セクションにジャンプ
- SQLはじめに
- SQL結合の操作方法
- 内部結合
- 左結合
- 右結合
- 完全外部結合
- Cross join
- Advance SQL Join
- 左結合
- 完全外部結合
- SQLのキーの種類
- 候補キー
- 主キー
- 一意キー
- 代替キー
- 複合キー
- スーパーキー
- 外部キー
- SQL関数の操作方法
- LEFT()Function
- RIGHT()Function
- CHARINDEX()Function
- SUBSTRING()Function
- REPLICATE()Function
- SPACE()Function
- PATINDEX()関数
- REPLACE()関数
- STUFF()関数
- 日付時刻関数
- isDate()Function
- Month()関数
- Year()関数
- Year()関数
- Datename()関数
- DatePart()Function
- DateAdd()関数
- DatedDiff()Function
- Cast()関数とConvert()関数
- ユーザー定義関数
- スカラー関数
- インラインテーブル値関数
- マルチステートメントテーブル値関数
- 結論
SQLはじめに
SQLはStructured Query Languageの略です。 これは、主にデータ操作、データ修正、およびデータ検索に使用されます。 これは、リレーショナルデータベース管理システム(RDBMS)に付属しています。
結合や関数などのSQLのより高度な機能について学びます。
SQL結合の操作方法
単純な結合手段は、特定のデータベース内の複数のテーブルを結合することです。 結合は、2つのテーブルの共通エンティティで機能します。
結合には、Inner join、Outer Join、Left Join、Right Join、Cross Joinの5つのサブ結合が含まれています。
内部結合
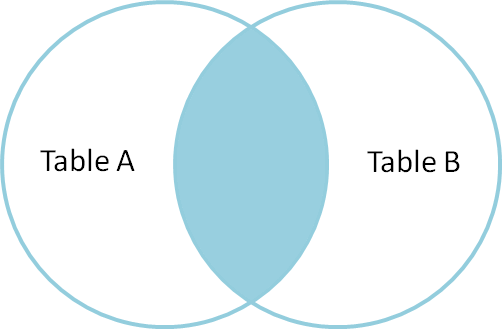
内部結合は、両方のテーブル(テーブルAとテーブルB)に共通または一致する値を含むレコードを選択するために使用されます。 非一致は除去される。
そこで、結合の種類と、一般的な例とそれらの違いを理解しましょう。
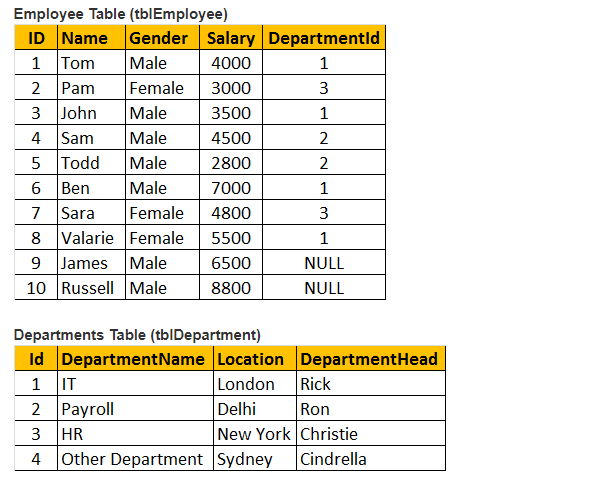
表1:従業員テーブル(tblEmployee)
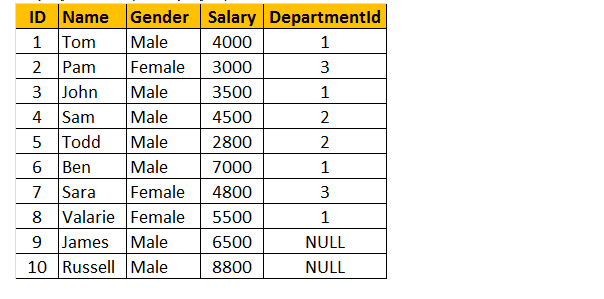
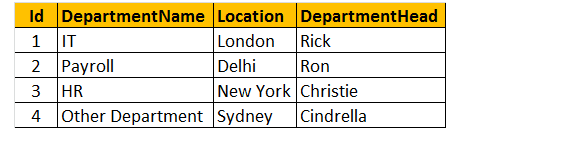
表2:Departmentsテーブル(tblDepartments)
そこで、プログラムを実行するためのテーブルtblDepartmentsを作成しましょう。

次に、テーブルtblDepartmentsにレコードを挿入します。

プログラムを実行するための別のテーブルtblEmployeeを作成しましょう。

したがって、テーブルtblEmployeeにレコードを挿入します。

したがって、結合のための一般的な式。

テーブルtblEmployeeとtblDepartmentsの両方からName、Gender、Salary、DepartmentNameを検索するクエリを作成します。

