gå til sektion
- introduktion
- Sådan arbejder du med joinforbindelser
- indre joinforbindelse
- venstre Deltag
- højre Deltag
- fuld ydre join
- Cross join
- Sådan arbejder du med Advance accounts
- venstre Deltag
- fuld ydre join
- typer af nøgler i KVL
- kandidatnøgle
- primær nøgle
- unik nøgle
- alternativ nøgle
- sammensat nøgle
- Super Key
- fremmed nøgle
- Sådan arbejder du med funktioner
- Left() funktion
- højre() funktion
- CHARINDEKS() funktion
- SUBSTRING() funktion
- REPLICATE () funktion
- SPACE() funktion
- PATINDEKS() funktion
- erstat () funktion
- ting () funktion
- Datotidsfunktion
- isDate () – funktion
- måned() funktion
- år() funktion
- Datename() funktion
- DatePart () – funktion
- DateAdd() funktion
- DatedDiff () funktion
- Cast() og konverter() funktioner
- brugerdefinerede funktioner
- Skalarfunktioner
- funktioner med indbygget tabelværdi
- multi-STATEMENT TABLE VALUED FUNCTION
- konklusion
introduktion
står for struktureret forespørgselssprog. Det bruges hovedsageligt til datamanipulation, datamodifikation og dataindhentning. Dette kommer rundt med relationel Database Management System (RDBMS).
vi lærer om mere avancerede funktioner i f.eks.
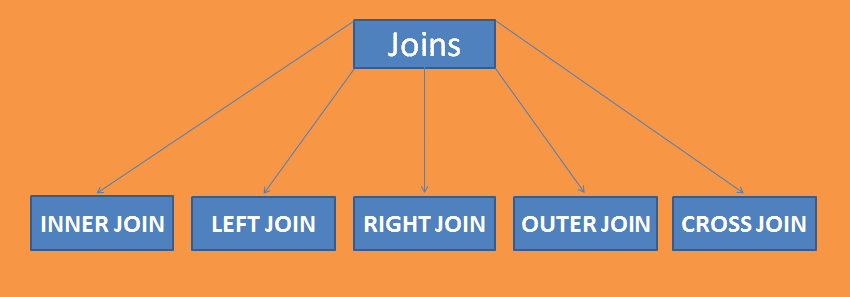
Sådan arbejder du med joinforbindelser
en simpel joinforbindelse er at kombinere to eller flere tabeller i en given database. En join arbejder på en fælles enhed af to tabeller.
en joinforbindelse indeholder 5 sub-joinforbindelser, som som; indre joinforbindelse, ydre joinforbindelse, venstre joinforbindelse, højre joinforbindelse og kryds joinforbindelse.
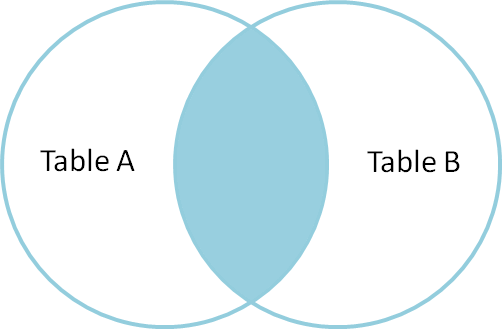
indre joinforbindelse
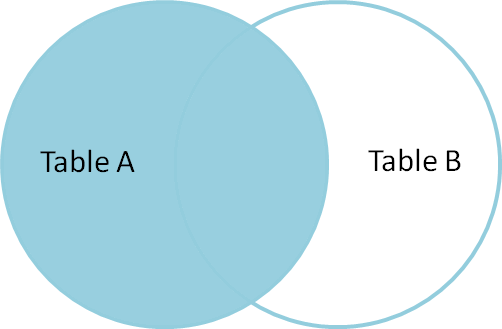
en indre joinforbindelse bruges til at vælge poster, der indeholder fælles eller matchende værdier i begge tabeller (Tabel A og tabel B). Ikke-matchende elimineres.
så lad os forstå typen af sammenføjninger, og med almindelige eksempler og forskellene mellem dem.
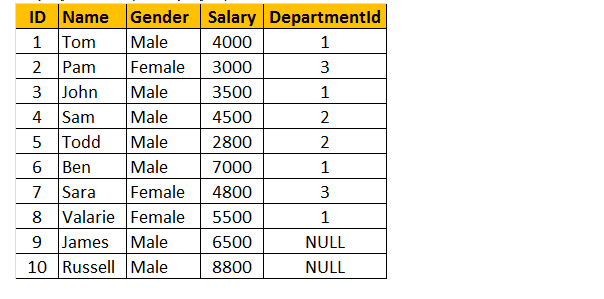
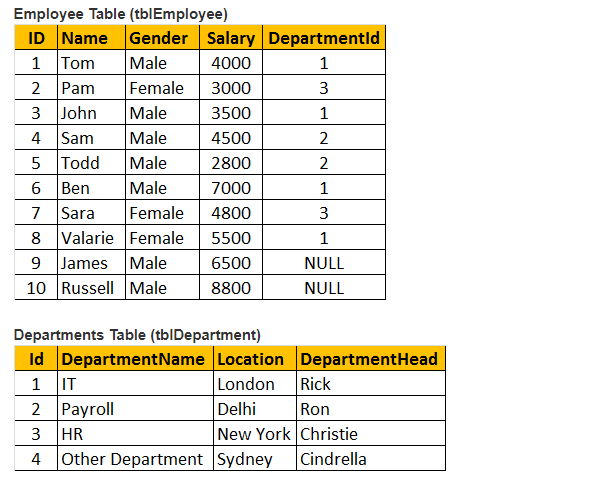
tabel 1: Medarbejderbord (tblmedarbejder)
tabel 2: Afdelingstabel (tblafdelinger)
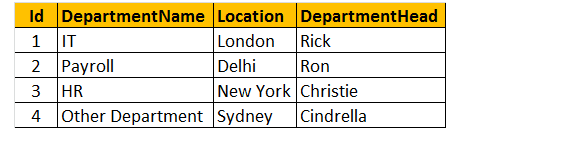
så lad os oprette tabel tblafdelinger til udførelse af et program.

