Ga naar sectie
- SQL Introduction
- hoe te werken met SQL-Joins
- Inner Join
- links samenvoegen
- rechter Join
- volledige buitenste verbinding
- Cross join
- hoe te werken met vooraf SQL Joins
- links samenvoegen
- volledige buitenste verbinding
- soorten sleutels in SQL
- Kandidaatsleutel
- primaire sleutel
- unieke sleutel
- alternatieve sleutel
- samengestelde sleutel
- Supersleutel
- buitenlandse sleutel
- hoe te werken met SQL-functies
- LEFT () Function
- RIGHT () Function
- CHARINDEX () Function
- SUBSTRING() Function
- REPLICATE () Function
- SPACE () functie
- PATINDEX () functie
- REPLACE () Function
- STUFF() Function
- Datum Tijd functie
- isDate () functie
- Month () functie
- Year() Function
- Datename() Function
- Datepart () Function
- Dateadd () functie
- DatedDiff() Functie
- Cast() en Convert () functies
- door de gebruiker gedefinieerde functies
- scalaire functies
- Inline table-valued function
- MULTI-STATEMENT TABLE VALUED FUNCTION
- conclusie
SQL Introduction
SQL staat voor Structured Query Language. Het wordt hoofdzakelijk gebruikt voor gegevensmanipulatie, gegevenswijziging, en gegevensherwinning. Dit komt rond met Relational Database Management System (RDBMS).
we zullen meer leren over meer geavanceerde functies van SQL zoals Joins en functies.
hoe te werken met SQL-Joins
een eenvoudige join betekent het combineren van twee of meer tabellen in een bepaalde database. Een join werkt op een gemeenschappelijke entiteit van twee tabellen.
een join bevat 5 sub-joins die als; Inner join, Outer Join, Left Join, Right Join en Cross Join.
Inner Join
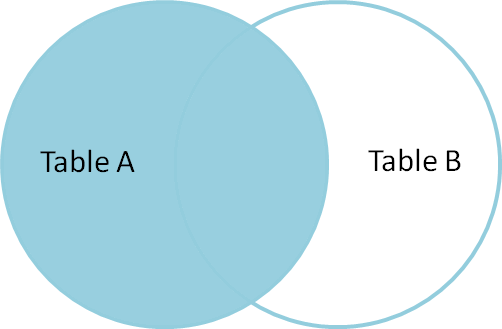
een inner join wordt gebruikt om records te selecteren die gemeenschappelijke of overeenkomende waarden bevatten in beide tabellen (Tabel A en Tabel B). Niet-matching worden geëlimineerd.
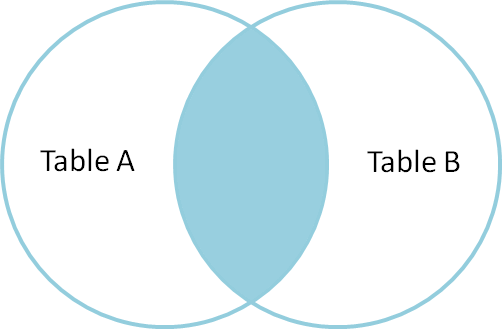
dus, laten we begrijpen het type joins, en met gemeenschappelijke voorbeelden en de verschillen tussen hen.
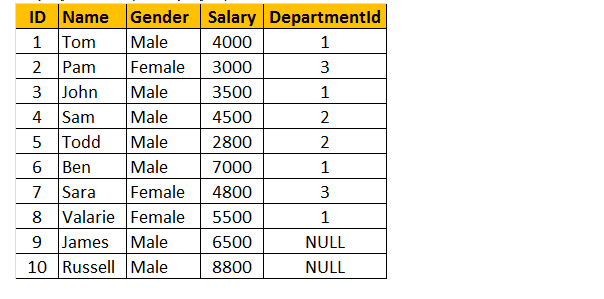
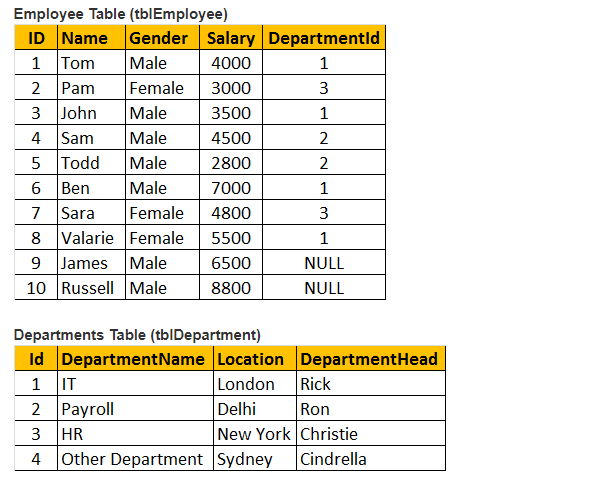
Tabel 1: Werknemerstabel (tblwerknemer))
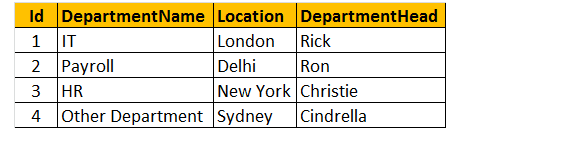
Tabel 2: Afdelingstabel (tbldeafdelingen))
dus, laten we table tblDepartments maken voor de uitvoering van een programma.

nu, voeg records in tabel tblDepartments.

laten we een andere tabel tblEmployee voor de uitvoering van een programma.

dus, voeg records in tabel tblEmployee.

daarom is een algemene formule voor joins.

om een query te maken om naam, geslacht, salaris en Afdelingsnaam te vinden van zowel de tabellen tblwerknemer en tbldeafdelingen.

