Salt la sectiune
- SQL Introducere
- Cum de a lucra cu Sql se alătură
- asociere interioară
- stânga Alătură-te
- dreapta se alăture
- complet exterior se alăture
- cross join
- cum să lucrați cu advance SQL se alătură
- stânga Alăturați-vă
- complet exterior se alăture
- tipuri de chei în SQL
- cheie candidat
- cheie primară
- cheie unică
- cheie alternativă
- cheie compozită
- Super Key
- cheie străină
- cum se lucrează cu funcțiile SQL
- LEFT() funcția
- right() funcție
- CHARINDEX() Function
- subșir() funcție
- REPLICATE () funcția
- spațiu() funcția
- Patindex() funcție
- REPLACE () funcția
- STUFF () funcția
- funcție Dată Oră
- Isdate () funcția
- lună() funcție
- Year() funcția
- Datename() funcția
- DatePart () funcția
- DateAdd() funcția
- DatedDiff () funcția
- Cast() și Convert() funcții
- funcții definite de utilizator
- funcții scalare
- funcții cu valoare de tabel în linie
- funcție cu valoare de tabel multi-declarație
- concluzie
SQL Introducere
SQL standuri pentru Structured Query Language. Este utilizat în principal pentru manipularea datelor, modificarea datelor și recuperarea datelor. Acest lucru vine în jurul cu sistemul de gestionare a bazelor de date relaționale (RDBMS).
vom afla despre mai multe caracteristici avansate ale SQL cum ar fi se alătură și funcții.
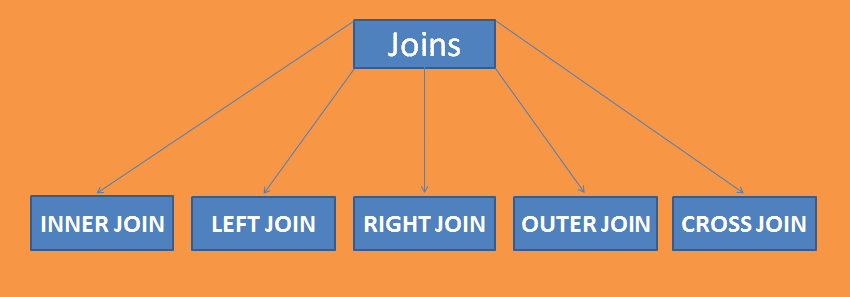
Cum de a lucra cu Sql se alătură
un mijloc simplu se alăture este de a combina două sau mai multe tabele într-o bază de date dată. Un join funcționează pe o entitate comună a două tabele.
un join conține 5 sub-Join-uri care, ca; inner join, Outer Join, Left Join, Right Join și Cross Join.
asociere interioară
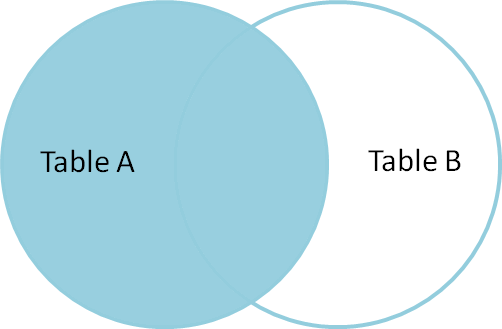
o asociere interioară este utilizată pentru a selecta înregistrări care conțin valori comune sau potrivite în ambele tabele (Tabelul A și Tabelul B). Non-potrivire sunt eliminate.
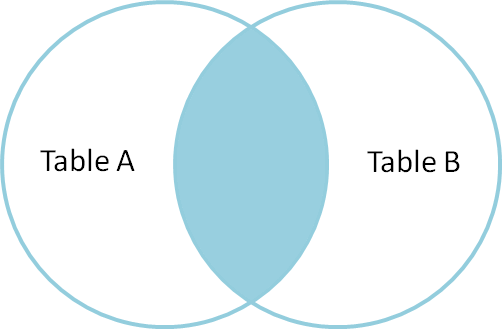
deci, să înțelegem tipul de îmbinări și cu exemple comune și diferențele dintre ele.
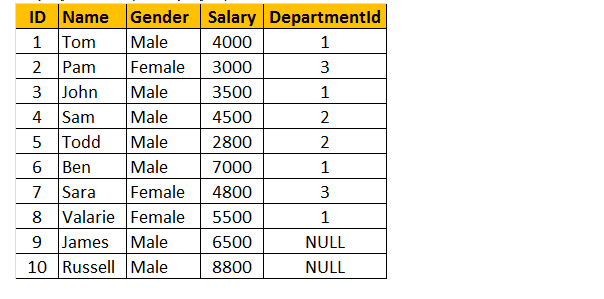
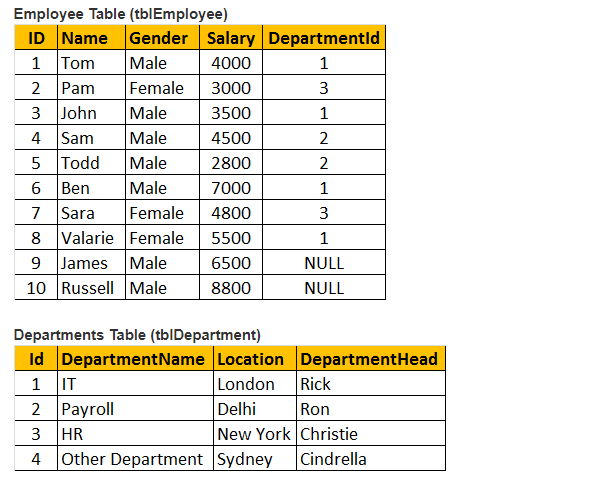
Tabelul 1: Tabelul angajaților (tblEmployee)
Tabelul 2: Tabelul departamentelor (tbldepartamente)
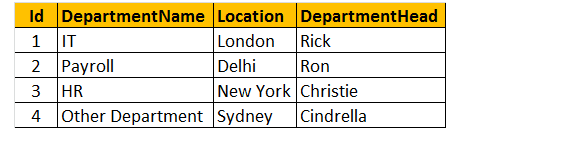
deci, să creăm tabelul tbldepartamente pentru executarea unui program.

Acum, introduceți înregistrări în tabelul tbldepartamente.

să creăm un alt tabel tblemangajat pentru executarea unui program.

deci, introduceți înregistrări în tabelul tblEmployee.

prin urmare, o formulă generală pentru se alătură.