Indsæt nu poster i tabel tblafdelinger.

lad os oprette en anden tabel tblmedarbejder til udførelse af et program.

så indsæt poster i tabel tblmedarbejder.

derfor er en generel formel for joinforbindelser.

at stille en forespørgsel for at finde navn, køn, løn og Afdelingsnavn fra både tabellerne tblmedarbejder og tblDepartments.

Bemærk: JOIN eller indre JOIN betyder det samme. Men altid bedre at bruge indre JOIN, og dette specificerer din hensigt eksplicit.
Output: nu vil den endelige outputtabel se sådan ud;
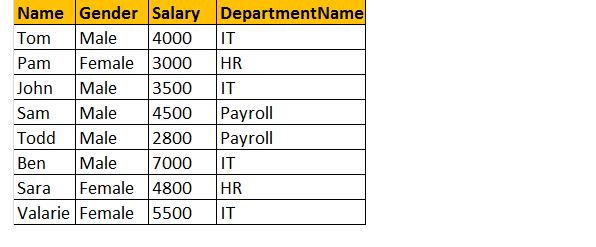
hvis du ser på outputvinduet, har vi kun 8 rækker, men i tabellen tblmedarbejder, vi har 10 rækker. Vi fik ikke JAMES og RUSSELL records. Dette skyldes, at afdelingen, i tabel tblmedarbejder er NULL for disse to medarbejdere og stemmer ikke overens med deres ID-kolonne i tabel tblDepartments.
så i en endelig erklæring, indre joinforbindelser returnerer kun matchende rækker fra både tabellerne og ikke-matchende rækker elimineres på grund af dens underforespørgsel.
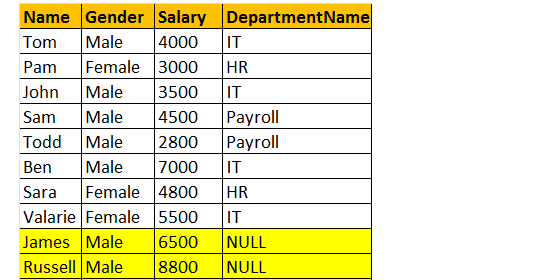
venstre Deltag
venstre joinforbindelse returnerer alle de matchende rækker og ikke-matchende rækker fra venstre sidebord. Ud over, indre sammenføjning og venstre sammenføjning bruges i vid udstrækning hinanden.
så lad os tage et eksempel, Jeg vil have alle rækkerne fra tblmedarbejderbordet, herunder JAMES og RUSSELL records. Så output vil se ud som;

højre Deltag
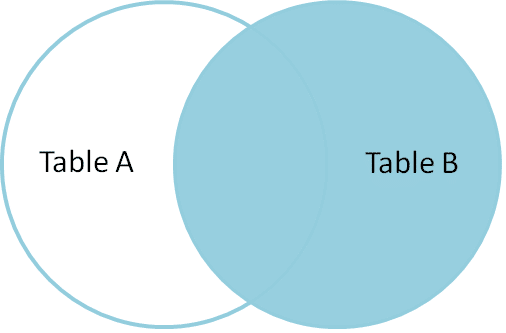
højre Join returnerer alle de matchende rækker og ikke-matchende rækker fra højre sidebord.
så lad os tage et eksempel; Jeg vil have alle rækkerne fra højre tabeller involveret i join. Som et resultat ville være som;

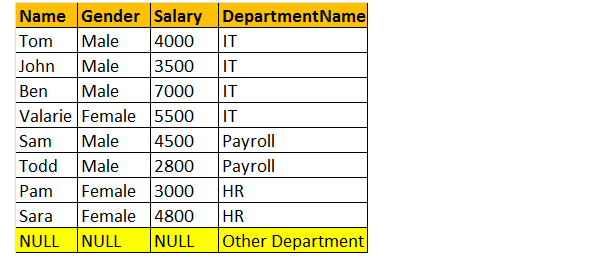
fuld ydre join

ydre joinforbindelse eller Fuld ydre joinforbindelse returnerer alle rækker fra både venstre og højre tabeller og inkluderer de ikke-matchende rækker fra tabellerne.
så lad os tage et eksempel; Jeg vil have alle rækkerne fra begge tabellerne involveret i join.

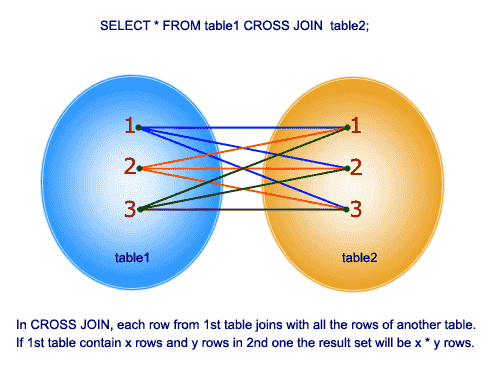
Cross join
denne joinforbindelse giver det kartesiske produkt af de 2 tabeller i joinfunktionen. Denne tilslutning indeholder ikke ON-klausul.
så lad os forstå et eksempel: I tabellen tblmedarbejder har vi 10 rækker og i tabellen tblDepartments har vi 4 rækker. Så et kryds forbinder mellem disse 2 tabeller producerer 40 rækker.

Sådan arbejder du med Advance accounts
i denne session vil jeg forklare disse ting som følger;
- avanceret eller intelligent slutter sig til.
- Hent data kun de ikke-matchende rækker fra venstre tabel.
- Hent data kun de ikke-matchende rækker fra højre tabel.
- Hent data kun de ikke-matchende rækker fra både venstre og højre tabeller.
så lad os overveje både tabellerne tblmedarbejder og tblafdeling.
venstre Deltag
så lad os forstå et eksempel, Jeg vil kun hente de ikke-matchende rækker fra venstre sidebord.

Output: endelig vil output se sådan ud;

højre Deltag
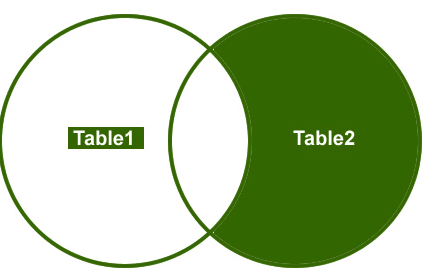
så lad os forstå et eksempel, Jeg vil kun hente de ikke-matchende rækker fra højre sidebord.

