 heeft u moeite om uw webpagina te vinden via online zoekopdrachten? In dit bericht, leert u hoe om te controleren of uw pagina is geïndexeerd.
heeft u moeite om uw webpagina te vinden via online zoekopdrachten? In dit bericht, leert u hoe om te controleren of uw pagina is geïndexeerd.
als u niet rangschikt voor iets wat u probeert, maakt niet uit hoe specifiek het is, heeft het misschien niets te maken met de kwaliteit van uw inhoud — het kan een indexeringsprobleem zijn.
elke zoekmachine trekt zijn resultaten uit een index, en als een webpagina ontbreekt in die index, kan deze uiteraard niet in de resultaten worden weergegeven. Vanwege dit, een indexering probleem kan uiteindelijk volledig verspillen van al uw kwalitatief hoogwaardige inhoud en op-pagina optimalisatie werk.
als u niet zeker weet of uw webpagina ‘ s correct zijn geïndexeerd, of als u advies nodig hebt om een indexeringsprobleem op te lossen, is dit het artikel voor u. We gaan kijken hoe indexeren werkt, wat de meest voorkomende indexeringsproblemen zijn, en hoe je de nodige wijzigingen kunt aanbrengen om ervoor te zorgen dat je niet opnieuw last hebt van indexeringsproblemen.
- hoe indexeren werkt
- waarom sommige pagina ‘ s niet geïndexeerd zouden moeten worden
- er zijn drie redenen waarom het een slecht idee zou zijn om absoluut elke live link in een zoekindex op te nemen:
- hoe te zien of een pagina is geïndexeerd
- veel voorkomende redenen waarom een pagina niet wordt geïndexeerd
- de gevolgen van indexeringsemissies
- weten wanneer een pagina wordt geïndexeerd
- hoe u uw webinstellingen voor indexering
- waar indexering past in uw SEO-strategie
- met behulp van indexen voor onderzoek van concurrenten
- het afronden van hoe te controleren of uw pagina is geïndexeerd
hoe indexeren werkt
wanneer nieuwe websites of pagina ‘ s online worden gehost, melden ze zich niet aan bij zoekmachines — de engines moeten het werk doen om ze te vinden. De manier waarop ze dit doen is door middel van zoekmachine bots (anders aangeduid als crawlers). Crawlers, zoals de naam al doet vermoeden, maken hun weg door websites, het volgen van interne en externe links met als doel het indexeren en organiseren van alle inhoud die ze vinden.
alle gegevens die onderweg worden verzameld, worden opgeslagen in de index, klaar voor gebruik door de zoekmachine. Wanneer een gebruiker een zoekopdracht indient, doet de zoekmachine het volgende:
- Parse de query naar beste rechter searcher intent.
- filteren van de index in overeenstemming met de afgeleide bedoeling.
- Selecteer alle pagina ‘ s die geschikt worden geacht (rekening houdend met een groot aantal factoren).
- presenteer ze aan de gebruiker in volgorde van relevantie.
omdat pagina ‘ s regelmatig worden bijgewerkt, in kwaliteit stijgen of dalen en relevant zijn voor bepaalde onderwerpen, moeten crawlers regelmatig terugkeren naar geïndexeerde sites. Hoe regelmatig een site wordt gekropen zal afhangen van hoe vaak het verandert, hoeveel autoriteit het wordt geacht te hebben, en tal van andere statistieken.
waarom sommige pagina ‘ s niet geïndexeerd zouden moeten worden
zoekindexen zijn niet alleen databases van alles wat gevonden wordt door crawlers.
er zijn drie redenen waarom het een slecht idee zou zijn om absoluut elke live link in een zoekindex op te nemen:
- het doel van een zoekindex is om pagina ’s op te slaan die relevant zijn voor de bedoeling van de zoeker, en bepaalde pagina’ s (en paginatypen) bevatten geen dergelijke inhoud en zijn niet de moeite waard om op te nemen. Websites met productfilters kunnen bijvoorbeeld vaak automatisch lange lijsten met verschillende URL ‘ s genereren voor gefilterde of gesorteerde weergaven, en veel van die weergaven zullen voor niemand interessant zijn. Bovendien, als meerdere pagina ‘ s dezelfde inhoud hebben, moet slechts één van hen worden geretourneerd: zoekers profiteren niet van meerdere resultaten met dezelfde inhoud.