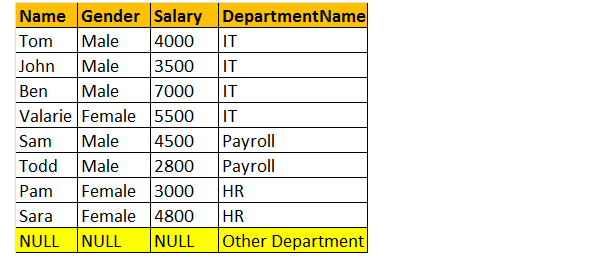
pentru a face o interogare pentru a găsi numele, sexul, salariul și DepartmentName din ambele tabele tblEmployee și tblDepartments.

notă: JOIN sau inner JOIN înseamnă același lucru. Dar întotdeauna mai bine să utilizați inner JOIN, iar acest lucru specifică intenția dumneavoastră în mod explicit.
ieșire: Acum tabelul final de ieșire va arăta astfel;
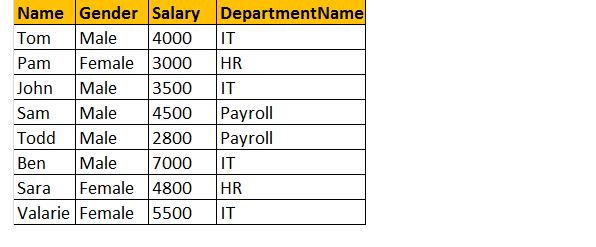
dacă te uiți la fereastra de ieșire, avem doar 8 rânduri, dar în tabelul tblEmployee, avem 10 rânduri. Nu am primit înregistrările lui JAMES și RUSSELL. Acest lucru se datorează faptului că DEPARTMENTID, în tabelul tblEmployee este nul pentru acești doi angajați și nu se potrivește cu coloana ID-ul lor în tabelul tblDepartments.
deci, într-o declarație finală, Inner Joins returnează doar rândurile potrivite din ambele tabele și rândurile care nu se potrivesc sunt eliminate datorită subinterogării sale.
stânga Alătură-te
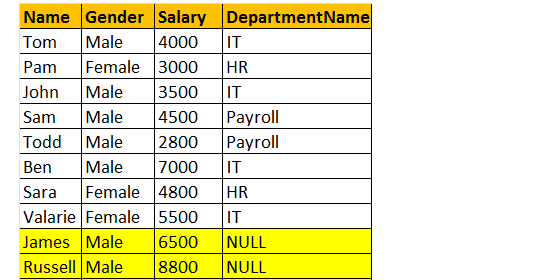
Left Join returnează toate rândurile potrivite și rândurile care nu se potrivesc din tabelul din partea stângă. În plus, îmbinarea interioară și îmbinarea stângă sunt utilizate pe scară largă reciproc.
deci, să luăm un exemplu, Vreau toate rândurile din tabelul tblEmployee, inclusiv JAMES și RUSSELL records. Apoi, ieșirea va arăta ca;

dreapta se alăture
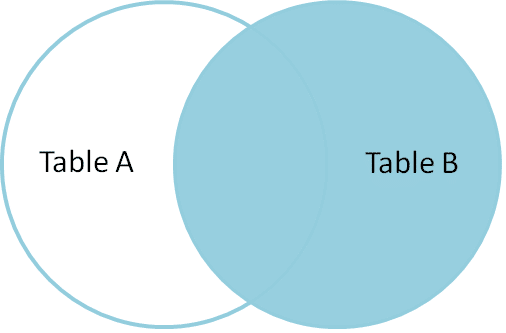
right Join returnează toate rândurile potrivite și rândurile care nu se potrivesc din tabelul din partea dreaptă.
deci, să luăm un exemplu; Vreau toate rândurile din tabelele din dreapta implicate în join. Ca rezultat ar fi ca;

complet exterior se alăture

outer join sau Full OUTER Join returnează toate rândurile din tabelele din stânga și din dreapta și inclusiv rândurile care nu se potrivesc din tabele.
deci, să luăm un exemplu; Vreau toate rândurile din ambele tabele implicate în join.

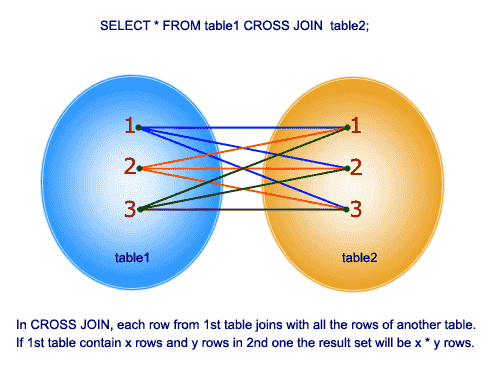
cross join
acest join oferă produsul cartezian al celor 2 tabele din funcția join. Acest join nu conține pe clauza.
deci, să înțelegem un exemplu: În tabelul tblEmployee avem 10 rânduri, iar în tabelul tblDepartments avem 4 rânduri. Deci, o cruce se unește între aceste 2 tabele produce 40 de rânduri.

cum să lucrați cu advance SQL se alătură
în această sesiune, voi explica aceste lucruri după cum urmează;
- avansat sau inteligent se alătură în SQL Server.
- preluați date numai rândurile care nu se potrivesc din tabelul din stânga.
- preluați date numai rândurile care nu se potrivesc din tabelul din dreapta.
- preluați date numai rândurile care nu se potrivesc atât din tabelele din stânga, cât și din dreapta.
deci, să luăm în considerare atât tabelele tblEmployee, cât și tblDepartment.
stânga Alăturați-vă
deci, să înțelegem un exemplu, Vreau să recuperez doar rândurile care nu se potrivesc din tabelul din partea stângă.

ieșire: în cele din urmă, ieșirea va arăta astfel;

dreapta se alăture
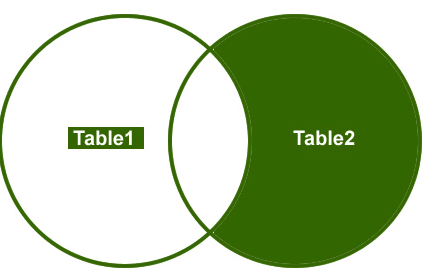
deci, să înțelegem un exemplu, Vreau să recuperez doar rândurile care nu se potrivesc din tabelul din partea dreaptă.