Output: endelig vil output se sådan ud;

fuld ydre join
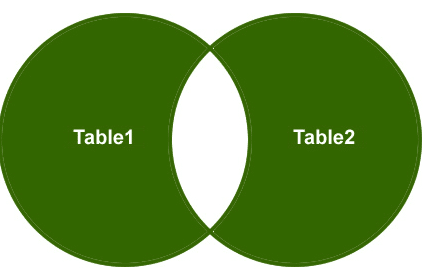
så lad os forstå et eksempel, Jeg vil kun hente de ikke-matchende rækker fra højre sidebord og venstre sidebord og matchende rækker bør elimineres.

Output: endelig vil output se sådan ud;
typer af nøgler i KVL
en nøgle i KVL er et datafelt, der udelukkende identificerer en post. I et andet ord er en nøgle et sæt kolonner, der bruges til entydigt at identificere posten i en tabel.
- Opret relationer mellem to tabeller.
- Oprethold unikhed og ansvar i en tabel.
- Bevar konsistente og gyldige data i en database.
- kan hjælpe med hurtig dataindhentning ved at lette indekser på kolonne(er).
en server indeholder nøgler som følger;
- kandidatnøgle
- primær nøgle
- unik nøgle
- alternativ nøgle
- sammensat nøgle
- Super nøgle
- fremmed nøgle
før du går videre, og se venligst på billedet nedenfor;
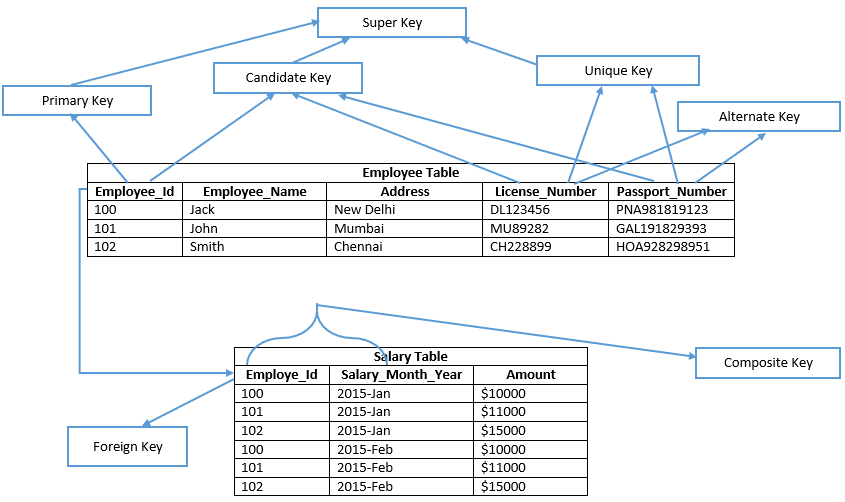
lad os forstå hver nøgle i detaljer
kandidatnøgle
en kandidatnøgle er en nøgle i en tabel, der kan vælges som en primær nøgle i tabellen, og en tabel kan have flere kandidatnøgler, derfor kan man vælges som en primær nøgle.
eksempel: Employee_Id, License_Number,& Passport_Number viser kandidatnøgler
primær nøgle
en primær nøgle svarer til den valgte kandidatnøgle i tabellen for at verificere hver datapost entydigt i tabellen. Derfor indeholder primær nøgle ikke nogen null-værdi i nogen af kolonnerne i en tabel, og den indeholder også unikke værdier i kolonnen. I det givne eksempel definerer Employee_Id primær nøgle i Medarbejdertabellen. Derfor opretter primær nøgle som standard et grupperet indeks på en bunkebord, og en tabel, der ikke består af et grupperet indeks, er kendt som en bunketabel. Hvorvidt definerer en nonclustered primær nøgle på en tabel efter type indeks eksplicit.
desuden kan en tabel kun have en primær nøgle, og den primære nøgle kan defineres i:
- Kreta TABLE statement (på tidspunktet for tabeloprettelse) – som følge heraf definerer systemet navnet på den primære nøgle.
- ALTER TABLE –sætning (ved hjælp af en primær nøglebegrænsning) – som et resultat erklærer brugeren selv navnet på den primære nøglebegrænsning.
eksempel: Employee_Id er en primær nøgle i Medarbejdertabellen.
unik nøgle
en unik nøgle er meget som den primære nøgle, og som ikke indeholder duplikatværdier i kolonnen. Det har under forskelle i sammenligningen af den primære nøgle:
- det tillader en null-værdi i kolonnen.
- som standard opretter det et ikke-grupperet indeks og heap-tabeller.
alternativ nøgle
den alternative nøgle svarer til kandidatnøgle, men ikke valgt som en primær nøgle i tabellen.
eksempel: License_Number og Passport_Number er alternative nøgler.
sammensat nøgle
sammensat nøgle (også kendt som en sammensat nøgle eller sammenkædet nøgle) er en gruppe på to eller flere kolonner, der identificerer hver række i en tabel entydigt. Desuden kan en enkelt enhedskolonne i en sammensat nøgle muligvis ikke entydigt verificere dataposterne. Som resultat, det kan enten være primær nøgle eller kandidatnøgle også.
eksempel: i tabellen bekræfter Employee_Id & Salary_Month_Year begge kolonner hver række entydigt i Løntabellen. Derfor Employee_Id eller Salary_Month_Year kolonne i tabellen, som ikke kan identificere hver række entydigt. Vi kan oprette en enkelt sammensat primær nøgle på Løntabellen ved hjælp af kolonnenavne Employee_Id og Salary_Month_Year.
Super Key
Super key er et sæt kolonner, hvor alle kolonner i tabellen er funktionelt afhængige. På grund af det sæt kolonner, der entydigt identificerer hver række i en tabel. I et andet ord indeholder denne nøgle få yderligere kolonner, som ikke er strengt nødvendige for entydigt at verificere hver række i tabellen. Det ser ud til, at primære nøgle-og kandidatnøgler er minimale superkeys, eller du kan sige en delmængde af superkeys.
