Hoppa till innehåll
- SQL introduktion
- hur man arbetar med SQL Joins
- inre koppling
- vänster gå med
- höger gå med
- Full yttre koppling
- Cross join
- hur man arbetar med Advance SQL Joins
- vänster gå med
- Full yttre koppling
- typer av nycklar i SQL
- kandidatnyckel
- primärnyckel
- unik nyckel
- alternativ Nyckel
- sammansatt Nyckel
- Super Key
- utländsk nyckel
- hur man arbetar med SQL-funktioner
- vänster() funktion
- höger () funktion
- CHARINDEX() funktion
- SUBSTRING() funktion
- REPLICATE () funktion
- SPACE() funktion
- PATINDEX () funktion
- REPLACE () funktion
- STUFF () funktion
- Datumtidsfunktion
- isDate () funktion
- månad () funktion
- år() funktion
- Datename() funktion
- DatePart () funktion
- DateAdd() funktion
- DatedDiff () – funktionen
- Cast() och Convert() funktioner
- användardefinierade funktioner
- skalära funktioner
- inline-tabellvärderade funktioner
- Multi-STATEMENT Table VALUED FUNCTION
- slutsats
SQL introduktion
SQL står för Structured Query Language. Det används främst för datamanipulation, data modifiering och datahämtning. Detta kommer runt med relationsdatabashanteringssystem (RDBMS).
vi kommer att lära oss mer avancerade funktioner i SQL som kopplingar och funktioner.
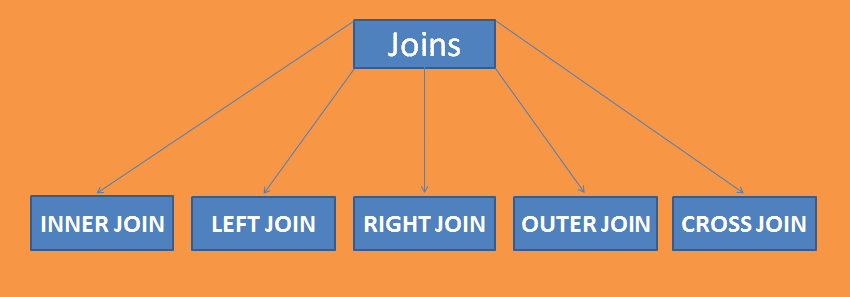
hur man arbetar med SQL Joins
ett enkelt kopplingsmedel är att kombinera två eller flera tabeller i en given databas. En koppling verk på en gemensam enhet av två tabeller.
en koppling innehåller 5 sub-joins som as; Inner join, Outer Join, Left Join, Right Join och Cross Join.
inre koppling
en inre koppling används för att välja poster som innehåller vanliga eller matchande värden i båda tabellerna (tabell A och Tabell B). Icke-matchning elimineras.
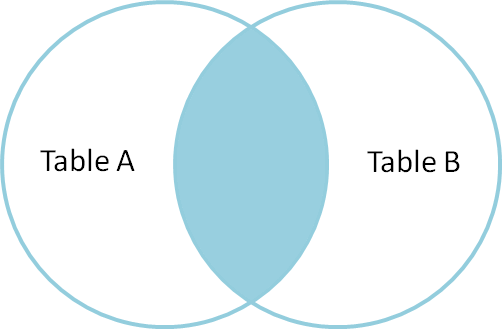
så, låt oss förstå typen av anslutningar, och med vanliga exempel och skillnaderna mellan dem.
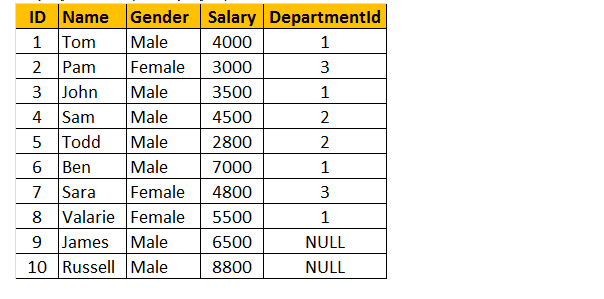
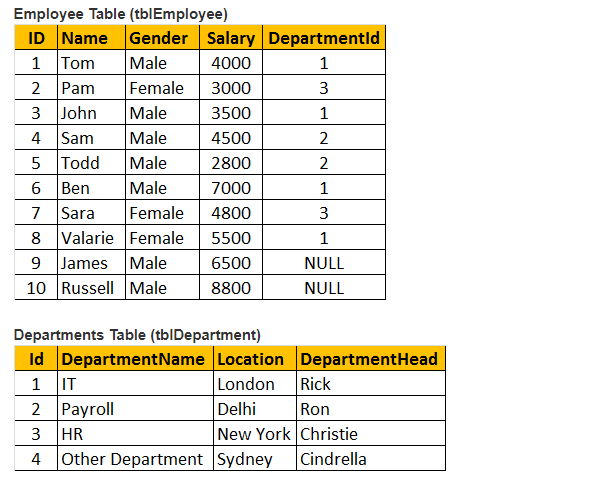
Tabell 1: anställd tabell (tblEmployee)
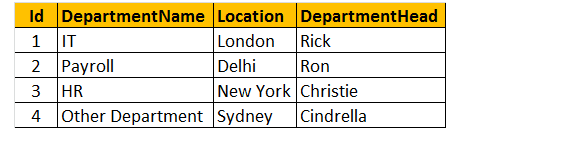
Tabell 2: Avdelningstabell (tblDepartments)
så, låt oss skapa tabell tbdavdelningar för utförande av ett program.

Lägg nu in poster i tabell tblDepartments.

låt oss skapa en annan tabell tblanställd för körning av ett program.

så sätt in poster i tabell tblanställd.

därför en allmän formel för sammanfogningar.

för att göra en fråga för att hitta namn, kön, lön och Avdelningsnamn från både tabellerna tblEmployee och tblDepartments.

