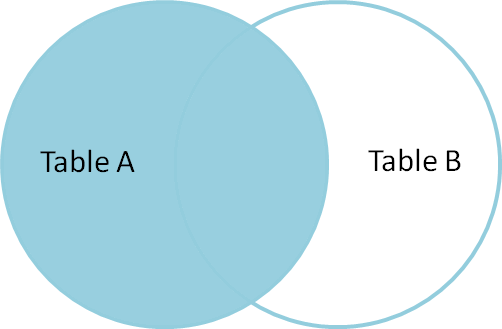
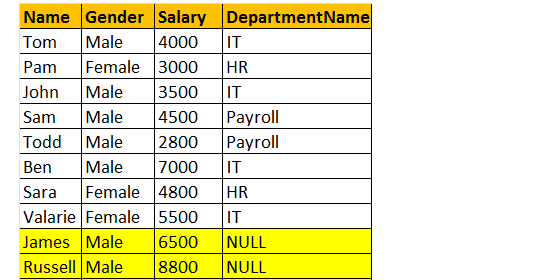
LEFT Join restituisce tutte le righe corrispondenti e le righe non corrispondenti dalla tabella laterale sinistra. Inoltre, Inner join e Left join sono ampiamente utilizzati l’un l’altro.
Quindi, facciamo un esempio, voglio tutte le righe della tabella tblEmployee, inclusi i record JAMES e RUSSELL. Quindi l’output sarà simile a;

Destra Join
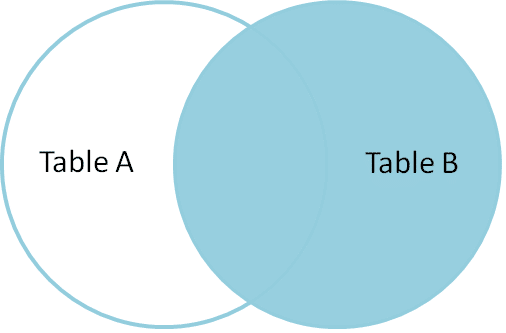
RIGHT Join restituisce tutte le righe corrispondenti e le righe non corrispondenti dalla tabella laterale destra.
Quindi, facciamo un esempio; Voglio tutte le righe delle tabelle giuste coinvolte nel join. Di conseguenza sarebbe come;

Pieno esterno join

OUTER join o FULL OUTER Join restituisce tutte le righe da entrambe le tabelle sinistra e destra, comprese le righe non corrispondenti dalle tabelle.
Quindi, facciamo un esempio; Voglio tutte le righe da entrambe le tabelle coinvolte nel join.

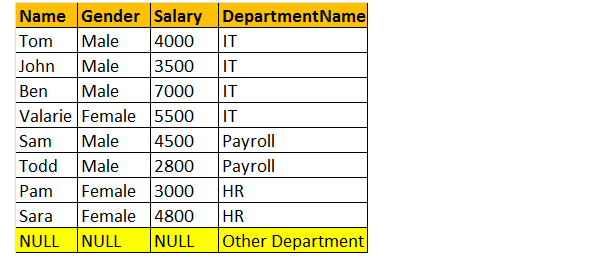
Cross join
Questo join fornisce il prodotto cartesiano delle 2 tabelle nella funzione join. Questo join non contiene la clausola ON.
Quindi, capiamo un esempio: Nella tabella tblEmployee abbiamo 10 righe e nella tabella tblDepartments abbiamo 4 righe. Quindi, un incrocio tra queste 2 tabelle produce 40 righe.

Come lavorare con Advance SQL Join
In questa sessione, spiegherò queste cose come segue;
- Join avanzati o intelligenti in SQL Server.
- Recupera i dati solo le righe non corrispondenti dalla tabella di sinistra.
- Recupera i dati solo le righe non corrispondenti dalla tabella di destra.
- Recupera i dati solo le righe non corrispondenti da entrambe le tabelle sinistra e destra.
Quindi, consideriamo entrambe le tabelle tblEmployee e tblDepartment.
Sinistra Join
Quindi, capiamo un esempio, voglio recuperare solo le righe non corrispondenti dalla tabella laterale sinistra.

Output: Infine, l’output sarà simile a questo;

Destra Join
Quindi, capiamo un esempio, voglio recuperare solo le righe non corrispondenti dalla tabella laterale destra.

Output: Infine, l’output sarà simile a questo;

Pieno esterno join
Quindi, capiamo un esempio, voglio recuperare solo le righe non corrispondenti dalla tabella laterale destra e dalla tabella laterale sinistra e le righe corrispondenti dovrebbero essere eliminate.

Output: Infine, l’output sarà simile a questo;
Tipi di chiavi in SQL
Una chiave in SQL è un campo di dati che identifica esclusivamente un record. In un’altra parola, una chiave è un insieme di colonne che viene utilizzato per identificare in modo univoco il record in una tabella.
- Crea relazioni tra due tabelle.
- Mantenere l’unicità e la responsabilità in una tabella.