注:JOINまたはINNER JOINは同じことを意味します。 しかし、常にINNER JOINを使用する方が良いので、これはあなたの意図を明示的に指定します。
出力:最終的な出力テーブルは次のようになります;
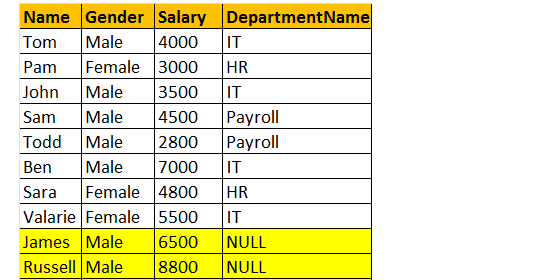
出力ウィンドウを見ると、8行しかありませんが、テーブルtblEmployeeには10行あります。 ジェイムズ-アンド-ラッセル-レコードは手に入らなかった これは、テーブルtblEmployeeのDEPARTMENTIDがこれら2人の従業員でNULLであり、テーブルtblDepartmentsのID列と一致しないためです。
したがって、最後のステートメントでは、内部結合はテーブルの両方から一致する行のみを返し、一致しない行はそのサブクエリのために削除されます。
左結合
LEFT Joinは、左側のテーブルから一致するすべての行と一致しない行を返します。 さらに、Inner joinとLeft joinは相互に広く使用されています。
だから、例を見てみましょう、私はJAMESとRUSSELLレコードを含むtblEmployeeテーブルからすべての行が必要です。 出力は次のようになります;

右結合
RIGHT Joinは、右側のテーブルから一致するすべての行と一致しない行を返します。右のテーブルのすべての行が結合に含まれている必要があります。 その結果、次のようになります;

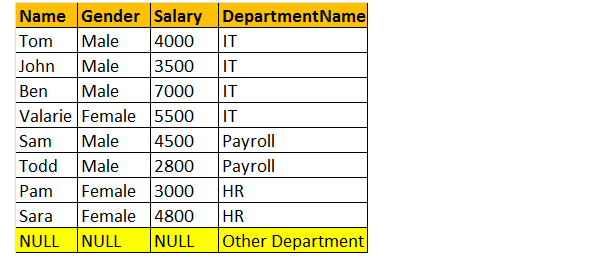
完全外部結合

OUTER joinまたはFULL OUTER Joinは、左右のテーブルのすべての行と、テーブルの一致しない行を返します。
だから、例を見てみましょう;私は結合に関与する両方のテーブルからすべての行が必要です。

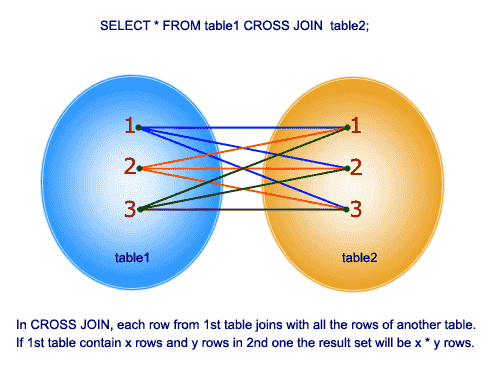
Cross join
このjoinは、join関数内の2つのテーブルのデカルト積を与えます。 この結合にはON句は含まれていません。
だから、例を理解してみましょう: TblEmployeeテーブルには10行があり、tblDepartmentsテーブルには4行があります。 したがって、これらの2つのテーブル間の交差結合は40行を生成します。

Advance SQL Join
の操作方法このセッションでは、これらのことを次のように説明します;
- SQL Serverでの高度な結合またはインテリジェント結合。
- 左のテーブルから一致しない行のみを取得します。
- 右のテーブルから一致しない行のみデータをフェッチします。
- 左と右の両方のテーブルから一致しない行のみのデータを取得します。
だから、テーブルtblEmployeeとtblDepartmentの両方を考えてみましょう。
左結合
左側のテーブルから一致しない行のみを取得したいのですが。

出力:最後に、出力は次のようになります;

右結合
例を理解しましょう、右側のテーブルから一致しない行のみを取得したいと思います。

出力:最後に、出力は次のようになります;