ieșire: în cele din urmă, ieșirea va arăta astfel;

complet exterior se alăture
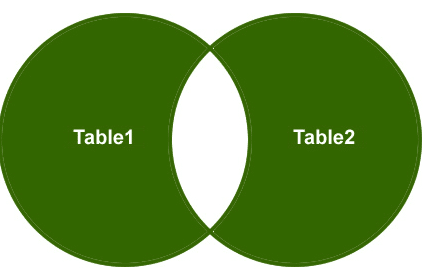
deci, să înțelegem un exemplu, Vreau să recuperez doar rândurile care nu se potrivesc din tabelul din partea dreaptă și tabelul din partea stângă și rândurile potrivite ar trebui eliminate.

ieșire: în cele din urmă, ieșirea va arăta astfel;
tipuri de chei în SQL
o cheie în SQL este un câmp de date care identifică exclusiv o înregistrare. Într-un alt cuvânt, o cheie este un set de coloane care este utilizat pentru a identifica în mod unic înregistrarea într-un tabel.
- creați relații între două tabele.
- mențineți unicitatea și răspunderea într-un tabel.
- păstrați date consistente și valide într-o bază de date.
- ar putea ajuta la recuperarea rapidă a datelor prin facilitarea indexurilor pe coloană(coloane).
un server SQL conține chei după cum urmează;
- cheie candidat
- cheie primară
- cheie unică
- cheie alternativă
- cheie compozită
- Super cheie
- cheie străină
înainte de a merge mai departe, și vă rugăm să aruncați o privire la imaginea de mai jos;
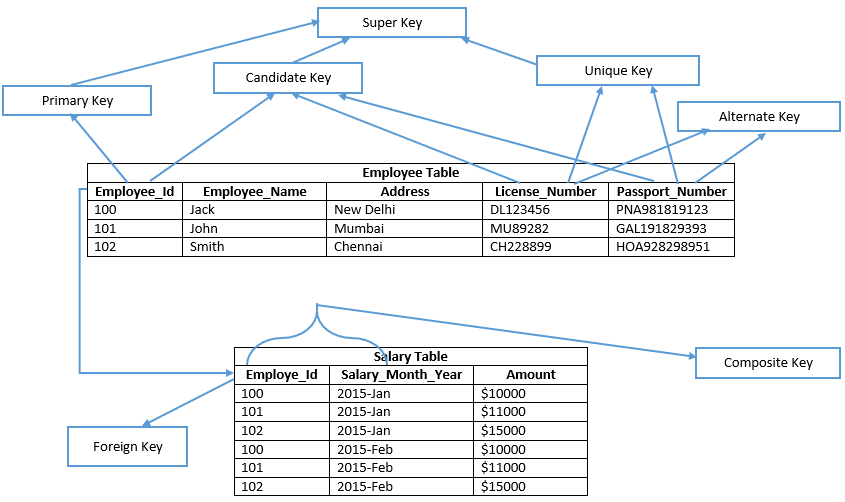
să înțelegem fiecare cheie în detalii
cheie candidat
o cheie candidat este o cheie a unui tabel care poate fi selectat ca o cheie primară a tabelului și un tabel poate avea mai multe chei candidat, prin urmare, unul poate fi selectat ca o cheie primară.
exemplu: Employee_Id, License_Number,& Passport_Number afișează cheile candidate
cheie primară
o cheie primară este similară cu cheia candidată selectată din tabel pentru a verifica Fiecare înregistrare de date în mod unic în tabel. Prin urmare, cheia primară nu conține nicio valoare nulă în niciuna dintre coloanele unui tabel și păstrează, de asemenea, valori unice în coloană. În exemplul dat, Employee_Id definește cheia primară a tabelului angajaților. În consecință, în SQL Server Management Studio, cheia primară creează în mod implicit un index pus în cluster pe un tabel heap și un tabel care nu constă dintr-un index pus în cluster este cunoscut sub numele de tabel heap. Dacă definește o cheie primară nonclustered pe un tabel în funcție de tipul de index în mod explicit.
în plus, un tabel poate avea doar o cheie primară și cheie primară pot fi definite în SQL Server folosind instrucțiuni SQL:
- declarația tabelului Creta (la momentul creării tabelului) – ca rezultat, sistemul definește numele cheii primare.
- ALTER TABLE (folosind o constrângere cheie primară) –ca rezultat, utilizatorul însuși declară numele constrângerii cheie primară.
exemplu: Employee_Id este o cheie primară a tabelului angajaților.
cheie unică
o cheie unică este la fel ca cheia primară și care nu conține valori duplicate în coloană. Are diferențe sub Compararea cheii primare:
- acesta permite o valoare nulă în coloană.
- în mod implicit, se creează un index non-grupate și tabele heap.
cheie alternativă
cheia alternativă este similară cu cheia candidată, dar nu este selectată ca cheie primară a tabelului.
exemplu: License_Number și Passport_Number sunt chei alternative.
cheie compozită
cheie compozită (cunoscută și sub numele de cheie compusă sau cheie concatenată) este un grup de două sau mai multe coloane care identifică fiecare rând al unui tabel în mod unic. În plus, este posibil ca o singură coloană unitate a unei chei compozite să nu poată verifica în mod unic înregistrările de date. Drept urmare, poate fi fie cheie primară, fie cheie candidată.
exemplu: în tabel, Employee_Id & Salary_Month_Year ambele coloane verifică fiecare rând în mod unic în tabelul salarial. Prin urmare, coloana Employee_Id sau Salary_Month_Year din tabel, care nu poate identifica fiecare rând în mod unic. Putem crea o singură cheie primară compozită pe masa salarială utilizând numele coloanelor Employee_Id și Salary_Month_Year.
Super Key