- Mantenere i dati coerenti e validi in un database.
- Potrebbe aiutare nel recupero rapido dei dati facilitando gli indici sulle colonne.
SQL server contiene chiavi come segue;
- Candidato Tasto
- Chiave Primaria
- Unico Tasto
- Alternativo Tasto
- Composito Tasto
- Tasto Super
- Foreign Key
Prima di andare avanti, e si prega di dare un’occhiata all’immagine qui sotto;
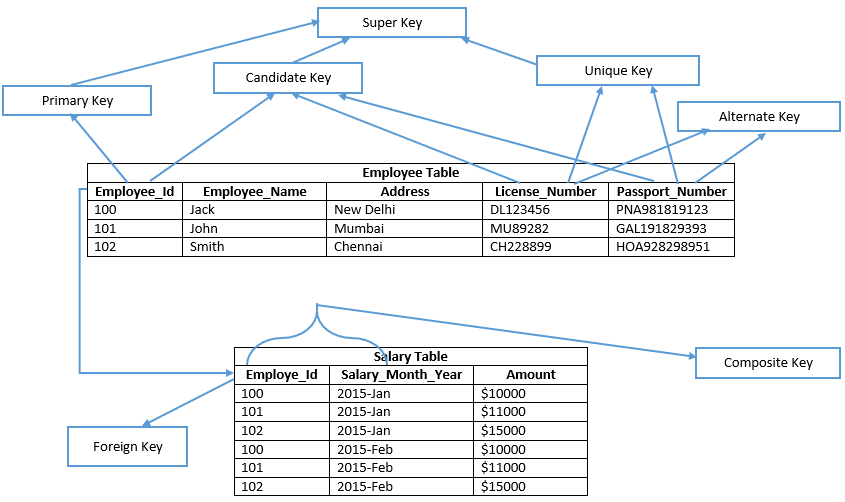
Capiamo ogni chiave nei dettagli
Chiave candidata
Una chiave candidata è una chiave di una tabella che può essere selezionata come chiave primaria della tabella e una tabella può avere più chiavi candidate, quindi una può essere selezionata come chiave primaria.
Esempio: Employee_Id, License_Number, & Passport_Number mostra le chiavi candidate
Chiave primaria
Una chiave primaria è simile alla chiave candidata selezionata della tabella per verificare ogni record di dati in modo univoco nella tabella. Pertanto, la chiave primaria non contiene alcun valore null in nessuna delle colonne di una tabella e mantiene anche valori univoci nella colonna. Nell’esempio dato, Employee_Id definisce la chiave primaria della tabella Employee. Di conseguenza, in SQL Server Management Studio, Primary key crea un indice cluster su una tabella heap per impostazione predefinita e una tabella che non consiste in un indice cluster è nota come tabella heap. Indica se definisce esplicitamente una chiave primaria non cluster in una tabella per tipo di indice.
Inoltre, una tabella può avere una sola chiave primaria e la chiave primaria può essere definita in SQL Server utilizzando istruzioni SQL:
- Dichiarazione TABELLA CRETA (al momento della creazione della tabella) – di conseguenza, il sistema definisce il nome della chiave primaria.
- ALTER TABLE statement (utilizzando un vincolo di chiave primaria) –di conseguenza, l’Utente stesso dichiara il nome del vincolo di chiave primaria.
Esempio: Employee_Id è una chiave primaria della tabella Employee.
Chiave univoca
Una chiave univoca è tanto quanto la chiave primaria e che non contiene valori duplicati nella colonna. Ha sotto le differenze nel confronto della chiave primaria:
- Permette un valore null nella colonna.
- Per impostazione predefinita, crea un indice non cluster e tabelle heap.
Chiave alternativa
La chiave alternativa è simile alla chiave candidata, ma non selezionata come chiave primaria della tabella.
Esempio: License_Number e Passport_Number sono chiavi alternative.
Chiave composita
Chiave composita (nota anche come chiave composta o chiave concatenata) è un gruppo di due o più colonne che identifica ciascuna riga di una tabella in modo univoco. Inoltre, una singola colonna di unità di una chiave composita potrebbe non essere in grado di verificare in modo univoco i record di dati. Di conseguenza, può essere anche chiave primaria o chiave candidata.
Esempio: nella tabella, Employee_Id & Salary_Month_Year entrambe le colonne verificano ogni riga in modo univoco nella tabella degli stipendi. Pertanto, Employee_Id o Salary_Month_Year colonna nella tabella, che non può identificare ogni riga in modo univoco. Possiamo creare una singola chiave primaria composita sulla tabella degli stipendi utilizzando i nomi delle colonne Employee_Id e Salary_Month_Year.
Super Key
Super key è un insieme di colonne su cui tutte le colonne della tabella dipendono funzionalmente. A causa del set di colonne che identifica in modo univoco ogni riga in una tabella. In un’altra parola, questa chiave contiene alcune colonne aggiuntive che non sono strettamente necessarie per verificare in modo univoco ogni riga della tabella. Sembra che la chiave primaria e le chiavi candidate siano superkeys minime o si può dire un sottoinsieme di superkeys.