opmerking: JOIN of INNER JOIN betekent hetzelfde. Maar altijd beter om INNER JOIN te gebruiken, en dit specificeert je intentie expliciet.
uitvoer: nu ziet de uiteindelijke uitvoertabel er zo uit;
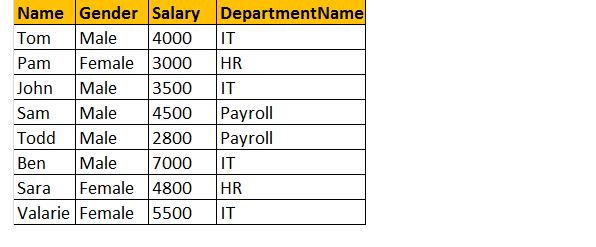
Als u naar het outputvenster kijkt, hebben wij slechts 8 rijen, maar in de lijst tblEmployee, hebben wij 10 rijen. We hebben JAMES en RUSSELL records niet. Dit komt omdat de afdeling in tabel tblwerknemer nul is voor deze twee werknemers en niet overeenkomt met hun ID kolom in tabel tbldeafdelingen.
dus in een eindafschrift retourneert Inner Joins alleen overeenkomende rijen uit zowel de tabellen als niet-overeenkomende rijen worden geëlimineerd vanwege de subquery.
links samenvoegen
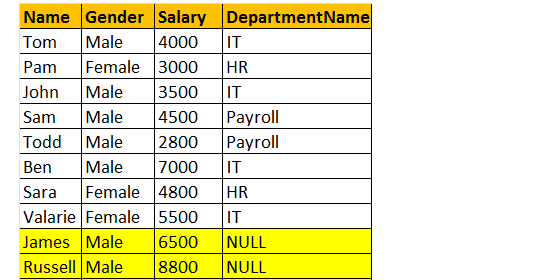
LEFT Join retourneert alle bijpassende rijen en niet-bijpassende rijen van de linker zijtafel. Daarnaast worden Inner join en Left join uitgebreid met elkaar gebruikt.
dus, laten we een voorbeeld nemen, Ik wil alle rijen uit de tblemployee tabel, inclusief JAMES en RUSSELL records. Dan zal de uitvoer eruit zien als;

rechter Join
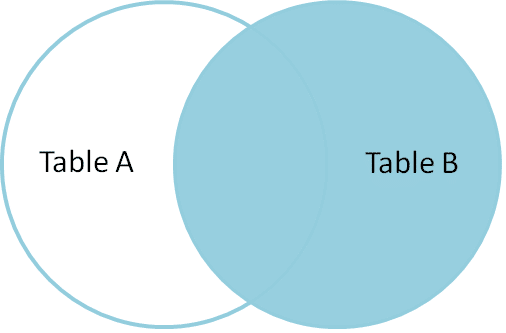
RIGHT Join retourneert alle bijpassende rijen en niet-bijpassende rijen van de rechter bijzettafel.
dus, laten we een voorbeeld nemen; Ik wil alle rijen van de juiste tabellen die betrokken zijn bij de join. Als gevolg zou zijn als;

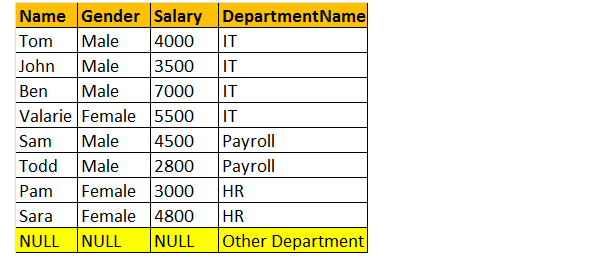
volledige buitenste verbinding

OUTER join of FULL OUTER Join retourneert alle rijen uit zowel de linker-als de rechtertabellen, inclusief de niet-overeenkomende rijen uit de tabellen.
dus, laten we een voorbeeld nemen; Ik wil alle rijen van beide tabellen die betrokken zijn bij de join.

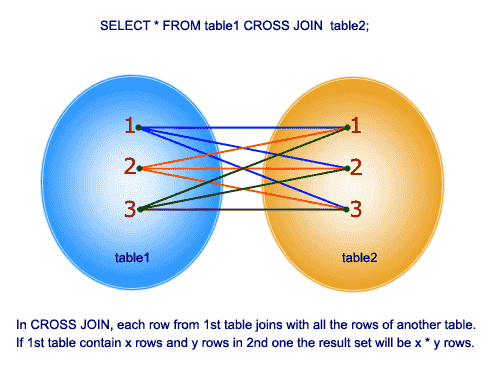
Cross join
deze join geeft het Cartesiaanse product van de 2 tabellen in de join functie. Dit lid bevat geen clausule.
dus, laten we een voorbeeld begrijpen: In de tblEmployee-lijst hebben wij 10 rijen en in de tbldepartments-lijst hebben wij 4 rijen. Dus, een kruising verbindt tussen deze 2 tabellen produceert 40 rijen.

hoe te werken met vooraf SQL Joins
In deze sessie zal ik deze dingen als volgt uitleggen;
- geavanceerde of intelligente joins in SQL Server.
- haal alleen de niet-overeenkomende rijen uit de linker tabel op.
- haal alleen de niet-overeenkomende rijen uit de juiste tabel op.
- haal alleen de niet-overeenkomende rijen op uit zowel de linker-als de rechtertabellen.
laten we dus zowel de tabellen van de werknemer als van de afdeling bekijken.
links samenvoegen
dus, laten we een voorbeeld begrijpen, Ik wil alleen de niet-overeenkomende rijen van de linker bijzettafel ophalen.

Output: uiteindelijk zal de output er zo uitzien;

rechter Join
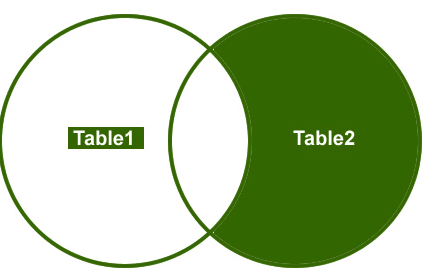
dus, laten we een voorbeeld begrijpen, Ik wil alleen de niet-overeenkomende rijen van de rechter bijzettafel ophalen.

