Aller à la Section
- Introduction SQL
- Comment travailler avec les jointures SQL
- Jointure interne
- Jointure gauche
- Rejoindre à Droite
- Jointure extérieure complète
- Cross join
- Comment travailler avec Advance SQL Joins
- Rejoindre à Gauche
- Jointure extérieure complète
- Types de clés en SQL
- Clé candidate
- Clé primaire
- Clé unique
- Clé alternative
- Clé composite
- Super Key
- Clé étrangère
- Comment travailler avec les fonctions SQL
- Fonction LEFT()
- Fonction RIGHT()
- Fonction CHARINDEX()
- Fonction SUBSTRING()
- REPLICATE() Function
- Fonction SPACE()
- Fonction PATINDEX()
- REPLACE() Fonction
- Fonction STUFF()
- Fonction Date-heure
- isDate() Function
- Fonction Month()
- Fonction Year()
- Fonction DateName()
- Fonction DatePart()
- Fonction DateAdd()
- Fonction DatedDiff()
- Fonctions Cast() et Convert()
- Fonctions définies par l’utilisateur
- Fonctions scalaires
- Fonctions à valeur de table en ligne
- FONCTION à valeurs DE TABLE MULTI-INSTRUCTIONS
- Conclusion
Introduction SQL
SQL signifie Langage de requête structuré. Il est principalement utilisé pour la manipulation, la modification et la récupération de données. Cela vient avec le Système de gestion de base de données Relationnelle (SGBDR).
Nous allons en apprendre davantage sur les fonctionnalités plus avancées de SQL telles que les jointures et les fonctions.
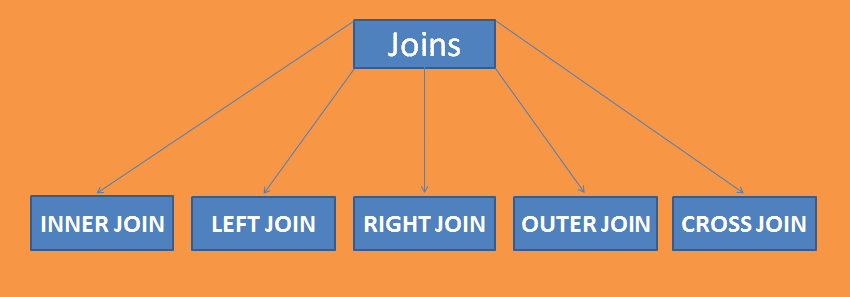
Comment travailler avec les jointures SQL
Un moyen de jointure simple consiste à combiner deux tables ou plus dans une base de données donnée. Une jointure fonctionne sur une entité commune de deux tables.
Une jointure contient 5 sous-jointures qui sont: Jointure interne, Jointure externe, Jointure Gauche, Jointure Droite et Jointure croisée.
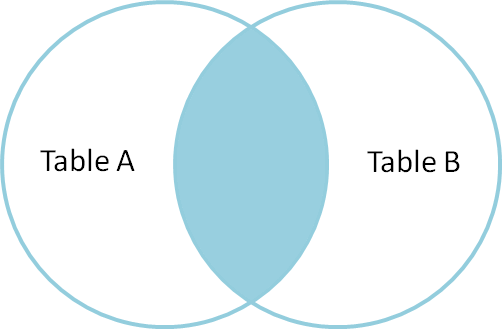
Jointure interne
Une jointure interne est utilisée pour sélectionner des enregistrements contenant des valeurs communes ou correspondantes dans les deux tables (tableau A et Tableau B). Les non-appariements sont éliminés.
Alors, comprenons le type de jointures, et avec des exemples communs et les différences entre eux.
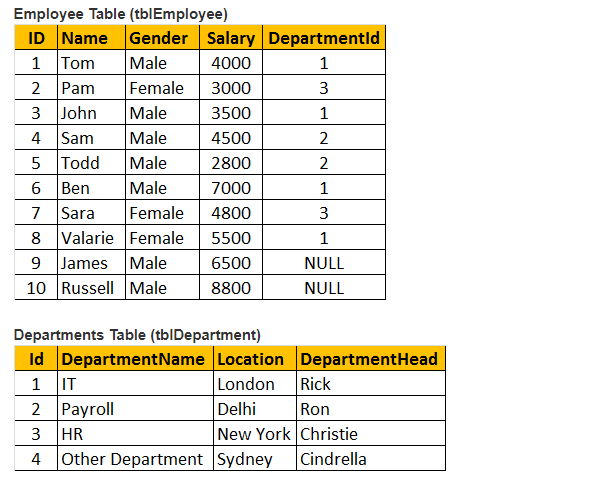
Tableau 1 : Tableau des employés (Tblemployé)
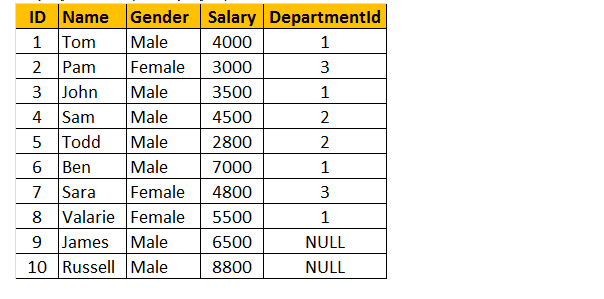
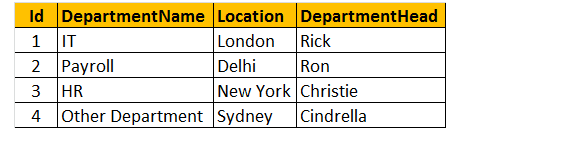
Tableau 2 : Tableau des départements (TBLDÉPARTEMENTS)
Alors, créons la table TBLDÉPARTEMENTS pour l’exécution d’un programme.

Maintenant, Insérez des enregistrements dans la table tblDepartments.

Créons une autre table Tblemployé pour l’exécution d’un programme.

Insérez donc des enregistrements dans la table tblEmployee.

Par conséquent, une formule générale pour les jointures.

Pour effectuer une requête pour trouver le nom, le sexe, le salaire et le nom du département à partir des tables tblEmployee et tblDepartments.

