przejdź do sekcji
- Wprowadzenie do SQL
- jak pracować z łączami SQL
- połączenie wewnętrzne
- Left Join
- Right Join
- pełne złącze zewnętrzne
- połączenie krzyżowe
- jak pracować z Advance SQL
- Left Join
- pełne złącze zewnętrzne
- rodzaje kluczy w SQL
- klucz kandydata
- klucz podstawowy
- unikalny klucz
- klucz alternatywny
- klucz kompozytowy
- Super Key
- klucz obcy
- jak pracować z funkcjami SQL
- funkcja LEFT ()
- funkcja RIGHT ()
- CHARINDEX() Function
- SUBSTRING() funkcja
- funkcja REPLICATE ()
- funkcja SPACE ()
- funkcja PATINDEX ()
- funkcja REPLACE ()
- funkcja STUFF ()
- funkcja czasu daty
- funkcja isDate ()
- funkcja Month ()
- Year() Function
- funkcja Datename ()
- funkcja DatePart ()
- funkcja DateAdd ()
- DatedDiff () Function
- funkcje Cast() I Convert ()
- funkcje zdefiniowane przez użytkownika
- funkcje skalarne
- funkcje wbudowane w tabelę
- funkcja wielostanowiskowa o wartości tabeli
- Conclusion
Wprowadzenie do SQL
SQL oznacza Structured Query Language. Służy głównie do manipulacji danymi, modyfikacji danych i pobierania danych. Chodzi o relacyjny system zarządzania bazami danych (RDBMS).
poznamy bardziej zaawansowane funkcje SQL, takie jak Połączenia i funkcje.
jak pracować z łączami SQL
prostym sposobem łączenia jest połączenie dwóch lub więcej tabel w danej bazie danych. Połączenie działa na wspólnej jednostce dwóch tabel.
A join zawiera 5 sub-join, które jako; Inner join, Outer Join, Left Join, Right Join i Cross Join.
połączenie wewnętrzne
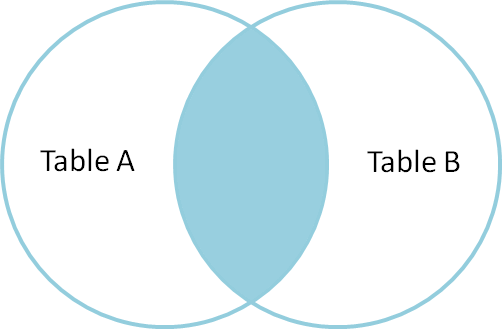
połączenie wewnętrzne służy do wybierania rekordów zawierających wspólne lub pasujące wartości w obu tabelach (Tabela A I Tabela B). Brak dopasowania są eliminowane.
przyjrzyjmy się więc rodzajowi połączeń, z typowymi przykładami i różnicami między nimi.
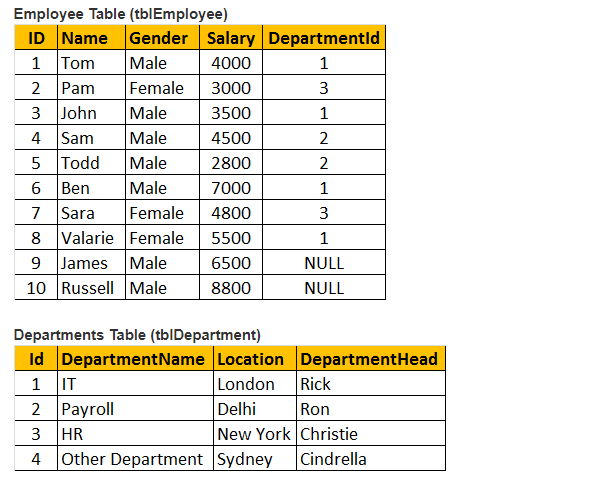
Tabela 1: Tabela pracowników (tblEmployee)
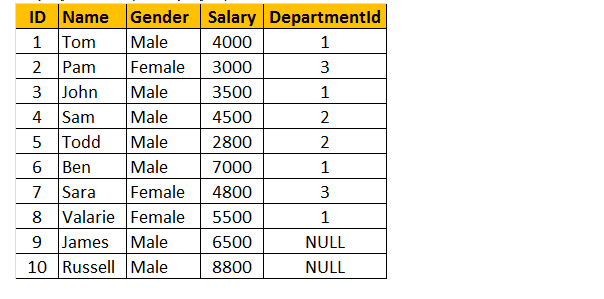
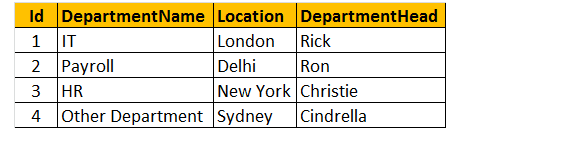
Tabela 2: Tabela wydziałów (tblDepartments)
stwórzmy więc tabelę tblDepartments do wykonania programu.

teraz Wstaw rekordy do tabeli tblDepartments.

stwórzmy kolejną tabelę tblEmployee do wykonania programu.

tak, wstawić rekordy do tabeli tblEmployee.

dlatego też ogólny wzór na połączenia.

aby wysłać zapytanie, aby znaleźć imię i nazwisko, płeć, wynagrodzenie i nazwę działu z obu tabel tblEmployee i tblDepartments.