Output: uiteindelijk zal de output er zo uitzien;

volledige buitenste verbinding
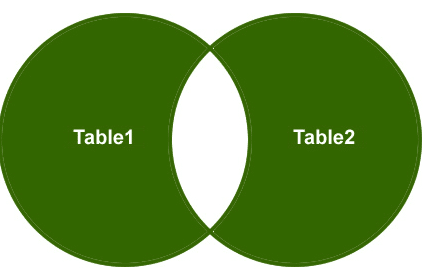
dus, laten we een voorbeeld begrijpen, Ik wil alleen de niet-overeenkomende rijen van de rechter zijtafel en de linker zijtafel ophalen en bijpassende rijen moeten worden geëlimineerd.

uitvoer: ten slotte zal de uitvoer er zo uitzien;
soorten sleutels in SQL
een sleutel in SQL is een gegevensveld dat uitsluitend een record identificeert. In een ander woord, een sleutel is een set van kolom(s) die wordt gebruikt om het record in een tabel uniek te identificeren.
- maak relaties tussen twee tabellen.
- uniciteit en aansprakelijkheid behouden in een tabel.
- consistente en geldige gegevens in een database bewaren.
- kan helpen bij het snel ophalen van gegevens door het vergemakkelijken van indexen op kolom(s).
een SQL-server bevat de volgende sleutels;
- Kandidaatsleutel
- primaire sleutel
- unieke sleutel
- alternatieve sleutel
- samengestelde sleutel
- Supersleutel
- buitenlandse sleutel
voordat u verder gaat, en bekijk de afbeelding hieronder;
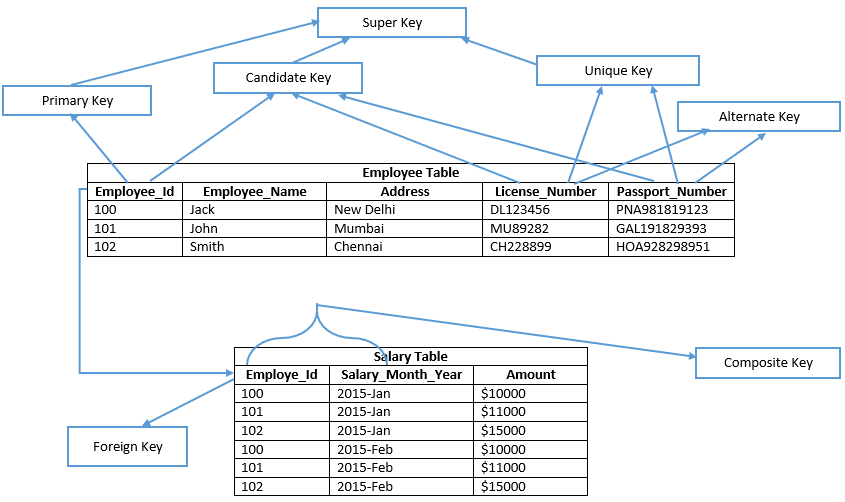
laten we elke sleutel in detail begrijpen
Kandidaatsleutel
een kandidaatsleutel is een sleutel van een tabel die kan worden geselecteerd als een primaire sleutel van de tabel en een tabel kan meerdere kandidaatsleutels hebben, daarom kan een worden geselecteerd als een primaire sleutel.
voorbeeld: Employee_Id, License_Number, & Passport_Number toont kandidaatsleutels
primaire sleutel
een primaire sleutel is vergelijkbaar met de geselecteerde kandidaatsleutel van de tabel om elk gegevensrecord uniek in de tabel te verifiëren. Daarom bevat de primaire sleutel geen null-waarde in een van de kolommen van een tabel en behoudt het ook unieke waarden in de kolom. In het gegeven voorbeeld definieert Employee_Id de primaire sleutel van de Employee table. Daarom maakt primaire sleutel in SQL Server Management Studio Standaard Een geclusterde index op een heaptabel en een tabel die niet uit een geclusterde index bestaat, wordt een heaptabel genoemd. Of een niet-geclusterde primaire sleutel op een tabel expliciet wordt gedefinieerd op indextype.
bovendien kan een tabel slechts één primaire sleutel hebben en kan de primaire sleutel in SQL Server worden gedefinieerd met behulp van SQL-statements:
- CRETE TABLE statement (op het moment van het aanmaken van de tabel) – als gevolg hiervan definieert het systeem de naam van de primaire sleutel.
- ALTER TABLE statement (met behulp van een primaire sleutel beperking) –als gevolg hiervan, de gebruiker zelf declareert de naam van de primaire sleutel beperking.
voorbeeld: Employee_Id is een primaire sleutel van de tabel met werknemers.
unieke sleutel
een unieke sleutel is net als de primaire sleutel en bevat geen dubbele waarden in de kolom. Het heeft hieronder verschillen in de vergelijking van de primaire sleutel:
- het staat een null waarde in de kolom.
- standaard maakt het een niet-geclusterde index-en heaptabellen aan.
alternatieve sleutel
de alternatieve sleutel is vergelijkbaar met de kandidaat-sleutel, maar is niet geselecteerd als primaire sleutel in de tabel.
voorbeeld: License_Number en Passport_Number zijn alternatieve sleutels.
samengestelde sleutel
samengestelde sleutel (ook bekend als samengestelde sleutel of aaneengeschakelde sleutel) is een groep van twee of meer kolommen die elke rij van een tabel uniek identificeert. Bovendien kan een enkele eenheidskolom van een samengestelde sleutel de gegevensrecords mogelijk niet op unieke wijze verifiëren. Als gevolg daarvan, het kan ofwel primaire sleutel of kandidaat sleutel ook.
voorbeeld: in de tabel, Employee_Id & Salary_Month_Year controleren beide kolommen elke rij uniek in de salarislijst. Daarom is de kolom Employee_Id of Salary_Month_Year in de tabel, die elke rij niet uniek kan identificeren. We kunnen een enkele samengestelde primaire sleutel op de salarislijst maken met behulp van Employee_Id en Salary_Month_Year kolomnamen.
Supersleutel