super key este un set de coloane pe care toate coloanele tabelului sunt dependente funcțional. Datorită setului de coloane care identifică în mod unic fiecare rând dintr-un tabel. Într-un alt cuvânt, această cheie conține câteva coloane suplimentare care nu sunt strict necesare pentru a verifica în mod unic fiecare rând din tabel. Se pare că cheile primare și cheile candidate sunt superkeys minime sau puteți spune un subset de superkeys.
deci, să ne uităm la exemplul de mai sus, în tabelul angajat, numele coloanei Employee_Id este greu suficientă pentru a verifica în mod unic Orice rând al tabelului. Deci, că orice set de o coloană din tabelul angajat care conține Employee_Id este un superkey pentru tabelul angajat.
de exemplu: {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id,Employee_Name, adresa} etc.
License_Number și Passport_Number sunt numele coloanelor, de asemenea, poate verifica în mod unic Orice rând al tabelului. Oricine din setul de nume de coloană care constă în License_Number sau Passport_Number sau Employee_Id este o superkey a tabelului.
de exemplu: {License_Number, Employee_Name, Address}, {License_Number, Employee_Name, Passport_Number}, {Passport_Number, Employee_number, Address, License_Number}, {Passport_Number, Employee_Id} etc.
cheie străină
un FK definește relația dintre două sau mai multe tabele la un moment dat. O cheie primară a unui singur tabel se referă la o cheie străină într-un alt tabel. O cheie străină poate avea valori duplicate într-un tabel și, de asemenea, poate avea valori nule dacă numele coloanei este definit pentru a accepta încă valori nule.
de exemplu, numele coloanei „Employee_Id” ( care este o cheie primară a tabelului angajaților ) este o cheie străină în tabelul salariilor.
notă: tastele precum cheia primară și cheia unică creează indici cu coloane de chei. Datele organizate în nodul structurii arborelui B (Arborele echilibrat: nodurile frunzelor sunt toate la nivel diferit de partea rădăcină) în SQL Server. Prin urmare, indicele Nonclustered creează o structură separată de tabelul de date de bază, dar indicele grupat convertește tabelul de date de bază din structura heap într-o structură B-arbore.
în plus, indicele grupat nu creează o structură separată în afară de tabelul de bază și acesta este motivul pentru care putem crea un singur index grupat pe un tabel. Prin urmare, putem sorta un tabel într-un singur mod (poate avea mai multe coloane de sortat, dar sortarea se poate face într-un singur mod), care este ordinea indexului grupat.
cum se lucrează cu funcțiile SQL
o funcție este un program de entitate care este stocat în baza de date SQL Server fie puteți trece parametrii în sau returnați o valoare. În plus, vom aștepta cu nerăbdare câteva funcții încorporate foarte utile și funcții definite de utilizator.
funcția Coalesce
Coalesce() : această funcție returnează numai valoarea Non null. Deci, să luăm un exemplu peste Coalesce () funcție.
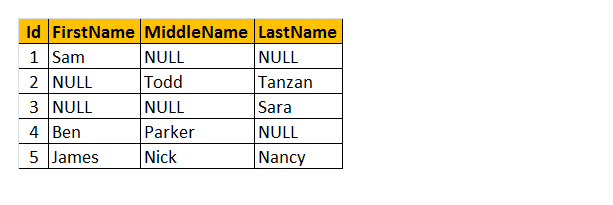 să înțelegem tabelul ca nume ‘angajat’ de mai sus. Drept urmare, puteți vedea că unii dintre angajați au prenumele lipsă, unii au un nume de mijloc și unii dintre ei au numele de familie lipsă. Deci, vreau să returnez doar „numele” angajatului.
să înțelegem tabelul ca nume ‘angajat’ de mai sus. Drept urmare, puteți vedea că unii dintre angajați au prenumele lipsă, unii au un nume de mijloc și unii dintre ei au numele de familie lipsă. Deci, vreau să returnez doar „numele” angajatului.
cum va funcționa? Înțelegeți, procesăm coloanele FirstName, MiddleName și LastName ca parametri pentru funcția COALESCE (). Prin urmare, această funcție va returna singura primă valoare non-nulă din 3 coloane.
interogare: selectați Id, COALESCE (FirstName, MiddleName, LastName) ca nume de la tblEmployee
în cele din urmă, ieșirea va arăta astfel;
 LEFT() funcția
LEFT() funcția
LEFT(Expresie_ caracter, Expresie_ Integer) – această funcție returnează numărul specificat de caractere din partea stângă a expresiei valorii caracterului dat.
exemplu: Selectați stânga (‘ABCDE’, 3)
ieșire: ABC
right() funcție