Uwaga: JOIN lub Inner JOIN oznacza to samo. Ale zawsze lepiej używać Inner JOIN, a to wyraźnie określa Twoją intencję.
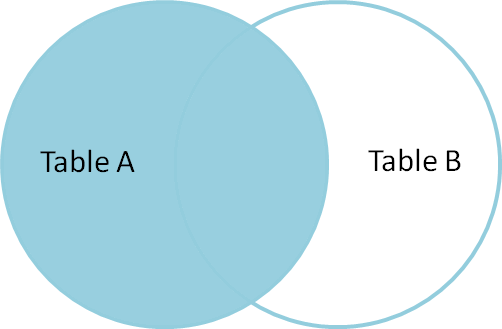
wyjście: teraz końcowa tabela wyników będzie wyglądać tak;
jeśli spojrzysz na okno wyjściowe, mamy tylko 8 wierszy, ale w tabeli tblEmployee mamy 10 wierszy. Nie mamy płyt Jamesa i Russella. Dzieje się tak dlatego, że identyfikator departamentu w tabeli tblEmployee jest NULL dla tych dwóch pracowników i nie pasuje do ich kolumny ID w tabeli tblDepartments.
tak więc, w końcowej instrukcji, połączenia wewnętrzne zwracają tylko pasujące wiersze zarówno z tabel, jak i niepasujące wiersze są eliminowane z powodu ich podquery.
Left Join
LEFT Join zwraca wszystkie pasujące wiersze i niepasujące wiersze z tabeli po lewej stronie. Ponadto Złącze wewnętrzne i złącze lewe są szeroko stosowane.
weźmy więc przykład, chcę wszystkie wiersze z tabeli tblEmployee, w tym rekordy Jamesa i Russella. Wtedy wyjście będzie wyglądać jak;

Right Join
RIGHT Join zwraca wszystkie pasujące wiersze i niepasujące wiersze z prawej tabeli bocznej.
weźmy więc przykład; chcę, aby wszystkie wiersze z prawej tabeli były zaangażowane w łączenie. W rezultacie byłoby jak;

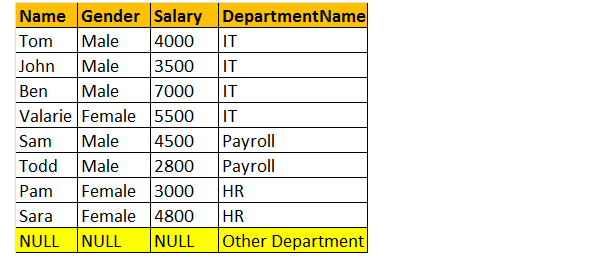
pełne złącze zewnętrzne

OUTER join lub FULL OUTER Join zwraca wszystkie wiersze zarówno z lewej, jak i prawej tabeli, włącznie z niepasującymi wierszami z tabel.
weźmy więc przykład; chcę wszystkie wiersze z obu tabel zaangażowanych w join.

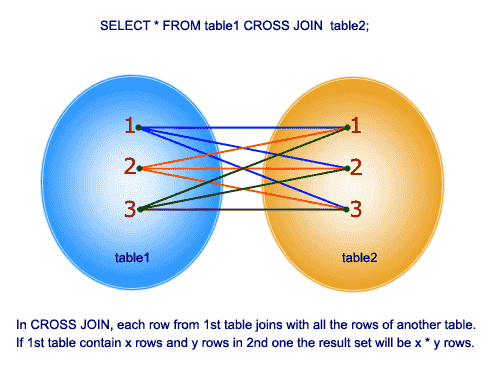
połączenie krzyżowe
to połączenie daje iloczyn kartezjański 2 tabel w funkcji łączenia. To połączenie nie zawiera klauzuli ON.
więc zrozummy przykład: W tabeli tblEmployee mamy 10 wierszy, a w tabeli tbldepartments mamy 4 wiersze. Tak więc, krzyż łączący te 2 tabele daje 40 wierszy.

jak pracować z Advance SQL
w tej sesji wyjaśnię te rzeczy w następujący sposób;
- zaawansowane lub inteligentne połączenia w SQL Server.
- pobiera dane tylko niepasujące wiersze z lewej tabeli.
- pobiera dane tylko niepasujące wiersze z prawej tabeli.
- pobiera dane tylko niepasujące wiersze z lewej i prawej tabeli.
rozważmy więc obie tabele tblEmployee i tblDepartment.
Left Join
tak więc, zrozummy przykład, Chcę pobrać tylko niepasujące wiersze z lewej tabeli bocznej.

wyjście: na koniec wyjście będzie wyglądać następująco;

Right Join
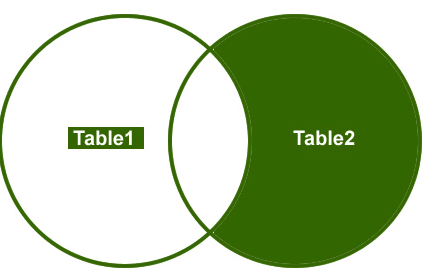
tak więc, zrozummy przykład, Chcę pobrać tylko niepasujące wiersze z prawej tabeli bocznej.

wyjście: na koniec wyjście będzie wyglądać następująco;

pełne złącze zewnętrzne
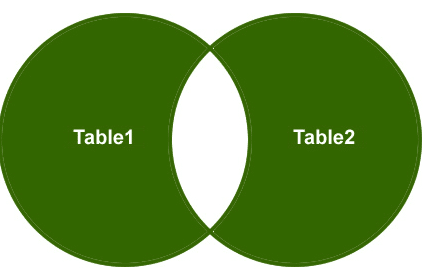
tak więc, zrozummy przykład, Chcę pobrać tylko niepasujące wiersze z prawej tabeli bocznej i lewej tabeli bocznej, a pasujące wiersze powinny zostać wyeliminowane.