Supersleutel is een verzameling kolommen waarvan alle kolommen van de tabel functioneel afhankelijk zijn. Vanwege de reeks kolommen die elke rij in een tabel uniek identificeert. Met een ander woord, Deze sleutel bevat enkele extra kolommen die niet strikt nodig zijn om elke rij in de tabel uniek te verifiëren. Het lijkt erop dat primaire sleutel en kandidaat sleutels minimale superkeys zijn of je kunt zeggen een subset van superkeys.
dus, laten we eens kijken naar boven voorbeeld, in de werknemer tabel, kolom Naam Employee_Id is nauwelijks voldoende om een unieke rij van de tabel te verifiëren. Dus, dat elke set van een kolom van werknemer tabel die Employee_Id bevat is een superkey voor werknemer tabel.
bijvoorbeeld: {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id, Employee_Name, Address} etc.
License_Number en Passport_Number zijn de naam van de kolommen, het kan ook uniek controleren om het even welke rij van de tabel. Iedereen van kolom Naam ingesteld die bestaat License_Number of Passport_Number of Employee_Id is een superkey van de tabel.
bijvoorbeeld: {License_Number, Employee_Name, Address}, {License_Number, Employee_Name, Passport_Number}, {Passport_Number,Employee_Name, Address, License_Number}, {Passport_Number, Employee_Name}, {Passport_Number, Employee_Id} etc.
buitenlandse sleutel
een FK definieert de relatie tussen twee of meer tabellen tegelijk. Een primaire sleutel van een enkele tabel wordt verwezen naar een buitenlandse sleutel in een andere tabel. Een buitenlandse sleutel kan dubbele waarden in een tabel hebben en kan ook null-waarden hebben als de kolomnaam is gedefinieerd om null-waarden nog te accepteren.
bijvoorbeeld kolomnaam “Employee_Id” ( een primaire sleutel van de tabel met werknemers ) is een buitenlandse sleutel in de salarislijst.
opmerking: sleutels zoals primaire sleutel en unieke sleutel maken indexen met sleutels kolommen. Georganiseerde gegevens in B-Tree structuur knooppunt (Balanced Tree: blad knooppunten zijn allemaal op het verschillende niveau van de root kant) in SQL Server. Vandaar, creëert de niet-geclusterde index een afzonderlijke structuur van de basisgegevenslijst maar de geclusterde index converteert basisgegevenslijst van heapstructuur naar een B-boomstructuur.
bovendien creëert de geclusterde index geen aparte structuur naast de basistabel en dat is de reden waarom we slechts één geclusterde index op een tabel kunnen maken. Daarom kunnen we een tabel sorteren op slechts één manier (het kan meerdere kolommen hebben om te sorteren, maar het sorteren kan op één enkele manier worden gedaan) wat de volgorde is van de geclusterde index.
hoe te werken met SQL-functies
een functie is een entity-programma dat is opgeslagen in de SQL Server-Database. Verder zullen we uitkijken naar een aantal zeer nuttige ingebouwde functie en door de gebruiker gedefinieerde functies.
Coalesce functie
Coalesce (): deze functie geeft alleen de eerste niet-nulwaarde terug. Dus, laten we een voorbeeld nemen over Coalesce() functie.
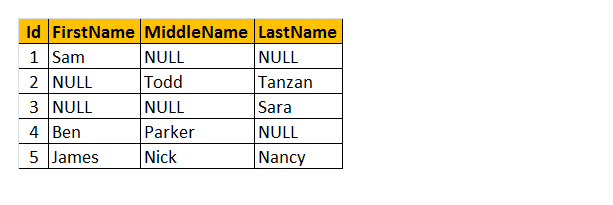 laten we de tabel begrijpen als de naam ‘werknemer’ hierboven. Als gevolg hiervan, kunt u zien dat sommige van de werknemers hebben hun voornaam ontbreekt, sommige hebben een middelste naam en sommige van hen hebben achternaam ontbreekt. Dus, Ik wil alleen “naam” van de werknemer terug te keren.
laten we de tabel begrijpen als de naam ‘werknemer’ hierboven. Als gevolg hiervan, kunt u zien dat sommige van de werknemers hebben hun voornaam ontbreekt, sommige hebben een middelste naam en sommige van hen hebben achternaam ontbreekt. Dus, Ik wil alleen “naam” van de werknemer terug te keren.
Hoe werkt het? Begrijp, we verwerken voornaam, middelnaam en achternaam kolommen als parameters om COALESCE () functie. Daarom retourneert deze functie de enige eerste niet-null waarde van 3 van de kolommen.
Query: Selecteer Id, COALESCE (voornaam, middelnaam, achternaam) als naam van tblwerknemer
tenslotte zal de uitvoer er zo uitzien;
 LEFT () Function
LEFT () Function
LEFT (Character_Expression, Integer_Expression)-deze functie retourneert het opgegeven aantal tekens aan de linkerkant van de gegeven character value expression.
voorbeeld: selecteer links (‘ABCDE’, 3)
Output: ABC
RIGHT () Function