RIGHT(Expresie_ caracter, Expresie_ Integer) – această funcție returnează numărul specificat de caractere din partea dreaptă a expresiei valorii caracterului dat.
exemplu: selectați dreapta (‘ABCDE’, 3)
ieșire: CDE
CHARINDEX() Function
CHARINDEX(‘Expression_To_Find’, ‘Expression_To_Search’, ‘Start_Location’) – această funcție returnează poziția de pornire a expresiei valorii specificate într-un șir de caractere sub. Parametrul Start_Location este opțional.
exemplu: să înțelegem, vom face poziția de pornire a ‘@’ Caracter în șirul de e-mail ‘[email protected]’.
selectați CHARINDEX (‘@’, ‘[email protected]’,1)
ieșire: 5
subșir() funcție
subșir(expression’, ‘Start’, ‘Length’) – această funcție returnează subșir (subpartea șirului), din expresia valorii date. În plus, când specificați poziția de pornire folosind parametrul ‘ start ‘și celălalt număr de caractere din subșir folosind parametrul’ lungime’. Toți cei trei parametri sunt obligatorii.
exemplu :Vreau să afișez doar o parte din domeniul e-mailului dat ‘[email protected]’.
selectați subșir(‘[email protected]’,6, 7)
ieșire: bbb.com
Ca rezultat, am făcut codificarea cu poziția de pornire și parametrii de lungime. În loc de hardcoding parametrii, le putem prelua dinamic folosind CHARINDEX () și Len () funcții șir așa cum se arată mai jos.
exemplu:
selectați subșir(‘[email protected]’, (CHARINDEX ( ‘ @ ‘ , ‘[email protected]’) + 1), (LEN(‘[email protected]’) – CHARINDEX (‘@’, ‘[email protected]’)))
ieșire: bbb.com
deci, să luăm un exemplu real cu utilizarea funcțiilor LEN(), CHARINDEX() și subșir (). Să credem că avem un tabel așa cum se arată mai jos;
 deci, întrebarea este cum veți găsi numărul total de e-mailuri după domeniul lor.
deci, întrebarea este cum veți găsi numărul total de e-mailuri după domeniul lor.
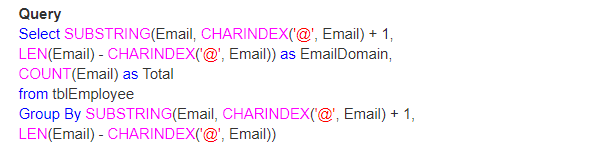
ieșire: în cele din urmă, ieșirea va arăta astfel;
 REPLICATE () funcția
REPLICATE () funcția
REPLICATE(String_To_Be_Replicated, Number_Of_Times_To_Replicate) – această funcție repetă punctul dat al șirului și pentru numărul specificat de ori.
exemplu: selectați replică (‘Pragim’, 3)
ieșire: Pragim Pragim Pragim
să vorbim despre un exemplu practic de utilizare a funcției REPLICATE (): Vom folosi acest tabel de cele mai multe ori și pentru restul exemplelor noastre din acest articol.
deci, să presupunem că avem un tabel așa cum se arată mai jos;
 interogare: selectați prenume, prenume, subșir(e-mail, 1, 2) + replică(‘*’,5) +
interogare: selectați prenume, prenume, subșir(e-mail, 1, 2) + replică(‘*’,5) +
subșir (e – mail, CHARINDEX(‘@’,e-mail), LEN(e-mail) – CHARINDEX(‘@’,e-mail)+1) ca e-mail
de la tblEmployee
să facem e-mail cu simboluri 5 * (stea). Apoi, ieșirea ar fi ca aceasta
 spațiu() funcția
spațiu() funcția
spațiu(Number_Of_Spaces) – această funcție returnează singurul număr de spații, și specificate de argumentul Number_Of_Spaces termen.
exemplu: funcția SPACE(5), va introduce 5 spații între FirstName și LastName
selectați FirstName + SPACE(5) + LastName ca nume complet din tblEmployee
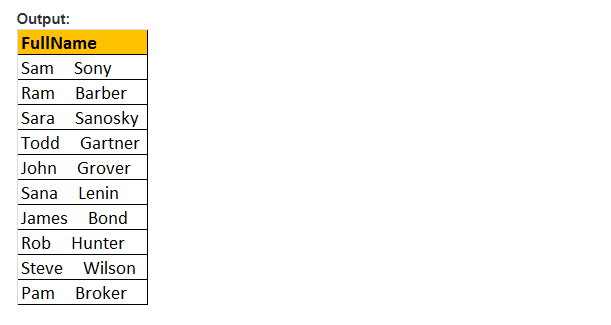 Patindex() funcție
Patindex() funcție
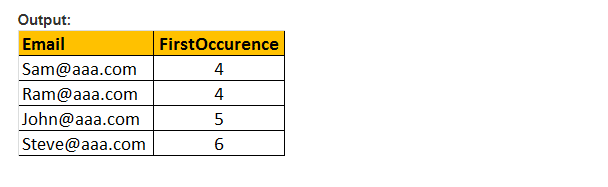
această funcție returnează numai locația de pornire a primei apariții a unui model într-o expresie eficientă specificată. Prin urmare, este nevoie de doar două argumente, și modelul care trebuie căutat și expresia. Prin urmare, PATINDEX() este similar cu CHARINDEX(). Cu CHARINDEX() nu putem folosi metacaractere, în timp ce PATINDEX () implică această capacitate. Dacă valoarea de model specificată nu este găsită, PATINDEX () returnează ZERO.
exemplu: selectați E-mail, PATINDEX (‘%aaa.com, e-mail’) ca FirstOccurence de la tblEmployee unde PATINDEX(‘%@AAA.com’, E-mail) > 0
 REPLACE () funcția
REPLACE () funcția
REPLACE(String_Expression, Pattern, Replacement_Value), această funcție înlocuiește toate aparițiile poziția unei valori șir specificat cu o altă valoare șir.
