od Ahad Sheriff
- jednoduchý projekt pro učení základů škrabání na webu
- první věc, kterou bychom měli udělat, je importovat všechny potřebné knihovny. Budeme používat BeautifulSoup, požadavky a urllib pro stírání webu. from bs4 import BeautifulSoupimport requestsimport requests.exceptionsfrom urllib.parse import urlsplitfrom urllib.parse import urlparsefrom collections import deque
- čas na procházení
- na závěr
jednoduchý projekt pro učení základů škrabání na webu

než začneme, ujistěte se, že rozumíme tomu, co je škrabání na webu:
škrabání na webu je proces extrahování dat z webových stránek a jejich prezentace ve formátu, který uživatelé mohou snadno dávat smysl.
v tomto tutoriálu chci ukázat, jak snadné je vytvořit jednoduchý prolézací modul URL v Pythonu, který můžete použít k mapování webových stránek. I když je tento program relativně jednoduchý, může poskytnout skvělý úvod do základů stírání a automatizace webu. Zaměříme se na rekurzivní extrahování odkazů z webových stránek, ale stejné nápady lze aplikovat na nesčetné množství dalších řešení.
náš program bude fungovat takto:
- navštivte webovou stránku
- seškrábněte všechny jedinečné adresy URL nalezené na webové stránce a přidejte je do fronty
- rekurzivně zpracovávejte adresy URL jeden po druhém, dokud nevyčerpáme frontu
- výsledky tisku
první věc, kterou bychom měli udělat, je importovat všechny potřebné knihovny. Budeme používat BeautifulSoup, požadavky a urllib pro stírání webu.
from bs4 import BeautifulSoupimport requestsimport requests.exceptionsfrom urllib.parse import urlsplitfrom urllib.parse import urlparsefrom collections import deque
from bs4 import BeautifulSoupimport requestsimport requests.exceptionsfrom urllib.parse import urlsplitfrom urllib.parse import urlparsefrom collections import dequedále musíme vybrat adresu URL, ze které se má začít procházet. I když si můžete vybrat libovolnou webovou stránku s odkazy HTML, doporučuji použít ScrapeThisSite. Je to bezpečné pískoviště, které můžete procházet, aniž byste se dostali do potíží.
url = "https://scrapethissite.com" dále budeme muset vytvořit nový objekt deque, abychom mohli snadno přidat nově nalezené odkazy a odstranit je, jakmile dokončíme jejich zpracování. Předvyplňte deque pomocí proměnné url :
# a queue of urls to be crawled nextnew_urls = deque()poté můžeme použít sadu k uložení jedinečných adres URL, jakmile budou zpracovány:
# a set of urls that we have already processed processed_urls = set()chceme také sledovat lokální (stejnou doménu jako cíl), cizí (jinou doménu jako cíl) a nefunkční adresy URL:
# a set of domains inside the target websitelocal_urls = set()# a set of domains outside the target websiteforeign_urls = set()# a set of broken urlsbroken_urls = set()čas na procházení
se vším, co je na místě, můžeme nyní začít psát skutečný kód pro procházení webu.
chceme se podívat na každou adresu URL ve frontě, zjistit, zda na této stránce nejsou nějaké další adresy URL, a každou přidat na konec fronty, dokud nezůstanou žádné. Jakmile dokončíme škrábání adresy URL, odstraníme ji z fronty a přidáme ji do sady processed_urls pro pozdější použití.
# process urls one by one until we exhaust the queuewhile len(new_urls): # move url from the queue to processed url set url = new_urls.popleft() processed_urls.add(url) # print the current url print("Processing %s" % url) Dále přidejte výjimku pro zachycení všech poškozených webových stránek a přidejte je do sady broken_urls pro pozdější použití:
try: response = requests.get(url)except(requests.exceptions.MissingSchema, requests.exceptions.ConnectionError, requests.exceptions.InvalidURL, requests.exceptions.InvalidSchema): # add broken urls to it's own set, then continue broken_urls.add(url) continuepoté musíme získat základní adresu URL webové stránky, abychom mohli snadno rozlišit místní a zahraniční adresy:
# extract base url to resolve relative linksparts = urlsplit(url)base = "{0.netloc}".format(parts)strip_base = base.replace("www.", "")base_url = "{0.scheme}://{0.netloc}".format(parts)path = url if '/' in parts.path else urlinicializujte BeautifulSoup pro zpracování dokumentu HTML:
soup = BeautifulSoup(response.text, "lxml")nyní seškrábněte webovou stránku pro všechny odkazy a seřaďte je do odpovídající sady:
for link in soup.find_all('a'): # extract link url from the anchor anchor = link.attrs if "href" in link.attrs else ''if anchor.startswith('/'): local_link = base_url + anchor local_urls.add(local_link) elif strip_base in anchor: local_urls.add(anchor) elif not anchor.startswith('http'): local_link = path + anchor local_urls.add(local_link) else: foreign_urls.add(anchor)protože chci omezit svůj prohledávač pouze na místní adresy, přidám následující pro přidání nových adres URL do naší fronty:
for i in local_urls: if not i in new_urls and not i in processed_urls: new_urls.append(i)pokud chcete procházet všechny adresy URL, použijte:
if not link in new_urls and not link in processed_urls: new_urls.append(link)varování: Způsob, jakým program v současné době funguje, procházení cizích URL bude trvat velmi dlouho. Ty by mohly dostat do potíží pro škrábání webové stránky bez povolení. Používejte na vlastní nebezpečí!
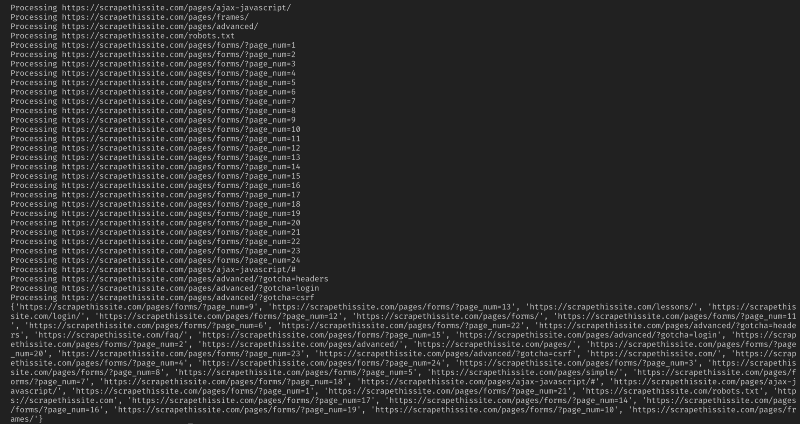
zde je celý můj kód:
a to by mělo být ono. Právě jste vytvořili jednoduchý nástroj pro procházení webových stránek a mapování všech nalezených adres URL!
na závěr
neváhejte a stavět na a zlepšit tento kód. Můžete například upravit program tak, aby při procházení prohledával e-mailové adresy nebo telefonní čísla na webových stránkách. Dalo by se dokonce rozšířit funkčnost přidáním argumentů příkazového řádku poskytnout možnost definovat výstupní soubory, omezit vyhledávání do hloubky, a mnohem více. Zde se dozvíte, jak vytvořit rozhraní příkazového řádku pro přijímání argumentů.