Quindi, diamo un’occhiata all’esempio precedente, nella tabella Employee, column name Employee_Id è appena sufficiente per verificare in modo univoco qualsiasi riga della tabella. Quindi, qualsiasi insieme di una colonna dalla tabella Employee che contiene Employee_Id è una superchiave per la tabella Employee.
Ad esempio: {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id, Employee_Name, Address} ecc.
License_Number e Passport_Number sono il nome delle colonne, può anche verificare in modo univoco qualsiasi riga della tabella. Chiunque di column name set che consiste License_Number o Passport_Number o Employee_Id è una superchiave della tabella.
Ad esempio: {License_Number, Employee_Name, Address}, {License_Number, employee_number, Passport_Number}, {Passport_Number, Employee_Name}, {Passport_Number, Employee_Id} ecc.
Chiave esterna
Un FK definisce la relazione tra due o più tabelle alla volta. Una chiave primaria di una singola tabella si riferisce a una chiave esterna in un’altra tabella. Una chiave esterna può avere valori duplicati in una tabella e può anche avere valori null se il nome della colonna è definito per accettare ancora valori null.
Ad esempio il nome della colonna “Employee_Id” ( che è una chiave primaria della tabella dei dipendenti ) è una chiave esterna nella tabella degli stipendi.
Nota: chiavi come la chiave primaria e la chiave univoca creano indici con colonne di chiavi. Dati organizzati nel nodo struttura B-Tree (Albero bilanciato: i nodi Foglia sono tutti al livello diverso dal lato radice) in SQL Server. Quindi, l’indice non cluster crea una struttura separata dalla tabella di dati di base, ma l’indice cluster converte la tabella di dati di base dalla struttura heap in una struttura ad albero B.
Inoltre, l’indice cluster non crea una struttura separata a parte la tabella di base e questo è il motivo per cui possiamo creare un solo indice cluster su una tabella. Quindi, possiamo ordinare una tabella in un solo modo (potrebbe avere più colonne da ordinare ma l’ordinamento può essere fatto in un solo modo) che è l’ordine dell’indice cluster.
Come lavorare con le funzioni SQL
Una funzione è un programma di entità che viene memorizzato nel database di SQL Server o è possibile passare parametri o restituire un valore. Inoltre, saremo lieti di alcune funzioni incorporate molto utili e funzioni definite dall’utente.
Funzione Coalesce
Coalesce() : questa funzione restituisce solo il primo valore non NULLO. Quindi, facciamo un esempio sulla funzione Coalesce ().
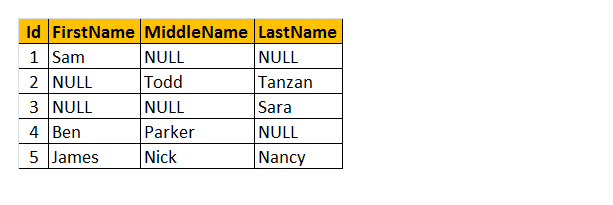 Comprendiamo la tabella come nome “Dipendente” sopra. Di conseguenza, è possibile vedere alcuni dei dipendenti hanno il loro nome mancante, alcuni hanno un secondo nome e alcuni di loro hanno Cognome mancante. Quindi, voglio restituire solo “Nome” del dipendente.
Comprendiamo la tabella come nome “Dipendente” sopra. Di conseguenza, è possibile vedere alcuni dei dipendenti hanno il loro nome mancante, alcuni hanno un secondo nome e alcuni di loro hanno Cognome mancante. Quindi, voglio restituire solo “Nome” del dipendente.
Come funzionerà? Capire, stiamo elaborando FirstName, MiddleName e LastName colonne come parametri per COALESCE () funzione. Quindi, questa funzione restituirà l’unico primo valore non nullo da 3 delle colonne.
Query: Seleziona Id, COALESCE (FirstName, MiddleName, LastName) COME Nome DA tblEmployee
Infine, l’output sarà simile a questo;
 LEFT() Function
LEFT() Function
LEFT(Character_Expression, Integer_Expression) – Questa funzione restituisce il numero specificato di caratteri dal lato sinistro dell’espressione del valore del carattere specificato.
Esempio: Selezionare SINISTRA(‘ABCDE’, 3)
Output: ABC
Funzione RIGHT ()
RIGHT(Character_Expression, Integer_Expression) – Questa funzione restituisce il numero specificato di caratteri dal lato destro dell’espressione del valore del carattere specificato.
Esempio: Seleziona A DESTRA(‘ABCDE’, 3)
Uscita: CDE
Funzione CHARINDEX ()
CHARINDEX(‘Expression_To_Find’, ‘Expression_To_Search’, ‘Start_Location’) – Questa funzione restituisce la posizione iniziale dell’espressione del valore specificato in una stringa secondaria di caratteri. Il parametro Start_Location è facoltativo.