RIGHT (Character_Expression, Integer_Expression)-deze functie retourneert het opgegeven aantal tekens van de rechterkant van de gegeven character value expression.
voorbeeld: rechts selecteren (‘ABCDE’, 3)
uitvoer: CDE
CHARINDEX () Function
CHARINDEX (‘Expression_To_Find’, ‘Expression_To_Search’, ‘Start_Location’) – deze functie retourneert de beginpositie van de opgegeven waarde-expressie in een teken substring. Start_Location parameter is optioneel.
voorbeeld: laten we begrijpen, we maken de startpositie van het teken ‘ @ ‘ in de e-mailstring ‘[email protected]’.
select CHARINDEX ( ‘ @’, ‘[email protected]’,1)
uitvoer: 5
SUBSTRING() Function
SUBSTRING (expression’, ‘Start’, ‘Length’) – deze functie retourneert substring (subdeel van de string), uit de gegeven waarde-expressie. Bovendien, wanneer u de startpositie specificeert met behulp van de’ start ‘parameter en het andere aantal tekens in de substring met behulp van’ lengte ‘ parameter. Alle drie de parameters zijn verplicht.
voorbeeld: Ik wil alleen domein deel van de gegeven e-mail weer te geven ‘[email protected]’.
select SUBSTRING (‘[email protected]’,6, 7)
uitvoer: bbb.com
als gevolg hiervan hebben we de codering gemaakt met de beginpositie en de lengteparameters. In plaats van de parameters hardcoderen, kunnen we ze dynamisch ophalen met behulp van CHARINDEX() en LEN() string functies zoals hieronder getoond.
voorbeeld:
select SUBSTRING (‘[email protected]’, (CHARINDEX ( ‘ @ ‘, ‘[email protected]’) + 1), (LEN (‘) [email protected]’) – CHARINDEX ( ‘ @’, ‘[email protected]’)))
uitvoer: bbb.com
dus, laten we een echt voorbeeld nemen met het gebruik van LEN (), CHARINDEX() en SUBSTRING() functies. Laten we denken dat we een tabel hebben zoals hieronder getoond;
 de vraag is dus hoe u het totale aantal e-mails op hun domein kunt vinden.
de vraag is dus hoe u het totale aantal e-mails op hun domein kunt vinden.
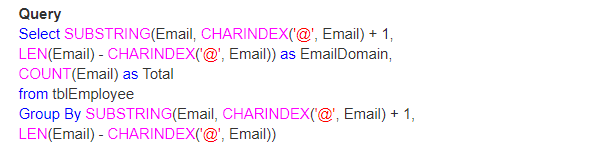
Output: uiteindelijk zal de output er zo uitzien;
 REPLICATE () Function
REPLICATE () Function
REPLICATE (String_To_Be_Replicated, Number_Of_Times_To_Replicate) – deze functie herhaalt het gegeven punt van de string, en voor het opgegeven aantal keren.
voorbeeld: selecteer repliceren (‘Pragim’, 3)
uitvoer: Pragim Pragim Pragim
laten we het hebben over een praktisch voorbeeld van het gebruik van de functie REPLICATE() : We zullen deze tabel het grootste deel van de tijd gebruiken, en voor de rest van onze voorbeelden in dit artikel.
dus, laten we aannemen dat we een tabel hebben zoals hieronder getoond;
 Query: selecteer Voornaam, Achternaam, SUBSTRING (Email, 1, 2) + repliceren(‘*’,5) +
Query: selecteer Voornaam, Achternaam, SUBSTRING (Email, 1, 2) + repliceren(‘*’,5) +
SUBSTRING (e-mail, CHARINDEX (‘@’, e – mail), LEN (e-mail) – CHARINDEX (‘@ ‘ , e-mail)+1) als e-mail
van tblwerknemer
laten we e-mail maken met 5 * (ster) symbolen. Dan zou de uitvoer zijn als deze
 SPACE () functie
SPACE () functie
SPACE (Number_Of_Spaces) – deze functie retourneert het enige aantal spaties, en gespecificeerd door het argument term Number_Of_Spaces.
voorbeeld: de functie SPACE (5) voegt 5 spaties in tussen voornaam en achternaam
selecteer Voornaam + spatie(5) + achternaam Als volledige naam uit tblwerknemer
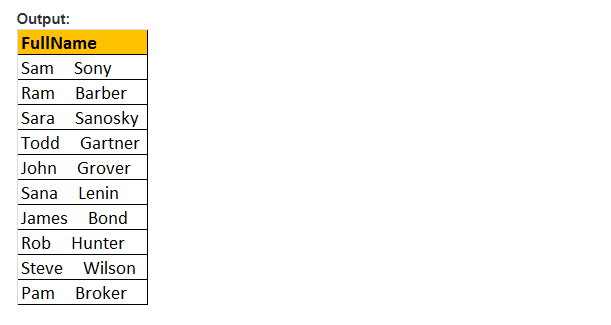 PATINDEX () functie
PATINDEX () functie
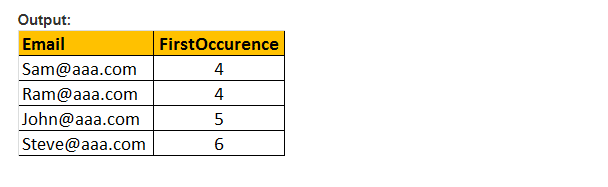
deze functie geeft alleen de beginlocatie van het eerste voorkomen van een patroon in een opgegeven effectieve expressie terug. Er zijn dus slechts twee argumenten nodig, en het te doorzoeken patroon en de uitdrukking. Daarom is PATINDEX () vergelijkbaar met CHARINDEX (). Met CHARINDEX() kunnen we geen jokertekens gebruiken, terwijl PATINDEX () dit mogelijk maakt. Als de opgegeven patroonwaarde niet wordt gevonden, geeft PATINDEX() nul terug.
voorbeeld: selecteer E-Mail, PATINDEX (‘%aaa.com, e-mail’) als eerste optreden van de werknemer waar PATINDEX (‘%@aaa.com’, Email) > 0
 REPLACE () Function
REPLACE () Function
REPLACE (String_Expression, Pattern, Replacement_Value), deze functie vervangt alle occurrences positie van een opgegeven string waarde door een andere string waarde.