Remarque: JOIN ou INNER JOIN signifie la même chose. Mais toujours mieux d’utiliser INNER JOIN, et cela spécifie explicitement votre intention.
Sortie: Maintenant, la table de sortie finale ressemblera à ceci;
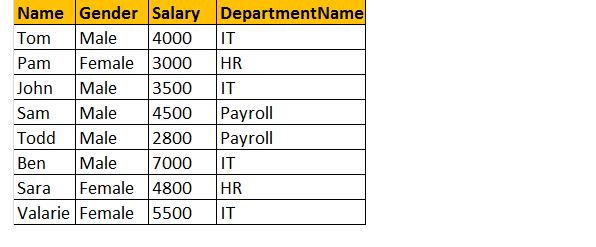
Si vous regardez la fenêtre de sortie, nous n’avons que 8 lignes, mais dans le tableau tblEmployee, nous avons 10 lignes. On n’a pas eu les enregistrements de JAMES et RUSSELL. En effet, le DEPARTMENTID, dans la table tblEmployee est NUL pour ces deux employés et ne correspond pas à leur colonne ID dans la table tblDepartments.
Ainsi, dans une instruction finale, les jointures internes renvoient uniquement les lignes correspondantes des tables et les lignes non correspondantes sont éliminées en raison de sa sous-requête.
Jointure gauche
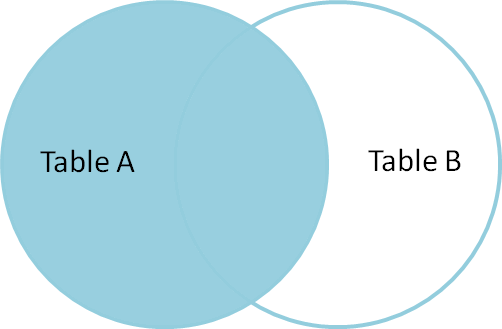
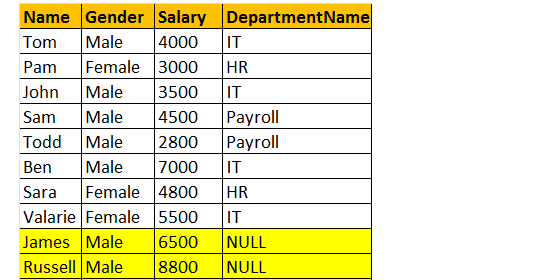
LEFT Join renvoie toutes les lignes correspondantes et les lignes non correspondantes de la table latérale gauche. De plus, la jointure intérieure et la jointure gauche sont largement utilisées l’une l’autre.
Prenons donc un exemple, je veux toutes les lignes de la table tblEmployee, y compris les enregistrements JAMES et RUSSELL. Ensuite, la sortie ressemblera à;

Rejoindre à Droite
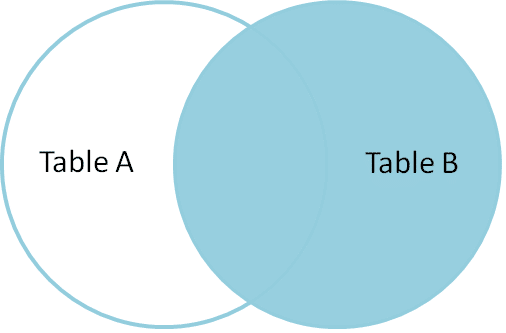
RIGHT Join renvoie toutes les lignes correspondantes et les lignes non correspondantes de la table latérale droite.
Prenons donc un exemple; je veux que toutes les lignes des bonnes tables soient impliquées dans la jointure. En conséquence serait comme;

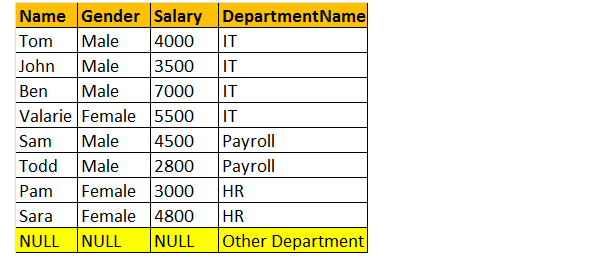
Jointure extérieure complète

OUTER Join ou FULL OUTER Join renvoie toutes les lignes des tables de gauche et de droite, y compris les lignes non correspondantes des tables.
Prenons donc un exemple; je veux toutes les lignes des deux tables impliquées dans la jointure.

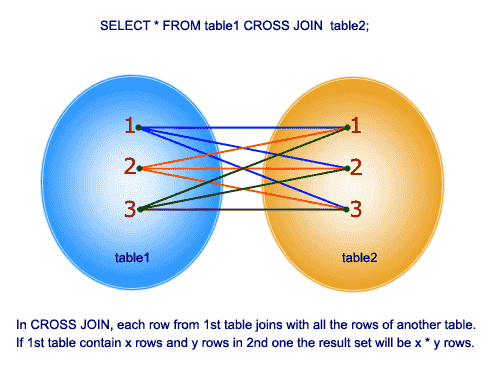
Cross join
Cette jointure donne le produit cartésien des 2 tables de la fonction join. Cette jointure ne contient pas de clause ON.
Alors, comprenons un exemple: Dans la table tblEmployee, nous avons 10 lignes et dans la table tblDepartments, nous avons 4 lignes. Ainsi, une jointure croisée entre ces 2 tables produit 40 lignes.

Comment travailler avec Advance SQL Joins
Dans cette session, je vais expliquer ces choses comme suit;
- Jointures avancées ou intelligentes dans SQL Server.
- Récupère uniquement les données des lignes non correspondantes de la table de gauche.
- Récupère uniquement les lignes non correspondantes de la table de droite.
- Récupère uniquement les données des lignes non correspondantes des tables de gauche et de droite.
Considérons donc à la fois les tables tblEmployee et tblDepartment.
Rejoindre à Gauche
Donc, comprenons un exemple, je veux récupérer uniquement les lignes non correspondantes de la table latérale gauche.

Sortie: Enfin, la sortie ressemblera à ceci;

Rejoindre à Droite
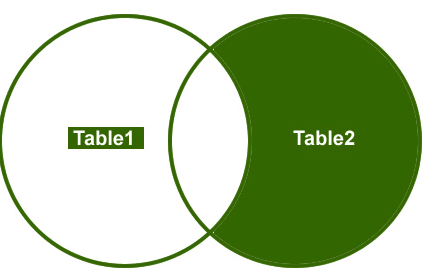
Donc, comprenons un exemple, je veux récupérer uniquement les lignes non correspondantes de la table latérale droite.