wyjście: wreszcie, wyjście będzie wyglądać tak;
rodzaje kluczy w SQL
klucz w SQL jest polem danych, które identyfikuje wyłącznie rekord. Innymi słowy, klucz jest zbiorem kolumn (kolumn), które są używane do jednoznacznej identyfikacji rekordu w tabeli.
- Utwórz relacje między dwiema tabelami.
- Zachowaj wyjątkowość i odpowiedzialność w tabeli.
- Zachowaj spójne i poprawne dane w bazie danych.
- może pomóc w szybkim wyszukiwaniu danych, ułatwiając indeksy na kolumnach.
serwer SQL zawiera klucze w następujący sposób;
- Candidate Key
- Primary Key
- Unique Key
- Alternate Key
- Composite Key
- Super Key
- Foreign Key
zanim przejdziesz do przodu, spójrz na poniższy obrazek;
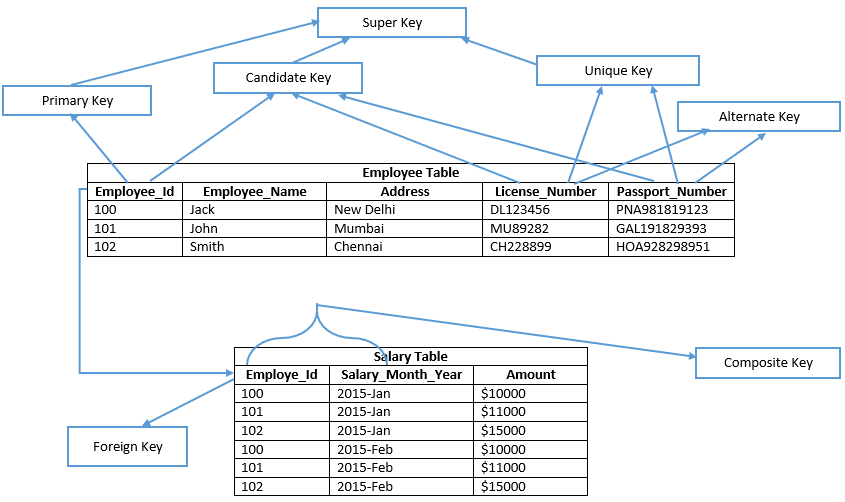
poznajmy szczegółowo każdy klucz
klucz kandydata
klucz kandydata jest kluczem tabeli, który może być wybrany jako klucz podstawowy tabeli, a tabela może mieć wiele kluczy kandydata, dlatego jeden może być wybrany jako klucz podstawowy.
przykład: Employee_Id, License_Number, & Passport_Number pokazuje klucze kandydata
klucz podstawowy
klucz podstawowy jest podobny do wybranego klucza kandydata w tabeli, aby zweryfikować każdy rekord danych w tabeli. Dlatego klucz podstawowy nie zawiera żadnej wartości null w żadnej z kolumn tabeli, a także zachowuje unikalne wartości w kolumnie. W podanym przykładzie Employee_Id definiuje klucz podstawowy tabeli pracowników. W związku z tym w SQL Server Management Studio klucz podstawowy domyślnie tworzy indeks klastrowy na tabeli sterty, a tabela, która nie składa się z indeksu klastrowego, jest znana jako tabela sterty. Określa jawnie nieklustrowany klucz podstawowy w tabeli według typu indeksu.
ponadto tabela może mieć tylko jeden klucz podstawowy i klucz podstawowy może być zdefiniowany w SQL Server za pomocą instrukcji SQL:
- Instrukcja CRETE TABLE (w momencie tworzenia tabeli) – w rezultacie system definiuje nazwę klucza podstawowego.
- ALTER polecenie TABLE (używając ograniczenia klucza podstawowego) – w rezultacie użytkownik sam deklaruje nazwę ograniczenia klucza podstawowego.
przykład: Employee_Id jest podstawowym kluczem tabeli pracowników.
unikalny klucz
unikalny klucz jest podobny do klucza podstawowego i nie zawiera zduplikowanych wartości w kolumnie. Ma poniżej różnice w porównaniu klucza podstawowego:
- pozwala na jedną wartość null w kolumnie.
- domyślnie tworzy niezgrupowane tabele indeksów i sterty.
klucz alternatywny
klucz alternatywny jest podobny do klucza kandydata, ale nie jest wybrany jako klucz podstawowy tabeli.
przykład: License_Number i Passport_Number są alternatywnymi kluczami.
klucz kompozytowy
klucz kompozytowy (znany również jako klucz złożony lub klucz konkatenowany) to grupa dwóch lub więcej kolumn, która jednoznacznie identyfikuje każdy wiersz tabeli. Ponadto pojedyncza kolumna jednostkowa klucza złożonego może nie być w stanie jednoznacznie zweryfikować zapisów danych. W rezultacie może to być klucz podstawowy lub klucz kandydata.
przykład: w tabeli Employee_Id & Salary_Month_Year obie kolumny weryfikują każdy wiersz w tabeli wynagrodzeń. Dlatego kolumny Employee_Id lub Salary_Month_Year w tabeli, które nie mogą jednoznacznie zidentyfikować każdego wiersza. Możemy utworzyć pojedynczy złożony klucz podstawowy w tabeli wynagrodzeń, używając nazw kolumn Employee_Id i Salary_Month_Year.
Super Key
Super key to zestaw kolumn, od których funkcjonalnie zależą wszystkie kolumny tabeli. Ze względu na zestaw kolumn, które jednoznacznie identyfikują każdy wiersz w tabeli. Innymi słowy, ten klucz zawiera kilka dodatkowych kolumn, które nie są ściśle wymagane do jednoznacznej weryfikacji każdego wiersza w tabeli. Wygląda na to, że klucz podstawowy i klucze kandydata są minimalnymi superkluczami lub można powiedzieć podzbiorem superkluczy.
spójrzmy więc na powyższy przykład, w tabeli pracowników nazwa kolumny Employee_Id nie jest wystarczająca, aby jednoznacznie zweryfikować dowolny wiersz tabeli. Tak więc każdy zestaw kolumn z tabeli pracowników, który zawiera Employee_Id, jest kluczem nadrzędnym dla tabeli pracowników.
na przykład: {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id, Employee_Name, Address} itd.
License_Number i Passport_Number to nazwy kolumn, mogą również jednoznacznie zweryfikować dowolny wiersz tabeli. Każdy z zestawu nazw kolumn, który składa się z numeru License_Number lub Passport_Number lub Employee_Id, jest kluczem nadrzędnym tabeli.
na przykład: {License_Number, Employee_Name, Address}, {License_Number, Employee_Name, Passport_number}, {Passport_Number, Employee_number, Address, License_Number}, {Passport_Number, Employee_Id} itd.
klucz obcy
FK definiuje zależność między dwiema lub więcej tabelami naraz. Klucz podstawowy pojedynczej tabeli jest odnoszony do klucza obcego w innej tabeli. Klucz obcy może mieć zduplikowane wartości w tabeli, a także może mieć wartości null, jeśli nazwa kolumny jest zdefiniowana tak, aby przyjmować wartości null.