voorbeeld: Alle. COM-tekenreeksen worden vervangen door. net
Selecteer Email, REPLACE (Email,’. com’,’.net’) as ConvertedEmail from tblEmployee
 STUFF() Function
STUFF() Function
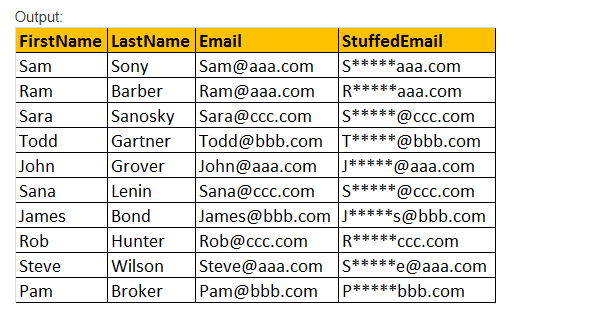
STUFF(Original_Expression, Start, Length, Replacement_expression), This STUFF() function only inserts Replacement_expression, which is specified at the start position, along with removing the characters specified using Length parameter value expression.
voorbeeld: selecteer Voornaam, Achternaam, Email, STUFF(Email),2,3,’*****’) als gestoffeerde e-mail van de werknemer.
 Datum Tijd functie
Datum Tijd functie
er zijn verschillende ingebouwde DateTime functies beschikbaar in SQL Server database. De meeste van de volgende functies kunnen worden gebruikt om de huidige datum en tijd van het systeem te krijgen, en waar u SQL server hebt geïnstalleerd.
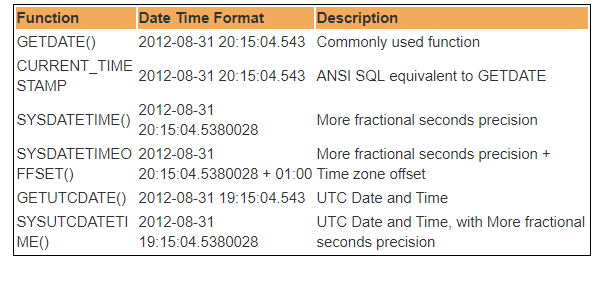 vandaar dat UTC staat voor Coordinated Universal Time, op basis waarvan de wereld klokken en tijdgegevens reguleert. Opmerkelijk. er zijn kleine verschillen tussen GMT en UTC, maar voor de meest voorkomende doeleinden, UTC is synoniem over met GMT.
vandaar dat UTC staat voor Coordinated Universal Time, op basis waarvan de wereld klokken en tijdgegevens reguleert. Opmerkelijk. er zijn kleine verschillen tussen GMT en UTC, maar voor de meest voorkomende doeleinden, UTC is synoniem over met GMT.
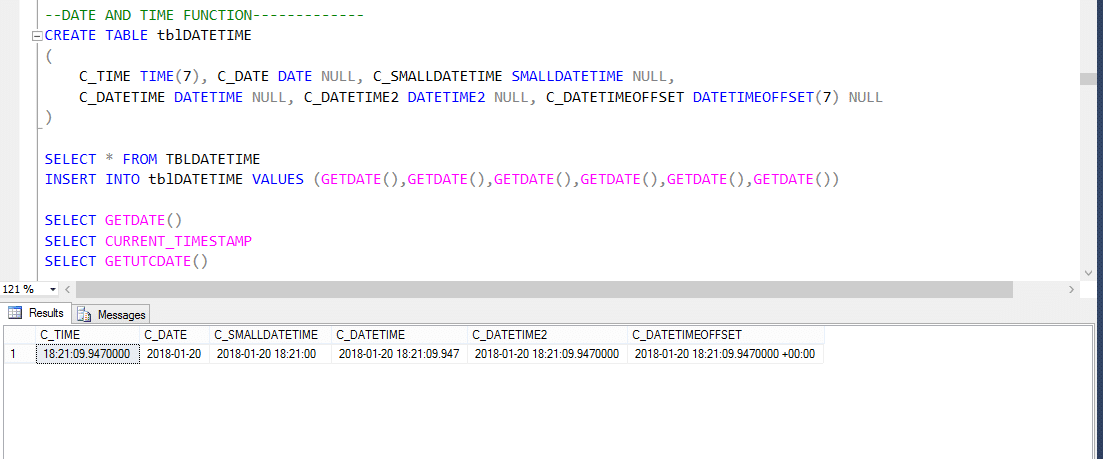
dus, laten we een ander voorbeeld nemen zoals hieronder getoond;
isDate () functie
ISDATE () – deze functie controleert of de enige gegeven waarde, en bestaat een geldige datum, tijd, of DateTime. Dan, het zal terugkeren 1 voor succes, 0 voor mislukking.
voorbeeld:
Select ISDATE(‘PRAGIM’) — het geeft 0
voorbeeld:
Select ISDATE(Getdate()) — het geeft 1
voorbeeld:
Select ISDATE(‘2018-01-20 21:02:04.167’) — het geeft 1
Opmerking: Voor datetime2 waarden geeft IsDate nul terug.
voorbeeld:
selecteer ISDATE(‘2018-01-20 22:02:05.158.1918447’) — het geeft 0 terug.
Day () functie
Day () – Deze functie geeft alleen het ‘dagnummer van de maand’ van de opgegeven datum terug.
voorbeelden:
Select DAY (GETDATE ()) — het geeft de uitvoer namens het dagnummer van de maand, en op basis van de huidige systeem DateTime.
Select DAY — ’01/14/2018′) – het geeft 14
Month () functie
Month () – deze functie geeft de output namens het’ maandnummer van het jaar ‘ van de opgegeven datum.
voorbeelden:
Selecteer maand (GETDATE ()) — deze functie geeft de uitvoer namens het ‘maandnummer van het jaar’, en gebaseerd op de huidige systeemdatum en-tijd.
Select Month(’05/14/2018) — it will returns 5
Year() Function
Year() – This function will give the output on behalf of the ‘Year number’ of the given date
Examples:
Select Year(GETDATE()) — Returns the year number, and based on the current system date
Select Year(’01/20/2018) — it will returns 2018
Datename() Function
Datename(datepart, date) – deze functie geeft alleen een Tekenreeksuitdrukking terug en vertegenwoordigt slechts een deel van de opgegeven datum. Deze functies bestaan uit 2 parameters.
de eerste parameter’ DatePart ‘ specificeert het deel van de datum dat we willen. De tweede parameter is de echte Datum, van waaruit we het deel van de datum willen.
 Voorbeeld 1:
Voorbeeld 1:
selecteer DATENAME (Day, ‘2017-04-20 13:47:47.350’) — het geeft 20
Voorbeeld 2:
Selecteer DATENAME (weekdag, ‘2017-04-20 13:47:47.350’) — het zal donderdag
Voorbeeld 3:
Selecteer DATENAME (maand, ‘2017-04-20 13:47:47.350’) — het geeft April
dus, laten we een voorbeeld nemen met behulp van enkele van deze DateTime functies. Denk aan de tafel tbllewerknemers.
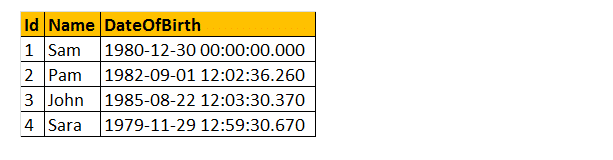 voorbeeld: Ik wil alle Naam, DateOfBirth, Day, MonthNumber, MonthName en Year retourneren zoals hieronder getoond.
voorbeeld: Ik wil alle Naam, DateOfBirth, Day, MonthNumber, MonthName en Year retourneren zoals hieronder getoond.
Select Name, DateOfBirth, Datenaam (weekdag,DateOfBirth) as, Month(DateOfBirth) as MonthNumber, Datenaam (MONTH, DateOfBirth) as, Year (DateOfBirth) as From tblle employees

