아하드 보안관
웹 스크래핑의 기초를 배우기 위한 간단한 프로젝트

웹 스크래핑은 웹 사이트에서 데이터를 추출하여 사용자가 쉽게 이해할 수있는 형식으로 제공하는 프로세스입니다.
이 튜토리얼에서,나는 당신이 웹 사이트를 매핑하는 데 사용할 수있는 파이썬에서 간단한 웹 사이트 크롤러를 구축하는 것이 얼마나 쉬운 방법을 보여 드리고자합니다. 이 프로그램은 비교적 간단하지만 웹 스크래핑 및 자동화의 기본 사항에 대한 훌륭한 소개를 제공 할 수 있습니다. 우리는 웹 페이지에서 재귀 적으로 링크를 추출하는 데 초점을 맞출 것이지만 동일한 아이디어를 수많은 다른 솔루션에 적용 할 수 있습니다.
우리의 프로그램은 다음과 같이 작동합니다:
- 웹 페이지 방문
- 웹 페이지에서 찾은 모든 고유 한 주소를 긁어 큐에 추가
- 재귀 적으로 큐를 소진 할 때까지 하나씩 처리
- 인쇄 결과
첫 번째 것들 먼저
먼저해야 할 일은 모든 항목을 가져 오는 것입니다.필요한 라이브러리. 우리는 웹 스크래핑을 위해 아름다운 수프,요청 및 우르립을 사용할 것입니다.
from bs4 import BeautifulSoupimport requestsimport requests.exceptionsfrom urllib.parse import urlsplitfrom urllib.parse import urlparsefrom collections import deque다음으로 크롤링을 시작할 주소를 선택해야 합니다. 당신은 웹 페이지를 선택할 수 있지만,나는 스크랩을 사용하는 것이 좋습니다. 당신이 말썽안에 얻기없이 포복할 수 있는 안전한 모래통 이다.
url = "https://scrapethissite.com"다음으로,우리는 우리가 쉽게 새로 발견 된 링크를 추가하고 우리가 그들을 처리가 완료되면 제거 할 수 있도록 새로운 데크에게 개체를 만들어야합니다. url변수로 데크를 미리 채 웁니다.:
# a queue of urls to be crawled nextnew_urls = deque()우리는 다음 설정을 사용할 수 있습니다 저장 고유 한 주소의들이 처리 된 후:
# a set of urls that we have already processed processed_urls = set()또한 로컬(대상과 동일한 도메인),외부(대상과 다른 도메인)및 깨진 웹 사이트를 추적하려고합니다:
# a set of domains inside the target websitelocal_urls = set()# a set of domains outside the target websiteforeign_urls = set()# a set of broken urlsbroken_urls = set()크롤링하는 시간
그 자리에 모든,우리는 지금 웹 사이트를 크롤링하는 실제 코드를 작성 시작할 수 있습니다.
우리는 큐의 각 링크에서 보면,그 페이지 내에 추가 링크의 존재 여부를 확인하고 아무도 남아 있지 때까지 큐의 끝에 각 하나를 추가 할 수 있습니다. 2752>집합에 추가하여 나중에 사용할 수 있습니다.
# process urls one by one until we exhaust the queuewhile len(new_urls): # move url from the queue to processed url set url = new_urls.popleft() processed_urls.add(url) # print the current url print("Processing %s" % url)다음으로,깨진 웹 페이지를 잡아서 나중에 사용할 수 있도록broken_urls세트에 추가하는 예외를 추가합니다:
try: response = requests.get(url)except(requests.exceptions.MissingSchema, requests.exceptions.ConnectionError, requests.exceptions.InvalidURL, requests.exceptions.InvalidSchema): # add broken urls to it's own set, then continue broken_urls.add(url) continue그런 다음 로컬 주소와 외부 주소를 쉽게 구분할 수 있도록 웹 페이지의 기본 주소를 가져와야 합니다:
# extract base url to resolve relative linksparts = urlsplit(url)base = "{0.netloc}".format(parts)strip_base = base.replace("www.", "")base_url = "{0.scheme}://{0.netloc}".format(parts)path = url if '/' in parts.path else url이 문서를 처리 할 수 있습니다.:
soup = BeautifulSoup(response.text, "lxml")이제 모든 링크에 대한 웹 페이지를 긁어 정렬 해당 세트에 추가:
for link in soup.find_all('a'): # extract link url from the anchor anchor = link.attrs if "href" in link.attrs else ''if anchor.startswith('/'): local_link = base_url + anchor local_urls.add(local_link) elif strip_base in anchor: local_urls.add(anchor) elif not anchor.startswith('http'): local_link = path + anchor local_urls.add(local_link) else: foreign_urls.add(anchor)크롤러를 로컬 주소로만 제한하고 싶기 때문에 다음을 추가하여 큐에 새 주소를 추가합니다:
for i in local_urls: if not i in new_urls and not i in processed_urls: new_urls.append(i)크롤링하려면 다음을 사용합니다:
if not link in new_urls and not link in processed_urls: new_urls.append(link)경고: 이 프로그램이 현재 작동하는 방식은 매우 오랜 시간이 걸릴 것입니다. 당신은 아마도 허가없이 웹 사이트를 긁어 곤경에 얻을 수 있습니다. 자신의 위험에 사용!
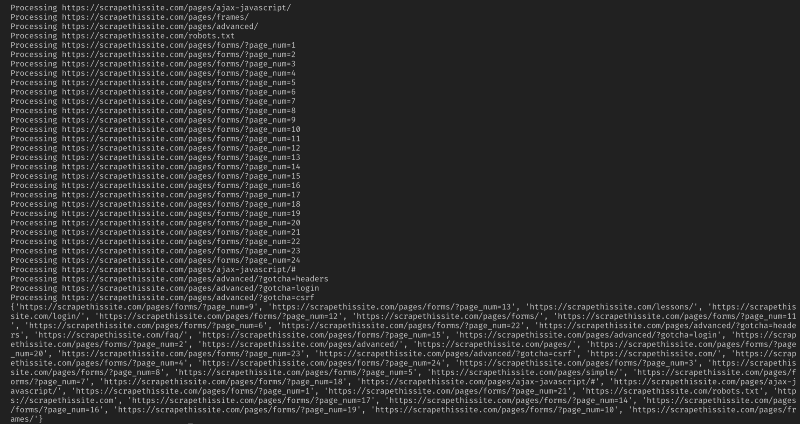
여기 내 모든 코드가 있습니다. 당신은 웹 사이트를 크롤링하고 발견 된 모든 주소를 매핑 할 수있는 간단한 도구를 만들었습니다!
결론
이 코드를 구축하고 개선하십시오. 예를 들어 크롤링할 때 웹 페이지에서 이메일 주소나 전화 번호를 검색하도록 프로그램을 수정할 수 있습니다. 명령 줄 인수를 추가하여 기능을 확장하여 출력 파일을 정의하고 검색을 깊이로 제한 할 수있는 옵션을 제공 할 수도 있습니다. 여기서 인수를 허용하는 명령줄 인터페이스를 만드는 방법에 대해 알아봅니다.