na przykład nazwa kolumny „Employee_Id” ( która jest podstawowym kluczem tabeli pracowników ) jest kluczem zagranicznym w tabeli wynagrodzeń.
Uwaga: klucze takie jak klucz podstawowy i klucz unikalny tworzą indeksy z kolumnami kluczy. Uporządkowane dane w węźle struktury B-Tree (Balanced Tree: Leaf nodes are all at the different level from the root side) w SQL Server. W związku z tym indeks Nieklustrowany tworzy oddzielną strukturę z bazowej tabeli danych, ale indeks klastrowy konwertuje bazową tabelę danych ze struktury sterty do struktury drzewa B.
ponadto indeks klastrowy nie tworzy odrębnej struktury poza tabelą bazową i dlatego możemy utworzyć tylko jeden indeks klastrowy na tabeli. W związku z tym możemy sortować tabelę tylko w jeden sposób (może mieć wiele kolumn do sortowania, ale sortowanie może być wykonane tylko w jeden sposób), który jest kolejnością skumulowanego indeksu.
jak pracować z funkcjami SQL
funkcja jest programem encji, który jest przechowywany w bazie danych SQL Server albo można przekazać parametry do lub zwrócić wartość. Co więcej, będziemy czekać na kilka bardzo przydatnych wbudowanych funkcji i funkcji zdefiniowanych przez użytkownika.
funkcja Coalesce
Coalesce() : ta funkcja zwraca tylko pierwszą wartość inną niż NULL. Weźmy przykład funkcji Coalesce ().
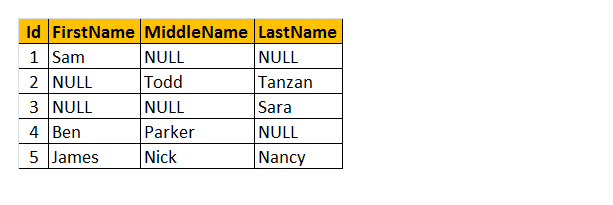 zrozummy tabelę jako nazwę 'pracownik’ powyżej. W rezultacie możesz zobaczyć, że niektórzy pracownicy mają brak imienia, niektórzy mają drugie imię, a niektórzy nazwisko. Tak więc chcę zwrócić tylko „imię” pracownika.
zrozummy tabelę jako nazwę 'pracownik’ powyżej. W rezultacie możesz zobaczyć, że niektórzy pracownicy mają brak imienia, niektórzy mają drugie imię, a niektórzy nazwisko. Tak więc chcę zwrócić tylko „imię” pracownika.
Jak to będzie działać? Rozumiem, że przetwarzamy kolumny FirstName, MiddleName i LastName jako parametry funkcji COALESCE (). Dlatego ta funkcja zwróci jedyną pierwszą wartość niezerową z 3 kolumn.
zapytanie: Wybierz Id, COALESCE (FirstName, MiddleName, LastName) jako nazwę z tblEmployee
na koniec wynik będzie wyglądał następująco;
 funkcja LEFT ()
funkcja LEFT ()
LEFT(Character_Expression, Integer_Expression) – funkcja Zwraca określoną ilość znaków z lewej strony danego wyrażenia wartości znakowej.
przykład: Select LEFT (’ABCDE’, 3)
wyjście: ABC
funkcja RIGHT ()
RIGHT(Character_Expression, Integer_Expression) – funkcja Zwraca określoną ilość znaków z prawej strony danego wyrażenia wartości znakowej.
przykład: Select RIGHT (’ABCDE’, 3)
wyjście: CDE
CHARINDEX() Function
CHARINDEX(’Expression_To_Find’, 'Expression_To_Search’, 'Start_Location’) – funkcja zwraca pozycję początkową podanego wyrażenia wartości w łańcuchu znaków. Parametr Start_Location jest opcjonalny.
przykład: zrozummy, tworzymy początkową pozycję znaku ’ @ ’ w ciągu wiadomości e-mail '[email protected]’.
Select CHARINDEX (’@’, '[email protected]’,1)
wyjście: 5
SUBSTRING() funkcja
SUBSTRING(wyrażenie’, 'Start’, 'Length’) – funkcja zwraca podłańcuch (podczęść łańcucha) z podanego wyrażenia wartości. Ponadto, gdy określasz pozycję początkową za pomocą parametru „start”, a inną liczbę znaków w podłańcuchu za pomocą parametru „Length”. Wszystkie trzy parametry są obowiązkowe.
przykład: chcę wyświetlić tylko część domeny podanego e-maila „[email protected]’.
Select SUBSTRING (’[email protected]’,6, 7)
wyjście: bbb.com
w rezultacie wykonaliśmy kodowanie z pozycją początkową i parametrami długości. Zamiast twardego kodowania parametrów, możemy je dynamicznie pobrać za pomocą funkcji łańcuchowych CHARINDEX() i len (), jak pokazano poniżej.
przykład:
Select SUBSTRING(’[email protected]’, (CHARINDEX (’@ ’, '[email protected]’) + 1), (LEN (’[email protected]’) – CHARINDEX ( ’ @ ’ ,’[email protected]’)))
wyjście: bbb.com
weźmy więc prawdziwy przykład z wykorzystaniem funkcji len (), CHARINDEX() i SUBSTRING (). Pomyślmy, że mamy tabelę, jak pokazano poniżej;
 więc pytanie brzmi, Jak znajdziesz całkowitą liczbę e-maili według ich domeny.
więc pytanie brzmi, Jak znajdziesz całkowitą liczbę e-maili według ich domeny.
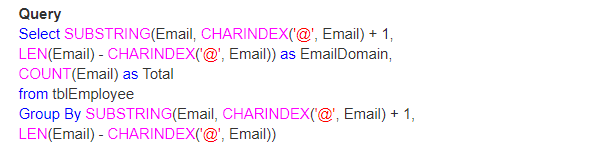
wyjście: na koniec wyjście będzie wyglądać następująco;
 funkcja REPLICATE ()
funkcja REPLICATE ()
REPLICATE (String_To_Be_Replicated, Number_Of_Times_To_Replicate) – funkcja ta powtarza podany punkt łańcucha i określoną liczbę razy.
przykład: SELECT REPLICATE (’Pragim’, 3)
wyjście: Pragim Pragim Pragim
porozmawiajmy o praktycznym przykładzie użycia funkcji REPLICATE (): Będziemy używać tej tabeli przez większość czasu, a do reszty naszych przykładów w tym artykule.
Załóżmy, że mamy tabelę, jak pokazano poniżej;
 zapytanie: Wybierz FirstName, LastName, SUBSTRING(Email, 1, 2) + Replikuj(’*’,5) +
zapytanie: Wybierz FirstName, LastName, SUBSTRING(Email, 1, 2) + Replikuj(’*’,5) +
SUBSTRING (Email, CHARINDEX (’@’, Email), LEN (Email) – CHARINDEX (’@’, Email)+1) jako Email