Datepart () Function
Datepart (DatePart, Date) – Deze functie geeft een geheel getal dat de opgegeven datepart waarde weergeeft. Meestal functie is vergelijkbaar met datename () functie. DateName() geeft alleen nvarchar waarde terug, terwijl DatePart () alleen een integer waarde retourneert. De geldige datepart parameterwaarden worden hieronder weergegeven.
voorbeelden:
selecteer DATAPART (weekdag, ‘2012-08-30 19:45:31.793’) — het geeft 5
Selecteer DATENAME (weekdag, ‘2012-08-30 19:45:31.793’) — het retourneert donderdag
Dateadd () functie
Dateadd (datepart, NumberToAdd, date) – Deze SQL-functie geeft alleen de DateTime, na opgegeven term NumberToAdd, en aan de datepart gespecificeerd van de opgegeven datum.
voorbeelden:
Selecteer DateAdd(DAG, 10, ‘2018-01-20 19:45:31.793’) — het resultaat ‘2018-01-30 19:45:31.793’
Selecteer DateAdd(DAG, -10, ‘2012-08-30 19:45:31.793’)– het resultaat ‘2018-01-20 19:45:31.793’
DatedDiff() Functie
DATEDIFF(datepart, begindatum, einddatum) – Deze functie geeft het aantal van de opgegeven datepart boundaries crossed onder de opgegeven begindatum en einddatum.
voorbeelden:
Select DATEDIFF(MAAND, ’11/30/2005′,’01/31/2006′) — het geeft 2
Select DATEDIFF(DAG, ’11/30/2005′,’01/31/2006′) — het geeft 62
Dus, laten we een voorbeeld nemen, stel, we hebben een tabel;
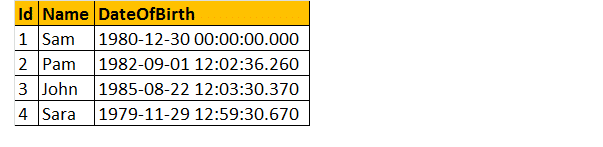
Dus, Schrijf een query te vinden van de leeftijd van een persoon, wanneer de datum van de geboorte is gegeven.