Esempio: Capiamo, facciamo la posizione iniziale del carattere ‘ @ ‘ nella stringa di posta elettronica ‘[email protected]’.
Seleziona CHARINDEX ( ‘ @’, ‘[email protected]’,1)
Uscita: 5
SUBSTRING() Function
SUBSTRING(expression’, ‘Start’, ‘Length’) – Questa funzione restituisce substring (sottoparte della stringa), dall’espressione di valore data. Inoltre, quando si specifica la posizione iniziale utilizzando il parametro’ start ‘e l’altro numero di caratteri nella sottostringa utilizzando il parametro’ Length’. Tutti e tre i parametri sono obbligatori.
Esempio: voglio visualizzare solo una parte del dominio dell’e-mail data ‘[email protected]’.
Seleziona SOTTOSTRINGA (‘[email protected]’,6, 7)
Uscita: bbb.com
Di conseguenza, abbiamo fatto la codifica con la posizione di partenza e i parametri di lunghezza. Invece di codificare i parametri, possiamo recuperarli dinamicamente usando le funzioni stringa CHARINDEX() e LEN() come mostrato di seguito.
Esempio:
Selezionare SUBSTRING(‘[email protected]’,(CHARINDEX(‘@’, ‘[email protected]’) + 1), (LEN(‘[email protected]’) – CHARINDEX(‘@’,’[email protected]’)))
Output: bbb.com
Allora, facciamo un esempio reale con l’uso di LEN(), CHARINDEX() e SUBSTRING() funzioni. Pensiamo di avere una tabella come mostrato di seguito;
 Quindi, la domanda è Come troverai il numero totale di email per il loro dominio.
Quindi, la domanda è Come troverai il numero totale di email per il loro dominio.
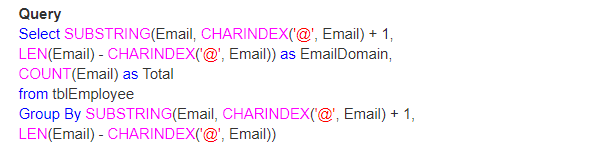
Output: Infine, l’output sarà simile a questo;
 REPLICATE() Funzione
REPLICATE() Funzione
REPLICATE (String_To_Be_Replicated, Number_Of_Times_To_Replicate) – Questa funzione ripete il punto dato della stringa, e per il numero specificato di volte.
Esempio: SELEZIONARE REPLICA (‘Pragim’, 3)
Output: Pragim Pragim Pragim
Parliamo di un esempio pratico di utilizzo della funzione REPLICATE (): Useremo questa tabella la maggior parte del tempo, e per il resto dei nostri esempi in questo articolo.
Quindi, supponiamo di avere una tabella come mostrato di seguito;
 Query: Select Nome, Cognome, SUBSTRING(e-Mail, 1, 2) + REPLICARE(‘*’,5) +
Query: Select Nome, Cognome, SUBSTRING(e-Mail, 1, 2) + REPLICARE(‘*’,5) +
SUBSTRING(e-Mail, CHARINDEX(‘@’,e-Mail), LEN(e – Mail) – CHARINDEX(‘@’,Email)+1) come e-Mail
da tblEmployee
facciamo email con 5 * (star) simboli. Quindi, l’output sarebbe come questo
 Funzione SPACE ()
Funzione SPACE ()
SPACE(Number_Of_Spaces) – Questa funzione restituisce l’unico numero di spazi e specificato dal termine argomento Number_Of_Spaces.
Esempio: La funzione SPACE(5), inserirà 5 spazi tra FirstName e LastName
Seleziona FirstName + SPACE(5) + LastName come FullName Da tblEmployee
 Funzione PATINDEX ()
Funzione PATINDEX ()
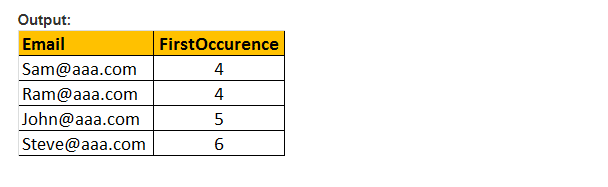
Questa funzione restituisce solo la posizione iniziale della prima occorrenza di un pattern in un’espressione efficace specificata. Quindi, ci vogliono solo due argomenti, e il modello da cercare e l’espressione. Pertanto, PATINDEX () è simile a CHARINDEX (). Con CHARINDEX() non possiamo usare i caratteri jolly, mentre PATINDEX () coinvolge questa funzionalità. Se il valore del modello specificato non viene trovato, PATINDEX () restituisce ZERO.
Esempio: Seleziona Email, PATINDEX (‘%aaa.com, E-mail’) come FirstOccurence da tblEmployee dove PATINDEX (‘%@aaa.com’, E-mail) > 0
 REPLACE () Funzione
REPLACE () Funzione
REPLACE(String_Expression, Pattern, Replacement_Value), Questa funzione sostituisce tutte le occorrenze posizione di un valore stringa specificato con un altro valore stringa.