så lad os se på ovenstående eksempel i Medarbejdertabellen er kolonnenavnet Employee_Id næppe tilstrækkeligt til entydigt at verificere nogen række i tabellen. Så at ethvert sæt af en kolonne fra Medarbejdertabel, der indeholder Employee_Id, er en superkey til Medarbejdertabel.
For eksempel: {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id, Employee_Name, Address} osv.
License_Number og Passport_Number er kolonnenavnet, det kan også entydigt bekræfte en hvilken som helst række i tabellen. Enhver af kolonne navn sæt, der består License_Number eller Passport_Number eller Employee_Id er en superkey af tabellen.
For eksempel: {License_Number, Employee_Name, Address}, {License_Number, Employee_number, Passport_Number}, {Passport_Number, Employee_id}, {Passport_Number, Employee_Name}, {Passport_Number, Employee_Id} osv.
fremmed nøgle
en FK definerer forholdet mellem to eller flere end to tabeller ad gangen. En primær nøgle i en enkelt tabel henvises til en fremmed nøgle i en anden tabel. En fremmed nøgle kan have dublerede værdier i en tabel, og den kan også have null-værdier, hvis kolonnenavnet er defineret til at acceptere null-værdier endnu.
for eksempel kolonnenavn “Employee_Id” ( som er en primær nøgle i Medarbejdertabellen ) er en fremmed nøgle i Løntabellen.
Bemærk: nøgler som primær nøgle og unik nøgle opretter indekser med nøgler kolonner. Organiserede data i B-Tree structure node (balanceret træ: Leaf noder er alle på forskellige niveauer fra rodsiden) i
derudover opretter det grupperede indeks ikke en separat struktur bortset fra basistabellen, og det er grunden til, at vi kun kan oprette et grupperet indeks på et bord. Derfor kan vi sortere en tabel på kun en måde (den kan have flere kolonner at sortere, men sortering kan udføres på en eneste måde), som er rækkefølgen af det grupperede indeks.
Sådan arbejder du med funktioner
en funktion er et enhedsprogram, der er gemt i databasen. Desuden ser vi frem til nogle meget nyttige indbyggede funktioner og brugerdefinerede funktioner.
Coalesce funktion
Coalesce() : denne funktion returnerer kun kommer først ikke NULL værdi. Så lad os tage et eksempel over Coalesce() funktion.
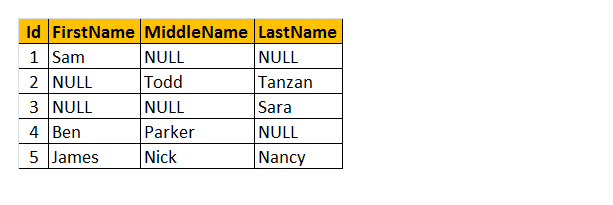 lad os forstå tabellen som navnet ‘medarbejder’ ovenfor. Som et resultat kan du se, at nogle af medarbejderne mangler deres fornavn, nogle har et mellemnavn, og nogle af dem mangler efternavn. Så jeg vil kun returnere “navn” på medarbejderen.
lad os forstå tabellen som navnet ‘medarbejder’ ovenfor. Som et resultat kan du se, at nogle af medarbejderne mangler deres fornavn, nogle har et mellemnavn, og nogle af dem mangler efternavn. Så jeg vil kun returnere “navn” på medarbejderen.
Hvordan fungerer det? Forstå, vi behandler fornavn, mellemnavn og efternavn kolonner som parametre til at samle() funktion. Derfor returnerer denne funktion den eneste første ikke-null-værdi fra 3 af kolonnerne.
forespørgsel: Vælg Id, COALESCE (fornavn, mellemnavn, efternavn) som navn fra tblmedarbejder
endelig vil output se sådan ud;
 Left() funktion
Left() funktion
LEFT(Character_ekspression, Integer_ekspression) – denne funktion returnerer det angivne antal tegn fra venstre side af det givne tegnværdiudtryk.
eksempel: Vælg venstre (‘ABCDE’, 3)
Output: ABC
højre() funktion
højre(Tegn_udtryk, Heltaludtryk) – denne funktion returnerer det angivne antal tegn fra højre side af det givne tegnværdiudtryk.
eksempel: Vælg højre (‘ABCDE’, 3)
Output: CDE
CHARINDEKS() funktion