OBS: JOIN eller INNER JOIN betyder detsamma. Men alltid bättre att använda INNER JOIN, och detta anger din avsikt uttryckligen.
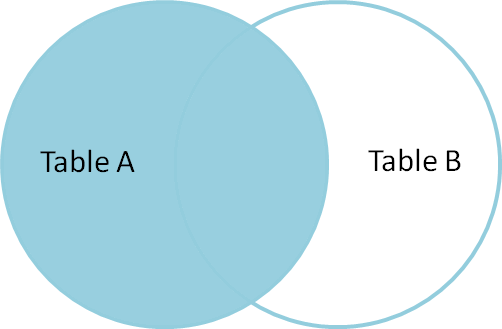
utgång: nu kommer den slutliga utmatningstabellen att se ut så här;
om du tittar på utmatningsfönstret har vi bara 8 rader, men i tabellen tblanställd har vi 10 rader. Vi fick inte JAMES och RUSSELL records. Detta beror på att avdelningen, i tabell tblEmployee är NULL för dessa två anställda och matchar inte med deras ID-kolumn i tabell tblDepartments.
så, i ett slutligt uttalande, returnerar inre kopplingar endast matchande rader från båda tabellerna och icke-matchande rader elimineras på grund av dess underfråga.
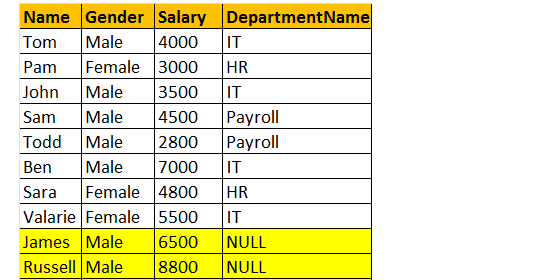
vänster gå med
Left Join returnerar alla matchande rader och icke-matchande rader från den vänstra sidobordet. För övrigt, Inner join och Left join används i stor utsträckning varandra.
så, låt oss ta ett exempel, Jag vill ha alla rader från tblemployee-tabellen, inklusive JAMES och RUSSELL records. Då kommer utmatningen att se ut som;

höger gå med
right Join returnerar alla matchande rader och icke-matchande rader från den högra sidobordet.
så, låt oss ta ett exempel; Jag vill ha alla rader från höger tabeller som är involverade i kopplingen. Som ett resultat skulle det vara som;

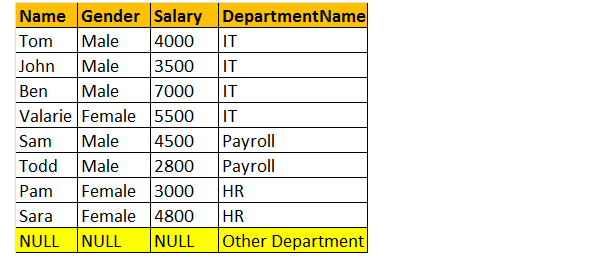
Full yttre koppling

OUTER join eller FULL OUTER Join returnerar alla rader från både vänster och höger tabeller, och inklusive icke-matchande rader från tabellerna.
så, låt oss ta ett exempel; Jag vill ha alla rader från båda tabellerna som är involverade i kopplingen.

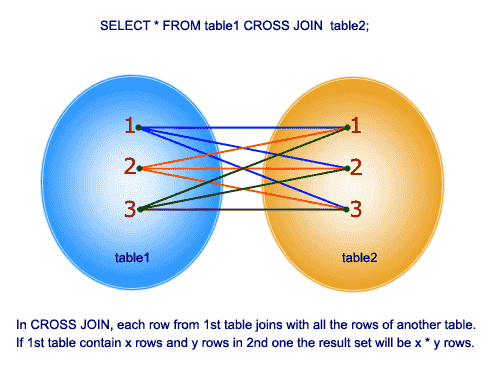
Cross join
denna koppling ger den kartesiska produkten av de 2 tabellerna i join-funktionen. Denna koppling innehåller inte på klausul.
så, låt oss förstå ett exempel: I tabellen tbl employee har vi 10 rader och i tabellen tblDepartments har vi 4 rader. Så, ett kors mellan dessa 2 tabeller ger 40 rader.

hur man arbetar med Advance SQL Joins
i den här sessionen kommer jag att förklara dessa saker enligt följande;
- avancerade eller intelligenta anslutningar i SQL Server.
- hämta data endast de icke-matchande raderna från den vänstra tabellen.
- hämta data endast de icke-matchande raderna från den högra tabellen.
- hämta data endast de icke-matchande raderna från både vänster och höger tabeller.
så, låt oss överväga både tabellerna tblEmployee och tblDepartment.
vänster gå med
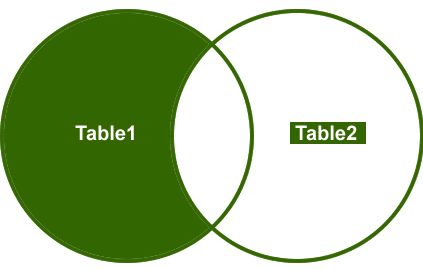
så, låt oss förstå ett exempel, Jag vill bara hämta de icke-matchande raderna från vänster sidobord.

utgång: slutligen kommer utgången att se ut så här;

höger gå med
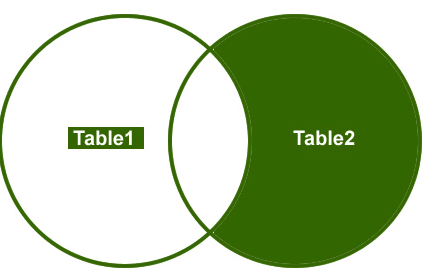
så, låt oss förstå ett exempel, Jag vill bara hämta de icke-matchande raderna från höger sida.

utgång: slutligen kommer utgången att se ut så här;

Full yttre koppling
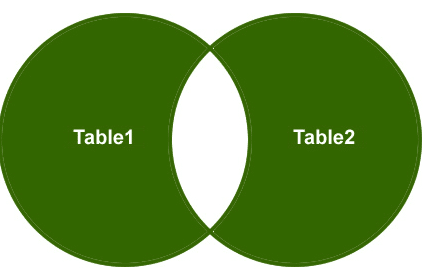
så, låt oss förstå ett exempel, Jag vill bara hämta de icke-matchande raderna från höger sidobord och vänster sidobord och matchande rader ska elimineras.