Sortie: Enfin, la sortie ressemblera à ceci;

Jointure extérieure complète
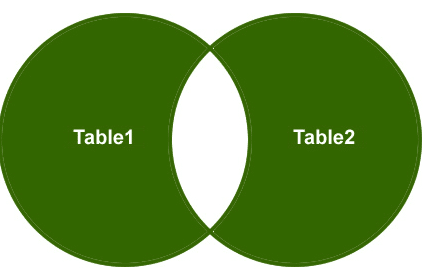
Donc, comprenons un exemple, je veux récupérer uniquement les lignes non correspondantes de la table latérale droite et de la table latérale gauche et les lignes correspondantes doivent être éliminées.

Sortie: Enfin, la sortie ressemblera à ceci ;
Types de clés en SQL
Une clé en SQL est un champ de données qui identifie exclusivement un enregistrement. En un autre mot, une clé est un ensemble de colonnes utilisées pour identifier de manière unique l’enregistrement dans une table.
- Créez des relations entre deux tables.
- Maintenir l’unicité et la responsabilité dans un tableau.
- Conservez des données cohérentes et valides dans une base de données.
- Peut aider à la récupération rapide des données en facilitant les index sur la ou les colonnes.
Un serveur SQL contient les clés suivantes;
- Clé candidate
- Clé Primaire
- Clé unique
- Clé Alternative
- Clé composite
- Super Key
- Clé étrangère
Avant d’aller de l’avant, et veuillez consulter l’image ci-dessous;
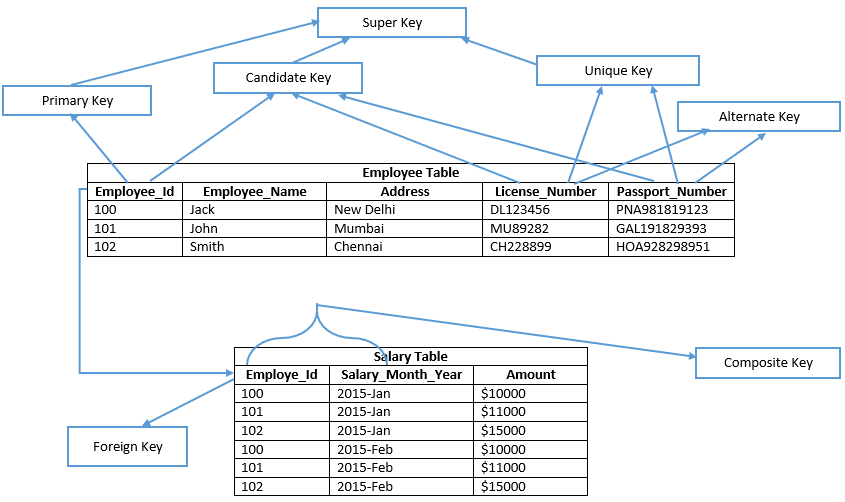
Comprenons chaque clé en détails
Clé candidate
Une clé candidate est une clé d’une table qui peut être sélectionnée comme clé primaire de la table et une table peut avoir plusieurs clés candidates, donc une peut être sélectionnée comme clé primaire.
Exemple : Employee_Id, Numéro de licence, & Numéro de passeport affiche les clés candidates
Clé primaire
Une clé primaire est similaire à la clé candidate sélectionnée de la table pour vérifier chaque enregistrement de données de manière unique dans la table. Par conséquent, la clé primaire ne contient aucune valeur nulle dans aucune des colonnes d’une table et conserve également des valeurs uniques dans la colonne. Dans l’exemple donné, Employee_Id définit la clé primaire de la table Employee. Par conséquent, dans SQL Server Management Studio, la clé primaire crée un index en cluster sur une table de tas par défaut et une table qui ne consiste pas en un index en cluster est connue sous le nom de table de tas. Indique si définit explicitement une clé primaire non en cluster sur une table par type d’index.
De plus, une table ne peut avoir qu’une seule clé primaire et la clé primaire peut être définie dans SQL Server à l’aide d’instructions SQL:
- Instruction CRETE TABLE (au moment de la création de la table) – en conséquence, le système définit le nom de la clé primaire.
- Instruction ALTER TABLE (en utilisant une contrainte de clé primaire) – par conséquent, l’utilisateur déclare lui-même le nom de la contrainte de clé primaire.
Exemple : Employee_Id est une clé primaire de la table Employee.
Clé unique
Une clé unique est similaire à la clé primaire et ne contient pas de valeurs en double dans la colonne. Il présente des différences ci-dessous dans la comparaison de la clé primaire:
- Il permet une valeur nulle dans la colonne.
- Par défaut, il crée un index non clusterisé et des tables de tas.
Clé alternative
La clé alternative est similaire à la clé candidate, Mais n’est pas sélectionnée comme clé primaire de la table.
Exemple : License_Number et Passeport_number sont des clés alternatives.
Clé composite
La clé composite (également appelée clé composée ou clé concaténée) est un groupe de deux colonnes ou plus qui identifie chaque ligne d’une table de manière unique. De plus, une seule colonne unitaire d’une clé composite peut ne pas être en mesure de vérifier de manière unique les enregistrements de données. En conséquence, Il peut également s’agir d’une clé primaire ou d’une clé candidate.
Exemple : Dans le tableau, Employee_Id & Salary_Month_Year les deux colonnes vérifient chaque ligne de manière unique dans le tableau des salaires. Par conséquent, la colonne Employee_Id ou Salary_Month_Year dans la table, qui ne peut pas identifier chaque ligne de manière unique. Nous pouvons créer une clé primaire composite unique sur la table des salaires en utilisant les noms de colonnes Employee_Id et Salary_Month_Year.
Super Key