CHARINDEKS(‘Ekspression_to_find’, ‘Ekspression_to_search’, ‘Start_Location’) – denne funktion returnerer startpositionen for det angivne værdiudtryk i en tegnunderstreng. Start_location parameter er valgfri.
eksempel: lad os forstå, vi laver startpositionen for ‘ @ ‘tegn i e-mail-strengen ‘[email protected]’.
Vælg CHARINDEKS (‘@’, ‘[email protected]’,1)
Output: 5
SUBSTRING() funktion
SUBSTRING(udtryk’, ‘Start’, ‘Længde’) – denne funktion returnerer substring (subpart af strengen) fra det givne værdiudtryk. Derudover, når du angiver startpositionen ved hjælp af parameteren ‘start’ og det andet antal tegn i substring ved hjælp af parameteren ‘Længde’. Alle tre parametre er obligatoriske.
eksempel: Jeg vil bare vise domænedel af den givne e-mail ‘[email protected]’.
Vælg SUBSTRING (‘[email protected]’,6, 7)
udgang: bbb.com
som følge heraf lavede vi kodningen med startpositionen og længdeparametrene. I stedet for hardcoding parametrene, kan vi dynamisk hente dem ved hjælp af charindeks() og LEN() streng funktioner som vist nedenfor.
eksempel:
Vælg SUBSTRING(‘[email protected]’, (CHARINDEKS (‘@’, ‘[email protected]’) + 1), (LEN(‘[email protected]’) – CHARINDEKS(‘@’,’[email protected]’)))
udgang: bbb.com
så lad os tage et rigtigt eksempel med brug af Len (), CHARINDEKS() og SUBSTRING() funktioner. Lad os tro, at vi har en tabel som vist nedenfor;
 så spørgsmålet er, hvordan finder du det samlede antal e-mails efter deres domæne.
så spørgsmålet er, hvordan finder du det samlede antal e-mails efter deres domæne.
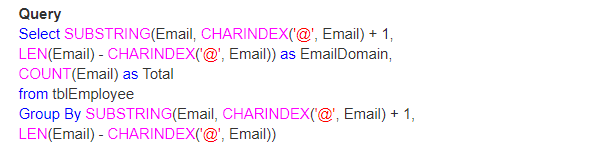
Output: endelig vil output se sådan ud;
 REPLICATE () funktion
REPLICATE () funktion
REPLICATE (String_To_Be_Replicated, Number_Of_Times_To_Replicate) – denne funktion gentager det givne punkt i strengen og for det angivne antal gange.
eksempel: vælg Repliker (‘Pragim’, 3)
Output: Pragim Pragim Pragim
lad os tale om et praktisk eksempel på at bruge replikat () – funktion: Vi vil bruge denne tabel det meste af tiden, og for resten af vores eksempler i denne artikel.
så lad os antage, at vi har en tabel som vist nedenfor;
 forespørgsel: Vælg Fornavn, Efternavn, SUBSTRING ( E-Mail, 1, 2) + replikere(‘*’,5) +
forespørgsel: Vælg Fornavn, Efternavn, SUBSTRING ( E-Mail, 1, 2) + replikere(‘*’,5) +
SUBSTRING (e – mail, CHARINDEKS (‘@’, e-mail), LEN (e-mail) – CHARINDEKS (‘@’, E-Mail)+1) som e-mail
fra tblmedarbejder
lad os lave e-mail med 5 * (stjerne) symboler. Derefter ville outputtet være som dette
 SPACE() funktion
SPACE() funktion
SPACE(Number_Of_Spaces) – denne funktion returnerer det eneste antal mellemrum og specificeret af udtrykket Number_Of_Spaces argument.
eksempel: funktionen mellemrum(5), den indsætter 5 mellemrum mellem fornavn og efternavn
Vælg fornavn + mellemrum(5) + efternavn som Fuldnavn fra tblmedarbejder
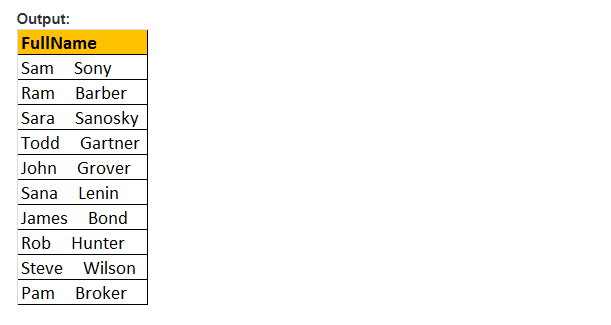 PATINDEKS() funktion
PATINDEKS() funktion
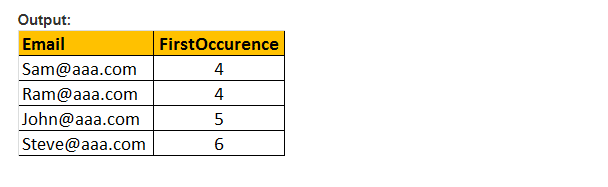
denne funktion returnerer kun startplaceringen for den første forekomst af et mønster i et specificeret effektivt udtryk. Derfor tager det kun to argumenter, og det mønster, der skal søges, og udtrykket. Derfor ligner PATINDEKS () CHARINDEKS (). Med CHARINDEKS() kan vi ikke bruge jokertegn, mens PATINDEKS() involverer denne evne. Hvis den angivne mønsterværdi ikke findes, returnerer PATINDEKS () nul.
eksempel: Vælg E-mail, PATINDEKS (‘%aaa.com, e-mail’) som Førsteforekomst fra tblmedarbejder hvor PATINDEKS(‘%@aaa.med, E-mail) > 0
 erstat () funktion
erstat () funktion
erstat(String_ekspression, mønster, Replacement_Value), denne funktion erstatter alle forekomster position af en bestemt streng værdi med en anden streng værdi.
eksempel: alle. COM-strenge erstattes med. net
Vælg E-mail, erstat(e-mail, ‘.com’, ‘.net’) som Konverteretemail fra tblmedarbejder