完全外部結合
したがって、例を理解しましょう、私は右側のテーブルと左側のテーブルから一致しない行だけを取得したいと一致する行を排除する必要があります。

出力:最後に、出力は次のようになります。
SQLのキーの種類
SQLのキーは、レコードを排他的に識別するデータフィールドです。 別の言葉では、キーは、テーブル内のレコードを一意に識別するために使用される列のセットです。
- 二つのテーブル間のリレーションシップを作成します。
- テーブル内の一意性と責任を維持します。
- データベース内の一貫性のある有効なデータを保持します。
- は、列のインデックスを容易にすることにより、高速なデータ取得に役立ちます。
SQL serverには、次のようなキーが含まれています;
- 候補キー
- 主キー
- 一意キー
- 代替キー
- 複合キー
- スーパーキー
- 外部キー
先に行く前に、下の画像を見てください;
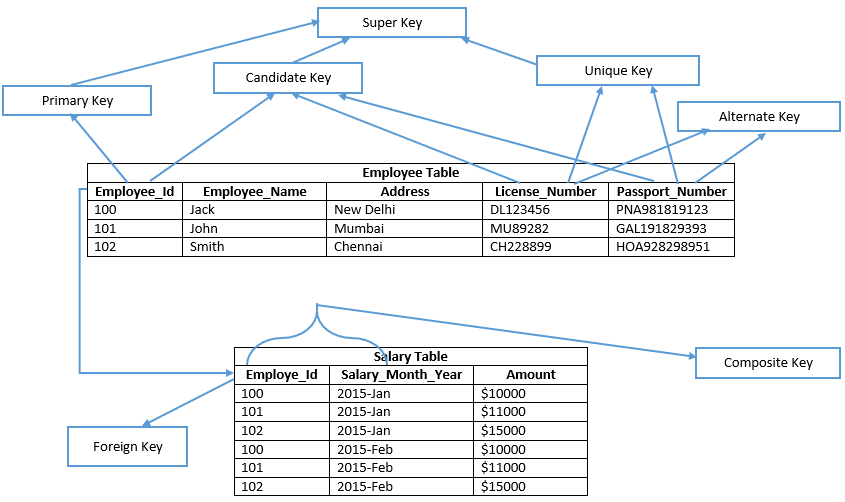
各キーを詳細に理解しよう
候補キー
候補キーは、テーブルの主キーとして選択できるテーブルのキーであり、テーブルは複数の候補キーを持つことができるため、主キーとして選択することができます。
例:Employee_Id,License_Number,&Passport_Number候補キーを示します
主キー
主キーは、テーブル内の各データレコードを一意に検証するために、テーブルの選択された候補キーに似ています。 したがって、primary keyにはテーブルのどの列にもnull値が含まれておらず、列に一意の値も保持されます。 この例では、Employee_IdはEmployeeテーブルの主キーを定義しています。 そのため、SQL Server Management Studioでは、主キーによって既定でヒープテーブルにクラスタ化インデックスが作成され、クラスタ化インデックスで構成されていないテーブ インデックスのタイプ別にテーブルの非クラスター化主キーを明示的に定義するかどうか。
さらに、テーブルには主キーを1つだけ含めることができ、SQLステートメントを使用してSQL Serverで主キーを定義できます:
- CRETE TABLEステートメント(テーブル作成時)-その結果、システムは主キーの名前を定義します。
- ALTER TABLEステートメント(主キー制約を使用)–その結果、ユーザー自身が主キー制約の名前を宣言します。
例:Employee_IdはEmployeeテーブルの主キーです。
一意キー
一意キーは主キーと同じであり、列に重複した値が含まれていません。 主キーの比較には以下の違いがあります:
- 列に1つのnull値を指定できます。
- 既定では、非クラスター化インデックスとヒープテーブルが作成されます。
代替キー
代替キーは候補キーに似ていますが、テーブルの主キーとして選択されていません。
例:License_NumberとPassport_Numberは代替キーです。
複合キー
複合キー(複合キーまたは連結キーとも呼ばれます)は、テーブルの各行を一意に識別する2つ以上の列のグループです。 さらに、複合キーの単一のユニット列は、データレコードを一意に検証できない場合があります。 その結果、主キーまたは候補キーのいずれかにすることもできます。
例:テーブルでは、Employee_Id&Salary_Month_Year両方の列がSalaryテーブルの各行を一意に検証します。 したがって、テーブル内のEmployee_Id列またはSalary_Month_Year列は、各行を一意に識別できません。 Employee_IdおよびSalary_Month_Year列名を使用して、給与テーブルに単一の複合主キーを作成できます。
スーパーキー
スーパーキーは、テーブルのすべての列が機能的に依存する列のセットです。 テーブル内の各行を一意に識別する列のセットが原因です。 つまり、このキーには、テーブル内の各行を一意に検証するために厳密に必要とされない追加の列がいくつか保持されています。 主キーと候補キーは最小限のスーパーキーであるか、スーパーキーのサブセットと言うことができます。
だから、上記の例を見てみましょう、Employeeテーブルでは、列名Employee_Idは、テーブルの行を一意に検証するのに十分ではありません。 したがって、Employee_Idを含むEmployeeテーブルの列のセットは、Employeeテーブルのスーパーキーです。
たとえば、{Employee_Id}、{Employee_Id、Employee_Name}、{Employee_Id、Employee_Name、Address}などです。
License_NumberとPassport_Numberは列名であり、テーブルの行のいずれかを一意に検証することもできます。 License_NumberまたはPassport_NumberまたはEmployee_Idで構成される列名セットの誰もがテーブルのスーパーキーです。
たとえば、{License_Number,Employee_Name,Address}、{License_Number,Employee_Name,Passport_Number}、{Passport_Number,Employee_Name,Address,License_Number}、{Passport_Number,Employee_Name}、{Passport_Number,Employee_Id}などです。
外部キー
FKは、一度に二つ以上のテーブル間の関係を定義します。 単一のテーブルの主キーは、別のテーブルの外部キーに参照されます。 外部キーは、テーブル内で重複した値を持つことができ、列名がまだnull値を受け入れるように定義されている場合はnull値を持つこともできます。たとえば、列名「Employee_Id」(Employeeテーブルの主キー)は、Salaryテーブルの外部キーです。
注:primary keyやunique keyなどのキーは、キー列を持つインデックスを作成します。 SQL ServerのBツリー構造ノード(バランスツリー:リーフノードはすべてルート側とは異なるレベルにあります)の組織化されたデータ。 そのため、非クラスター化インデックスは基本データテーブルとは別の構造を作成しますが、クラスター化インデックスは基本データテーブルをヒープ構造からBツリー構造に変換します。
