Vad är Beräkningsvy?
SAP HANA Beräkningsvy är en kraftfull Informationsvy.
SAP HANA Analytic view measure kan väljas från endast en faktatabell. När det finns behov av mer faktatabell i informationsvyn kommer beräkningsvyn på bilden. Beräkningsvyn stöder komplex beräkning.
datagrunden för beräkningsvyn kan innehålla tabeller, kolumnvyer, analytiska vyer och beräkningsvyer.
vi kan skapa kopplingar, fackföreningar, aggregering och prognoser på datakällor.
Beräkningsvyn kan innehålla flera mått och kan användas för flerdimensionell rapportering eller inget mått som används i listtyprapportering.
karakteristisk för SAP HANA Beräkningsvy enligt nedan–
- stöd komplex beräkning.
- stöd OLTP och OLAP modeller.
- stöd klienthantering, språk, valutakonvertering.
- stöd Union, projektion, aggregering, rang, etc.
SAP HANA Beräkningsvy är av två typer–
- SAP HANA grafisk Beräkningsvy (skapad av SAP HANA Studio grafisk redaktör).
- SAP HANA Script-baserade beräkningar vyer (skapad av SQL-skript av SAP HANA Studio).
SAP HANA grafisk Beräkningsvy
i SAP HANA analytisk vy kan vi bara välja ett mått från en tabell.
så när det finns ett krav på en vy som innehåller mått från den olika tabellen kan den inte uppnå genom analytisk vy utan genom beräkningsvy.
så i det här fallet kan vi använda två olika analytiska vyer för varje tabell och ansluta dem till beräkningsvyn.
vi kommer att skapa en grafisk Beräkningsvy ” CA_FI_LEDGER ”genom att gå med i två analytiska vyer” AN_PURCHASE_ORDER ”och”AN_FI_DOCUMENT”.
CA_FI_LEDGER visar finansdokumentdetaljer relaterade till en inköpsorder.
steg 1) i detta steg,
- gå till paketet (här modellering) och högerklicka.
- Välj Nytt Alternativ.
- Välj Beräkningsvy.
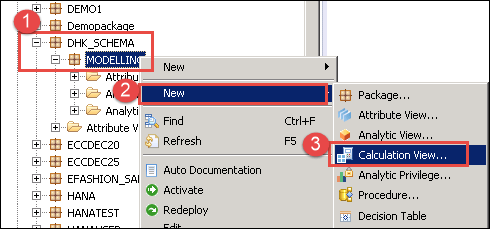
en beräkning View Editor kommer att visas, i vilket Scenario Panel display som nedan–
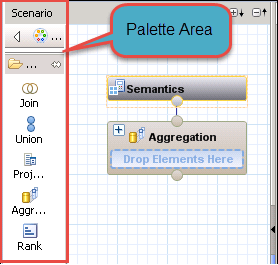
detalj av Scenario panelen är som nedan–
- palett: Det här avsnittet innehåller nedan noder som kan användas som källa för att bygga våra beräkningsvyer.
vi har 5 olika typer av noder, de är
- gå med: denna nod används för att gå med i två källobjekt och skicka resultatet till nästa nod. Kopplingstyperna kan vara inner, left outer, right outer och text join.Vi kan bara lägga till två källobjekt i en kopplingsnod.
- Union: detta används för att utföra union all operation mellan flera källor. Källan kan vara n antal objekt.
- projektion: detta används för att välja kolumner, filtrera data och skapa ytterligare kolumner innan vi använder den i nästa noder som en union, aggregering och rang.
notera: Vi kan bara lägga till ett källobjekt i en Projektionsnod.
- aggregering: detta används för att utföra aggregering på specifika kolumner baserat på de valda attributen.
- Rank: detta är den exakta ersättningen för RANK-funktionen i SQL. Vi kan definiera partitionen och order by-klausulen baserat på kravet.
steg 2)
- Klicka på Projektionsnod från paletten och dra och släpp till scenarioområde från Analysvyn för inköpsorder. Bytt namn till ”Projection_PO”.
- Klicka på Projektionsnod från paletten och dra och släpp till scenarioområde för fi Document analytic view. Bytt namn till ”Projection_FI”.
- dra och släpp analytisk vy ”AN_PUCHASE_ORDER” ”AN_FI_DOCUMENT” och från innehållsmapp till Projektionsnod respektive ”Projection_FI”.