 ting () funktion
ting () funktion
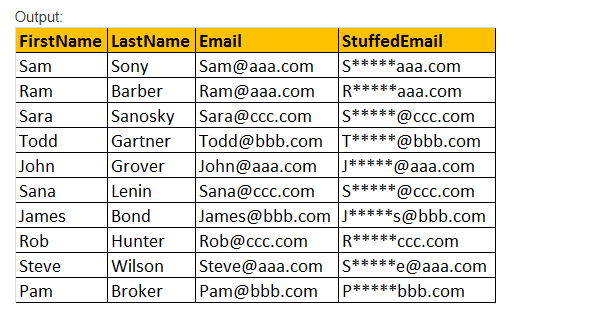
ting(Original_udtryk, Start, Længde, Udskiftning_udtryk), denne ting () funktion indsætter kun Udskiftning_udtryk, som er angivet i startpositionen, sammen med at fjerne de tegn, der er angivet ved hjælp af Længdeparameterværdiudtryk.
eksempel: Vælg fornavn, efternavn, e-mail, ting(E-Mail,2,3,’*****’) som StuffedEmail fra tblmedarbejder.
 Datotidsfunktion
Datotidsfunktion
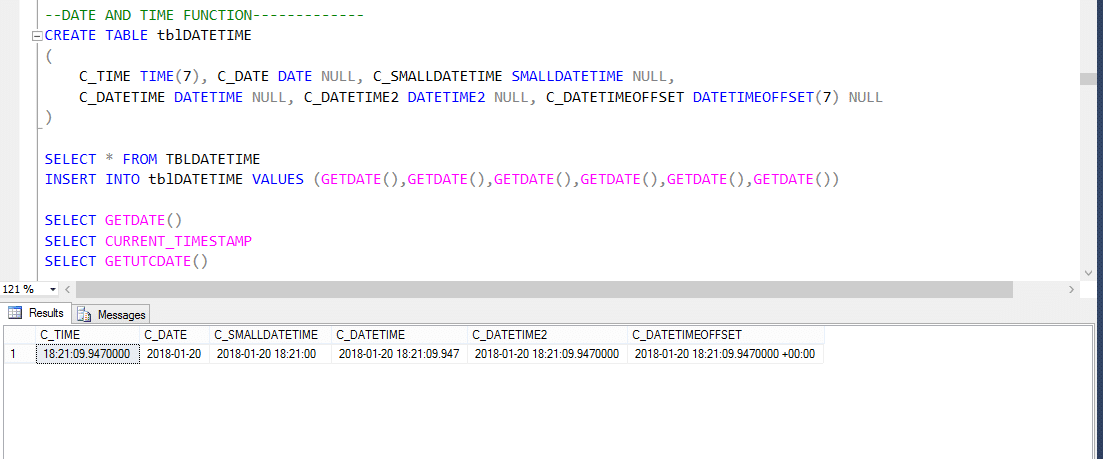
der er flere indbyggede DateTime-funktioner tilgængelige i SERVERDATABASEN. De fleste af følgende funktioner kan bruges til at få det aktuelle system dato og klokkeslæt, og hvor du har installeret.
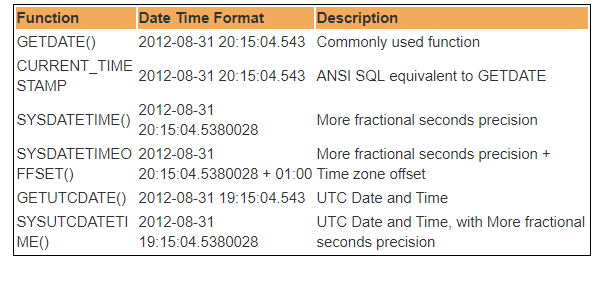 derfor står UTC for Koordineret Universal Time, baseret på hvilken verden regulerer Ure og tidsdata. Bemærkelsesværdig. der er mindre forskelle mellem GMT og UTC, men til de fleste almindelige formål er UTC synonymt med GMT.
derfor står UTC for Koordineret Universal Time, baseret på hvilken verden regulerer Ure og tidsdata. Bemærkelsesværdig. der er mindre forskelle mellem GMT og UTC, men til de fleste almindelige formål er UTC synonymt med GMT.
så lad os tage et andet eksempel som vist nedenfor;
isDate () – funktion
ISDATE() – denne funktion kontrollerer, om den eneste angivne værdi er, og der findes en gyldig dato, klokkeslæt eller DateTime. Derefter, det vil vende tilbage 1 For succes, 0 for fiasko.
eksempel:
Vælg ISDATE (‘PRAGIM’) — det returnerer 0
eksempel:
Vælg ISDATE (Getdate ()) — det vender tilbage1
eksempel:
Vælg ISDATE(‘2018-01-20 21:02:04.167’) — det returnerer 1
Bemærk: For datetime2-værdier returnerer IsDate nul.
eksempel:
Vælg ISDATE(‘2018-01-20 22:02:05.158.1918447’) — det vender tilbage 0.
dag() funktion
dag() – denne funktion returnerer kun Månedens Dagnummer for den givne dato.
eksempler:
Vælg dag(GETDATE()) — det giver output på vegne af månedens dagnummer og baseret på det aktuelle system DateTime.
Vælg dag(’01/14/2018′) — den returnerer 14
måned() funktion
måned() – Denne funktion giver output på vegne af ‘Månedens nummer for året’ for den givne dato.
eksempler:
Vælg måned(GETDATE()) — denne funktion giver output på vegne af ‘årets Månedsnummer’ og baseret på den aktuelle systemdato og-tid.
Vælg måned(’05/14/2018) — det returnerer 5
år() funktion
år() – denne funktion giver output på vegne af ‘årstal’ for den givne dato
eksempler:
Vælg år(GETDATE()) — returnerer årstallet og baseret på den aktuelle systemdato
vælg år(’01/20/2018) — det returnerer 2018
Datename() funktion
Datename(datepart, Dato) – denne funktion returnerer kun et strengudtryk, og det repræsenterer kun en del af den givne dato. Disse funktioner består af 2 parametre.
den første parameter ‘DatePart’ angiver, den del af datoen, som vi ønsker. Den anden parameter er den rigtige dato, hvorfra vi ønsker den del af datoen.
 eksempel 1:
eksempel 1:
Vælg DATENAVN(dag, ‘2017-04-20 13:47:47.350’) — det returnerer 20
eksempel 2:
Vælg DATENAME (ugedag, ‘2017-04-20 13:47:47.350’) — det vender tilbage torsdag
eksempel 3:
Vælg DATENAME(måned, ‘2017-04-20 13:47:47.350’) — det vender tilbage April
så lad os tage et eksempel ved hjælp af nogle af disse DateTime-funktioner. Overvej tabellen tblmedarbejdere.
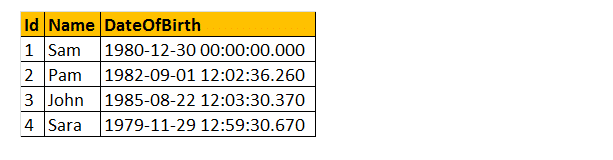 eksempel: Jeg vil returnere alt Navn, Datoofbirth, Day, MonthNumber, MonthName og Year som vist nedenfor.
eksempel: Jeg vil returnere alt Navn, Datoofbirth, Day, MonthNumber, MonthName og Year som vist nedenfor.
Vælg navn, Datoofbirth, DateName (ugedag,Datoofbirth) as, måned (Datoofbirth) som Månednummer, DateName (måned, Datoofbirth) as, år (Datoofbirth) fra tblmedarbejdere