Super key est un ensemble de colonnes dont toutes les colonnes de la table dépendent fonctionnellement. En raison de l’ensemble de colonnes qui identifie de manière unique chaque ligne d’une table. En un autre mot, cette clé contient quelques colonnes supplémentaires qui ne sont pas strictement nécessaires pour vérifier de manière unique chaque ligne de la table. Il semble que les clés primaires et les clés candidates soient des super-clés minimales ou vous pouvez dire un sous-ensemble de super-clés.
Donc, regardons l’exemple ci-dessus, Dans la table Employee, le nom de colonne Employee_Id n’est guère suffisant pour vérifier de manière unique n’importe quelle ligne de la table. Ainsi, tout ensemble de colonne de la table Employee contenant Employee_Id est une super-clé pour la table Employee.
Par exemple : {Employee_Id}, {Employee_Id, Employee_Name}, {Employee_Id, Employee_Name, Address} etc.
License_Number et Passeport_number sont le nom des colonnes, il peut également vérifier de manière unique n’importe quelle ligne de la table. Toute personne dont le nom de colonne est défini par License_Number ou Passeport_number ou Employee_Id est une super-clé de la table.
Par exemple: {Numéro de licence, Nom de l’employé, Adresse}, {Numéro de licence, Nom de l’employé, Numéro de passeport}, { Numéro de passeport, Nom de l’employé, Adresse, Numéro de licence}, {Numéro de passeport, Nom de l’employé}, {Numéro de passeport, Nom de l’employé}, {Numéro de passeport, Numéro de l’employé} etc.
Clé étrangère
Un FK définit la relation entre deux tables ou plus à la fois. Une clé primaire d’une seule table est référencée à une clé étrangère dans une autre table. Une clé étrangère peut avoir des valeurs en double dans une table et peut également avoir des valeurs nulles si le nom de colonne est défini pour accepter encore des valeurs nulles.
Par exemple, le nom de colonne « Employee_Id » (qui est une clé primaire de la table des employés) est une clé étrangère dans la table des salaires.
Remarque: Les clés comme la clé primaire et la clé unique créent des index avec des colonnes de clés. Données organisées dans un nœud de structure en arbre B (Arbre équilibré : les nœuds feuilles sont tous à un niveau différent du côté racine) dans SQL Server. Par conséquent, l’index non groupé crée une structure distincte de la table de données de base, mais l’index clusterisé convertit la table de données de base de la structure de tas en une structure d’arborescence B.
De plus, l’index en cluster ne crée pas de structure distincte de la table de base et c’est la raison pour laquelle nous ne pouvons créer qu’un seul index en cluster sur une table. Par conséquent, nous ne pouvons trier une table que d’une seule manière (elle peut avoir plusieurs colonnes à trier mais le tri ne peut être effectué que d’une seule manière) qui est l’ordre de l’index en cluster.
Comment travailler avec les fonctions SQL
Une fonction est un programme d’entité qui est stocké dans la base de données SQL Server, vous pouvez passer des paramètres ou renvoyer une valeur. En outre, nous nous réjouirons de certaines fonctions intégrées très utiles et des fonctions définies par l’utilisateur.
Fonction Coalesce
Coalesce(): Cette fonction renvoie uniquement la première valeur non NULLE. Prenons donc un exemple sur la fonction Coalesce().
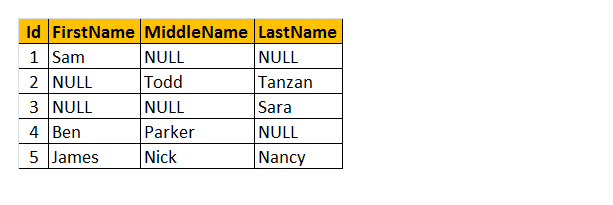 Comprenons le tableau comme nom ‘Employé’ ci-dessus. En conséquence, vous pouvez voir que certains employés ont leur prénom manquant, certains ont un deuxième prénom et certains d’entre eux ont un nom de famille manquant. Donc, je veux retourner uniquement le « Nom » de l’employé.
Comprenons le tableau comme nom ‘Employé’ ci-dessus. En conséquence, vous pouvez voir que certains employés ont leur prénom manquant, certains ont un deuxième prénom et certains d’entre eux ont un nom de famille manquant. Donc, je veux retourner uniquement le « Nom » de l’employé.
Comment cela va-t-il fonctionner? Comprenez, nous traitons les colonnes FirstName, MiddleName et LastName comme paramètres de la fonction COALESCE(). Par conséquent, cette fonction retournera la seule première valeur non nulle de 3 des colonnes.
Requête: Sélectionnez Id, COALESCE(FirstName, MiddleName, LastName) COMME Nom DE tblEmployee
Enfin, la sortie ressemblera à ceci;
 Fonction LEFT()
Fonction LEFT()
LEFT(Expression de caractères, expression d’entiers) – Cette fonction renvoie le nombre spécifié de caractères du côté gauche de l’expression de valeur de caractères donnée.
Exemple : Sélectionnez À GAUCHE (‘ABCDE’, 3)