utgång: slutligen kommer utmatningen att se ut så här;
typer av nycklar i SQL
en nyckel i SQL är ett datafält som uteslutande identifierar en post. I ett annat ord är en nyckel en uppsättning kolumner som används för att unikt identifiera posten i en tabell.
- skapa relationer mellan två tabeller.
- behåll unikhet och ansvar i en tabell.
- Håll konsekventa och giltiga data i en databas.
- kan hjälpa till med snabb datahämtning genom att underlätta index på kolumner.
en SQL server innehåller nycklar enligt följande;
- kandidatnyckel
- primärnyckel
- unik nyckel
- alternativ Nyckel
- sammansatt Nyckel
- Supernyckel
- utländsk nyckel
innan du går vidare, och ta en titt på bilden nedan;
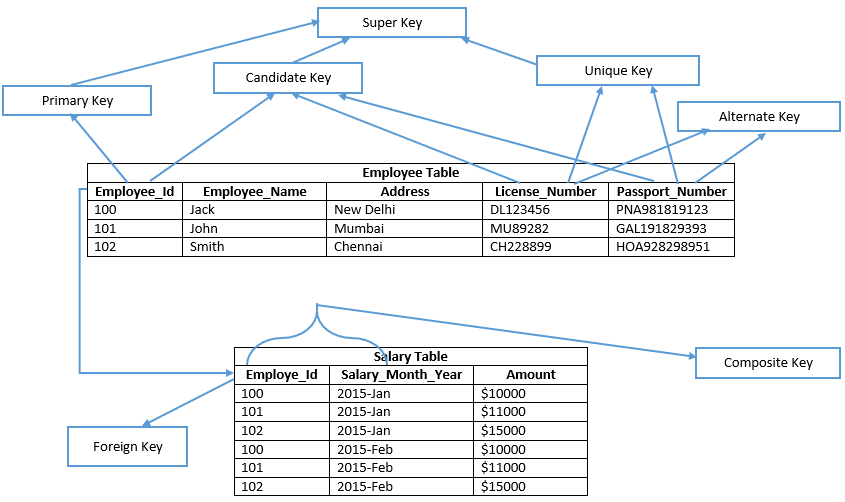
Låt oss förstå varje nyckel i detaljer
kandidatnyckel
en kandidatnyckel är en nyckel i en tabell som kan väljas som en primärnyckel i tabellen och en tabell kan ha flera kandidatnycklar, därför kan man väljas som en primärnyckel.
exempel: Employee_Id, License_Number, & Passport_Number visar kandidatnycklar
primärnyckel
en primärnyckel liknar vald kandidatnyckel i tabellen för att verifiera varje datapost unikt i tabellen. Därför innehåller primärnyckeln inget null-värde i någon av kolumnerna i en tabell och den behåller också unika värden i kolumnen. I det givna exemplet definierar Employee_Id primärnyckel för anställd tabell. Följaktligen skapar primärnyckel i SQL Server Management Studio ett grupperat index på en heap-tabell som standard och en tabell som inte består av ett grupperat index kallas en heap-tabell. Huruvida definierar en icke-klustrad primärnyckel på en tabell efter typ av index uttryckligen.
Dessutom kan en tabell bara ha en primärnyckel och primärnyckel kan definieras i SQL Server med SQL-satser:
- Kreta TABELLUTTALANDE (vid tidpunkten för tabellskapande) – som ett resultat definierar systemet namnet på primärnyckeln.
- ALTER TABLE –sats (med en primärnyckelbegränsning) – som ett resultat förklarar användaren själv namnet på primärnyckelbegränsning.
exempel: Employee_Id är en primär nyckel i anställd tabell.
unik nyckel
en unik nyckel är mycket som primärnyckel och som inte innehåller dubbla värden i kolumnen. Det har under skillnader i jämförelsen av primärnyckeln:
- det tillåter ett null-värde i kolumnen.
- som standard skapar det ett icke-grupperat index och heap-tabeller.
alternativ Nyckel
alternativ nyckel liknar kandidatnyckel, men inte markerad som primärnyckel i tabellen.
exempel: License_Number och Passport_Number är alternativa nycklar.
sammansatt Nyckel
sammansatt nyckel (även känd som en sammansatt nyckel eller sammanfogad nyckel) är en grupp med två eller flera kolumner som identifierar varje rad i en tabell unikt. Dessutom kanske en kolumn med en enhet i en sammansatt Nyckel inte kan verifiera dataposterna unikt. Som ett resultat kan det vara antingen primärnyckel eller kandidatnyckel också.
exempel: i tabellen, Employee_Id & Salary_Month_Year båda kolumnerna verifierar varje rad unikt i lönetabellen. Därför Employee_Id eller Salary_Month_Year kolumnen i tabellen, som inte kan identifiera varje rad unikt. Vi kan skapa en enda sammansatt primärnyckel på lönetabellen med hjälp av Employee_Id och Salary_Month_Year kolumnnamn.
Super Key
Super key är en uppsättning kolumner där alla kolumner i tabellen är funktionellt beroende. På grund av den uppsättning kolumner som unikt identifierar varje rad i en tabell. I ett annat ord innehåller den här tangenten några ytterligare kolumner som inte är strikt nödvändiga för att unikt verifiera varje rad i tabellen. Verkar som, primärnyckel och kandidatnycklar är minimala superkeys eller du kan säga en delmängd av superkeys.
så, låt oss titta på ovanstående exempel, i Medarbetartabellen är kolumnnamnet Employee_Id knappast tillräckligt för att unikt verifiera någon rad i tabellen. Så, att någon uppsättning av en kolumn från anställd tabell som innehåller Employee_Id är en superkey för anställd tabell.
till exempel: {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id, Employee_Name, Address} etc.
License_Number och Passport_Number är kolumnernas namn, det kan också unikt verifiera någon av raden i tabellen. Någon av kolumnnamn set som består License_Number eller Passport_Number eller Employee_Id är en superkey i tabellen.
till exempel: {License_Number, Employee_Name, Address}, {License_Number, Employee_Name, Passport_Number}, {Passport_Number, Employee_Name, Address, License_Number}, {Passport_Number, Employee_id} etc.
utländsk nyckel
en FK definierar förhållandet mellan två eller fler än två tabeller åt gången. En primärnyckel i en enda tabell hänvisas till en främmande nyckel i en annan tabell. En främmande nyckel kan ha dubbla värden i en tabell och det kan också ha null-värden om kolumnnamnet är definierat för att acceptera null-värden ännu.
till exempel kolumnnamn ”Employee_Id” ( som är en primärnyckel för anställd tabell ) är en utländsk nyckel i lönetabellen.