tot slot zal de uitvoer eruit zien zoals hieronder getoond.
Cast() en Convert () functies
om een enkel gegevenstype naar een ander eenheid te converteren, kunnen CAST en CONVERT functies worden gebruikt.
syntaxis van CAST en CONVERT functie:
CAST ( expressie als data_type )
CONVERT (data_type , expressie )
bovendien, zoals u kunt zien dat de functie CONVERT () een optionele waarde voor de stijlparameter heeft, terwijl de functie CAST () deze mogelijkheid niet heeft.
dus, laten we een voorbeeld nemen, we nemen een tabel hieronder;
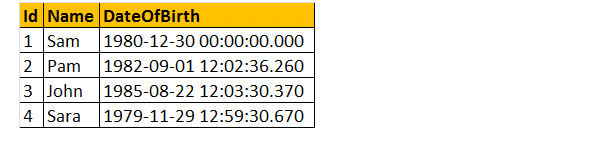 de volgende 2 queries converteren DateOfBirth ‘ s DateTime datatype naar NVARCHAR. De eerste query gebruikt de functie CAST () en de tweede de functie CONVERT (). Tot slot is de uitvoer precies hetzelfde voor beide queries zoals hieronder weergegeven.
de volgende 2 queries converteren DateOfBirth ‘ s DateTime datatype naar NVARCHAR. De eerste query gebruikt de functie CAST () en de tweede de functie CONVERT (). Tot slot is de uitvoer precies hetzelfde voor beide queries zoals hieronder weergegeven.
Select ID, Name DateOfBirth, Cast (DateOfBirth as nvarchar) as ConvertedDOB from tblle employees.
Select ID, Name DateOfBirth, Convert (DateOfBirth as nvarchar) as ConvertedDOB from tblle employees.
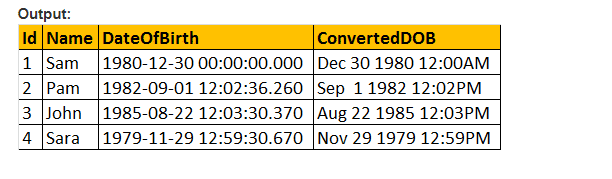 dus, laten we de stijl parameter van de CONVERT() functie waarde maken, en om de datum te formatteren zoals we het zouden willen. Dus, we gebruiken 103 als het passeren van het argument voor de parameter stijl in de onderstaande query, en die de datum formatteert als dd/mm / yy.
dus, laten we de stijl parameter van de CONVERT() functie waarde maken, en om de datum te formatteren zoals we het zouden willen. Dus, we gebruiken 103 als het passeren van het argument voor de parameter stijl in de onderstaande query, en die de datum formatteert als dd/mm / yy.
Select ID, Name, DateOfBirth, Convert (nvarchar, DateOFBirth, 103) as ConvertedDOB from tblle employees.
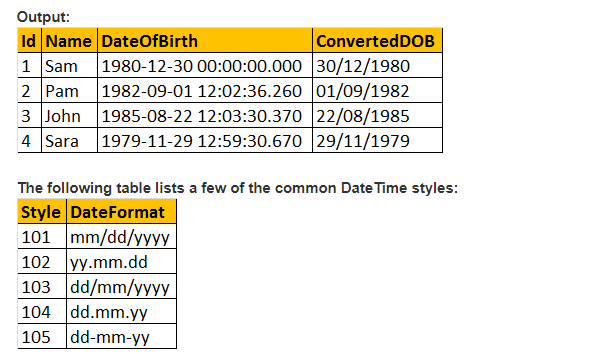
dus, laten we eens kijken naar praktisch voorbeeld met behulp van CAST () functie;
stel dat we een registratie tabel hieronder als;
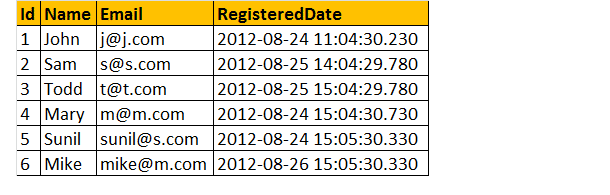 nu, laten we het totale aantal registratie per dag.
nu, laten we het totale aantal registratie per dag.
voorbeeld: selecteer CAST (RegisteredDate as DATE) als RegistrationDate, COUNT (Id) as TotalRegistrations Tblregistrations Group By CAST (RegisteredDate as DATE)
Output: ten slotte zal de uitvoer eruit zien als ;
door de gebruiker gedefinieerde functies
er zijn 3 soorten door de gebruiker gedefinieerde functies in SQL Server die als
- scalaire functies
- Inline table-valued functies
- Multistatement table-valued functies
scalaire functies
scalaire functies variëren in parameters die al dan niet parameters hebben, en altijd één enkele (scalaire) functie geeft waarde in de uitvoer. Daarom kan de geretourneerde waarde van elk gegevenstype-formaat zijn, behalve tekstwaarde, tekst, afbeelding, cursor en tijdstempel.
voorbeeld: Laten we dus een functie ontwikkelen die de leeftijd van een persoon in output berekent en retourneert. Daarom, om de leeftijd te vergelijken die we nodig hebben voor, geboortedatum. Dus, laten we de geboortedatum als een parameter. Daarom zal de functie AGE () een geheel getal retourneren en de datumparameter accepteren.
 Selecteer dbo.Leeftijd (dbo.Leeftijd (“10/08/1982”).
Selecteer dbo.Leeftijd (dbo.Leeftijd (“10/08/1982”).
dus, laten we een praktisch voorbeeld nemen in onderstaande tabel als volgt;
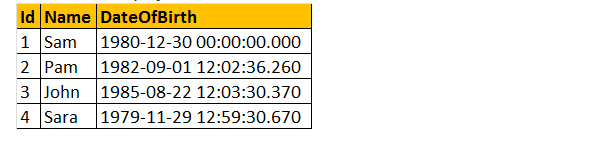
Scalar gebruikergedefinieerde functies kunnen worden gebruikt in de Select-clausule zoals hieronder getoond.
select Name, DateOfBirth, dbo.Age (DateOfBirth) as Age from tblwerknemers
 view Mostly the text of the function use sp_helptext FunctionName.
view Mostly the text of the function use sp_helptext FunctionName.
Inline table-valued function
een Inline Table Valued function geeft altijd een tabel terug als uitvoer.
dus, laten we een voorbeeld hieronder nemen; Maak een functie die werknemers per geslacht retourneert.
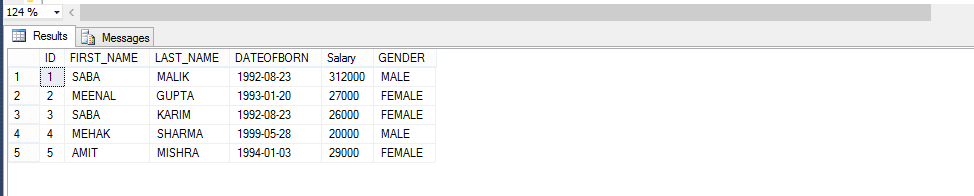
vanwege de aanroepmethode voor de door de gebruiker gedefinieerde functie,
Select * From Fn_employee Bygender(‘male’)
MULTI-STATEMENT TABLE VALUED FUNCTION
Multi-statement table-valued functions zijn veel meer vergelijkbaar met Inline Table-valued functions en met enkele verschillen. Laten we een voorbeeld bekijken en dan de verschillen noteren.
Werknemerstabel
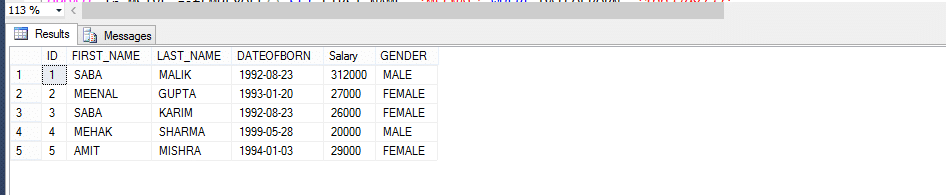
Multi-statement tabel waarde functie (MSTVF):
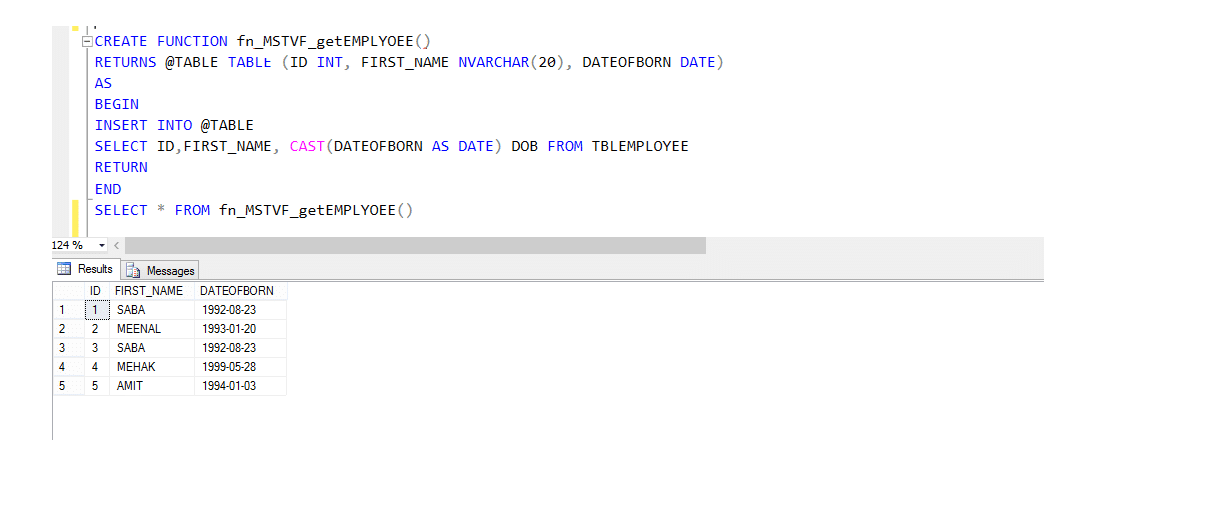 als gevolg van aanroepende methode voor VDE Multi-statement tabel waarde functie:
als gevolg van aanroepende methode voor VDE Multi-statement tabel waarde functie:
Select * from fn_MSTVF_GetEmployees ()
conclusie
de JOINs zijn zeer begrijpende term voor beginners tijdens de leerfase van SQL commando ‘ s. Bijgevolg, in het interview, Interviewer stelt ten minste een vraag is over de SQL joins, en functies. Zijn, in deze post, Ik probeer om de dingen voor nieuwe SQL leerlingen te vereenvoudigen en maken het gemakkelijk om de SQL joins te begrijpen. Bovendien, de functies in SQL, veel mensen hebben moeite om de werkelijke werkfunctie te begrijpen. Omdat SQL veel data in bulk bevat in verschillende database-en tabelnamen. Een functie is een opgeslagen programma in de SQL Server Database waar u parameters kunt doorgeven en een waarde kunt retourneren. Dus, ik heb wat meer nuttige term gegeven over de werking van functies.
- over
- Laatste berichten

- verschil tussen SQL en MySQL-14 April 2020
- hoe te werken met Subquery in datamining-23 maart 2018
- hoe gebruik ik browserfuncties van Javascript? – Maart 9, 2018