exemplu: toate șirurile .COM sunt înlocuite cu.NET
selectați E-mail, înlocuiți(e-mail,’. com’,’.net’) ca ConvertedEmail de la tblEmployee
 STUFF () funcția
STUFF () funcția
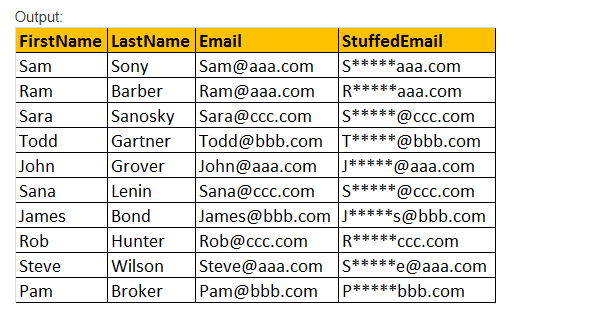
STUFF(Expresie_original, Start, lungime, Replacement_expression), această funcție STUFF () inserează numai Replacement_expression, care este specificat în poziția de pornire, împreună cu eliminarea caracterele specificate folosind Expresie valoare parametru lungime.
exemplu: selectați FirstName, lastName, Email, STUFF(Email,2,3,’*****’) ca StuffedEmail de la tblEmployee.
 funcție Dată Oră
funcție Dată Oră
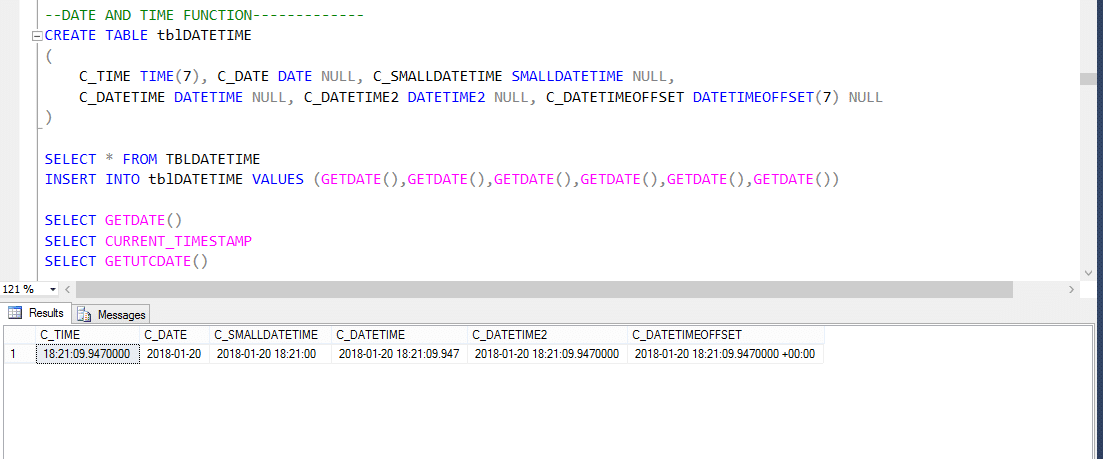
există mai multe funcții DateTime încorporate disponibile în baza de date SQL Server. Majoritatea următoarelor funcții pot fi utilizate pentru a obține data și ora curentă a sistemului și unde aveți SQL server instalat.
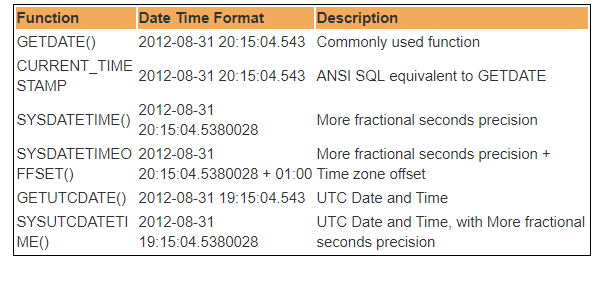 prin urmare, UTC reprezintă timpul Universal coordonat, pe baza căruia lumea reglementează ceasurile și datele de timp. Demn de remarcat. există diferențe minore între GMT și UTC, dar pentru cele mai comune scopuri, UTC este sinonim cu GMT.
prin urmare, UTC reprezintă timpul Universal coordonat, pe baza căruia lumea reglementează ceasurile și datele de timp. Demn de remarcat. există diferențe minore între GMT și UTC, dar pentru cele mai comune scopuri, UTC este sinonim cu GMT.
deci, să luăm un alt exemplu, așa cum se arată mai jos;
Isdate () funcția
ISDATE () – această funcție verifică dacă singura valoare dată, și există o dată validă, timp, sau DateTime. Apoi, se va întoarce 1 pentru succes, 0 pentru eșec.
Example:
Select ISDATE — ‘PRAGIM’) – se va întoarce 0
Example:
Select ISDATE (Getdate ()) — se va întoarce1
Example:
Select ISDATE(‘2018-01-20 21:02:04.167’) — acesta va întoarce 1
notă: pentru valorile datetime2, IsDate returnează ZERO.
exemplu:
selectați ISDATE(‘2018-01-20 22:02:05.158.1918447’) — se va întoarce 0.
Day() funcția
Day() – această funcție returnează doar ‘numărul zilei lunii’ de la data dată.
Exemple:
Selectați ziua(GETDATE()) — va da ieșirea în numele numărului zilei lunii și pe baza DateTime-ului curent al sistemului.
Selectați ziua(’01/14/2018′) — se va întoarce 14
lună() funcție
lună() – această funcție va da rezultatul în numele ‘numărul lunii anului’ de la data dată.
Exemple:
Selectați luna(GETDATE()) — această funcție va da rezultatul în numele ‘numărul lunii anului’ și pe baza datei și orei sistemului curent.
Select Month(’05/14/2018) — se va întoarce 5
Year() funcția
Year() – această funcție va da de ieșire în numele ‘numărul an’ de data dată
Exemple:
Select Year(GETDATE()) — returnează numărul an, și pe baza data sistemului curent
selectați Anul(’01/20/2018) — se va întoarce 2018
Datename() funcția
Datename(datepart, Data) – această funcție returnează doar o expresie șir, și care reprezintă doar o parte din data dată. Aceste funcții constau în 2 parametri.
primul parametru ‘DatePart’ specifică partea de dată pe care o dorim. Al doilea parametru este data reală, de la care dorim partea datei.
 Exemplul 1:
Exemplul 1:
selectați numele de Dată(Zi, ‘2017-04-20 13:47:47.350’) — se va întoarce 20
Exemplul 2:
selectați numele de dată (zi lucrătoare, ‘2017-04-20 13:47:47.350’) — acesta va reveni joi
Exemplul 3:
selectați numele de dată (luna, ‘2017-04-20 13:47:47.350’) — se va întoarce aprilie
deci, să luăm un exemplu folosind unele dintre aceste funcții DateTime. Luați în considerare tabelul tblangajați.
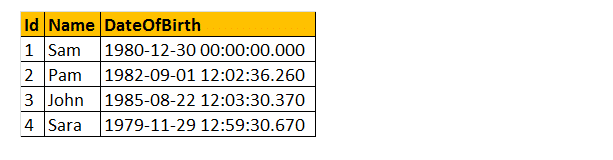 exemplu: Vreau să returnez toate numele, data nașterii, Ziua, numărul lunii, numele lunii și Anul așa cum se arată mai jos.
exemplu: Vreau să returnez toate numele, data nașterii, Ziua, numărul lunii, numele lunii și Anul așa cum se arată mai jos.
selectați Nume, DateOfBirth, DateName(WEEKDAY,DateOfBirth) as , Month(DateOfBirth) as MonthNumber, DateName (MONTH, DateOfBirth) as, Year (DateOfBirth) as From tblEmployees

