dit voorbeeld is gebaseerd op de misdaadstatistieken van de FBI uit 2006. We zijn vooral geïnteresseerd in de relatie tussen de omvang van de staat en het aantal moorden in de stad.
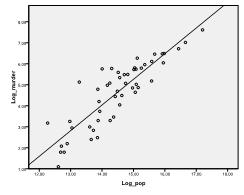
eerst moeten we controleren of er een lineair verband is in de gegevens. Daarvoor controleren we de scatterplot. Het diagram geeft een goede lineaire relatie aan, waardoor we een lineaire regressieanalyse kunnen uitvoeren. We kunnen ook de bivariate correlatie van Pearson controleren en vinden dat beide variabelen sterk gecorreleerd zijn (r = .959 met P < 0,001).

ontdek hoe we helpen bij het bewerken van uw proefschrift Hoofdstukken
het uitlijnen van theoretisch kader, het verzamelen van artikelen, het synthetiseren van hiaten, het articuleren van een duidelijke methodologie en data plan, en het schrijven over de theoretische en praktische implicaties van uw onderzoek zijn onderdeel van onze uitgebreide proefschrift editing services.
- breng proefschrift editing expertise om hoofdstukken 1-5 in tijdige wijze.
- volg alle wijzigingen en werk dan samen met u om wetenschappelijk schrijven tot stand te brengen.
- voortdurende steun voor feedback van het Comité, waardoor herzieningen worden beperkt.
ten tweede moeten we controleren op multivariate normaliteit. In ons voorbeeld vinden we dat multivariate normaliteit misschien niet aanwezig is.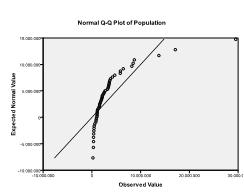
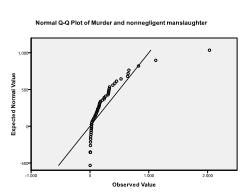
de Kolmogorov-Smirnov-test bevestigt dit vermoeden (p = 0,002 en p = 0.006). Het uitvoeren van een ln-transformatie op de twee variabelen lost het probleem en stelt multivariate normaliteit (K-s test p = .991 en p = .543).
we kunnen nu de lineaire regressieanalyse uitvoeren. Lineaire regressie wordt gevonden in SPSS In analyseren / regressie / lineair…
in dit eenvoudige geval moeten we gewoon de variabelen log_pop en log_murder toevoegen aan het model als afhankelijke en onafhankelijke variabelen.
de veldstatistieken stellen ons in staat om aanvullende statistieken op te nemen die we nodig hebben om de validiteit van onze lineaire regressieanalyse te beoordelen.
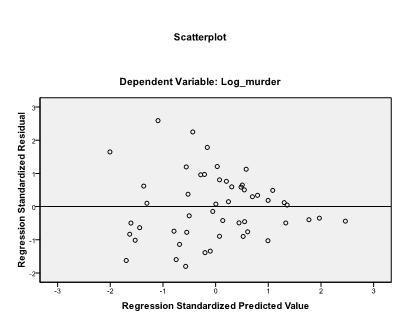
het is raadzaam om ook de collineariteitsdiagnose en de Durbin-Watson-test voor autocorrelatie op te nemen. Om de aanname van homoscedasticiteit van reststoffen te testen nemen we ook een speciaal perceel in het menu van de percelen.
de SPSS-syntaxis voor de lineaire regressieanalyse is
regressie
/ ontbrekende LISTWISE
/ STATISTICS COEFF OUTS R ANOVA COLLIN TOL
/ CRITERIA=PIN(.05) POUT(.10)
/ NOOORIGIN
/ DEPENDENT Log_murder
/ METHOD = ENTER Log_pop
/ SCATTERPLOT=(*ZRESID, * ZPRED)
/RESIDUALS DURBIN HIST (ZRESID).
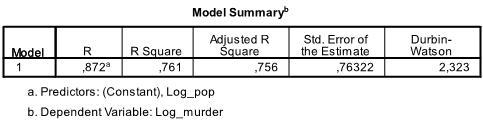
de eerste tabel van de output toont de modeloverzicht en de Algemene fit-statistieken. We vinden dat de aangepaste R2 van ons model 0,756 is met de R2 = .761 dat betekent dat de lineaire regressie 76 verklaart.1% van de variantie in de gegevens. De Durbin-Watson d = 2,323, dat is tussen de twee kritische waarden van 1,5 < d < 2,5 en daarom kunnen we aannemen dat er geen eerste orde lineaire auto-correlatie in de gegevens is.
de volgende tabel is de F-test, de F-test van de lineaire regressie heeft de nulhypothese dat er geen lineair verband is tussen de twee variabelen (met andere woorden R2=0). Met F = 156.2 en 50 vrijheidsgraden de test is zeer significant, dus kunnen we aannemen dat er een lineaire relatie is tussen de variabelen in ons model.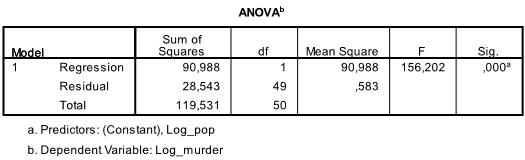
de volgende tabel toont de regressiecoëfficiënten, het intercept en de significantie van alle coëfficiënten en het intercept in het model. We vinden dat onze lineaire regressieanalyse schat dat de lineaire regressiefunctie y = -13.067 + 1.222
* x is. houd er rekening mee dat dit niet vertaalt in 1.2 extra moorden voor elke 1000 extra inwoners omdat we de variabelen veranderden.
als we de lineaire regressieanalyse opnieuw zouden uitvoeren met de oorspronkelijke variabelen, zouden we eindigen met y = 11.85 + 6.7*10-5 wat laat zien dat voor elke 10.000 extra inwoners we 6,7 extra moorden zouden verwachten.
in onze lineaire regressieanalyse test de test de nulhypothese dat de coëfficiënt 0 is. De T-test stelt vast dat zowel intercept als variabele zeer significant zijn (p < 0,001) en dus kunnen we zeggen dat ze verschillen van nul.
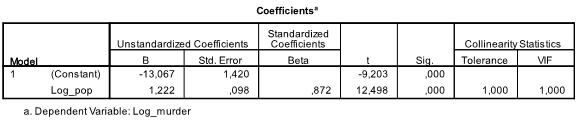
deze tabel bevat ook de Bètagewichten (die het relatieve belang van onafhankelijke variabelen uitdrukken) en de collineariteitsstatistieken. Aangezien we echter slechts 1 onafhankelijke variabele in onze Analyse hebben, besteden we geen aandacht aan die waarden.
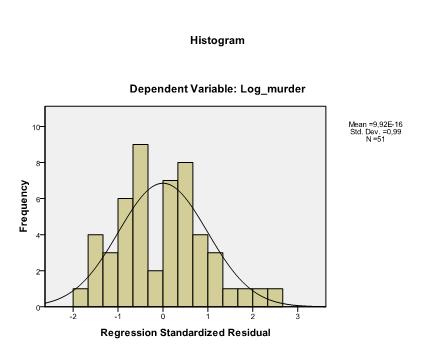
het laatste wat we moeten controleren is de homoscedasticiteit en normaliteit van reststoffen. Het histogram geeft aan dat de reststoffen een normale verdeling benaderen. De Q-Q-Plot van z * pred en z*presid laat ons zien dat er in onze lineaire regressieanalyse geen tendens is in de fouttermen.