- net zoals een pagina inhoudelijk geschikt moet zijn, moet hij ook technisch up-to-level zijn. Als een gebruiker klikt op een zoekresultaat link en de pagina nooit laadt, of opent spam pop-ups, of biedt een onaanvaardbare gebruikerservaring, dan is het weerspiegelt slecht op de zoekmachine en ontmoedigt de gebruiker.
- zoekmachines willen dat website-eigenaren zelf-curate omdat er geen voordeel is in het opnemen van pagina ‘ s die de eigenaren niet willen worden geïndexeerd. Soms website-eigenaren willen houden inhoud rond voor het nageslacht, maar ervoor kiezen om het te archiveren omdat het is verouderd en / of niet geschikt voor het doel. Zoekresultaten moeten worden gehouden om de meest waardevolle pagina ‘s, en dat zijn de pagina’ s die website-eigenaren actief willen worden gezien.
als gevolg hiervan zijn er verschillende dingen die ertoe kunnen leiden dat een pagina niet wordt geïndexeerd door een zoekmachine. Niet alleen kan de crawler beslissen dat een pagina is niet de moeite waard, maar de website eigenaar kan betekenen dat een pagina niet moet worden geïndexeerd, en zelfs tag specifieke links om crawlers vertellen om ze niet te volgen in de eerste plaats.
hoe te zien of een pagina is geïndexeerd
om te zien of een pagina is geïndexeerd door Google, gebruik onze gratis Google Index Checker. U kunt die tool gebruiken om te controleren tot 10 URL ‘ s in bulk op hetzelfde moment. Als een pagina niet is geïndexeerd, zal het u vertellen of het domein op zijn minst is geïndexeerd (wat betekent dat sommige andere pagina ‘ s van het domein zijn geïndexeerd).
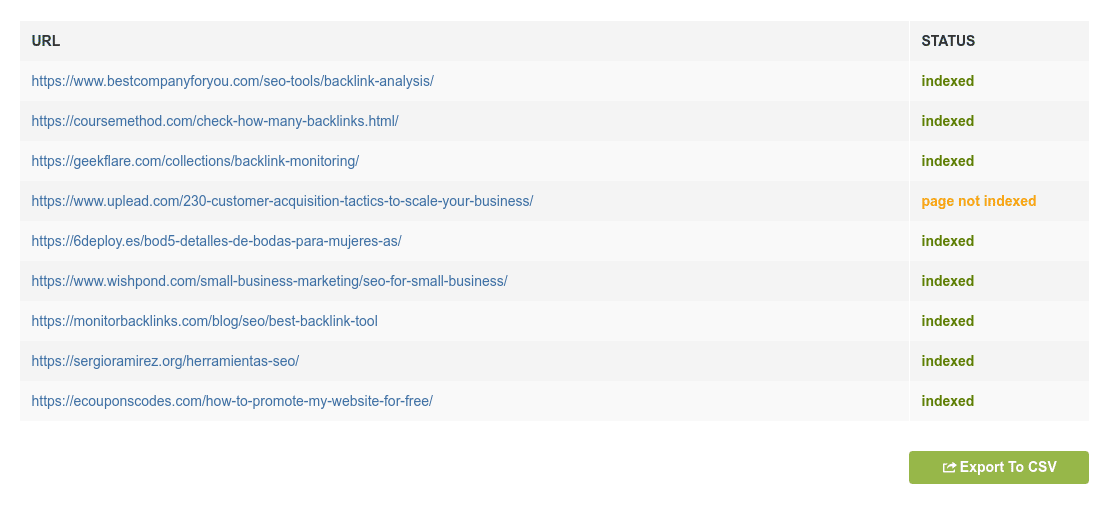
veel voorkomende redenen waarom een pagina niet wordt geïndexeerd
zoals opgemerkt, zijn er tal van redenen waarom een pagina niet wordt geïndexeerd. Hier zijn de meest voorkomende:
- Crawlers kunnen het niet vinden. Als uw website geen uitgebreide XML sitemap heeft (een lijst met alle pagina ‘ s die geïndexeerd moeten worden) of interne links naar een bepaalde pagina heeft of diep in mappen is begraven, zal een crawler deze vaak niet kunnen vinden en dus niet kunnen indexeren.