Esempio: Tutte le stringhe .COM vengono sostituite con.NET
Seleziona Email, SOSTITUISCI(Email,’. com’,’.net’) come ConvertedEmail da tblEmployee
 Funzione STUFF ()
Funzione STUFF ()
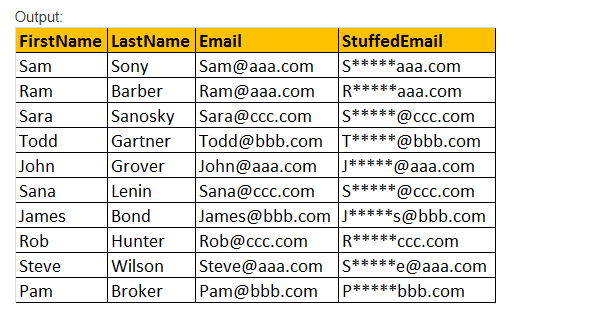
STUFF(Original_Expression, Start, Length, Replacement_expression), Questa funzione STUFF() inserisce solo Replacement_expression, che viene specificata nella posizione iniziale, insieme alla rimozione dei caratteri specificati utilizzando l’espressione del valore del parametro Length.
Esempio: Seleziona Nome, cognome, Email, ROBA(Email,2,3,’*****’) come StuffedEmail da tblEmployee.
 Funzione Data ora
Funzione Data ora
Sono disponibili diverse funzioni DateTime integrate nel database SQL Server. La maggior parte delle seguenti funzioni può essere utilizzata per ottenere la data e l’ora di sistema correnti e dove è installato SQL Server.
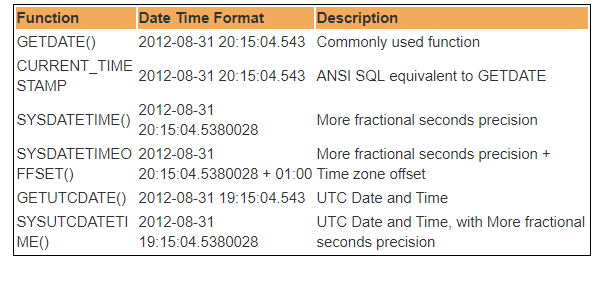 Quindi, UTC sta per Coordinated Universal Time, in base al quale il mondo regola gli orologi e i dati temporali. Degno. ci sono piccole differenze tra GMT e UTC, ma per gli scopi più comuni, UTC è sinonimo di GMT.
Quindi, UTC sta per Coordinated Universal Time, in base al quale il mondo regola gli orologi e i dati temporali. Degno. ci sono piccole differenze tra GMT e UTC, ma per gli scopi più comuni, UTC è sinonimo di GMT.
Quindi, prendiamo un altro esempio come mostrato di seguito;
isDate() Function
ISDATE() – Questa funzione controlla se l’unico valore dato, ed esiste una data valida, ora o DateTime. Quindi, restituirà 1 per il successo, 0 per il fallimento.
Esempio:
Seleziona ISDATE(‘PRAGIM’) — restituirà 0
Esempio:
Seleziona ISDATE (Getdate ()) – restituirà 1
Esempio:
Seleziona ISDATE(‘2018-01-20 21:02:04.167’) — restituisce 1
Nota: per i valori datetime2, IsDate restituisce ZERO.
Esempio:
Seleziona LA DATA ISDATE(‘2018-01-20 22:02:05.158.1918447’) — restituirà 0.
Funzione Day ()
Day() – Questa funzione restituisce solo il ‘numero del giorno del mese’ della data specificata.
Esempi:
Seleziona GIORNO (GETDATE ()) – Darà l’output per conto del numero del giorno del mese e in base al DateTime del sistema corrente.
Seleziona GIORNO (’01/14/2018′) – restituirà 14
Funzione Mese ()
Mese () – Questa funzione darà l’output per conto del’ Numero mese dell’anno ‘ della data specificata.
Esempi:
Seleziona mese (GETDATE ()) — Questa funzione darà l’output per conto del ‘Numero del mese dell’anno’ e in base alla data e all’ora del sistema corrente.
Selezionare il Mese(’05/14/2018) — si ritorna 5
Anno di Funzione ()
Anno() – Questa funzione permette di dare l’output, per conto della “numero dell’Anno’ della data
Esempi:
Selezionare l’Anno(GETDATE()) — Restituisce il numero dell’anno, e basato sulla data di sistema corrente
Selezionare l’Anno(’01/20/2018) — si ritorna 2018
DateName() la Funzione
DateName(DatePart, Data) Questa funzione restituisce solo una espressione di tipo stringa, e che rappresenta solo una parte di quella data. Queste funzioni consistono in 2 parametri.
Il primo parametro ‘DatePart’ specifica, la parte della data, che vogliamo. Il secondo parametro è la data reale, da cui vogliamo la parte della Data.