さらに、クラスター化インデックスはベーステーブルとは別に別の構造を作成しないため、テーブルに作成できるクラスター化インデックスは1つだけです。 したがって、クラスタ化インデックスの順序である1つの方法でテーブルをソートできます(ソートする列が複数ある場合もありますが、ソートは1つの方法
SQL関数の操作方法
関数は、SQL Serverデータベースに格納されているエンティティプログラムで、パラメータを渡すか、値を返すことができます。 さらに、我々はいくつかの非常に便利な組み込み関数とユーザー定義関数を楽しみにしています。
Coalesce Function
Coalesce():この関数は、最初の非NULL値のみを返します。 それでは、Coalesce()関数の例を見てみましょう。
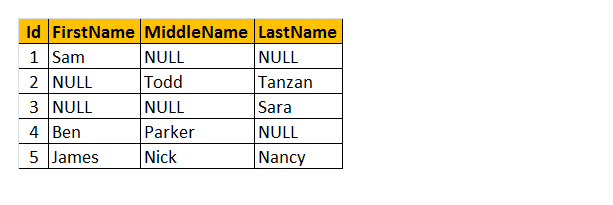 上記の名前’Employee’としてテーブルを理解しましょう。 その結果、従業員の中には名が欠落している人もいれば、ミドルネームがある人もいれば、姓が欠落している人もいることがわかります。 だから、私は従業員の”名前”だけを返したい。
上記の名前’Employee’としてテーブルを理解しましょう。 その結果、従業員の中には名が欠落している人もいれば、ミドルネームがある人もいれば、姓が欠落している人もいることがわかります。 だから、私は従業員の”名前”だけを返したい。
それはどのように動作しますか? COALESCE()関数のパラメータとして、FirstName、MiddleName、およびLastName列を処理していることを理解してください。 したがって、この関数は、3つの列から最初のnull以外の値のみを返します。
クエリ:Select Id,COALESCE(FirstName,MiddleName,LastName)AS Name FROM tblEmployee
最後に、出力は次のようになります;
 LEFT()Function
LEFT()Function
LEFT(Character_Expression,Integer_Expression)–この関数は、指定された文字値式の左側から指定された文字数を返します。
例:左を選択(‘ABCDE’, 3)
出力:ABC
RIGHT()Function
RIGHT(Character_Expression,Integer_Expression)–この関数は、指定された文字値式の右側から指定された文字数を返します。
例:右を選択(‘ABCDE’, 3)
出力: CDE
CHARINDEX()Function
CHARINDEX(‘Expression_To_Find’,’Expression_To_Search’,’Start_Location’)–この関数は、文字サブ文字列内の指定された値式の開始位置を返します。 Start_locationパラメータは省略可能です。
例:理解しましょう、我々は電子メール文字列の’@’文字の開始位置を作る’[email protected]’.
CHARINDEXを選択します(‘@’,’[email protected]’,1)
出力: 5
SUBSTRING()Function
SUBSTRING(expression’,’Start’,’Length’)–この関数は、指定された値式から部分文字列(文字列のサブパート)を返します。 さらに、’start’パラメータを使用して開始位置を指定し、’Length’パラメータを使用して部分文字列内の他の文字数を指定する場合。 3つのパラメータはすべて必須です。
例:指定されたメールのドメイン部分だけを表示したい’[email protected]’.
部分文字列を選択します(‘[email protected]’,6, 7)
出力:bbb。com
その結果、開始位置と長さパラメータで符号化を行いました。 パラメータをハードコーディングする代わりに、以下に示すようにCHARINDEX()とLEN()文字列関数を使用して動的にフェッチすることができます。
例:
部分文字列を選択します(‘[email protected]’,(CHARINDEX(‘@’,’[email protected]’)+1),(LEN(‘)+1),(LEN(‘)+1)[email protected]’)-CHARINDEX(‘@’,’)-CHARINDEX(‘@’,’[email protected]’)))
出力:bbb.com
では、LEN()、CHARINDEX()、SUBSTRING()関数を使用して実際の例を見てみましょう。 以下に示すように、我々はテーブルを持っていると思いましょう;
 だから、問題は、あなたが彼らのドメインによって電子メールの総数を見つける方法です。
だから、問題は、あなたが彼らのドメインによって電子メールの総数を見つける方法です。
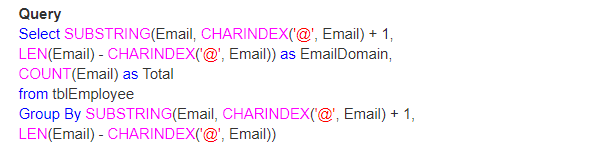
出力:最後に、出力は次のようになります;
 REPLICATE()Function
REPLICATE()Function
REPLICATE(String_To_Be_Replicated,Number_Of_Times_To_Replicate)–この関数は、文字列の指定されたポイントを、指定された回数だけ繰り返します。
例:SELECT REPLICATE(‘Pragim’, 3)
出力:Pragim Pragim Pragim
REPLICATE()関数を使用する実用的な例について話しましょう: ほとんどの場合、このテーブルを使用し、この記事の残りの例ではこのテーブルを使用します。
だから、以下に示すような表があるとしましょう;
 クエリ:名、姓、部分文字列(電子メール、1、2)+複製を選択します(‘*’,5) +
クエリ:名、姓、部分文字列(電子メール、1、2)+複製を選択します(‘*’,5) +
SUBSTRING(Email,CHARINDEX(‘@’,Email),LEN(Email)–CHARINDEX(‘@’,Email)+1)As Email
from tblEmployee
5つの*(星)記号で電子メールを作ってみましょう。 次に、出力は次のようになります
 SPACE()Function
SPACE()Function
SPACE(Number_Of_Spaces)–この関数はスペースの数だけを返し、number_Of_Spaces引数で指定します。
例:SPACE(5)関数では、FirstNameとLastNameの間に5つのスペースを挿入します
Select FirstName+SPACE(5)+LastName As FullName From tblEmployee