- de pagina is ingesteld op’noindex’. Zelfs als je een interne link naar een pagina hebt, of een Externe link die ernaar wijst vanuit een ander domein, is de pagina mogelijk gelabeld als ‘noindex’, wat leidt tot crawlers die deze negeren.
- het is geblokkeerd in robots.txt. Elke webserver levert een bestand genaamd robot.txt die instructies voor crawlers bevat. Als een robot.txt-bestand verbiedt alle crawlers van het indexeren van de site, dat is natuurlijk een enorm probleem. Hoewel dat is ongewoon, het is niet zo zeldzaam voor een ontwikkelaar om te proberen om specifieke pagina ‘ s te blokkeren, maar per ongeluk uiteindelijk blokkeren veel meer in het proces.
- het kwaliteitsniveau is niet hoog genoeg. Als uw domein lage waarde links en niet genoeg inhoud (of helemaal geen inhoud) bevat, kunnen zoekmachines besluiten om sommige of alle pagina ‘ s niet te rangschikken in een poging om een hoge standaard te handhaven.
er zijn verschillende andere mogelijke oorzaken voor pagina ‘ s die niet worden geïndexeerd, maar ze kunnen vrij technisch complex zijn en afhangen van de exacte aard van uw site. In de overgrote meerderheid van de gevallen zal de verklaring een van de hierboven genoemde zijn.
de gevolgen van indexeringsemissies
hoeveel een website wordt beïnvloed door indexeringsemissies hangt af van de aard en de breedte van de emissies en van de pagina ‘ s die zij beïnvloeden. Als een kleine pagina op uw site gaat niet geïndexeerd, het is niet het einde van de wereld, maar als een hoge kwaliteit SEO-vriendelijke stuk van evergreen inhoud is niet geïndexeerd, dat is een aanzienlijke verspilling van moeite.
en voor websites in de e-commercesector is indexering nog belangrijker. Organisch verkeer is veruit de meest kosteneffectieve vorm van verkeer voor productpagina ‘ s, omdat het niets kost om te verschijnen in de zoekresultaten, in tegenstelling tot PPC of social media reclame. Als de producten van een half bedrijf niet worden geïndexeerd, worden de conversiemogelijkheden enorm verminderd.
weten wanneer een pagina wordt geïndexeerd
het is heel gebruikelijk dat website-eigenaren een specifieke vraag stellen: wanneer wordt mijn pagina geïndexeerd? Helaas is er geen manier om het definitief te weten. Zelfs als u absoluut alles correct doet, strikt volgens de richtlijnen van Google en andere zoekmachines, zal dit afhangen van factoren buiten uw controle.
omdat zoekindexen miljoenen en miljoenen pagina ‘ s van over de hele wereld omvatten, en hun crawls consequent moeten vernieuwen om up-to-date informatie te garanderen, kan uw pagina morgen, volgende week of over een paar maanden worden geïndexeerd.
Duurzaamheid is alleen mogelijk door operationele efficiëntie, en er is geen efficiëntie of waarde in het maken van een poging om absoluut alles te indexeren als een kwestie van urgentie. Dit is de reden waarom Google praat over het hebben van een crawl budget dat bepaalt hoe vaak een pagina wordt gekropen.
hoe u uw webinstellingen voor indexering
controleert om ervoor te zorgen dat geïndexeerde pagina ’s correct geïndexeerd blijven, nieuwe pagina’ s aan die lijst worden toegevoegd en ongewenste pagina ‘ s niet worden opgenomen, is het belangrijk dat elk bedrijf met een grote aanwezigheid op het web tijd en middelen toewijst aan dit specifieke SEO-probleem.
op een enigszins regelmatige basis (misschien om de drie maanden of zo), moet u een grondige herziening uitvoeren van de volgende zaken::
- de informatiearchitectuur van uw website. Functioneert alles naar behoren vanuit technisch oogpunt? Behandelt de server de belasting zoals het hoort?