Sortie : ABC
Fonction RIGHT()
RIGHT(Expression de caractères, expression d’entiers) – Cette fonction renvoie le nombre spécifié de caractères du côté droit de l’expression de valeur de caractères donnée.
Exemple : Sélectionnez À DROITE (‘ABCDE’, 3)
Sortie: CDE
Fonction CHARINDEX()
CHARINDEX(‘Expression_To_Find’, ‘Expression_To_Search’, ‘Start_Location’) – Cette fonction renvoie la position de départ de l’expression de valeur spécifiée dans une sous-chaîne de caractères. Le paramètre Start_Location est facultatif.
Exemple: Comprenons, nous faisons la position de départ du caractère ‘@’ dans la chaîne d’e-mail’[email protected] ‘.
Sélectionnez CHARINDEX(‘@’, ‘[email protected]’,1)
Sortie: 5
Fonction SUBSTRING()
SUBSTRING(expression ‘, ‘Start’, ‘Length’) – Cette fonction renvoie la sous-chaîne (sous-partie de la chaîne), à partir de l’expression de valeur donnée. De plus, lorsque vous spécifiez la position de départ en utilisant le paramètre ‘start’ et l’autre nombre de caractères dans la sous-chaîne en utilisant le paramètre ‘Length’. Les trois paramètres sont obligatoires.
Exemple: Je souhaite afficher uniquement une partie du domaine de l’e-mail donné ‘[email protected] ‘.
Sélectionnez la SOUS-CHAÎNE (‘[email protected]’,6, 7)
Sortie : bbb.com
En conséquence, nous avons effectué le codage avec la position de départ et les paramètres de longueur. Au lieu de coder en dur les paramètres, nous pouvons les récupérer dynamiquement en utilisant les fonctions de chaîne CHARINDEX() et LEN() comme indiqué ci-dessous.
Exemple:
Sélectionnez une SOUS-CHAÎNE(‘[email protected] ‘, ‘, ‘, ‘, ‘, ‘, ‘, ‘, ‘, ‘, ‘, ‘,’,’[email protected] ‘) + 1), (LEN(‘[email protected] ‘) – CHARINDEX (‘@’, ‘[email protected]’)))
Sortie: bbb.com
Prenons donc un exemple réel avec l’utilisation des fonctions LEN(), CHARINDEX() et SUBSTRING(). Pensons que nous avons un tableau comme indiqué ci-dessous;
 La question est donc de savoir Comment allez-vous trouver le nombre total d’e-mails par domaine.
La question est donc de savoir Comment allez-vous trouver le nombre total d’e-mails par domaine.
Sortie: Enfin, la sortie ressemblera à ceci;
 REPLICATE() Function
REPLICATE() Function
REPLICATE(String_To_Be_Replicated, Number_Of_Times_To_Replicate) – Cette fonction répète le point donné de la chaîne et pour le nombre de fois spécifié.
Exemple : SÉLECTIONNEZ RÉPLIQUER(‘Pragim’, 3)
Sortie: Pragim Pragim Pragim
Parlons d’un exemple pratique d’utilisation de la fonction REPLICATE(): Nous utiliserons ce tableau la plupart du temps, et pour le reste de nos exemples dans cet article.
Supposons donc que nous ayons un tableau comme indiqué ci-dessous;
 Requête : Sélectionnez Prénom, nom, SOUS-CHAÎNE (Email, 1, 2) + RÉPLIQUER(‘*’,5) +
Requête : Sélectionnez Prénom, nom, SOUS-CHAÎNE (Email, 1, 2) + RÉPLIQUER(‘*’,5) +
SOUS-CHAÎNE (Email, CHARINDEX(‘@’, Email), LEN(Email) – CHARINDEX(‘@’, Email) +1) comme Email
de tblEmployee
Faisons un email avec 5 * (étoiles) symboles. Ensuite, la sortie serait comme ceci
 Fonction SPACE()
Fonction SPACE()
SPACE(Number_Of_Spaces) – Cette fonction renvoie le seul nombre d’espaces, et spécifié par le terme argument Number_Of_Spaces.
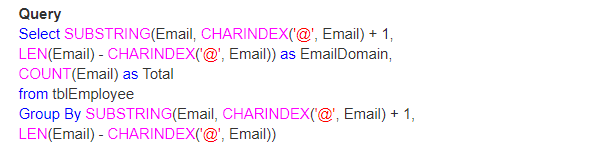
Exemple: La fonction SPACE(5) insère 5 espaces entre FirstName et LastName
Select FirstName + SPACE(5) + LastName as FullName From tblEmployee
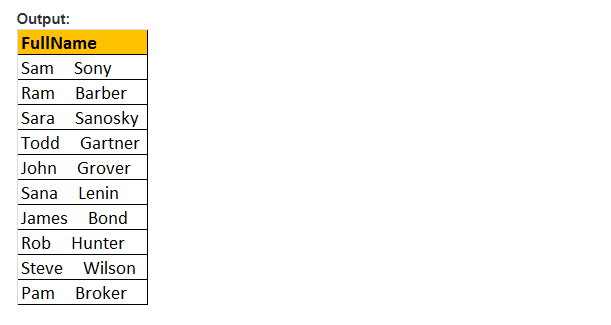 Fonction PATINDEX()
Fonction PATINDEX()
Cette fonction ne renvoie que l’emplacement de départ de la première occurrence d’un motif dans une expression effective spécifiée. Par conséquent, il ne faut que deux arguments, et le modèle à rechercher et l’expression. Par conséquent, PATINDEX() est similaire à CHARINDEX(). Avec CHARINDEX(), nous ne pouvons pas utiliser de caractères génériques, tandis que PATINDEX() implique cette fonctionnalité. Si la valeur de modèle spécifiée n’est pas trouvée, PATINDEX() renvoie ZÉRO.
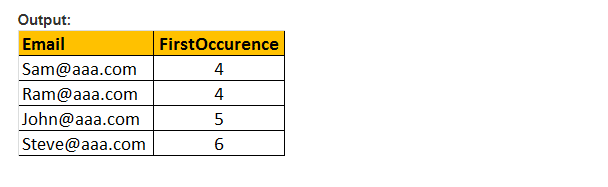
Exemple: Sélectionnez Email, PATINDEX(‘%aaa.com , Email ‘) comme première occurrence de tblEmployee où PATINDEX (‘% @ aaa.com’, E-mail) > 0
 REPLACE() Fonction
REPLACE() Fonction
REPLACE(Expression de chaîne, Motif, valeur de remplacement), Cette fonction remplace toutes les positions d’occurrences d’une valeur de chaîne spécifiée par une autre valeur de chaîne.