Obs: nycklar som primärnyckel och unik nyckel skapar index med nyckelkolumner. Organiserad data i b-Trädstrukturnod (balanserat träd: Bladnoder är alla på olika nivåer från rotsidan) i SQL Server. Därför skapar Nonclustered index en separat struktur från basdatatabellen men clustered index konverterar basdatatabellen från heapstruktur till en B-trädstruktur.
dessutom skapar det grupperade indexet inte en separat struktur bortsett från bastabellen och det är anledningen till att vi bara kan skapa ett grupperat index på en tabell. Därför kan vi Sortera en tabell på bara ett sätt (det kan ha flera kolumner att sortera men sortering kan göras på ett enda sätt) vilket är ordningen för det grupperade indexet.
hur man arbetar med SQL-funktioner
en funktion är ett entitetsprogram som lagras i SQL Server-databasen, antingen kan du skicka parametrar till eller returnera ett värde. Dessutom ser vi fram emot några mycket användbara inbyggda funktioner och användardefinierade funktioner.
Coalesce funktion
Coalesce() : denna funktion returnerar endast kommer första icke NULL värde. Så, låt oss ta ett exempel över Coalesce() funktion.
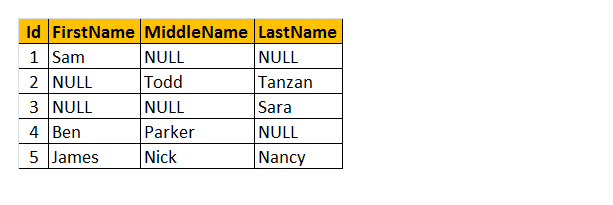 låt oss förstå tabellen som namn ’anställd’ ovan. Som ett resultat kan du se att några av de anställda har sitt förnamn saknas, vissa har ett mellannamn och några av dem har efternamn saknas. Så, jag vill bara returnera ”namn” på arbetstagaren.
låt oss förstå tabellen som namn ’anställd’ ovan. Som ett resultat kan du se att några av de anställda har sitt förnamn saknas, vissa har ett mellannamn och några av dem har efternamn saknas. Så, jag vill bara returnera ”namn” på arbetstagaren.
hur kommer det att fungera? Förstå, vi bearbetar förnamn, mellannamn och efternamn kolumner som parametrar till COALESCE() funktion. Därför returnerar denna funktion det enda första icke-null-värdet från 3 av kolumnerna.
fråga: Välj Id, COALESCE (förnamn, mellannamn, efternamn) som namn från tblEmployee
slutligen kommer utmatningen att se ut så här;
 vänster() funktion
vänster() funktion
vänster(Character_Expression, Integer_Expression) – denna funktion returnerar det angivna antalet tecken från vänster sida av det angivna teckenvärdet uttryck.
exempel: Välj Vänster (’ABCDE’, 3)
utgång: ABC
höger () funktion
höger (Character_Expression, Integer_Expression) – denna funktion returnerar det angivna antalet tecken från höger sida av det angivna teckenvärdet uttryck.
exempel: Välj rätt (’ABCDE’, 3)
utgång: CDE
CHARINDEX() funktion
CHARINDEX(’Expression_To_Find’, ’Expression_To_Search’, ’Start_Location’) – dessa funktioner returnerar startpositionen för det angivna värdeuttrycket i en teckensträng. Start_Location-parametern är valfri.
exempel: låt oss förstå, vi gör startpositionen för ’ @ ’ – tecknet i e-poststrängen ’[email protected]’.
Välj CHARINDEX (’@’, ’[email protected]’,1)
utgång: 5
SUBSTRING() funktion
SUBSTRING(uttryck’, ’Start’, ’Längd’) – denna funktion returnerar substring (del av strängen), från det givna värdeuttrycket. Dessutom, när du anger startpositionen med parametern’ start ’ och det andra antalet tecken i delsträngen med parametern ’längd’. Alla tre parametrarna är obligatoriska.
exempel: Jag vill bara visa domändelen av det angivna e-postmeddelandet ’[email protected]’.
Välj delsträng (’[email protected]’,6, 7)
utgång: bbb.com
som ett resultat gjorde vi kodningen med startpositionen och längdparametrarna. Istället för hårdkodning av parametrarna kan vi dynamiskt hämta dem med hjälp av charindex() och LEN() strängfunktioner som visas nedan.
exempel:
Välj SUBSTRING(’[email protected]’, (CHARINDEX ( ’ @ ’, ’[email protected]’) + 1), (LEN (’[email protected]’) – CHARINDEX ( ’ @’, ’[email protected]’)))
utgång: bbb.com
så, låt oss ta ett riktigt exempel med hjälp av Len(), CHARINDEX() och SUBSTRING() funktioner. Låt oss tro att vi har en tabell som visas nedan;
 så frågan är hur hittar du det totala antalet e-postmeddelanden av deras domän.
så frågan är hur hittar du det totala antalet e-postmeddelanden av deras domän.
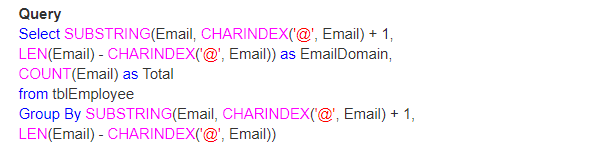
utgång: slutligen kommer utgången att se ut så här;
 REPLICATE () funktion
REPLICATE () funktion
REPLICATE (String_To_Be_Replicated, Number_Of_Times_To_Replicate) – denna funktion upprepar den givna punkten i strängen och för det angivna antalet gånger.
exempel: välj replikera (’Pragim’, 3)
utgång: Pragim Pragim Pragim
Låt oss prata om ett praktiskt exempel på att använda REPLICATE () – funktionen: Vi kommer att använda denna tabell för det mesta, och för resten av våra exempel i den här artikeln.
så, låt oss anta att vi har en tabell som visas nedan;
 fråga: Välj Förnamn, Efternamn, SUBSTRING (e-post, 1, 2) + replikera(’*’,5) +
fråga: Välj Förnamn, Efternamn, SUBSTRING (e-post, 1, 2) + replikera(’*’,5) +
SUBSTRING (e – post, CHARINDEX (’@’, e-post), LEN (e-post) – CHARINDEX (’@’, e-post)+1) som e-post
från tblEmployee
Låt oss göra e-post med 5 * (stjärna) symboler. Då skulle utmatningen vara så här
 SPACE() funktion
SPACE() funktion
SPACE(Number_Of_Spaces) – den här funktionen returnerar det enda antalet mellanslag och anges av termen Number_Of_Spaces argument.