- uw interne verbindingsstructuur. Heeft u voldoende interne links om regelmatig kruipen te ondersteunen? Je kunt vrij liberaal zijn met interne links omdat ze nuttige context bieden, maar ga niet overboord met hen omdat het een boete riskeert.
- uw breadcrumb-instelling. Zijn pagina ‘ s correct genest en in de juiste categorieën geplaatst? Het onderhouden van een logische interne structuur is erg belangrijk voor het tonen van zoekmachines dat uw pagina ‘ s zijn de moeite waard indexeren.
hoewel u hiervoor geen IT-expert hoeft te worden, moet u ofwel al deze concepten onder de knie krijgen, ofwel iemand raadplegen die precies weet hoe deze dingen te controleren en de vereiste wijzigingen aan te brengen.
waar indexering past in uw SEO-strategie
wanneer bedrijven nadenken over hoe SEO speelt in hun marketingstrategieën, hebben ze de neiging om technische SEO-overwegingen te zien als lage prioriteit. Andere SEO overwegingen zoals content marketing of social media outreach zijn creatiever en dus gezien als meer glamoureus en interessant.
het probleem met deze denkwijze is natuurlijk dat het over het hoofd zien van de technische grondbeginselen uiterst dwaas is. Als uw budget voor een lange campagne van betaalde reclame, social media werk, content productie, en merk advocacy, maar niet beseffen dat je het opbouwen van gezag rond een pagina die niet kan worden geïndexeerd in Google, het zal neerkomen op een nutteloze investering — zodra de campagne eindigt, uw verkeer zal alles behalve verdwijnen opnieuw.
met behulp van indexen voor onderzoek van concurrenten
afgezien van uw eigen indexering, is er een ander aspect van zoekindexen dat een vermelding verdient: onderzoek van concurrenten. Door te kijken naar welke pagina ‘ s de index van uw concurrent (en welke ze niet), kunt u een idee krijgen van wat ze doen en hebben de mogelijkheid om reverse engineer hun strategieën.
bedenk eens hoeveel informatie u zonder kosten kunt verkrijgen via eenvoudige Google-zoekopdrachten. Als u een beetje tijd te investeren in de herziening van hoe andere bedrijven in uw industrie omgaan met indexering, backlinks, en zoekresultaten in het algemeen, je zult veel uit te halen.
het afronden van hoe te controleren of uw pagina is geïndexeerd
het opbouwen van een website in een zeer concurrerende online aanwezigheid is een uitdaging op de beste momenten, ongeacht hoeveel geweldige content U hebt of hoe goed u contact hebt met uw publiek. Het kost tijd en consistentie, en er zijn tal van andere uitstekende sites die er de moeite waard zijn om boven je te worden gerangschikt als je je normen laat glijden.
omdat u zoveel tijd en moeite moet investeren in content, outreach en UX-ontwikkeling, is het van het grootste belang dat u ervoor zorgt dat u niet wordt tegengehouden door een fundamenteel technisch probleem zoals het hebben van belangrijke pagina ‘ s die niet worden geïndexeerd.
we hebben besproken wat indexeren is, waarom het zo belangrijk is, en hoe u actie kunt ondernemen om gemeenschappelijke indexeringsproblemen te identificeren en te overwinnen. De rest is aan jou. Vind de tijd om uw setup grondig te beoordelen, en Plan semi-frequente beoordelingen om ervoor te zorgen dat uw inspanningen niet worden ondermijnd door vermijdbare technische problemen.
 Kayleigh Toyra: Content strateeg
Kayleigh Toyra: Content strateeg
Half-Finse, half-Britse marketeer gevestigd in Bristol. Ik hou van het schrijven en verkennen van thema ‘ s als storytelling en customer experience marketing. Ik leid een klein team van schrijvers bij een boetiekbureau.