Exemple: Toutes les chaînes .COM sont remplacées par .NET
Sélectionnez Email, REPLACE(Email, ‘.com’, ‘.net ‘) en tant que ConvertedEmail de tblEmployee
 Fonction STUFF()
Fonction STUFF()
STUFF(Expression d’origine, Début, Longueur, Expression de remplacement), Cette fonction STUFF() insère uniquement l’expression de remplacement, qui est spécifiée à la position de départ, ainsi que la suppression des caractères spécifiés à l’aide de l’expression de valeur de paramètre de longueur.
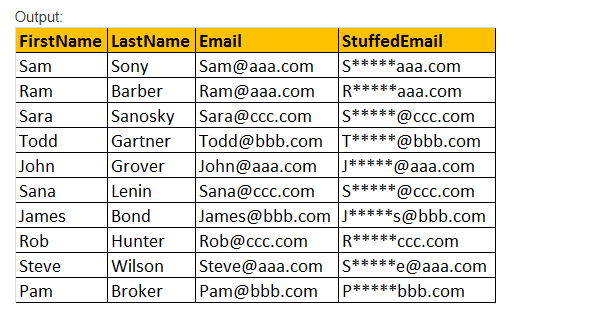
Exemple: Sélectionnez Prénom, Nom, Email, STUFF (Email,2,3,’*****’) comme le courrier de tblEmployee.
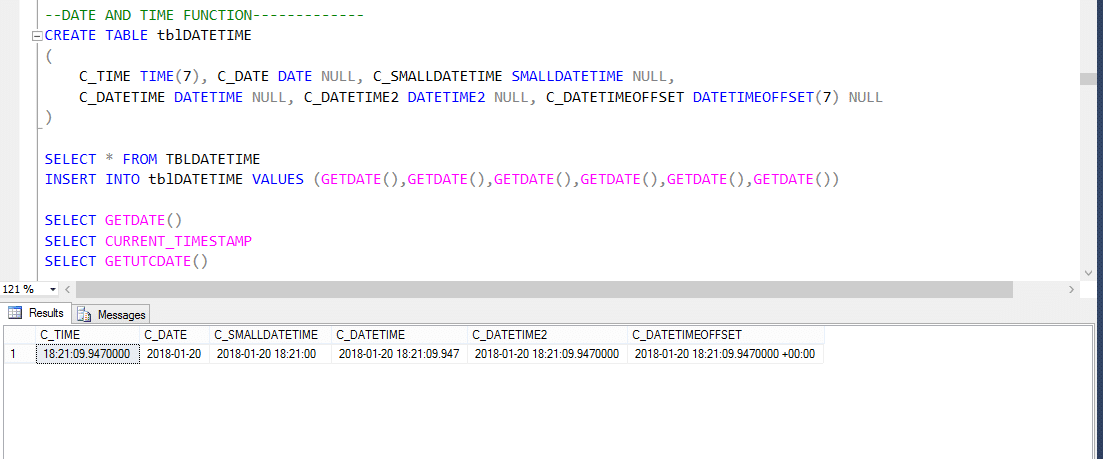
 Fonction Date-heure
Fonction Date-heure
Plusieurs fonctions DateTime intégrées sont disponibles dans la base de données SQL Server. La plupart des fonctions suivantes peuvent être utilisées pour obtenir la date et l’heure actuelles du système et l’emplacement où SQL server est installé.
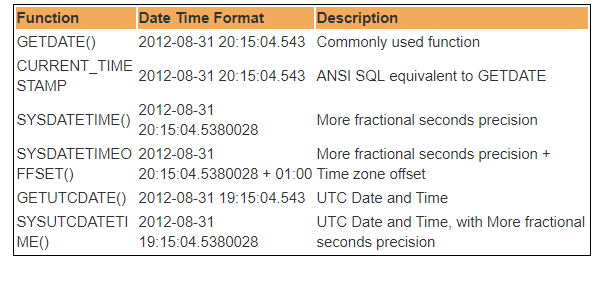 Par conséquent, UTC signifie Temps universel coordonné, sur la base duquel le monde régule les horloges et les données temporelles. Remarquable. il existe des différences mineures entre GMT et UTC, mais pour la plupart des fins courantes, UTC est synonyme de GMT.
Par conséquent, UTC signifie Temps universel coordonné, sur la base duquel le monde régule les horloges et les données temporelles. Remarquable. il existe des différences mineures entre GMT et UTC, mais pour la plupart des fins courantes, UTC est synonyme de GMT.
Prenons donc un autre exemple comme indiqué ci-dessous;
isDate() Function
ISDATE() – Cette fonction vérifie si la seule valeur donnée et existe une date, une heure ou une date-heure valides. Ensuite, il retournera 1 pour le succès, 0 pour l’échec.
Exemple:
Sélectionnez ISDATE(‘PRAGIM’) – il retournera 0
Exemple:
Sélectionnez ISDATE(Getdate()) — il retournera 1
Exemple:
Sélectionnez ISDATE(‘2018-01-20 21:02:04.167’) — il retournera 1
Remarque: Pour les valeurs datetime2, IsDate renvoie ZÉRO.
Exemple:
Sélectionnez ISDATE(‘2018-01-20 22:02:05.158.1918447’) — il retournera 0.
Fonction Day()
Day() – Cette fonction renvoie uniquement le ‘Numéro de jour du Mois’ de la date donnée.
Exemples:
Select DAY(GETDATE()— – Il donnera la sortie au nom du numéro de jour du mois et en fonction de la date-heure actuelle du système.
Select DAY(’14/01/2018′) – il renverra 14
Fonction Month()
Month() – Cette fonction donnera la sortie au nom du ‘Numéro de mois de l’année’ de la date donnée.
Exemples:
Select Month(GETDATE()) — Cette fonction donnera la sortie au nom du ‘Numéro de mois de l’année’, et en fonction de la date et de l’heure actuelles du système.
Select Month(’14/05/2018) — il renverra 5
Fonction Year()
Year() – Cette fonction donnera la sortie au nom du ‘Numéro d’année’ de la date donnée
Exemples:
Select Year(GETDATE()) — Renvoie le numéro d’année, et en fonction de la date système actuelle
Select Year(’20/01/2018) — il retournera 2018
Fonction DateName()
DateName(DatePart, Date) – Cette fonction renvoie uniquement une expression de chaîne, et cela ne représente qu’une partie de la date donnée. Ces fonctions sont constituées de 2 paramètres.
Le premier paramètre ‘DatePart’ spécifie, la partie de la date, que nous voulons. Le deuxième paramètre est la date réelle, à partir de laquelle nous voulons la partie de la Date.
 Exemple 1:
Exemple 1:
Sélectionnez le NOM DE DATE (Jour, ‘2017-04-20 13:47:47.350’) — il renverra 20
Exemple 2 :
Select DATENAME (JOUR DE LA SEMAINE, ‘2017-04-20 13:47:47.350’) — il retournera jeudi
Exemple 3:
Sélectionnez DATENAME (MOIS, ‘2017-04-20 13:47:47.350’) — il retournera April
Alors, prenons un exemple en utilisant certaines de ces fonctions DateTime. Considérez le tableau Tblemployés.Exemple
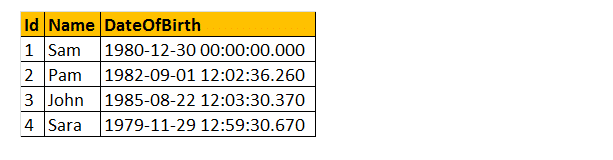 : Je souhaite renvoyer tous les Noms, DateOfBirth, Day, MonthNumber, MonthName et Year comme indiqué ci-dessous.
: Je souhaite renvoyer tous les Noms, DateOfBirth, Day, MonthNumber, MonthName et Year comme indiqué ci-dessous.
Sélectionnez Nom, Date DE naissance, Nom(JOUR DE LA SEMAINE, Date de naissance) comme, Mois (Date de naissance) comme Numéro de mois, Nom de date (MOIS, Date de naissance) comme, Année (Date de naissance) à partir de Tblemployés