exempel: funktionen mellanslag(5), den infogar 5 mellanslag mellan förnamn och efternamn
Välj förnamn + mellanslag(5) + efternamn som Fullnamn från tblEmployee
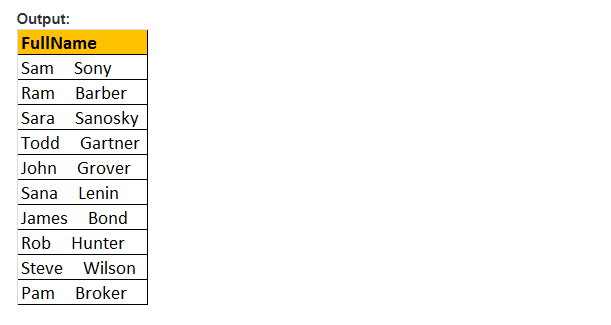 PATINDEX () funktion
PATINDEX () funktion
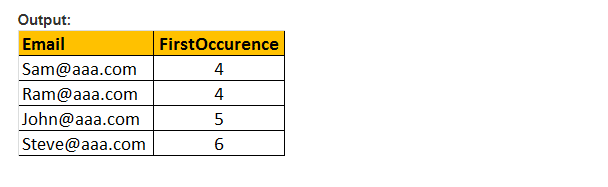
den här funktionen returnerar bara startplatsen för den första förekomsten av ett mönster i ett angivet effektivt uttryck. Därför tar det bara två argument, och mönstret som ska sökas och uttrycket. Därför liknar PATINDEX () CHARINDEX (). Med CHARINDEX() kan vi inte använda jokertecken, medan PATINDEX() involverar denna förmåga. Om det angivna mönstervärdet inte hittas returnerar PATINDEX () noll.
exempel: välj E-post, PATINDEX (’%aaa.com, e-post’) som FirstOccurence från tblEmployee där PATINDEX(’%@aaa.com’, e-post) > 0
 REPLACE () funktion
REPLACE () funktion
REPLACE(String_Expression, mönster, Replacement_Value), ersätter denna funktion alla förekomster position ett angivet strängvärde med ett annat strängvärde.
exempel: alla. COM-strängar ersätts med.NET
välj E-post, ersätt(e-post,’. com’,’.Net’) som ConvertedEmail från tbl employee
 STUFF () funktion
STUFF () funktion
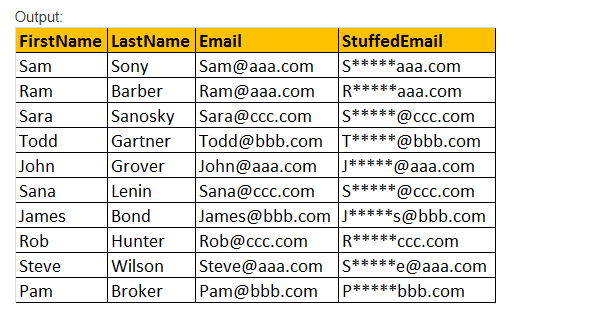
STUFF(Original_Expression, Start, längd, Replacement_expression), infogar denna STUFF () – funktion endast Replacement_expression, som anges vid startpositionen, tillsammans med att ta bort de tecken som anges med hjälp av Längdparametervärdeuttryck.
exempel: Välj Förnamn, Efternamn, E-post, Grejer(e-post,2,3,’*****’) som StuffedEmail från tblEmployee.
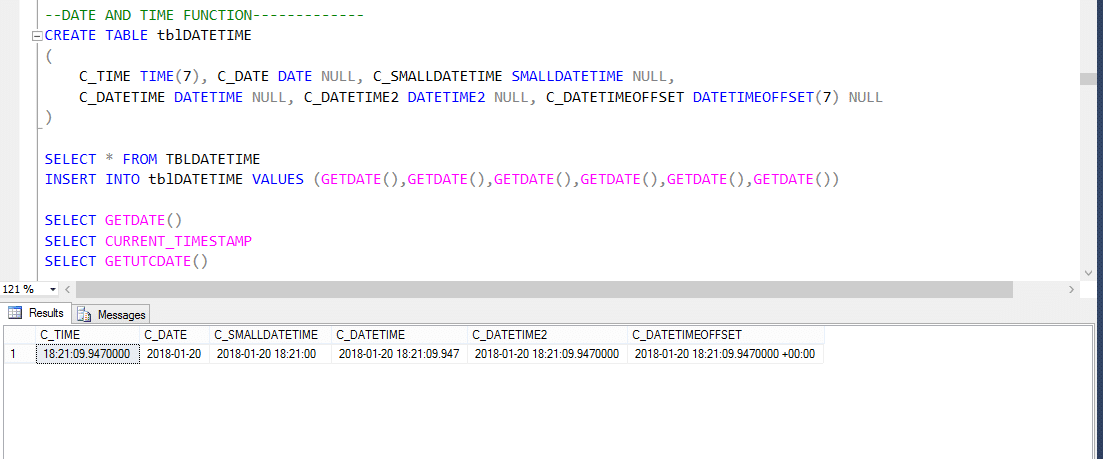
 Datumtidsfunktion
Datumtidsfunktion
det finns flera inbyggda DateTime-funktioner tillgängliga i SQL Server-databasen. De flesta av följande funktioner kan användas för att få det aktuella systemet datum och tid, och där du har SQL server installerat.
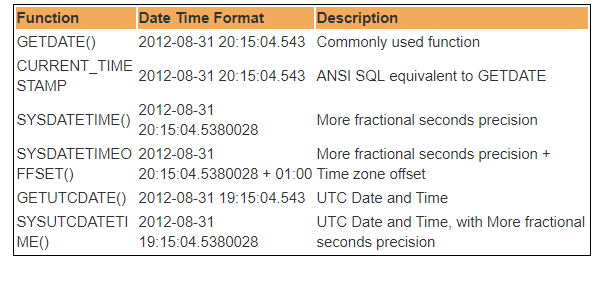 därför står UTC för Coordinated Universal Time, baserat på vilken världen reglerar klockor och tidsdata. Anmärkningsvärd. det finns mindre skillnader mellan GMT och UTC, men för de flesta vanliga ändamål är UTC synonymt med GMT.
därför står UTC för Coordinated Universal Time, baserat på vilken världen reglerar klockor och tidsdata. Anmärkningsvärd. det finns mindre skillnader mellan GMT och UTC, men för de flesta vanliga ändamål är UTC synonymt med GMT.
så, låt oss ta ett annat exempel som visas nedan;
isDate () funktion
ISDATE () – den här funktionen kontrollerar om det enda angivna värdet, och finns ett giltigt datum, tid eller DateTime. Då kommer det att återvända 1 för framgång, 0 för misslyckande.
exempel:
Välj ISDATE(’PRAGIM’) — det returnerar 0
exempel:
Välj ISDATE(Getdate()) — det returnerar 1
exempel:
Välj ISDATE(’2018-01-20 21:02:04.167’) — det kommer returnerar 1
Obs: För datetime2 värden, isdate returnerar noll.
exempel:
Välj ISDATE(’2018-01-20 22:02:05.158.1918447’) — det kommer att returnera 0.
dag() funktion
dag() – den här funktionen returnerar bara ’Månadens dagnummer’ för det angivna datumet.
exempel:
Välj dag (GETDATE ()) – det kommer att ge produktionen på uppdrag av dagen nummer i månaden, och baserat på nuvarande system DateTime.
Välj dag (’01/14/2018′) – den returnerar 14
månad () funktion
månad () – den här funktionen ger utmatningen på uppdrag av’ månadens nummer på året ’ för det angivna datumet.
exempel:
Välj månad(GETDATE()) — denna funktion kommer att ge utdata på uppdrag av ’månad nummer av året’, och baserat på det aktuella systemet datum och tid.
Välj månad(’05/14/2018) — det kommer att returnerar 5
år() funktion
år() – denna funktion kommer att ge produktionen på uppdrag av ’år nummer’ för det angivna datumet
exempel:
Välj år(GETDATE()) — returnerar år nummer, och baserat på det aktuella systemet datum
välj år(’01/20/2018) — det kommer returnerar 2018
Datename() funktion
Datename(datepart, Date) – den här funktionen returnerar endast Ett stränguttryck, och som bara representerar en del av det angivna datumet. Dessa funktioner består av 2 parametrar.
den första parametern ’DatePart’ anger den del av datumet som vi vill ha. Den andra parametern är det verkliga datumet, från vilket vi vill ha den del av datumet.
 exempel 1:
exempel 1:
Välj DATUMNAMN (dag, ’2017-04-20 13:47:47.350’) — det kommer returnerar 20
exempel 2:
Välj DATENAME (veckodag, ’2017-04-20 13:47:47.350’) — det kommer tillbaka torsdag
exempel 3:
Välj DATUMNAMN (månad, ’2017-04-20 13:47:47.350’) — det kommer att returnera April
så, låt oss ta ett exempel med några av dessa DateTime-funktioner. Tänk på tabellen tblanställda.
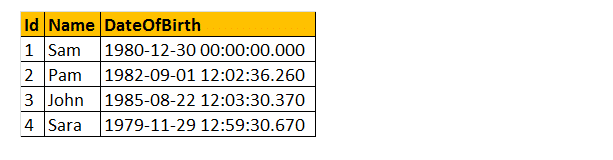 exempel: Jag vill returnera alla namn, DateOfBirth, dag, MonthNumber, MonthName och år som visas nedan.
exempel: Jag vill returnera alla namn, DateOfBirth, dag, MonthNumber, MonthName och år som visas nedan.
Välj namn, DateOfBirth, DateName (veckodag,DateOfBirth) som, månad (DateOfBirth) som MonthNumber, DateName( månad, DateOfBirth) som, år (DateOfBirth) från tblEmployees