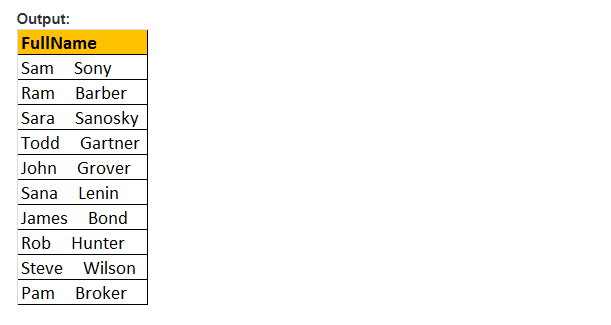 PATINDEX()関数
PATINDEX()関数
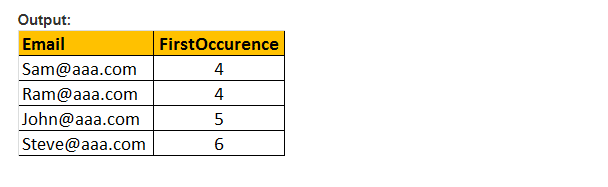
この関数は、指定された有効な式でパターンが最初に出現する開始位置のみを返します。 したがって、2つの引数と、検索されるパターンと式のみを取ります。 したがって、PATINDEX()はCHARINDEX()に似ています。 CHARINDEX()ではワイルドカードを使用できませんが、PATINDEX()にはこの機能が含まれます。 指定されたパターン値が見つからない場合、PATINDEX()はゼロを返します。
例:メールを選択し、PATINDEX(‘%aaa.comここで、PATINDEX(‘%@aaa.com”、メール) > 0
 REPLACE()関数
REPLACE()関数
REPLACE(String_Expression,Pattern,Replacement_Value)この関数は、指定された文字列値のすべての出現位置を別の文字列値に置き換えます。
例:すべての.COM文字列が.NET
Select Email,REPLACE(Email,’.com’,’.net’)tblEmployee
 STUFF()関数
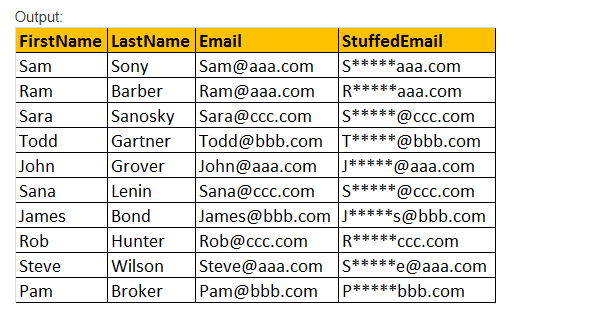
STUFF()関数
STUFF(Original_Expression,Start,Length,Replacement_Expression)からのConvertedEmailとして、このSTUFF()関数は、Lengthパラメータ値式を使用して指定された文字を削除するとともに、開始位置で指定されたReplacement_Expressionのみを挿入
例:姓、姓、電子メール、スタッフ(電子メール)を選択します,2,3,’*****’) tblEmployeeからのStuffedEmailとして。
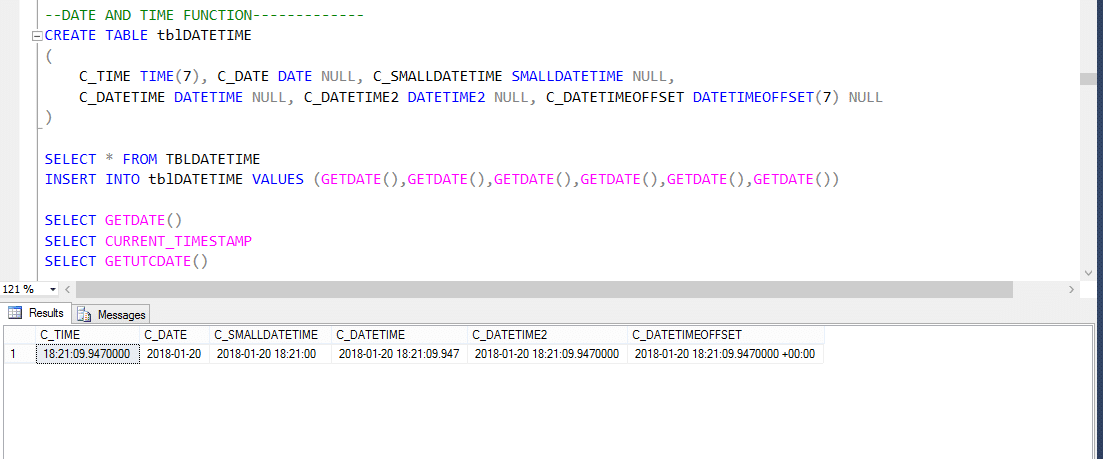
 日付時刻関数
日付時刻関数
SQL Serverデータベースには、いくつかの組み込みのDateTime関数があります。 次の関数のほとんどは、現在のシステムの日付と時刻、およびSQL serverがインストールされている場所を取得するために使用できます。
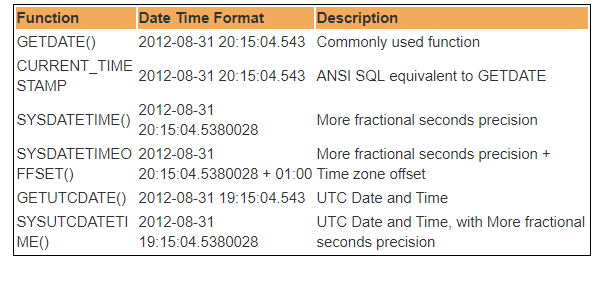 したがって、UTCは協定世界時の略で、それに基づいて世界は時計と時間データを規制しています。 注目すべきだ GMTとUTCの間にはわずかな違いがありますが、ほとんどの一般的な目的のために、UTCはGMTと同義です。
したがって、UTCは協定世界時の略で、それに基づいて世界は時計と時間データを規制しています。 注目すべきだ GMTとUTCの間にはわずかな違いがありますが、ほとんどの一般的な目的のために、UTCはGMTと同義です。
だから、以下に示すように別の例を見てみましょう;
isDate()Function
ISDATE()–この関数は、指定された値のみをチェックし、有効な日付、時刻、またはDateTimeが存在するかどうかを確認します。 次に、成功の場合は1、失敗の場合は0を返します。
例:
Select ISDATE(‘PRAGIM’)—0を返します
例:
Select ISDATE(Getdate())—1を返します
例:
Select ISDATE(Getdate())-1を返します
例:
Select ISDATE(‘2018-01-20 21:02:04.167’) — それは1
を返します注:datetime2値の場合、IsDateはゼロを返します。
例:
ISDATEを選択します(‘2018-01-20 22:02:05.158.1918447’) — それは0を返します。
Day()関数
Day()–この関数は、指定された日付の”月の日番号”のみを返します。
:
Select DAY(GETDATE())—現在のシステム日時に基づいて、月の日番号に代わって出力を提供します。
Select DAY(’01/14/2018′)—14を返します
Month()関数
Month()–この関数は、指定された日付の”年の月番号”の代わりに出力を与えます。
例:
Select Month(GETDATE())—この関数は、現在のシステムの日付と時刻に基づいて、”年の月番号”の代わりに出力を与えます。
Select Month(’05/14/2018)—5を返します
Year()関数
Year()–この関数は、指定された日付の”年番号”の代わりに出力を与えます
例:
Select Year(GETDATE())—年番号を返し、現在のシステム日付に基づいて
Select Year(GETDATE())—現在のシステム日付に基づいて年番号を返します
Year()関数
Year()–この関数は、指定された日付の”年番号”に代わって出力を与えます
Select Year(GETDATE())-現在のシステム日付に基づいて出力を与えます
Datename()関数
Datename(datepart,date)-この関数は文字列式のみを返し、指定された日付の一部のみを表します。 これらの関数は、2つのパラメータで構成されます。
最初のパラメータ’DatePart’は、日付の一部を指定します。 2番目のパラメータは実際の日付であり、そこから日付の一部が必要です。
 例1:
例1:
日付名(日)を選択します, ‘2017-04-20 13:47:47.350’) — それは20
を返します例2:
Select DATENAME(WEEKDAY, ‘2017-04-20 13:47:47.350’) — Thursday
が返されます例3:
Select DATENAME(MONTH, ‘2017-04-20 13:47:47.350’) — それはApril
を返しますので、これらのDateTime関数のいくつかを使用して例を見てみましょう。 テーブルtblEmployeesを考えてみましょう。例:以下に示すように、すべてのName、DateOfBirth、Day、MonthNumber、MonthName、およびYearを返します。
名前、DateOfBirth、DateName(WEEKDAY,DateOfBirth)as、Month(DateOfBirth)As MonthNumber、DateName(MONTH,DateOfBirth)as、Year(DateOfBirth)AsをtblEmployeesから選択します