Fonction DatePart()
DatePart(DatePart, Date) – Cette fonction donne un entier représentant la valeur de DatePart spécifiée. La plupart du temps, la fonction est similaire à la fonction DateName(). DateName() ne renvoie que la valeur nvarchar, tandis que DatePart() ne renvoie qu’une valeur entière. Les valeurs des paramètres DatePart valides sont affichées ci-dessous.
Exemples:
Sélectionnez le DATEPART (jour de la semaine, ‘2012-08-30 19:45:31.793’) — il renverra 5
Select DATENAME (jour de la semaine, ‘2012-08-30 19:45:31.793’) — il retournera Thursday
Fonction DateAdd()
DATEADD(datepart, NumberToAdd, date) – Cette fonction SQL ne donne que la date-heure, après le terme spécifié NumberToAdd, et à la date spécifiée de la date donnée.
Exemples:
Sélectionner la dateajouter (JOUR, 10, ‘2018-01-20 19:45:31.793’) — il reviendra ‘2018-01-30 19:45:31.793’
Sélectionnez Dateajouter (JOUR, -10, ‘2012-08-30 19:45:31.793’)– il reviendra ‘2018-01-20 19:45:31.793’
Fonction DatedDiff()
DATEDIFF(datepart, startdate, enddate) – Cette fonction donne le nombre de limites de datepart spécifiées franchies entre les dates de début et de fin spécifiées.
Exemples:
Sélectionnez DATEDIFF (MOIS, ’11/30/2005′,’01/31/2006′) — il retournera 2
Select DATEDIFF(DAY, ’11/30/2005′,’01/31/2006′) — il retournera 62
Donc, prenons un exemple, Supposons que nous ayons un tableau donné ci-dessous;
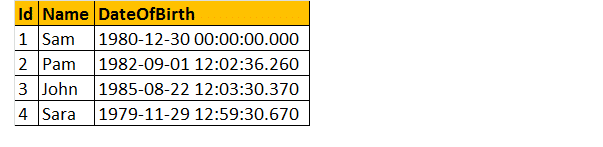
Alors, écrivez une requête pour connaître l’âge d’une personne, lorsque la date de naissance est donnée.