DatePart () – funktion
DatePart(DatePart, Dato) – denne funktion giver et heltal, der repræsenterer den angivne DatePart-værdi. For det meste funktion ligner DateName() funktion. DateName () returnerer kun nvarchar-værdi, mens DatePart () kun returnerer en heltalsværdi. De gyldige datepart-parameterværdier vises nedenfor.
eksempler:
Vælg DATEPART (ugedag, ‘2012-08-30 19:45:31.793’) — det vil returnerer 5
Vælg DATENAME (ugedag, ‘2012-08-30 19:45:31.793’) — den vender tilbage torsdag
DateAdd() funktion
DATEADD (datepart, NumberToAdd, date) – Denne funktion giver kun DateTime, efter specificeret term NumberToAdd, og til den datepart, der er angivet for den givne dato.
eksempler:
Vælg Datoadd (dag, 10, ‘2018-01-20 19:45:31.793’) — det vender tilbage ‘2018-01-30 19:45:31.793’
Vælg DateAdd (dag, -10, ‘2012-08-30 19:45:31.793’)– det vender tilbage ‘2018-01-20 19:45:31.793’
DatedDiff () funktion
DATEDIFF(datepart, startdate, enddate) – denne funktion giver optællingen af de angivne datepart-grænser krydset mellem den angivne startdato og slutdato.
eksempler:
Vælg DATEDIFF(måned, ’11/30/2005′,’01/31/2006′) — det vender tilbage 2
Vælg DATEDIFF(dag, ’11/30/2005′,’01/31/2006′) — det returnerer 62
så lad os tage et eksempel, lad os antage, at vi har en tabel nedenfor;
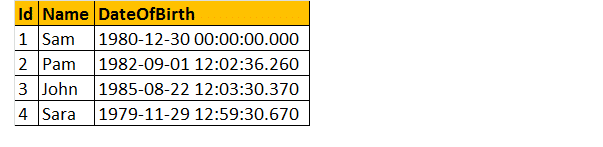
så skriv en forespørgsel for at finde ud af en persons alder, når fødselsdatoen er angivet.