DatePart () funcția
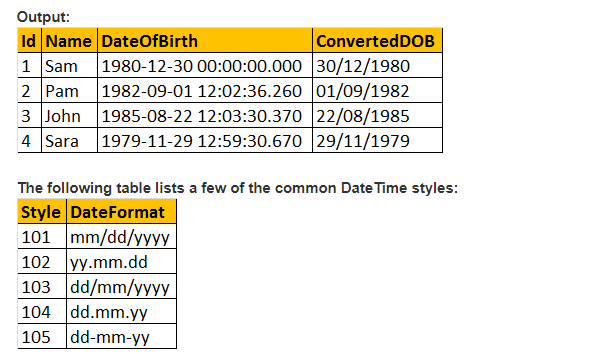
DatePart(DatePart, Data) – această funcție oferă un număr întreg reprezentând valoarea DatePart specificată. Cea mai mare parte funcția este similară cu DateName() funcție. DateName() returnează numai valoarea nvarchar, în timp ce DatePart () returnează doar o valoare întreagă. Valorile valide ale parametrilor DatePart sunt prezentate mai jos.
Exemple:
selectați DATEPART(zi lucrătoare, ‘2012-08-30 19:45:31.793’) — se va întoarce 5
selectați numele de dată (zi lucrătoare, ‘2012-08-30 19:45:31.793’) — se va întoarce joi
DateAdd() funcția
DATEADD (datepart, NumberToAdd, date) – Această funcție SQL dă numai DateTime, după termenul specificat NumberToAdd, și la datepart specificat de data dată.
Exemple:
selectați Dataadaugă (zi, 10, ‘2018-01-20 19:45:31.793’) — se va întoarce ‘2018-01-30 19:45:31.793’
selectați DateAdd (zi, -10, ‘2012-08-30 19:45:31.793’)– se va întoarce ‘2018-01-20 19:45:31.793’
DatedDiff () funcția
DATEDIFF (datepart, startdate, enddate) – această funcție dă numărul de limitele datepart specificate trecut între startdate specificate și enddate.
Exemple:
selecteaza data (luna, ’11/30/2005′,’01/31/2006′) — se va întoarce 2
selectați DATEDIFF (zi, ’11/30/2005′,’01/31/2006′) — se va întoarce 62
deci, să luăm un exemplu, să presupunem că avem un tabel de mai jos;
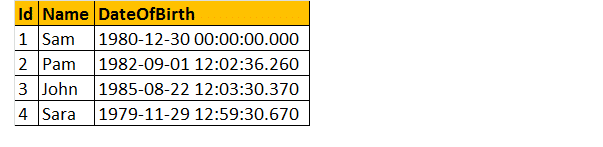
deci, scrieți o interogare pentru a afla vârsta unei persoane, când este dată data nașterii.