z tblEmployee
zróbmy email z symbolami 5 * (gwiazdki). Następnie wyjście będzie wyglądać następująco
 funkcja SPACE ()
funkcja SPACE ()
SPACE(Number_Of_Spaces) – funkcja ta zwraca jedyną liczbę spacji i określoną przez argument term Number_Of_Spaces.
przykład: funkcja SPACE(5) wstawia 5 spacji między FirstName i LastName
Wybierz FirstName + SPACE (5) + LastName jako FullName z tblEmployee
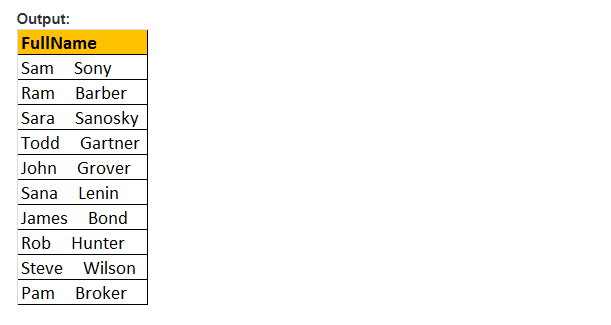 funkcja PATINDEX ()
funkcja PATINDEX ()
ta funkcja zwraca tylko początkową lokalizację pierwszego wystąpienia wzorca w określonym efektywnym wyrażeniu. Stąd potrzeba tylko dwóch argumentów, wzorca do przeszukiwania i wyrażenia. Dlatego PATINDEX() jest podobny do CHARINDEX(). W CHARINDEX () nie możemy używać symboli wieloznacznych, podczas gdy PATINDEX () wykorzystuje tę funkcję. Jeśli podana wartość wzorca nie zostanie znaleziona, patindex() zwraca ZERO.
przykład: wybierz Email, PATINDEX (’%aaa.com, E-Mail’) jako pierwsze z tblemplyee gdzie PATINDEX (’%@aaa.com’, Email) > 0
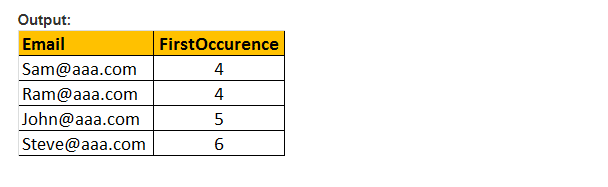 funkcja REPLACE ()
funkcja REPLACE ()
REPLACE (String_Expression, Pattern, Replacement_Value), funkcja ta zastępuje wszystkie wystąpienia określonej wartości łańcuchowej inną wartością łańcuchową.
przykład: wszystkie ciągi .COM są zastępowane. NET
Wybierz Email, zamień(Email, ’.com’, ’.net’) jako skonwertowana Poczta z tblEmployee
 funkcja STUFF ()
funkcja STUFF ()
STUFF(Original_Expression, Start, Length, Replacement_expression), Ta funkcja STUFF() wstawia tylko Replacement_expression, który jest określony na pozycji wyjściowej, wraz z usunięciem znaków podanych za pomocą wyrażenia wartości parametru Length.
przykład: Wybierz imię, nazwisko, e-mail, rzeczy (e-mail,2,3,’*****’) jako wypełniona Poczta od pracownika tbl.
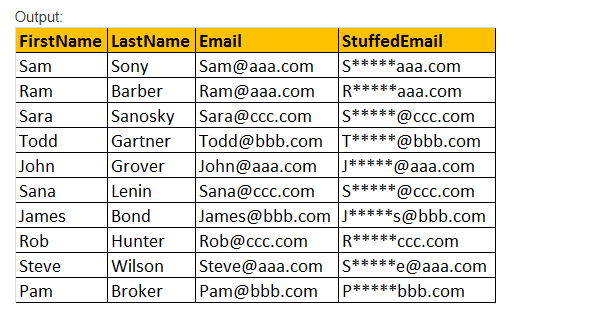 funkcja czasu daty
funkcja czasu daty
w bazie danych SQL Server dostępnych jest kilka wbudowanych funkcji DateTime. Większość z poniższych funkcji może być użyta do uzyskania aktualnej daty i godziny systemowej oraz miejsca, w którym jest zainstalowany SQL server.
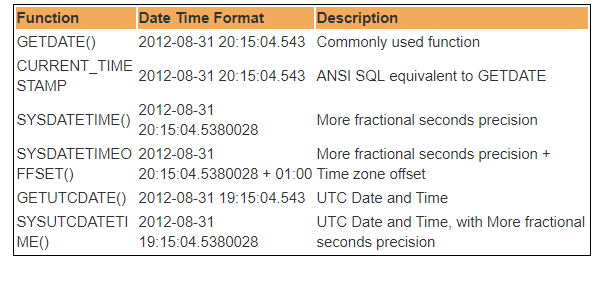 stąd UTC oznacza Coordinated Universal Time, na podstawie którego świat reguluje zegary i dane czasu. Godne uwagi. istnieją niewielkie różnice między GMT I UTC,ale dla większości typowych celów UTC jest synonimem GMT.
stąd UTC oznacza Coordinated Universal Time, na podstawie którego świat reguluje zegary i dane czasu. Godne uwagi. istnieją niewielkie różnice między GMT I UTC,ale dla większości typowych celów UTC jest synonimem GMT.
weźmy więc inny przykład, jak pokazano poniżej;
funkcja isDate ()
ISDATE () – ta funkcja sprawdza, czy jedyną podaną wartością jest prawidłowa data, godzina lub DateTime. Następnie zwróci 1 dla sukcesu, 0 dla porażki.
przykład:
Select ISDATE (’PRAGIM’) – zwróci 0
przykład:
Select ISDATE (Getdate ()) – zwróci 1
przykład:
Select ISDATE(’2018-01-20 21:02:04.167′) — zwróci 1
Uwaga: Dla wartości datetime2, IsDate zwraca ZERO.
przykład:
Wybierz ISDATE(’2018-01-20 22:02:05.158.1918447′) — zwróci 0.
funkcja Day ()
Day() – Ta funkcja zwraca tylko 'numer dnia miesiąca’ podanej daty.
:
Select DAY(GETDATE ()) – da wynik w imieniu numeru dnia miesiąca i na podstawie bieżącego systemu DateTime.
Select DAY(’01/14/2018′) — zwróci 14
funkcja Month ()
Month() – ta funkcja da wynik w imieniu 'numeru miesiąca roku’ podanej daty.
przykłady:
Select Month(GETDATE()) — ta funkcja wyświetli wynik w imieniu 'numeru miesiąca roku’ i na podstawie bieżącej daty i czasu systemowego.
Select Month(’05/14/2018) — zwróci 5
Year() Function
Year() – ta funkcja da wynik w imieniu 'year number’ podanej daty
przykłady:
Select Year(GETDATE()) — Zwraca numer roku i na podstawie bieżącej daty systemowej
select Year(’01/20/2018) — zwróci 2018
funkcja Datename ()
Datename(datepart, date) – ta funkcja zwraca tylko wyrażenie łańcuchowe, które reprezentuje tylko część podanej daty. Funkcje te składają się z 2 parametrów.
pierwszy parametr 'DatePart’ określa część daty, którą chcemy. Drugim parametrem jest rzeczywista data, od której chcemy część daty.
 przykład 1:
przykład 1:
Wybierz DATENAME (Day, '2017-04-20 13:47:47.350′) — zwróci 20
przykład 2:
Wybierz DATENAME (dzień tygodnia, '2017-04-20 13:47:47.350′) — powróci w czwartek
przykład 3:
Wybierz DATENAME(MONTH, '2017-04-20 13:47:47.350′) — zwróci April
więc weźmy przykład używając niektórych z tych funkcji DateTime. Rozważ tabelę pracowników.
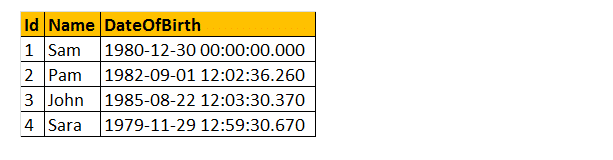 przykład: chcę zwrócić wszystkie nazwy, DateOfBirth, Day, MonthNumber, MonthName i Year, jak pokazano poniżej.
przykład: chcę zwrócić wszystkie nazwy, DateOfBirth, Day, MonthNumber, MonthName i Year, jak pokazano poniżej.
Select Name, DateOfBirth,DateName(dzień tygodnia, DateOfBirth) as, Month (DateOfBirth) as MonthNumber, DateName (miesiąc, DateOfBirth) as, Year (DateOfBirth) as From tblempracodawcy