DatePart()Function
DatePart(DatePart,Date)–この関数は、指定されたDatePart値を表す整数を与えます。 ほとんどの関数はDateName()関数に似ています。 DateName()はnvarchar値のみを返し、DatePart()は整数値のみを返します。 有効なDatePartパラメーター値を以下に示します。
例:
SELECT DATEPART(weekday, ‘2012-08-30 19:45:31.793’) — 5
Select DATENAME(weekday)を返します, ‘2012-08-30 19:45:31.793’) — それは木曜日を返します
DateAdd()関数
DATEADD(datepart,NumberToAdd,date)–このSQL関数は、指定された用語NumberToAddの後に、指定された日付で指定されたdatepartにのみDateTimeを与えます。
:
DateAdd(DAY)を選択します, 10, ‘2018-01-20 19:45:31.793′) — それは戻ります’2018-01-30 19:45:31.793’
DateAdd(日)を選択します, -10, ‘2012-08-30 19:45:31.793′)– それは戻ります’2018-01-20 19:45:31.793’
DatedDiff()Function
DATEDIFF(datepart,startdate,enddate)–この関数は、指定されたstartdateとenddateの間で交差する指定されたdatepart境界のカウントを与えます。
:
日付を選択(月), ’11/30/2005′,’01/31/2006′) — 2
Select DATEDIFF(DAY)を返します, ’11/30/2005′,’01/31/2006′) — それは62
を返しますので、例を見てみましょう、以下の表があるとしましょう;
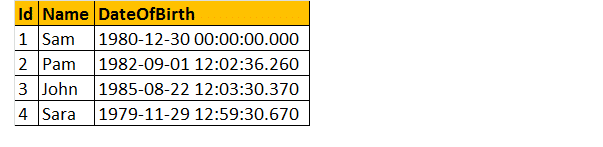
だから、生年月日が与えられたときに、人の年齢を調べるためのクエリを書いてください。