Enfin, la sortie se présentera comme indiqué ci-dessous.
Fonctions Cast() et Convert()
Pour convertir un type de données unitaire en un autre, les fonctions CAST et CONVERT peuvent être utilisées.
Syntaxe de la fonction CAST et CONVERT:
CAST(expression EN TANT QUE type de données)
CONVERT(type de données, expression)
De plus, Comme vous pouvez le voir, la fonction CONVERT() a une valeur de paramètre de style facultative, alors que la fonction CAST() n’a pas cette capacité.
Alors, Prenons un exemple, nous prenons un tableau donné ci-dessous;
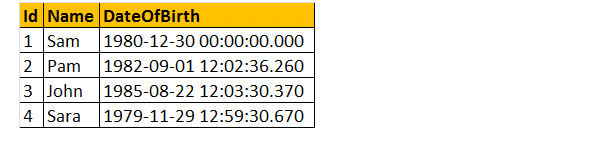 Les 2 requêtes suivantes convertissent le type de données DateTime de DateOfBirth en NVARCHAR. La première requête utilise la fonction CAST() et la seconde utilise la fonction CONVERT(). Enfin, la sortie est exactement la même pour les deux requêtes, comme indiqué ci-dessous.
Les 2 requêtes suivantes convertissent le type de données DateTime de DateOfBirth en NVARCHAR. La première requête utilise la fonction CAST() et la seconde utilise la fonction CONVERT(). Enfin, la sortie est exactement la même pour les deux requêtes, comme indiqué ci-dessous.
Sélectionnez ID, Nom DateOfBirth, Cast (DateOfBirth en tant que nvarchar) en tant que ConvertedDOB de tblemployees.
Sélectionnez ID, Nom DateOfBirth, Convert (DateOfBirth en tant que nvarchar) en tant que ConvertedDOB à partir de tblemployees.
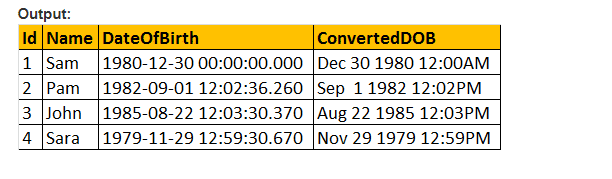 Alors, faisons le paramètre de style de la valeur de la fonction CONVERT(), et formatons la Date comme nous le souhaiterions. Donc, nous utilisons 103 comme passant l’argument du paramètre de style dans la requête ci-dessous, et qui formate la date en jj / mm / aa.
Alors, faisons le paramètre de style de la valeur de la fonction CONVERT(), et formatons la Date comme nous le souhaiterions. Donc, nous utilisons 103 comme passant l’argument du paramètre de style dans la requête ci-dessous, et qui formate la date en jj / mm / aa.
Sélectionnez ID, Name, DateOfBirth, Convert(nvarchar, DateOFBirth, 103) en tant que ConvertedDOB de tblEmployees.
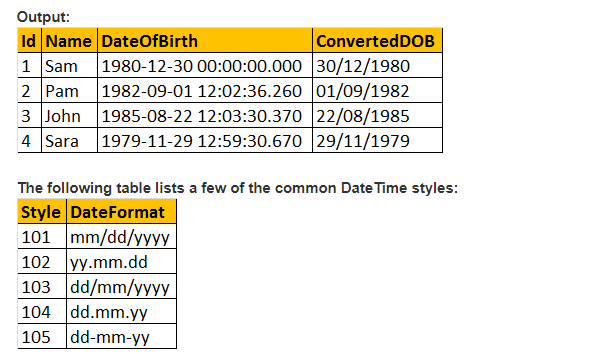
Alors, regardons un exemple pratique à l’aide de la fonction CAST();
Supposons que nous ayons une table d’enregistrement ci-dessous comme;
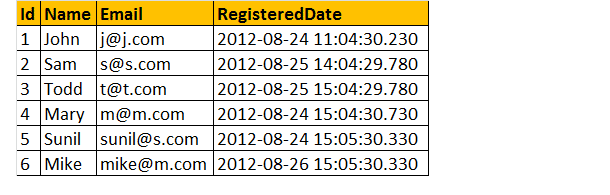 Maintenant, trouvons le nombre total d’inscriptions par jour.
Maintenant, trouvons le nombre total d’inscriptions par jour.
Exemple : Sélectionnez CAST(RegisteredDate as DATE) en tant que RegistrationDate, COUNT(Id) en tant que TotalRegistrations tblRegistrations Group By CAST (RegisteredDate as DATE)
Sortie: Enfin, la sortie ressemblera à ;
Fonctions définies par l’utilisateur
Il existe 3 types de Fonctions définies par l’utilisateur dans SQL Server qui en tant que
- Fonctions scalaires
- Fonctions à valeur de table en ligne
- Fonctions à valeur de table multistatement
Fonctions scalaires
Les fonctions scalaires varient en paramètres qui peuvent avoir ou non des paramètres, et donnent toujours une seule valeur (scalaire) dans la sortie. Par conséquent, la valeur renvoyée peut être de n’importe quel format de type de données à l’exception de la valeur de texte, du texte, de l’image, du curseur et de l’horodatage.
Exemple: Développons donc une fonction qui calcule et renvoie l’âge d’une personne en sortie. Par conséquent, pour comparer l’âge requis, la date de naissance. Passons donc la date de naissance comme paramètre. Par conséquent, la fonction AGE() renverra un entier et acceptera le paramètre date.
 Sélectionnez dbo.Âge (dbo.Âge (’10/08/1982′).
Sélectionnez dbo.Âge (dbo.Âge (’10/08/1982′).
Prenons donc un exemple pratique dans le tableau ci-dessous comme suit;
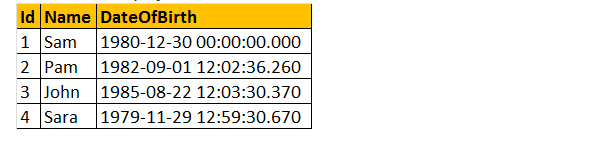
Les fonctions scalaires définies par l’utilisateur peuvent être utilisées dans la clause Select comme indiqué ci-dessous.
Sélectionnez Nom, Date de naissance, dbo.Age (Date de naissance) en tant qu’âge de Tblemployés
 Visualisez principalement le texte de la fonction utilisez sp_helptext FunctionName.
Visualisez principalement le texte de la fonction utilisez sp_helptext FunctionName.
Fonctions à valeur de table en ligne
Une fonction à valeur de table en ligne renvoie toujours une table en sortie.
Prenons donc un exemple ci-dessous; Créez une fonction qui renvoie les EMPLOYÉS par SEXE.
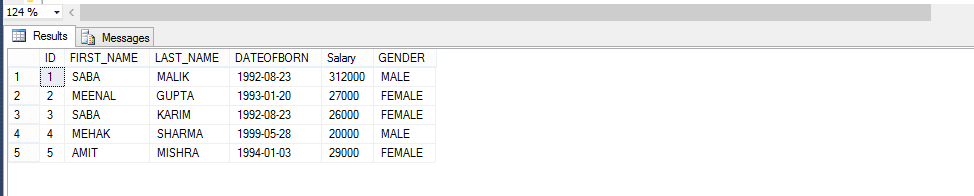
en raison de la méthode d’appel de la fonction définie par l’utilisateur,
Select * From Fn_EMPLOYEEbyGender(‘male’)
FONCTION à valeurs DE TABLE MULTI-INSTRUCTIONS
Les fonctions à valeurs de table multi-instructions sont beaucoup plus similaires aux fonctions à valeurs de table en ligne et avec quelques différences. Alors, regardons un exemple, puis notons les différences.
Tableau des employés
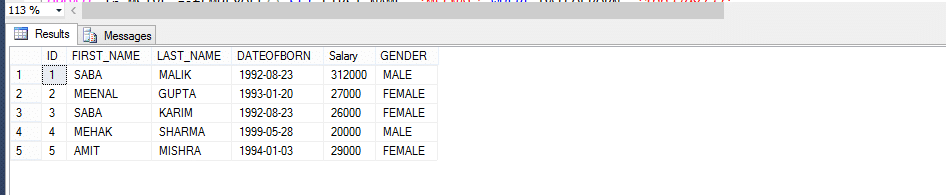
Fonction de valeur de table Multi-instructions (MSTVF):
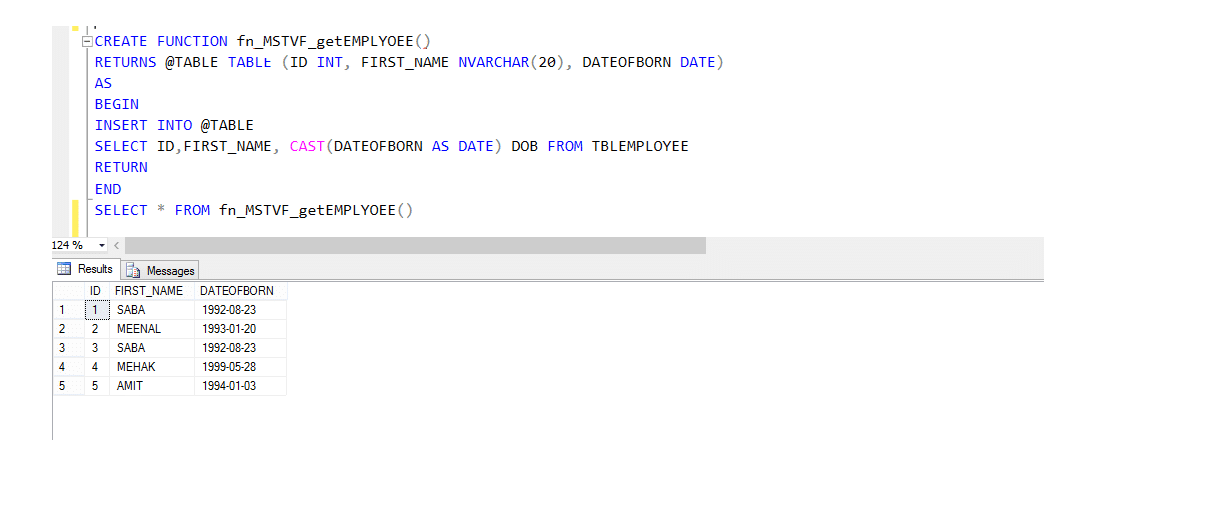 En raison de la méthode d’appel pour vla Fonction Valorisée de Table Multi-instructions:
En raison de la méthode d’appel pour vla Fonction Valorisée de Table Multi-instructions:
Select* from fn_MSTVF_GetEmployees()
Conclusion
Les jointures sont un terme très compréhensible pour les débutants pendant la phase d’apprentissage des commandes SQL. Par conséquent, Dans l’interview, l’intervieweur pose au moins une question sur les jointures SQL et les fonctions. Donc, dans cet article, j’essaie de simplifier les choses pour les nouveaux apprenants SQL et de faciliter la compréhension des jointures SQL. De plus, Les fonctions en SQL, beaucoup de gens ont du mal à comprendre la fonction de travail réelle. Parce que SQL contient beaucoup de données en vrac dans différents noms de bases de données et de tables. Une fonction est un programme stocké dans la base de données SQL Server dans lequel vous pouvez transmettre des paramètres et renvoyer une valeur. J’ai donc donné un terme plus utile sur le fonctionnement des fonctions.
- À propos de
- Derniers messages

- Différence entre SQL et MySQL – 14 avril 2020
- Comment travailler avec une sous-requête dans l’exploration de données – 23 mars 2018
- Comment utiliser les fonctionnalités du navigateur Javascript? – Mars 9, 2018