- Klicka på Gå med nod från paletten och dra och släpp till scenarioområdet.
- gå Projection_PO nod till Join_1 nod.
- gå Projection_FI nod till Join_1 nod.
- Klicka på aggregering nod från paletten och dra och släpp till scenario område.
- gå Join_1 nod till aggregering nod.
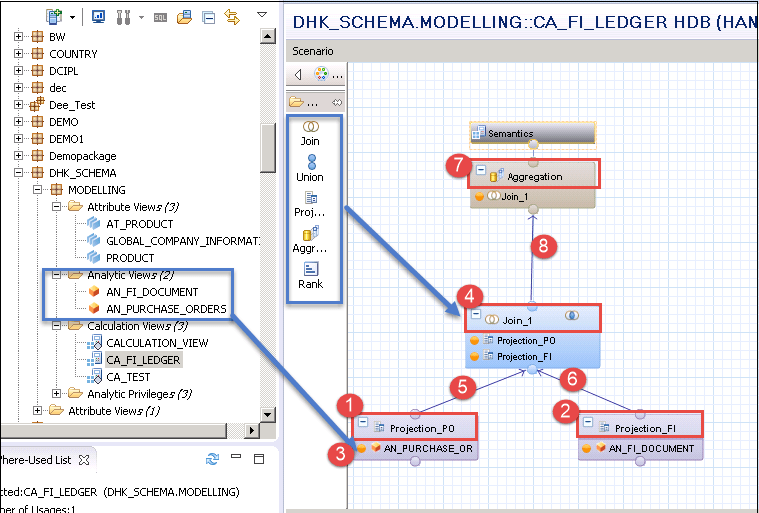
vi har lagt till två analytiska vyer, för att skapa en beräkning vy.
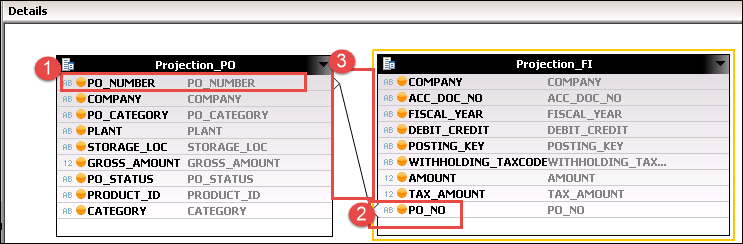
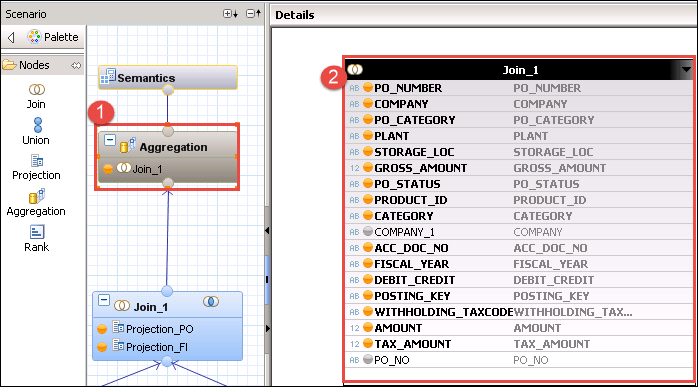
steg 3) Klicka på join_1 nod under aggregering och du kan se detaljavsnittet visas.
- Välj alla kolumn från Projection_PO nod för utdata.
- Välj alla kolumn från Projection_FI nod för utdata.
- gå Projection_PO nod till Projection_FI nod på kolumn
Projection_PO. PO_Number = Projection_FI.PO_NO.
steg 4) i detta steg,
- Klicka på aggregering nod och detaljer kommer att visas på höger sida av rutan.
- Välj kolumn för utmatning från Join_1 som visas på höger sida i detaljfönstret.
steg 5) Nu, klicka på semantik nod.
![]()
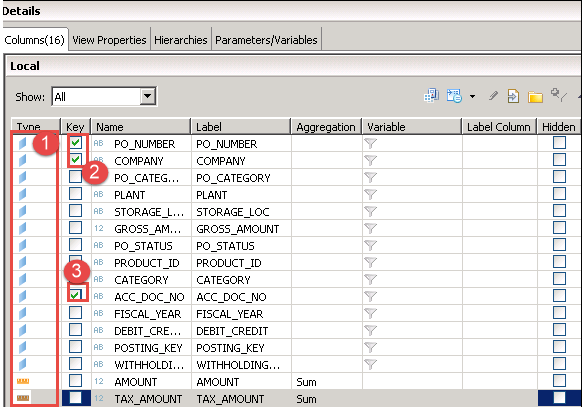
detalj skärmen kommer att visas som nedan. Definiera attribut och mäta typ för kolumnen och även markera nyckel för denna utgång.