DatePart () funktion
DatePart(DatePart, Date) – denna funktion ger ett heltal som representerar det angivna DatePart-värdet. För det mesta liknar funktionen DateName (). DateName () returnerar endast nvarchar-värde, medan DatePart () returnerar endast ett heltal. De giltiga parametervärdena för DatePart visas nedan.
exempel:
Välj DATUMDEL (vardag, ’2012-08-30 19:45:31.793’) — det kommer returnerar 5
Välj DATENAME (veckodag, ’2012-08-30 19:45:31.793’) — det kommer returnerar torsdag
DateAdd() funktion
DATEADD (datepart, NumberToAdd, date) – denna SQL-funktion ger endast DateTime, efter angiven term NumberToAdd, och till den datepart som anges för det angivna datumet.
exempel:
Välj Datumlägg till (dag, 10, ’2018-01-20 19:45:31.793’) — det kommer att återvända ’2018-01-30 19:45:31.793’
Välj Datumlägg till (dag, -10, ’2012-08-30 19:45:31.793’)– det kommer att återvända ’2018-01-20 19:45:31.793’
DatedDiff () – funktionen
DATEDIFF(datepart, startdate, enddate) – den här funktionen ger räkningen av de angivna datepart-gränserna som korsas mellan den angivna startdate och enddate.
exempel:
Välj DATUMDIFF (månad, ’11/30/2005′,’01/31/2006′) — det kommer returnerar 2
Välj DATEDIFF (dag, ’11/30/2005′,’01/31/2006′) — det kommer att returnera 62
så, låt oss ta ett exempel, låt oss anta att vi har en tabell nedan;
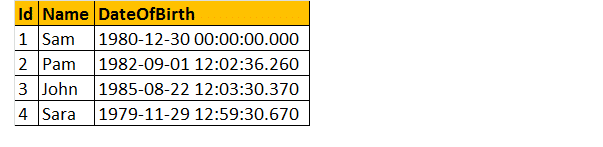
så skriv en fråga för att ta reda på en persons ålder när födelsedatum ges.