funkcja DatePart ()
DatePart(DatePart, Date) – funkcja ta podaje liczbę całkowitą reprezentującą określoną wartość DatePart. Przeważnie funkcja jest podobna do funkcji DateName (). DateName() zwraca tylko wartość nvarchar, podczas gdy DatePart () zwraca tylko wartość całkowitą. Poprawne wartości parametrów DatePart są pokazane poniżej.
przykłady:
Wybierz DATEPART (dzień tygodnia, '2012-08-30 19:45:31.793′) — zwróci 5
Wybierz DATENAME (weekday, '2012-08-30 19:45:31.793′) — zwróci Thursday
funkcja DateAdd ()
DATEADD (datepart, NumberToAdd, date) – ta funkcja SQL podaje tylko DateTime, po określonym termie NumberToAdd i do datepartu określonego podanej daty.
:
Wybierz DateAdd (dzień, 10, '2018-01-20 19:45:31.793′) — powróci '2018-01-30 19:45:31.793′
Wybierz DateAdd (dzień, -10, '2012-08-30 19:45:31.793′)– powróci '2018-01-20 19:45:31.793′
DatedDiff () Function
DATEDIFF (datepart, startdate, enddate) – ta funkcja podaje liczbę określonych granic datepartu przekroczonych pomiędzy określonymi startdate i enddate.
:
Wybierz datę (miesiąc, ’11/30/2005′,’01/31/2006′) — zwróci 2
Select DATEDIFF (DAY, ’11/30/2005′,’01/31/2006′) — zwróci 62
więc weźmy przykład, załóżmy, że mamy tabelę podaną poniżej;
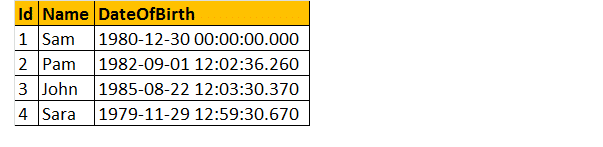
napisz więc zapytanie, aby dowiedzieć się, jaki jest wiek osoby, kiedy podana jest data urodzenia.