în cele din urmă, ieșirea va arăta așa cum se arată mai jos.
Cast() și Convert() funcții
pentru a converti un singur tip de date unitate la alta, CAST și converti funcții pot fi utilizate.
sintaxa funcției CAST și CONVERT:
CAST ( expression AS data_type)
CONVERT ( data_type , expression)
în plus, după cum puteți vedea că funcția CONVERT() are o valoare opțională a parametrului style, în timp ce funcția CAST() nu are această capacitate.
deci, să luăm un exemplu, vom lua un tabel de mai jos;
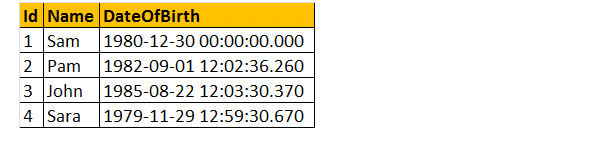 următoarele 2 interogări convertesc Dateofbirth DateTime datatype la NVARCHAR. Prima interogare utilizează funcția CAST (), iar cea de-a doua utilizează funcția CONVERT (). În cele din urmă, ieșirea este exact aceeași pentru ambele interogări așa cum se arată mai jos.
următoarele 2 interogări convertesc Dateofbirth DateTime datatype la NVARCHAR. Prima interogare utilizează funcția CAST (), iar cea de-a doua utilizează funcția CONVERT (). În cele din urmă, ieșirea este exact aceeași pentru ambele interogări așa cum se arată mai jos.
Selectați ID, Nume DateOfBirth, Cast(DateOfBirth ca nvarchar) ca ConvertedDOB de la tblemployees.
Selectați ID, Nume DateOfBirth, Convert(DateOfBirth ca nvarchar) ca ConvertedDOB de la tblemployees.
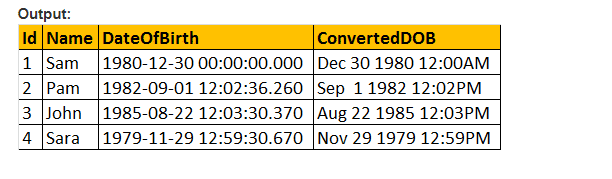 deci, să facem parametrul de stil al valorii funcției CONVERT() și să formatăm Data așa cum ne-ar plăcea. Deci, folosim 103 ca trecerea parametrului argument pentru stil în interogarea de mai jos și care formatează data ca zz/ll/aa.
deci, să facem parametrul de stil al valorii funcției CONVERT() și să formatăm Data așa cum ne-ar plăcea. Deci, folosim 103 ca trecerea parametrului argument pentru stil în interogarea de mai jos și care formatează data ca zz/ll/aa.
Selectați ID, Nume, DateOfBirth, Convert (nvarchar, DateOFBirth, 103) ca ConvertedDOB de la tblEmployees.
deci, să aruncăm o privire la exemplu practic cu ajutorul CAST () funcția;
să presupunem că avem un tabel de înregistrare de mai jos ca;
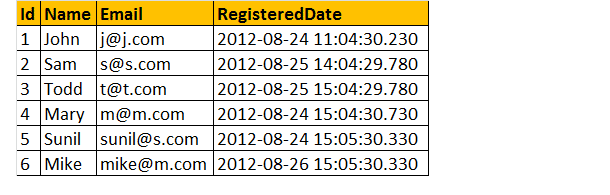 acum, să găsim numărul total de înregistrare pe zi.
acum, să găsim numărul total de înregistrare pe zi.
exemplu: selectați CAST (RegisteredDate as DATE) as RegistrationDate, COUNT (Id) as TotalRegistrations Tblregistrations Group By CAST(RegisteredDate as DATE)
Output: în cele din urmă ieșirea va arăta ca ;
funcții definite de utilizator
există 3 tipuri de funcții definite de utilizator în SQL Server care ca
- funcții scalare
- funcții cu valoare de tabel Inline
- funcții cu valoare de tabel Multistatement
funcții scalare
funcțiile scalare variază în parametri care pot avea sau nu parametri și oferă întotdeauna o singură valoare (scalară) în ieșire. Prin urmare, valoarea returnată poate fi de orice format de tip de date, cu excepția valorii textului, a textului, a imaginii, a cursorului și a marcajului de timp.
exemplu: Deci, să dezvoltăm o funcție care calculează și returnează vârsta unei persoane în ieșire. În consecință, pentru a compara vârsta pe care am cerut-o, data nașterii. Deci, să trecem data nașterii ca parametru. Prin urmare, funcția AGE() va returna un număr întreg și va accepta parametrul date.
 selectați dbo.Vârstă( dbo.Vârsta (’10/08/1982′).
selectați dbo.Vârstă( dbo.Vârsta (’10/08/1982′).
deci, să luăm un exemplu practic în tabelul de mai jos, după cum urmează;
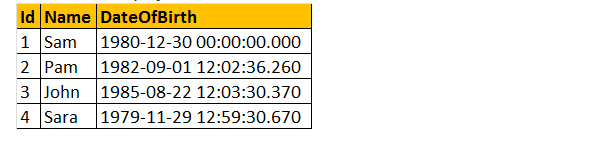
funcțiile scalare definite de utilizator pot fi utilizate în clauza Select așa cum se arată mai jos.
selectați numele, data nașterii, dbo.Vârsta (DateOfBirth) ca vârstă de la tblEmployees
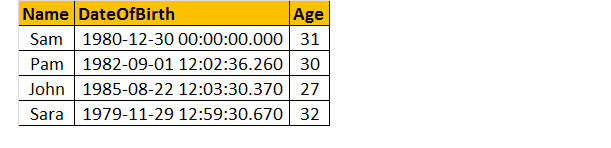 cea mai mare parte a vizualiza textul funcției utilizare Sp_helptext FunctionName.
cea mai mare parte a vizualiza textul funcției utilizare Sp_helptext FunctionName.
funcții cu valoare de tabel în linie
o funcție cu valoare de tabel în linie returnează întotdeauna un tabel ca ieșire.
deci, să luăm un exemplu de mai jos; Creați o funcție care returnează angajații după sex.
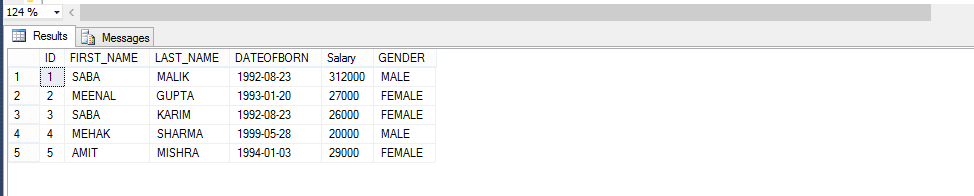
datorită metodei de apelare pentru funcția definită de utilizator,
selectați * din fn_employeebygender(‘male’)
funcție cu valoare de tabel multi-declarație
funcții cu valoare de tabel Multi-declarație sunt mult mai asemănătoare cu funcțiile cu valoare de tabel Inline și cu unele diferențe. Deci, să aruncăm o privire la un exemplu și apoi să notăm diferențele.
tabelul angajaților
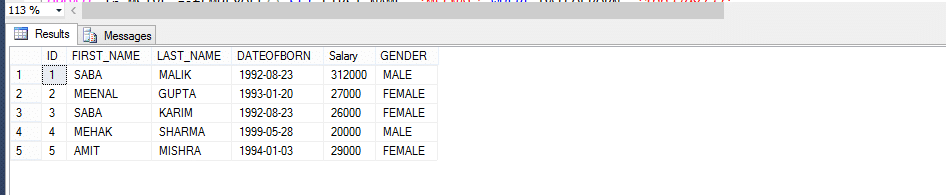
Multi-declarație tabelul evaluate funcție(MSTVF):
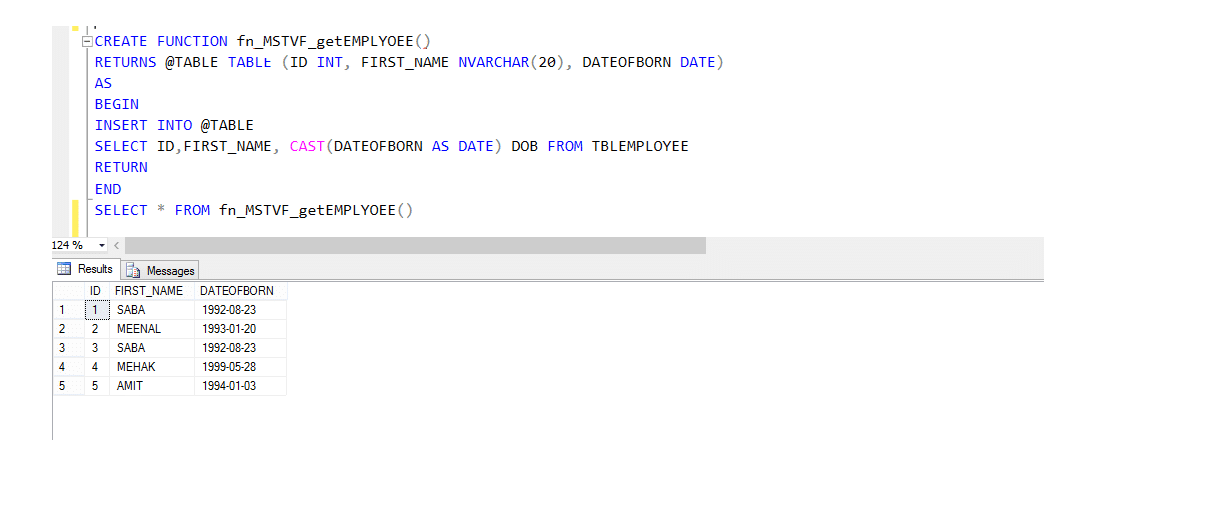 datorită metodei de apelare pentru funcția Vthe Multi-declarație de masă evaluate:
datorită metodei de apelare pentru funcția Vthe Multi-declarație de masă evaluate:
selectați * din fn_MSTVF_GetEmployees ()
concluzie
se alătură este foarte mult termen înțelegere pentru începători în timpul fazei de învățare a comenzilor SQL. În consecință, în interviu, intervievatorul pune cel puțin o întrebare este despre SQL se alătură, și funcții. Deci, în acest post, am încercat să simplifice lucrurile pentru noi cursanți SQL și să-l ușor de înțeles SQL se alătură. În plus, funcțiile din SQL, o mulțime de oameni au probleme să înțeleagă funcția de lucru reală. Deoarece SQL conține o mulțime de date în bloc în diferite baze de date și nume de tabele. O funcție este un program stocat în baza de date SQL Server unde puteți trece parametrii și returna o valoare. Deci, am dat un termen mai util despre funcționarea funcțiilor.
- despre
- ultimele postări

- diferența dintre SQL și MySQL-14 aprilie 2020
- cum se lucrează cu Subquery în data Mining – 23 martie 2018
- cum se utilizează caracteristicile browserului Javascript? – Martie 9, 2018