 Esempio 1:
Esempio 1:
Selezionare DATENAME(Giorno, ‘2017-04-20 13:47:47.350’) — si ritorna 20
Esempio 2:
Selezionare DATENAME(nei giorni FERIALI, ‘2017-04-20 13:47:47.350’) — tornerà giovedì
Esempio 3:
Selezionare DATENAME(MESE, ‘2017-04-20 13:47:47.350’) — si ritorna aprile
Quindi, diamo un esempio di utilizzo di alcune di queste funzioni DateTime. Considera la tabella tbloccupati.
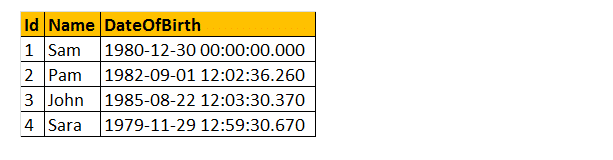 Esempio: voglio restituire tutti i nomi, DateOfBirth, Day, MonthNumber, MonthName e Year come mostrato di seguito.
Esempio: voglio restituire tutti i nomi, DateOfBirth, Day, MonthNumber, MonthName e Year come mostrato di seguito.
Seleziona Name, DateOfBirth,DateName(WEEKDAY, DateOfBirth) as, Month (DateOfBirth) as MonthNumber, DateName (MONTH, DateOfBirth) as, Year (DateOfBirth) as From tblEmployees

DatePart() Function
DatePart(DatePart, Date) – Questa funzione fornisce un numero intero che rappresenta il valore DatePart specificato. Per lo più la funzione è simile alla funzione DateName (). DateName () restituisce solo il valore nvarchar, mentre DatePart () restituisce solo un valore intero. I valori dei parametri DatePart validi sono mostrati di seguito.
Esempi:
Seleziona DATEPART(giorno della settimana, ‘2012-08-30 19:45:31.793’) — restituirà 5
Seleziona NOME DATA (giorno della settimana, ‘2012-08-30 19:45:31.793’) — restituirà Thursday
DateAdd() Function
DATEADD (datepart, NumberToAdd, date) – Questa funzione SQL fornisce solo DateTime, dopo il termine specificato NumberToAdd, e al datepart specificato della data specificata.
Esempi:
Selezionare DateAdd(GIORNO, 10, ‘2018-01-20 19:45:31.793’) — si ritorna ‘2018-01-30 19:45:31.793’
Selezionare DateAdd(GIORNO, -10, ‘2012-08-30 19:45:31.793’)– si ritorna ‘2018-01-20 19:45:31.793’
DatedDiff() la Funzione
DATEDIFF(datepart, datainizio, datafine) – Questa funzione fornisce il conteggio del datepart specificato confini varcati tra specificato datainizio e datafine.
Esempi:
Selezionare la funzione DATEDIFF(MESE, ’11/30/2005′,’01/31/2006′) — si ritorna 2
Selezionare la funzione DATEDIFF(GIORNO, ’11/30/2005′,’01/31/2006′) — si ritorna 62
Allora, facciamo un esempio, supponiamo di avere una tabella di seguito riportata;
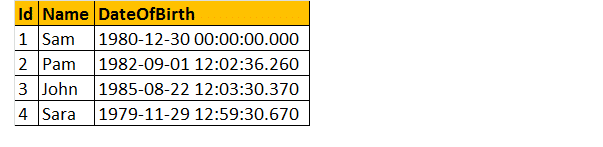
Così, Scrivere una query per sapere l’età di una persona, quando la data di nascita.

Infine, l’output apparirà come mostrato di seguito.
Funzioni Cast() e Convert ()
Per convertire un singolo tipo di dati in un altro, è possibile utilizzare le funzioni CAST e CONVERT.
Sintassi della funzione CAST e CONVERT:
CAST ( espressione COME data_type)
CONVERT ( data_type , expression)
Inoltre, come puoi vedere, la funzione CONVERT() ha un valore di parametro di stile opzionale, mentre la funzione CAST() manca di questa funzionalità.
Quindi, facciamo un esempio, prendiamo una tabella riportata di seguito;
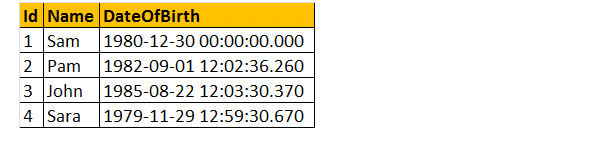 Le seguenti 2 query convertono il tipo di dati DateTime di DateOfBirth in NVARCHAR. La prima query utilizza la funzione CAST() e la seconda utilizza la funzione CONVERT (). Infine, l’output è esattamente lo stesso per entrambe le query come mostrato di seguito.
Le seguenti 2 query convertono il tipo di dati DateTime di DateOfBirth in NVARCHAR. La prima query utilizza la funzione CAST() e la seconda utilizza la funzione CONVERT (). Infine, l’output è esattamente lo stesso per entrambe le query come mostrato di seguito.
Seleziona ID, Nome DateOfBirth, Cast(DateOfBirth come nvarchar) come ConvertedDOB da tblemployees.