wreszcie, wyjście będzie wyglądać jak pokazano poniżej.
funkcje Cast() I Convert ()
aby przekonwertować pojedynczy typ danych jednostki na inny, można użyć funkcji CAST i CONVERT.
składnia funkcji CAST i CONVERT:
CAST ( wyrażenie jako data_type )
CONVERT ( data_type , wyrażenie )
ponadto, jak widać, funkcja CONVERT() ma opcjonalną wartość parametru style, podczas gdy funkcja CAST() nie ma tej możliwości.
weźmy więc przykład, bierzemy tabelę podaną poniżej;
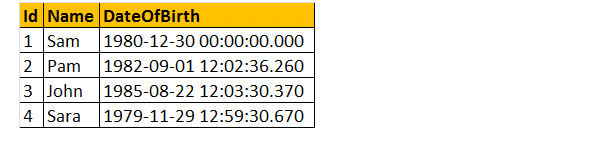 poniższe 2 zapytania konwertują dateofbirth ’ s DateTime datatype do NVARCHAR. Pierwsze zapytanie korzysta z funkcji CAST (), a drugie z funkcji CONVERT (). Wreszcie, wynik jest dokładnie taki sam dla obu zapytań, jak pokazano poniżej.
poniższe 2 zapytania konwertują dateofbirth ’ s DateTime datatype do NVARCHAR. Pierwsze zapytanie korzysta z funkcji CAST (), a drugie z funkcji CONVERT (). Wreszcie, wynik jest dokładnie taki sam dla obu zapytań, jak pokazano poniżej.
Wybierz ID, Name DateOfBirth, Cast(DateOfBirth jako nvarchar) jako ConvertedDOB z tblem employees.
Wybierz ID, nazwę DateOfBirth, Konwertuj (DateOfBirth jako nvarchar)jako ConvertedDOB z pracowników TBL.
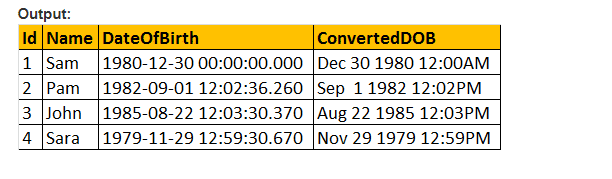 więc zróbmy parametr style wartości funkcji CONVERT () i sformatujmy datę tak, jak byśmy tego chcieli. Tak więc używamy 103 jako przekazania argumentu dla parametru style w podanym poniżej zapytaniu i który formatuje datę jako dd / mm / ry.
więc zróbmy parametr style wartości funkcji CONVERT () i sformatujmy datę tak, jak byśmy tego chcieli. Tak więc używamy 103 jako przekazania argumentu dla parametru style w podanym poniżej zapytaniu i który formatuje datę jako dd / mm / ry.
Wybierz ID, Name, DateOfBirth, Convert (nvarchar, DateOFBirth, 103) jako ConvertedDOB od pracowników tbl.
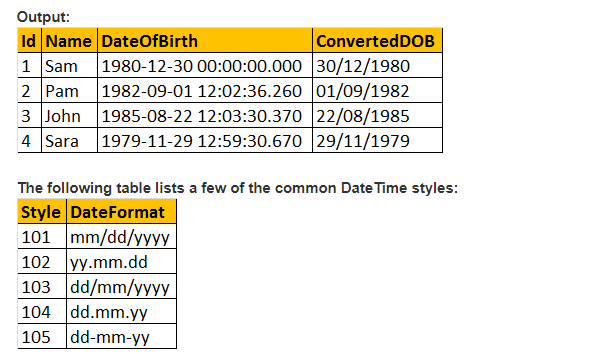
spójrzmy więc na praktyczny przykład z pomocą funkcji CAST ();
Załóżmy, że mamy tabelę rejestracyjną poniżej jako;
 teraz znajdźmy całkowitą liczbę rejestracji w ciągu dnia.
teraz znajdźmy całkowitą liczbę rejestracji w ciągu dnia.
przykład: wybierz CAST (RegisteredDate as DATE) as RegistrationDate, COUNT (Id) as TotalRegistrations Tblregistrations Group By Cast (RegisteredDate as DATE)
Output: Finally the output will look as ;
funkcje zdefiniowane przez użytkownika
Istnieją 3 typy funkcji zdefiniowanych przez Użytkownika w SQL Server, które jako
- funkcje skalarne
- funkcje wbudowane w tabelę
- funkcje wielostanowiskowe
funkcje skalarne
funkcje skalarne różnią się parametrami, które mogą, ale nie muszą mieć parametrów i zawsze dają pojedynczą (skalarną) wartość na wyjściu. Dlatego zwracana wartość może być dowolnego formatu danych z wyjątkiem wartości tekstowej, tekstu, obrazu, kursora i znacznika czasu.