slutligen kommer utmatningen att se ut som visas nedan.
Cast() och Convert() funktioner
för att konvertera en enda enhet datatyp till en annan, CAST och konvertera funktioner kan användas.
Syntax för CAST och konvertera funktion:
CAST ( uttryck som data_type )
konvertera ( data_type , expression )
dessutom, som du kan se att konvertera () – funktionen har ett valfritt stilparametervärde, medan CAST () – funktionen saknar denna kapacitet.
så, låt oss ta ett exempel, Vi tar en tabell nedan;
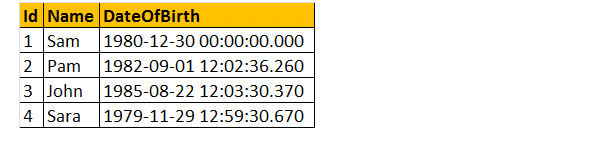 det följande 2 frågor konvertera DateOfBirth s DateTime datatyp till NVARCHAR. Den första frågan använder funktionen CAST() och den andra använder funktionen CONVERT (). Slutligen är utmatningen exakt densamma för båda frågorna som visas nedan.
det följande 2 frågor konvertera DateOfBirth s DateTime datatyp till NVARCHAR. Den första frågan använder funktionen CAST() och den andra använder funktionen CONVERT (). Slutligen är utmatningen exakt densamma för båda frågorna som visas nedan.
Välj ID, Namn DateOfBirth, Cast(DateOfBirth som nvarchar) som ConvertedDOB från tblemployees.
Välj ID, Namn DateOfBirth, konvertera (DateOfBirth som nvarchar) som ConvertedDOB från tblemployees.
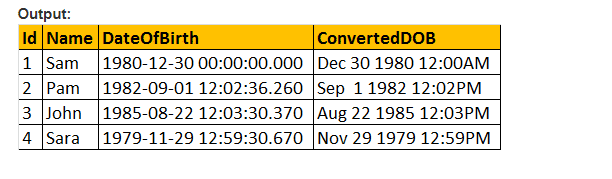 så, låt oss göra stilparametern för CONVERT () – funktionsvärdet och formatera datumet som vi skulle vilja ha det. Så vi använder 103 som passerar argumentet för stilparametern i nedan fråga, och som formaterar datumet som dd/mm/yy.
så, låt oss göra stilparametern för CONVERT () – funktionsvärdet och formatera datumet som vi skulle vilja ha det. Så vi använder 103 som passerar argumentet för stilparametern i nedan fråga, och som formaterar datumet som dd/mm/yy.
Välj ID, Namn, DateOfBirth, konvertera (nvarchar, DateOFBirth, 103) som ConvertedDOB från tblEmployees.
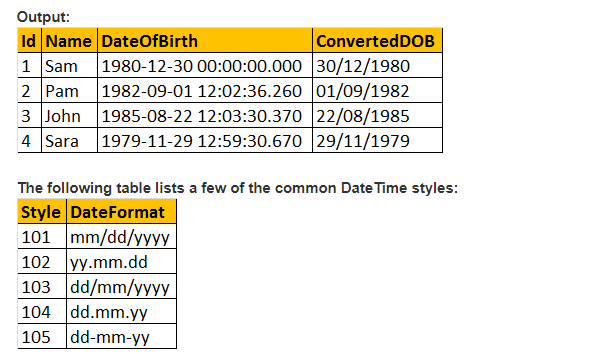
så, låt oss ta en titt på praktiskt exempel med hjälp av CAST () funktion;
låt oss anta att vi har en registreringstabell nedan som;
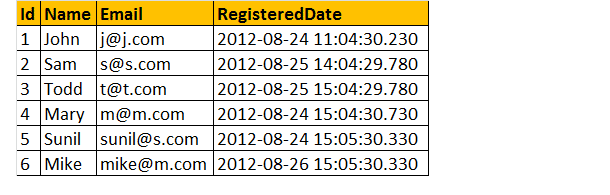 låt oss nu hitta det totala antalet registreringar per dag.
låt oss nu hitta det totala antalet registreringar per dag.
exempel: välj CAST (RegisteredDate som datum) som RegistrationDate, COUNT( Id) som TotalRegistrations Tblregistrations Group By CAST (RegisteredDate som datum)
Output: slutligen kommer utmatningen att se ut som ;
användardefinierade funktioner
det finns 3 typer av användardefinierade funktioner i SQL Server som som
- skalära funktioner
- inline tabellvärderade funktioner
- multistatement tabellvärderade funktioner
skalära funktioner
skalära funktioner varierar i parametrar som kan eller inte kan ha parametrar och ger alltid ett enda (skalärt) värde i utgången. Därför kan det returnerade värdet vara av alla datatypsformat utom textvärde, text, bild, markör och tidsstämpel.