最後に、出力は以下のようになります。
Cast()関数とConvert()関数
単一のユニットデータ型を別のデータ型に変換するには、CAST関数とCONVERT関数を使用できます。
CASTおよびCONVERT関数の構文:
CAST(expression AS data_type)
CONVERT(data_type,expression)
また、CONVERT()関数にはオプションのスタイルパラメータ値がありますが、CAST()関数にはこの機能がありません。
だから、例を見てみましょう、我々は以下の表を取って;
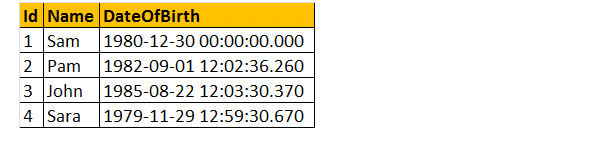 次の2つのクエリは、DateOfBirthのDateTimeデータ型をNVARCHARに変換します。 最初のクエリはCAST()関数を使用し、2番目のクエリはCONVERT()関数を使用します。 最後に、以下に示すように、出力は両方のクエリでまったく同じになります。
次の2つのクエリは、DateOfBirthのDateTimeデータ型をNVARCHARに変換します。 最初のクエリはCAST()関数を使用し、2番目のクエリはCONVERT()関数を使用します。 最後に、以下に示すように、出力は両方のクエリでまったく同じになります。
ID、名前DateOfBirth、キャスト(DateOfBirthをnvarcharとして)をTblemployeesからConvertedDOBとして選択します。
ID、名前DateOfBirth、Convert(DateOfBirth as nvarchar)をTblemployeesからConvertedDOBとして選択します。
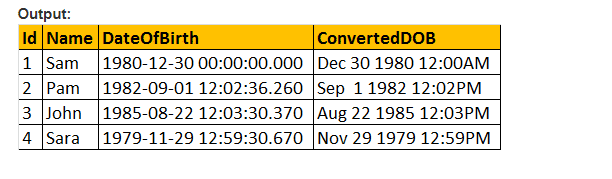 では、CONVERT()関数の値のスタイルパラメータを作成し、希望するように日付を書式設定しましょう。 そのため、以下のクエリでスタイルパラメータの引数を渡すために103を使用しており、日付をdd/mm/yyとしてフォーマットしています。
では、CONVERT()関数の値のスタイルパラメータを作成し、希望するように日付を書式設定しましょう。 そのため、以下のクエリでスタイルパラメータの引数を渡すために103を使用しており、日付をdd/mm/yyとしてフォーマットしています。
ID、名前、DateOfBirth、Convert(nvarchar,DateOFBirth,103)をTblemployeesからConvertedDOBとして選択します。
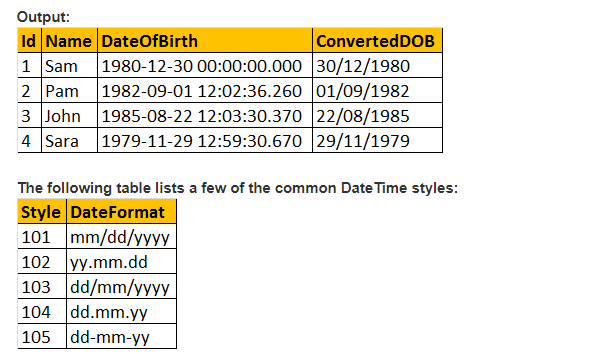
それでは、CAST()関数の助けを借りて実用的な例を見てみましょう。
以下のように登録テーブルがあるとしましょう;
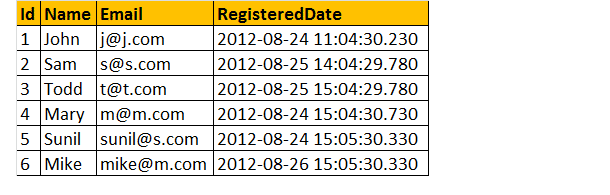 さて、日ごとの登録の総数を見てみましょう。
さて、日ごとの登録の総数を見てみましょう。
例:CAST(RegisteredDate as DATE)をRegistrationDateとして選択し、COUNT(Id)をTotalRegistrationsとしてTBLREGISTRATIONS GROUP By CAST(RegisteredDate as DATE)
出力:最後に出力は次のようになります ;
ユーザー定義関数
SQL Serverには、
- スカラー関数
- インラインテーブル値関数
- マルチステートメントテーブル値関数
スカラー関数