przykład: Opracujmy więc funkcję, która oblicza i zwraca wiek osoby na wyjściu. W związku z tym, aby porównać wiek, który wymagaliśmy, datę urodzenia. Podajmy datę urodzenia jako parametr. Dlatego funkcja AGE () zwróci liczbę całkowitą i zaakceptuje parametr date.
 Wybierz dbo.Wiek (dbo.Wieku(„10/08/1982”).
Wybierz dbo.Wiek (dbo.Wieku(„10/08/1982”).
weźmy więc praktyczny przykład w poniższej tabeli w następujący sposób;
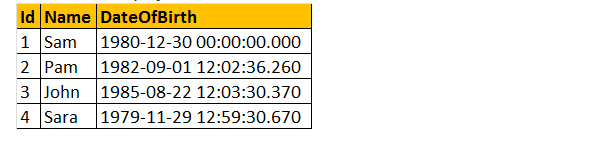
skalarne funkcje zdefiniowane przez użytkownika mogą być użyte w klauzuli Select, jak pokazano poniżej.
wybierz nazwę, DateOfBirth, dbo.Wiek (DateOfBirth)jako wiek pracowników
 najczęściej przegląda tekst funkcji Użyj funkcji sp_helptext.
najczęściej przegląda tekst funkcji Użyj funkcji sp_helptext.
funkcje wbudowane w tabelę
funkcja wbudowana w tabelę zawsze zwraca tabelę jako wynik.
weźmy przykład poniżej; Utwórz funkcję, która zwraca pracowników według płci.
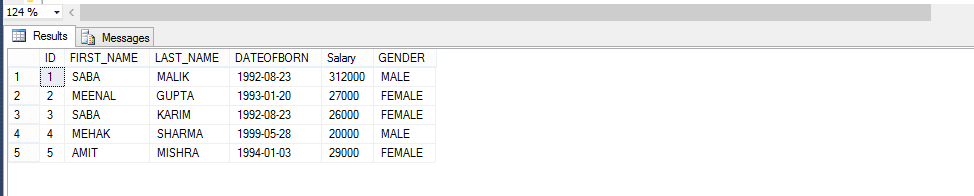
ze względu na wywołanie metody dla funkcji zdefiniowanej przez użytkownika,
Select * From Fn_EMPLOYEEbyGender (’male’)
funkcja wielostanowiskowa o wartości tabeli
funkcje wielostanowiskowe o wartości tabeli są znacznie bardziej podobne do funkcji Inline o wartości tabeli i z pewnymi różnicami. Spójrzmy więc na przykład, a następnie zauważmy różnice.
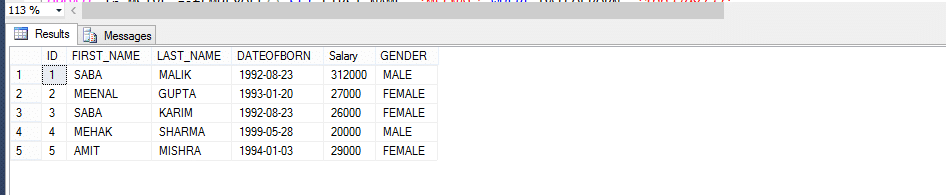
funkcja wielostanowiskowa o wartości tabeli (MSTVF):
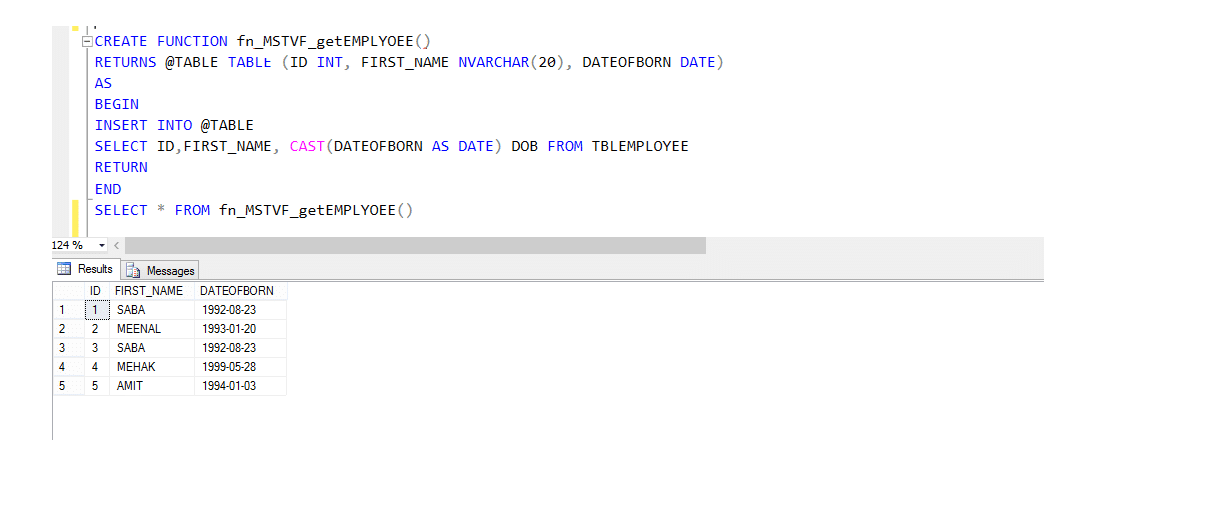 ze względu na wywołanie metody dla funkcji Vthe Multi-statement table Valued:
ze względu na wywołanie metody dla funkcji Vthe Multi-statement table Valued:
Select * from fn_MSTVF_GetEmployees ()
Conclusion
JOINs jest bardzo zrozumiałym terminem dla początkujących w fazie nauki poleceń SQL. W związku z tym, w wywiadzie, ankieter zadaje co najmniej jedno pytanie jest o SQL łączy i funkcji. Tak więc, w tym poście, staram się uprościć rzeczy dla nowych uczniów SQL i ułatwić zrozumienie SQL dołącza. Co więcej, funkcje w SQL, Wiele osób ma problemy ze zrozumieniem rzeczywistej funkcji roboczej. Ponieważ SQL zawiera wiele danych w różnych nazwach baz danych i tabel. Funkcja jest zapisanym programem w bazie danych SQL Server, do którego można przekazać parametry i zwrócić wartość. Podałem więc trochę bardziej użytecznego terminu o działaniu funkcji.
- o
- najnowsze posty

- różnica między SQL i MySQL-Kwiecień 14, 2020
- jak pracować z Podquery w eksploracji danych-Marzec 23, 2018
- jak korzystać z funkcji przeglądarki Javascript? – Marzec 9, 2018
