Av Ahad Sheriff
et enkelt prosjekt for å lære grunnleggende av nettskraping

Før vi begynner, la oss sørge for at vi forstår hva nettskraping er:
nettskraping er prosessen med å trekke ut data fra nettsteder for å presentere det i et format brukere enkelt kan forstå.
i denne opplæringen vil jeg demonstrere hvor enkelt det er å bygge en enkel url crawler I Python som du kan bruke til å kartlegge nettsteder. Selv om dette programmet er relativt enkelt, kan det gi en god introduksjon til grunnleggende av nettskraping og automatisering. Vi vil fokusere på rekursivt å trekke ut lenker fra nettsider, men de samme ideene kan brukes på et mylder av andre løsninger.
vårt program vil fungere slik:
- Besøk en nettside
- Skrap alle unike URL-er funnet på nettsiden og legg dem til en kø
- Rekursivt behandle URL-ene en etter en til vi utmatter køen
- Skriv ut resultater
Første Ting Først
det første vi bør gjøre er å importere alle nødvendige biblioteker. Vi vil bruke BeautifulSoup, forespørsler og urllib for nettskraping.
from bs4 import BeautifulSoupimport requestsimport requests.exceptionsfrom urllib.parse import urlsplitfrom urllib.parse import urlparsefrom collections import dequeDeretter må vi velge EN URL for å begynne å krype fra. Mens du kan velge hvilken som helst nettside MED HTML-koblinger, anbefaler jeg å bruke ScrapeThisSite. Det er en trygg sandkasse som du kan krype uten å komme i trøbbel.
url = "https://scrapethissite.com" Deretter må vi opprette et nytt deque-objekt slik at vi enkelt kan legge til nylig funnet koblinger og fjerne dem når vi er ferdige med å behandle dem. Pre-fylle deque med url variabel:
# a queue of urls to be crawled nextnew_urls = deque()Vi kan da bruke et sett til å lagre unike URL-ER når de har blitt behandlet:
# a set of urls that we have already processed processed_urls = set()Vi ønsker også å holde styr på lokale (samme domene som målet), utenlandske (annet domene som målet), og ødelagte Nettadresser:
# a set of domains inside the target websitelocal_urls = set()# a set of domains outside the target websiteforeign_urls = set()# a set of broken urlsbroken_urls = set()Tid Til Å Krype
med alt det på plass, kan vi nå begynne å skrive den faktiske koden for å gjennomsøke nettstedet.
Vi vil se på HVER URL i køen, se om det er noen EKSTRA URL-er på den siden og legg til hver til slutten av køen til det ikke er noen igjen. Så snart vi er ferdig med å skrape EN URL, fjerner vi den fra køen og legger den til processed_urls – settet for senere bruk.
# process urls one by one until we exhaust the queuewhile len(new_urls): # move url from the queue to processed url set url = new_urls.popleft() processed_urls.add(url) # print the current url print("Processing %s" % url) Legg Deretter til et unntak for å fange opp ødelagte nettsider og legge dem til broken_urls – settet for senere bruk:
try: response = requests.get(url)except(requests.exceptions.MissingSchema, requests.exceptions.ConnectionError, requests.exceptions.InvalidURL, requests.exceptions.InvalidSchema): # add broken urls to it's own set, then continue broken_urls.add(url) continueVi må da få basen URL til nettsiden slik at vi enkelt kan skille mellom lokale og utenlandske adresser:
# extract base url to resolve relative linksparts = urlsplit(url)base = "{0.netloc}".format(parts)strip_base = base.replace("www.", "")base_url = "{0.scheme}://{0.netloc}".format(parts)path = url if '/' in parts.path else urlInitialiser BeautifulSoup for å behandle HTML-dokumentet:
soup = BeautifulSoup(response.text, "lxml")skrap nå nettsiden for alle koblinger og sorter legg dem til deres tilsvarende sett:
for link in soup.find_all('a'): # extract link url from the anchor anchor = link.attrs if "href" in link.attrs else ''if anchor.startswith('/'): local_link = base_url + anchor local_urls.add(local_link) elif strip_base in anchor: local_urls.add(anchor) elif not anchor.startswith('http'): local_link = path + anchor local_urls.add(local_link) else: foreign_urls.add(anchor)Siden jeg bare vil begrense søkeroboten til lokale adresser, legger jeg til følgende For å legge til Nye Nettadresser i køen vår:
for i in local_urls: if not i in new_urls and not i in processed_urls: new_urls.append(i)hvis du vil gjennomgå Alle Nettadresser, bruk:
if not link in new_urls and not link in processed_urls: new_urls.append(link)Advarsel: Måten programmet for tiden fungerer, krypende utenlandske URL-er vil ta SVÆRT lang tid. Du kan muligens komme i trøbbel for skraping nettsteder uten tillatelse. Bruk på egen risiko!
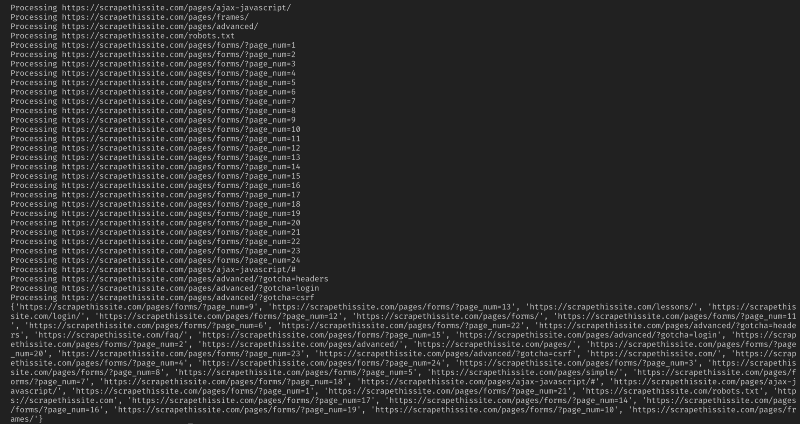
her er all koden min:
og det burde være det. Du har nettopp laget et enkelt verktøy for å gjennomgå et nettsted og kartlegge Alle Nettadresser funnet!
Avslutningsvis
Føl deg fri til å bygge videre på og forbedre denne koden. Du kan for eksempel endre programmet for å søke på nettsider etter e-postadresser eller telefonnumre mens du gjennomsøker dem. Du kan til og med utvide funksjonaliteten ved å legge til kommandolinjeargumenter for å gi muligheten til å definere utdatafiler, begrense søk til dybde og mye mer. Lær om hvordan du oppretter kommandolinjegrensesnitt for å godta argumenter her.