- definiera attribut och mått.
- markera Po_nummer och företag som nyckel.
- markera ACC_DOC_NO som nyckel.
steg 6) validera och aktivera beräkningsvy, från det övre fältet i fönstret.
![]()
- Klicka på Validera ikonen.
- Klicka på Aktivera ikonen.
Beräkningsvy kommer att aktiveras och visas under Modelleringspaket enligt nedan–
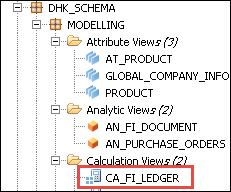
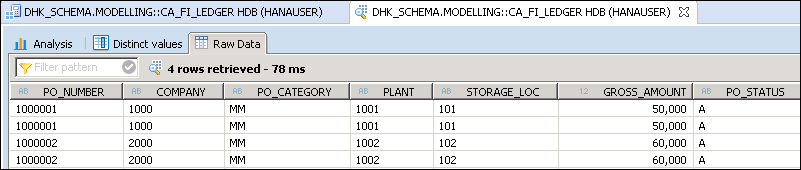
Välj beräkningsvy och högerklicka ->dataförhandsgranskning
vi har lagt till två analytiska vyer och välj mått (TAX_AMOUNT, GROSS_AMOUNT) från både analytisk vy.
skärmen för förhandsgranskning av Data visas enligt nedan–
CE funktioner även känd som beräkning Engine Plan Operator (CE operatörer) är alternativ till SQL-satser.
CE – funktionen är två typer –
datakällans åtkomstfunktion
denna funktion binder en kolumntabell eller en kolumnvy till en tabellvariabel.
nedan är några datakälla åtkomstfunktion lista–
- CE_COLUMN_TABLE
- CE_JOIN_VIEW
- CE_OLAP_VIEW
- CE_CALC_VIEW
relationell Operatörsfunktion
genom att använda relationell operatör kan användaren kringgå SQL-processorn under utvärderingen och kommunicera direkt med beräkningsmotorn.
nedan är några relationella Operatörsfunktionslista–
- CE_JOIN (det används för att utföra inre koppling mellan två källor och
läs de nödvändiga kolumnerna/data.)
- CE_RIGHT_OUTER_JOIN (det används för att utföra höger yttre koppling mellan de två källorna
och visa de frågade kolumnerna till utgången.)
- CE_LEFT_OUTER_JOIN (det används för att utföra vänster yttre koppling mellan källorna och
visa de frågade kolumnerna till utgången).
- CE_PROJECTION (den här funktionen visar de specifika kolumnerna från källan och använder
– filter för att begränsa data. Det ger kolumnnamn Alias funktioner också.)
- CE_CALC (det används för att beräkna ytterligare kolumner baserat på affärskravet.
detta är samma som beräknad kolumn i grafiska modeller.)
nedan är en lista över SQL med CE-funktion med några exempel-
| Frågenamn | SQL-fråga | CE-inbyggd funktion |
|---|---|---|
| Välj fråga på Kolumntabellen | välj C, D från”COLUMN_TABLE”. | CE_COLUMN_TABLE (”COLUMN_TABLE”,) |
| Välj fråga på Attributvy | välj C, D från ”ATTRIBUTE_VIEW” | CE_JOIN_VIEW (”ATTRIBUTE_VIEW”,) |
| Välj fråga på analytisk vy | välj C, D, SUM (E) från ”ANALYTIC_VIEW” – gruppen av C, D | CE_OLAP_VIEW (”ANALYTIC_VIEW”,) |
| Välj fråga vid Beräkningsvy | välj C, D, SUM (E) från ”CALCULATION_VIEW” – gruppen av C, D | CE_CALC_VIEW (”CALCULATION_VIEW”,) |
| var har | välj C, D, Summa (E) från” ANALYTIC_VIEW ”där C = ’värde’ | Var1= CE_COLUMN_TABLE (”COLUMN_TABLE”); CE_PROJECTION (: var1,, ” C ” = ”värde”/ |