exempel: Så, låt oss utveckla en funktion som beräknar och returnerar en persons ålder i produktionen. Följaktligen, för att jämföra den ålder vi krävde för, födelsedatum. Så, låt oss skicka födelsedatum som en parameter. Därför kommer ålder () funktion returnera ett heltal och kommer att acceptera datum parameter.
 Välj dbo.Ålder (dbo.Ålder (’10/08/1982′).
Välj dbo.Ålder (dbo.Ålder (’10/08/1982′).
så, låt oss ta ett praktiskt exempel i tabellen nedan enligt följande;
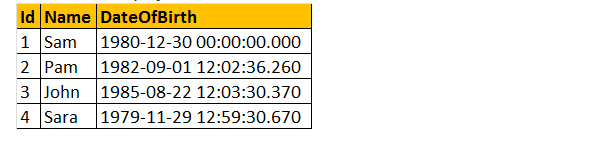
skalära användardefinierade funktioner kan användas i Select-satsen som visas nedan.
Välj namn, Datumfödelse, dbo.Ålder (DateOfBirth) som ålder från tblEmployees
 mestadels visa texten i funktionen använd sp_helptext FunctionName.
mestadels visa texten i funktionen använd sp_helptext FunctionName.
inline-tabellvärderade funktioner
en inline-Tabellvärderad funktion returnerar alltid en tabell som utdata.
så, låt oss ta ett exempel nedan; skapa en funktion som returnerar anställda efter kön.
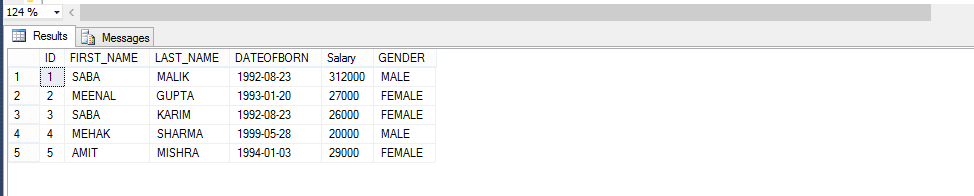
på grund av anropsmetod för den användardefinierade funktionen,
Välj * från FN_ Employeebygender (’male’)
Multi-STATEMENT Table VALUED FUNCTION
Multi-statement table-värderade funktioner liknar mycket mer inline-tabellvärderade funktioner och med vissa skillnader. Så, låt oss ta en titt på ett exempel och notera sedan skillnaderna.
anställd tabell
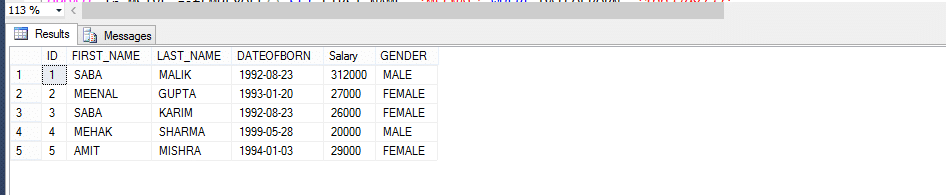
Multi-uttalande tabell värderad funktion (MSTVF):
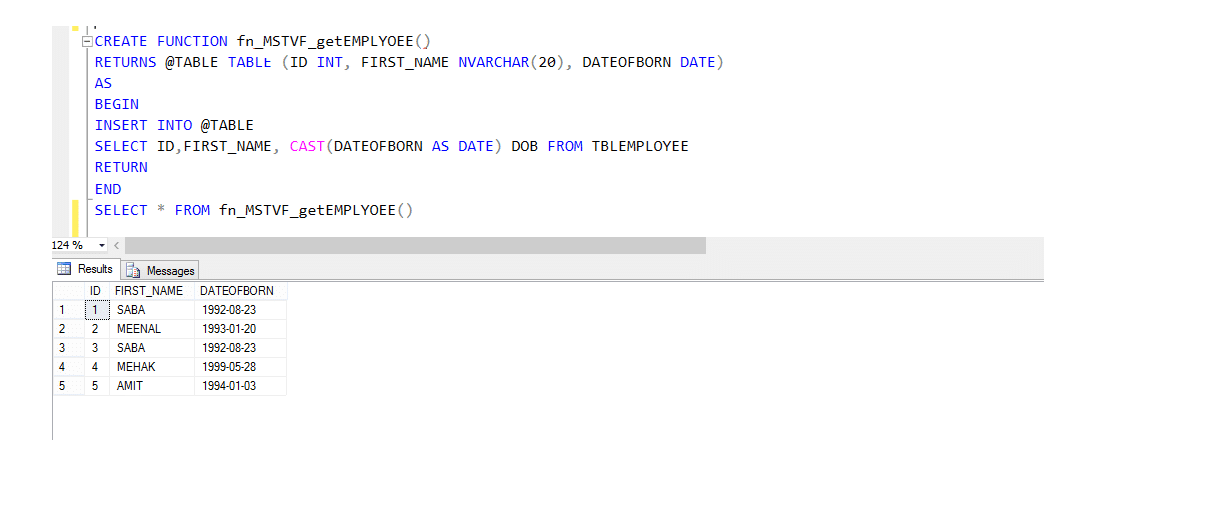 på grund av att ringa metod för vden Multi-uttalande tabellen värderad funktion:
på grund av att ringa metod för vden Multi-uttalande tabellen värderad funktion:
Välj * från fn_MSTVF_GetEmployees()
slutsats
Sammanfogningarna är mycket förståelse för nybörjare under inlärningsfasen av SQL-kommandon. Följaktligen, i intervjun, intervjuaren frågar minst en fråga handlar om SQL går, och funktioner. Så i det här inlägget försöker jag förenkla sakerna för nya SQL-elever och göra det lätt att förstå SQL-anslutningarna. Dessutom har funktionerna i SQL många människor problem med att förstå den faktiska arbetsfunktionen. Eftersom SQL innehåller mycket data i bulk i olika databas-och tabellnamn. En funktion är ett lagrat program i SQL Server-databasen där du kan skicka parametrar till och returnera ett värde. Så, jag har gett lite mer användbar term om att arbeta med funktioner.
- om
- Senaste inlägg

- skillnad mellan SQL och MySQL-14 April 2020
- hur man arbetar med Subquery i Data Mining – 23 mars 2018
- Hur använder man webbläsarfunktioner i Javascript? – Mars 9, 2018