endelig vil output se ud som vist nedenfor.
Cast() og konverter() funktioner
for at konvertere en enkelt enhed datatype til en anden, CAST og konvertere funktioner kan bruges.
syntaks for CAST og konverter funktion:
CAST ( udtryk som data_type)
konverter ( data_type , udtryk)
derudover, som du kan se, at CONVERT () – funktionen har en valgfri stilparameterværdi, mens CAST () – funktionen mangler denne funktion.
så lad os tage et eksempel, Vi tager en tabel nedenfor;
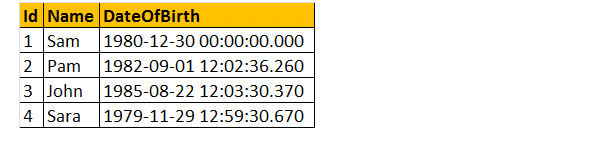 det følgende 2 forespørgsler konverterer Dateofbirths DateTime datatype til NVARCHAR. Den første forespørgsel bruger funktionen CAST (), og den anden bruger funktionen CONVERT (). Endelig er output nøjagtigt det samme for begge forespørgsler som vist nedenfor.
det følgende 2 forespørgsler konverterer Dateofbirths DateTime datatype til NVARCHAR. Den første forespørgsel bruger funktionen CAST (), og den anden bruger funktionen CONVERT (). Endelig er output nøjagtigt det samme for begge forespørgsler som vist nedenfor.
Vælg ID, Navn DateOfBirth, Cast(DateOfBirth som nvarchar) som ConvertedDOB fra tblmedarbejdere.
Vælg ID, Navn DateOfBirth, Convert(DateOfBirth as nvarchar) som ConvertedDOB fra tblmedarbejders.
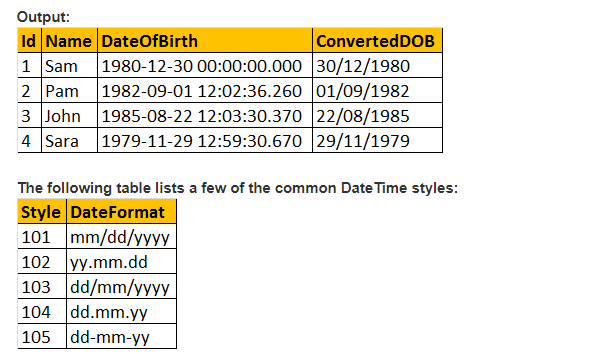
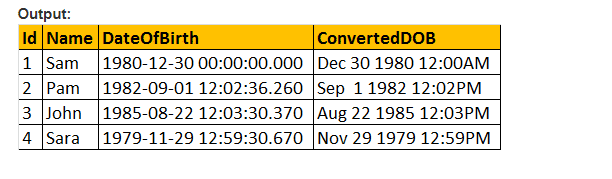 så lad os lave stilparameteren for funktionen konverter() og formatere datoen, som vi gerne vil have den. Så vi bruger 103 som passerer argumentet for stilparameter i nedenstående forespørgsel, og som formaterer datoen som dd/mm/yy.
så lad os lave stilparameteren for funktionen konverter() og formatere datoen, som vi gerne vil have den. Så vi bruger 103 som passerer argumentet for stilparameter i nedenstående forespørgsel, og som formaterer datoen som dd/mm/yy.
Vælg ID, Navn, DateOfBirth, Convert (nvarchar, DateOFBirth, 103) som ConvertedDOB fra tblmedarbejders.
så lad os se på praktisk eksempel ved hjælp af CAST() funktion;
lad os antage, at vi har en registreringstabel nedenfor som;
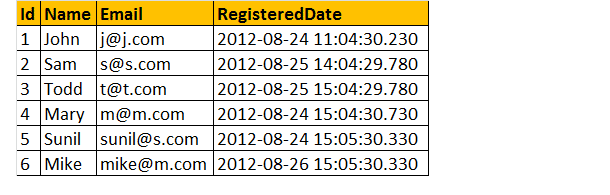 lad os nu finde det samlede antal registrering om dagen.
lad os nu finde det samlede antal registrering om dagen.
eksempel: vælg CAST (Registeretdato som dato) som Registreringdato, tæl (Id) som Totalregistrationer tblregistrationer gruppe efter CAST(Registeretdato som dato)
Output: endelig vil output se ud som ;
brugerdefinerede funktioner
der er 3 typer brugerdefinerede funktioner i serveren, som som
- Skalarfunktioner
- indbyggede tabelværdier
- multistatement tabelværdier
Skalarfunktioner
skalarfunktioner varierer i parametre, der måske eller måske ikke har parametre, og giver altid en enkelt (skalar) værdi i output. Derfor kan den returnerede værdi være af ethvert datatypeformat undtagen tekstværdi, tekst, billede, markør og tidsstempel.
eksempel: Så lad os udvikle en funktion, der beregner og returnerer en persons alder i output. Følgelig, at sammenligne den alder, vi krævede for, fødselsdato. Så lad os passere fødselsdato som en parameter. Derfor vil alder () funktion returnere et heltal og vil acceptere dato parameter.
 Vælg dbo.Alder (dbo.Alder(’10/08/1982′).
Vælg dbo.Alder (dbo.Alder(’10/08/1982′).
så lad os tage et praktisk eksempel i nedenstående tabel som følger;
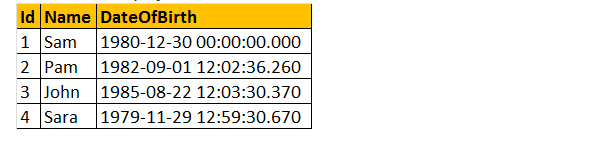
skalære brugerdefinerede funktioner kan bruges i Select-klausulen som vist nedenfor.
Vælg navn, Datoofbirth, dbo.Alder (DateOfBirth) som Alder fra tblmedarbejdere
 se for det meste teksten til funktionen Brug sp_helptekstfunktionnavn.
se for det meste teksten til funktionen Brug sp_helptekstfunktionnavn.
funktioner med indbygget tabelværdi
en funktion med indbygget tabelværdi returnerer altid en tabel som output.
så lad os tage et eksempel nedenfor; Opret en funktion, der returnerer medarbejdere efter køn.
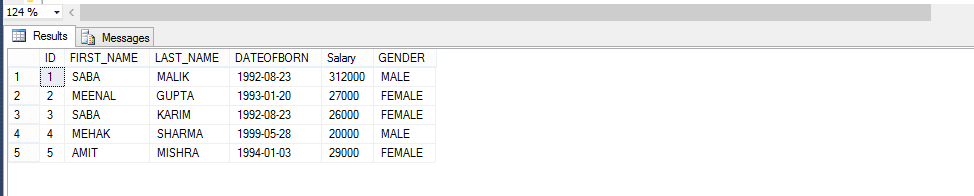
på grund af opkaldsmetoden til den brugerdefinerede funktion,
vælg * fra fn_ Employeebygender(‘mand’)
multi-STATEMENT TABLE VALUED FUNCTION
multi-statement table-valued functions er meget mere ligner Inline Table-valued functions og med nogle forskelle. Så lad os se på et eksempel, og bemærk derefter forskellene.
Medarbejderbord
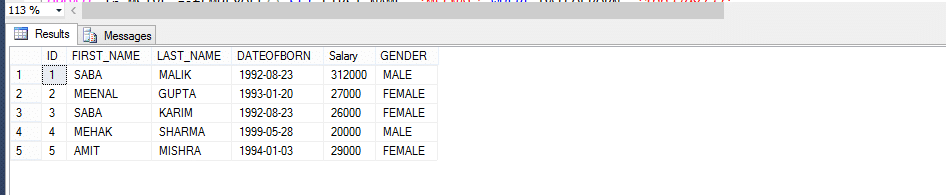
Multi-statement tabel værdsat funktion (MSTVF):
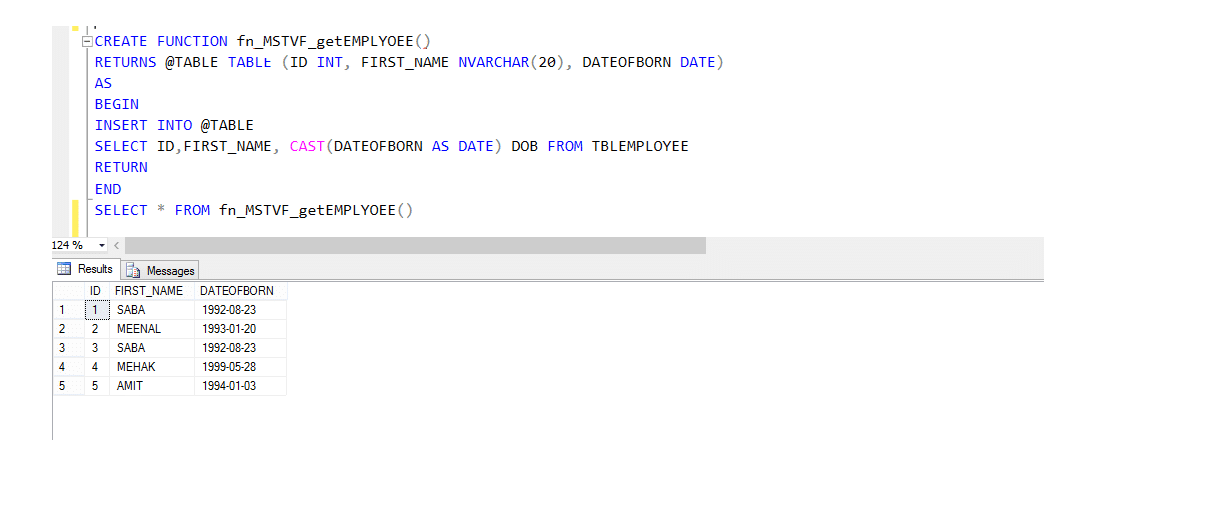 på grund af opkaldsmetode til VDE Multi-statement tabel værdsat funktion:
på grund af opkaldsmetode til VDE Multi-statement tabel værdsat funktion:
vælg * fra fn_MSTVF_GetEmployees()
konklusion
joinforbindelserne er meget forstående udtryk for begyndere i læringsfasen af kommandoer. Derfor, i samtalen, intervju spørger mindst et spørgsmål handler om, hvordan man tilslutter sig, og funktioner. Så, i dette indlæg, Jeg prøver at forenkle tingene for nye KVL-elever og gøre det let at forstå, at KVL slutter sig til. Desuden er de funktioner, en masse mennesker har problemer med at forstå faktiske arbejde funktion. Fordi
- om
- Seneste indlæg

- 14. April 2020
- Sådan arbejder du med underforespørgsler i Data Mining – 23. marts 2018
- Sådan bruger du Javascript-funktioner? – Marts 9, 2018