Seleziona ID, Nome DateOfBirth, Converti(DateOfBirth come nvarchar) come ConvertedDOB da tblemployees.
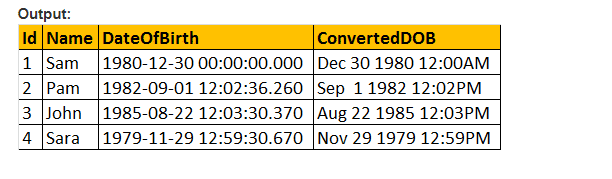 Quindi, facciamo il parametro di stile del valore della funzione CONVERT() e formattare la data come vorremmo. Quindi, stiamo usando 103 come passaggio dell’argomento per il parametro style nella query riportata di seguito e che formatta la data come gg/mm/aa.
Quindi, facciamo il parametro di stile del valore della funzione CONVERT() e formattare la data come vorremmo. Quindi, stiamo usando 103 come passaggio dell’argomento per il parametro style nella query riportata di seguito e che formatta la data come gg/mm/aa.
Seleziona ID, Name, DateOfBirth, Convert (nvarchar, DateOFBirth, 103) come ConvertedDOB da tblEmployees.
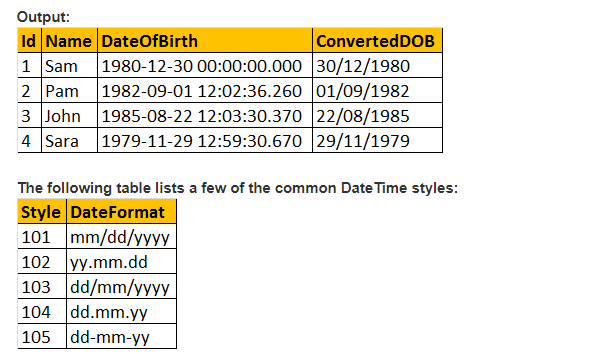
Quindi, diamo un’occhiata all’esempio pratico con l’aiuto della funzione CAST ();
Supponiamo di avere una tabella di registrazione qui sotto come;
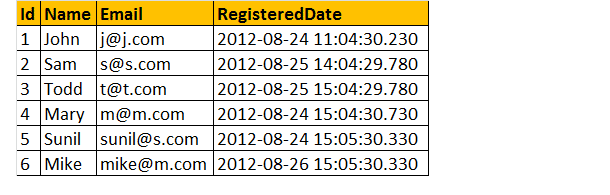 Ora, troviamo il numero totale di registrazione per giorno.
Ora, troviamo il numero totale di registrazione per giorno.
Esempio: Select CAST(RegisteredDate as DATE) as RegistrationDate, COUNT (Id) as TotalRegistrations tblRegistrations Group By CAST(RegisteredDate as DATE)
Output: Infine l’output apparirà come ;
Funzioni Definite dall’Utente
Ci sono 3 tipi di Funzioni Definite dall’Utente in SQL Server che come
- funzioni Scalari
- Inline funzioni con valori di tabella
- con istruzioni multiple funzioni con valori di tabella
Funzioni Scalari
funzioni Scalari variare dei parametri che possono o non possono avere parametri, e dà sempre una sola (scalare) valore in uscita. Pertanto, il valore restituito può essere di qualsiasi formato di tipo di dati ad eccezione del valore di testo, testo, immagine, cursore e timestamp.
Esempio: Quindi, sviluppiamo una funzione che calcola e restituisce l’età di una persona in uscita. Di conseguenza, per confrontare l’età che abbiamo richiesto per, data di nascita. Quindi, passiamo la data di nascita come parametro. Pertanto, la funzione AGE () restituirà un numero intero e accetterà il parametro date.
 Selezionare dbo.Età (dbo.Età(“10/08/1982”).
Selezionare dbo.Età (dbo.Età(“10/08/1982”).
Quindi, prendiamo un esempio pratico nella tabella riportata di seguito come segue;
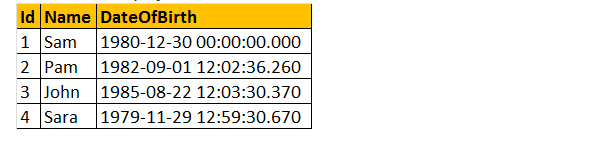
Le funzioni definite dall’utente scalari possono essere utilizzate nella clausola Select come mostrato di seguito.
Seleziona Nome, Data di nascita, dbo.Età (DateOfBirth) come Età da tblEmployees
 Per lo più visualizza il testo della funzione usa sp_helptext FunctionName.
Per lo più visualizza il testo della funzione usa sp_helptext FunctionName.
Funzioni a valori di tabella in linea
Una funzione a valori di tabella in linea restituisce sempre una tabella come output.
Quindi, facciamo un esempio qui sotto; Creare una funzione che restituisce i DIPENDENTI per GENERE.