スカラー関数は、パラメータを持つ場合と持たない場合があるパラメータが異なり、出力には常に単一の(スカラー)値が与えられます。 したがって、戻り値は、text value、text、image、cursor、およびtimestamp以外の任意のデータ型形式にすることができます。
: そこで、出力で人の年齢を計算して返す関数を開発しましょう。 その結果、私たちが必要とした年齢、生年月日を比較する。 では、生年月日をパラメータとして渡してみましょう。 したがって、AGE()関数は整数を返し、日付パラメータを受け入れます。
 dboを選択します。年齢(dbo.(’10/08/1982)
dboを選択します。年齢(dbo.(’10/08/1982)
だから、次のように、以下の与えられた表の実用的な例を見てみましょう;
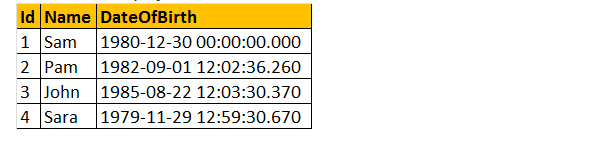
スカラーユーザー定義関数は、以下に示すようにSelect句で使用できます。
名前、日付、dboを選択します。Age(DateOfBirth)As Age from tblEmployees
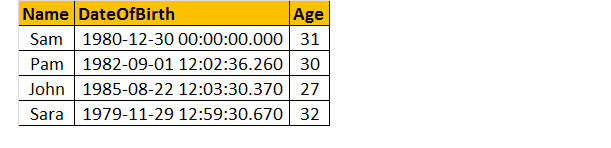 主に関数のテキストを表示するsp_helptext FunctionNameを使用します。
主に関数のテキストを表示するsp_helptext FunctionNameを使用します。
インラインテーブル値関数
インラインテーブル値関数は、常にテーブルを出力として返します。
だから、以下の例を見てみましょう;性別によって従業員を返す関数を作成します。
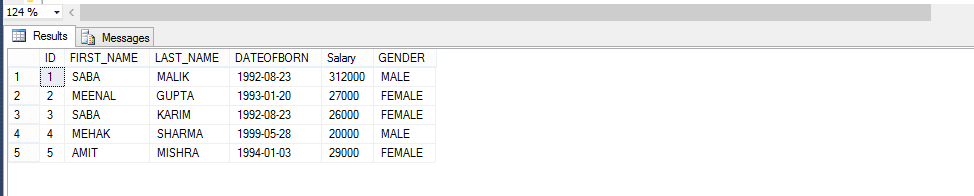
ユーザー定義関数の呼び出しメソッドにより、
Select*From Fn_Employeebygender(‘male’)
マルチステートメントテーブル値関数
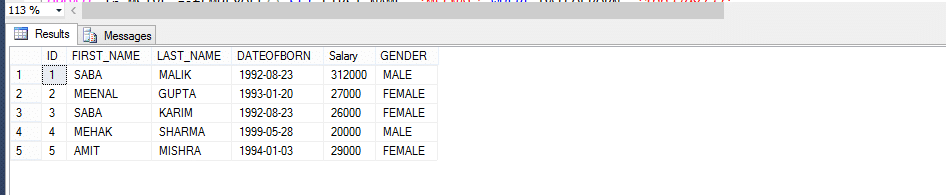
マルチステートメントテーブル値関数は、インラインテーブル値関数 それでは、例を見て、違いに注意してみましょう。
従業員表
マルチステートメントテーブル値関数(MSTVF):
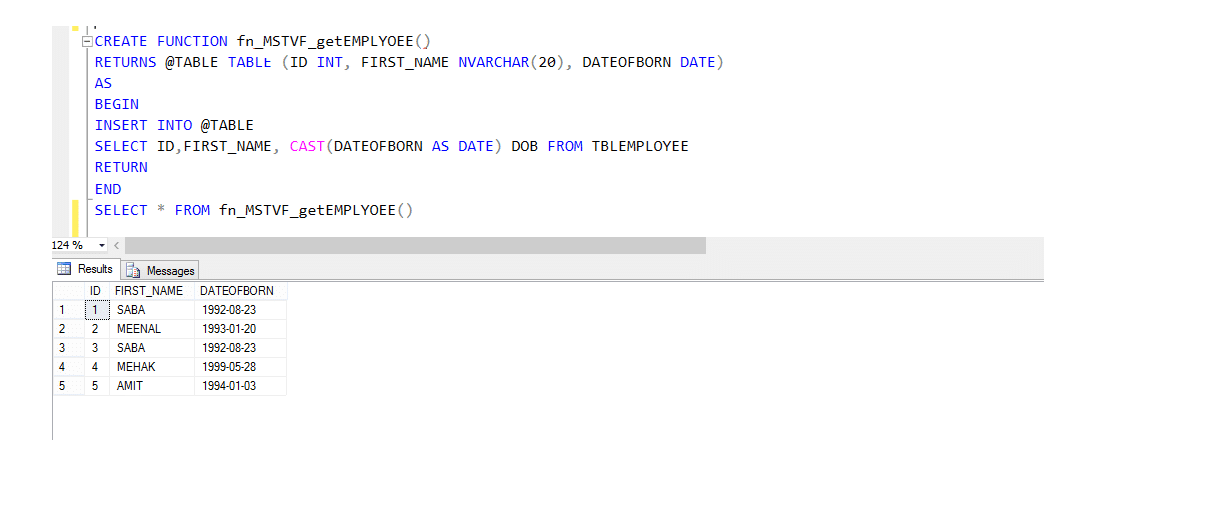 Vマルチステートメントテーブル値関数の呼び出しメソッドのために:
Vマルチステートメントテーブル値関数の呼び出しメソッドのために:
Select*from fn_mstvf_getemployees()
結論
結合は、SQLコマンドの学習段階で初心者のための用語を非常に理解しています。 その結果、インタビューでは、インタビュアーは、少なくとも一つの質問は、SQL結合、および関数についてです尋ねます。 したがって、この投稿では、新しいSQL学習者のためのものを単純化し、SQL結合を理解しやすくしようとしています。 さらに、SQLの関数は、多くの人々が実際の作業関数を理解するのに苦労しています。 SQLには、異なるデータベース名とテーブル名で大量のデータが含まれているためです。 関数とは、SQL Serverデータベースに格納されているプログラムで、パラメーターを渡して値を返すことができます。 だから、私は関数の作業についていくつかのより有用な用語を与えました。
- の最新記事

- SQLとMySQLの違い-2020年4月14日
- データマイニングでサブクエリを操作する方法-2018年3月23日
- Javascriptのブラウザ機能を使用する方法は? -マーチ9, 2018