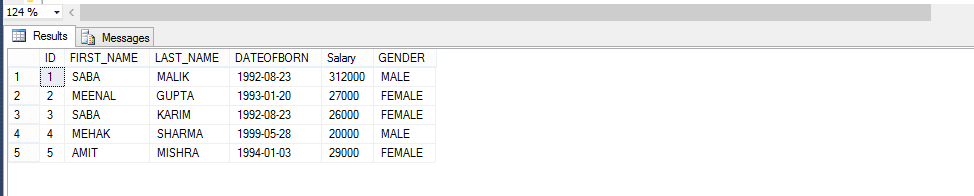
a causa del metodo di chiamata per la funzione definita dall’utente,
Select * From Fn_EMPLOYEEbyGender(‘male’)
MULTI-STATEMENT TABLE VALUED FUNCTION
Multi-statement table-valued functions are much more similar to Inline Table-valued functions and with some differences. Quindi, diamo un’occhiata a un esempio, quindi notiamo le differenze.
Tabella dipendenti
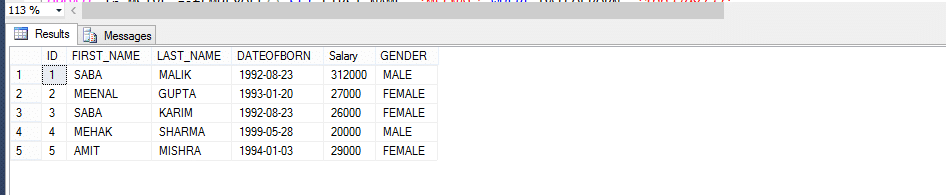
Funzione di valore della tabella multi-statement (MSTVF):
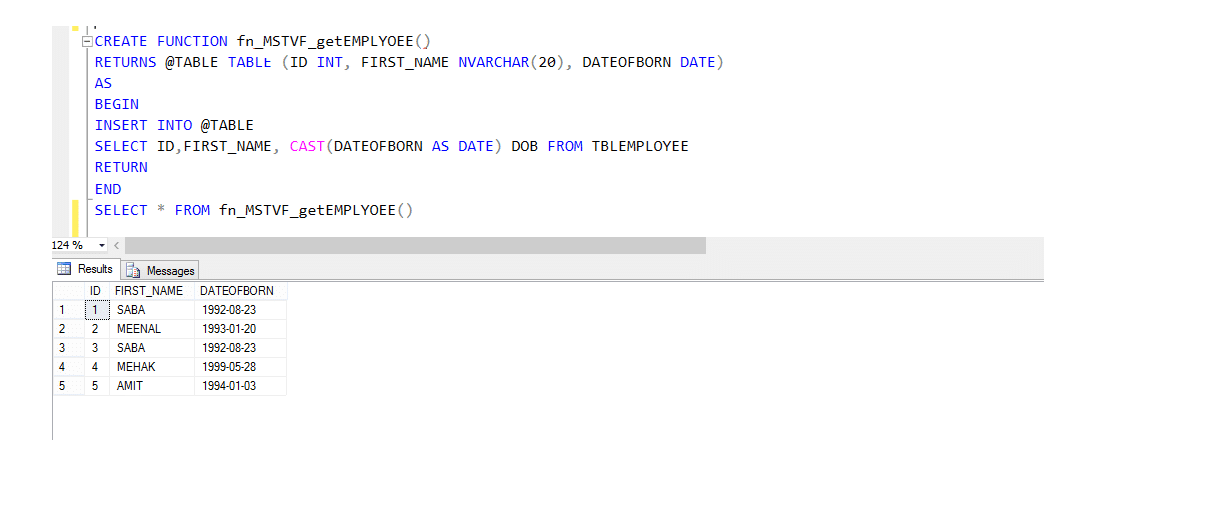 A causa del metodo di chiamata per la funzione vthe Multi-statement Table Valued:
A causa del metodo di chiamata per la funzione vthe Multi-statement Table Valued:
Seleziona * da fn_MSTVF_GetEmployees ()
Conclusione
I JOIN sono termini molto comprensivi per i principianti durante la fase di apprendimento dei comandi SQL. Di conseguenza, nell’intervista, l’intervistatore chiede almeno una domanda riguarda i join SQL e le funzioni. Quindi, in questo post, sto cercando di semplificare le cose per i nuovi studenti SQL e rendere più facile capire i join SQL. Inoltre, le funzioni in SQL, molte persone hanno difficoltà a comprendere la funzione di lavoro effettiva. Poiché SQL contiene molti dati in blocco in diversi nomi di database e tabelle. Una funzione è un programma memorizzato nel database SQL Server in cui è possibile passare i parametri e restituire un valore. Quindi, ho dato qualche termine più utile sul funzionamento delle Funzioni.
- Informazioni su
- Ultimi messaggi

- Differenza Tra SQL e MySQL – aprile 14, 2020
- Come lavorare con Subquery in Data Mining – 23 Marzo 2018
- Come utilizzare funzionalità del browser di Javascript? – Marzo 9, 2018
